
tagged by: application architecture
Microservices Guide
The microservice architectural pattern is an approach to developing a single application as a suite of small services, each running in its own process and communicating with lightweight mechanisms, often an HTTP resource API. These services are built around business capabilities and independently deployable by fully automated deployment machinery. There is a bare minimum of centralized management of these services, which may be written in different programming languages and use different data storage technologies. While their advantages have made them very fashionable in the last few years, they come with the costs of increasing distribution, weakened consistency and require maturity in operational management.
Microservices
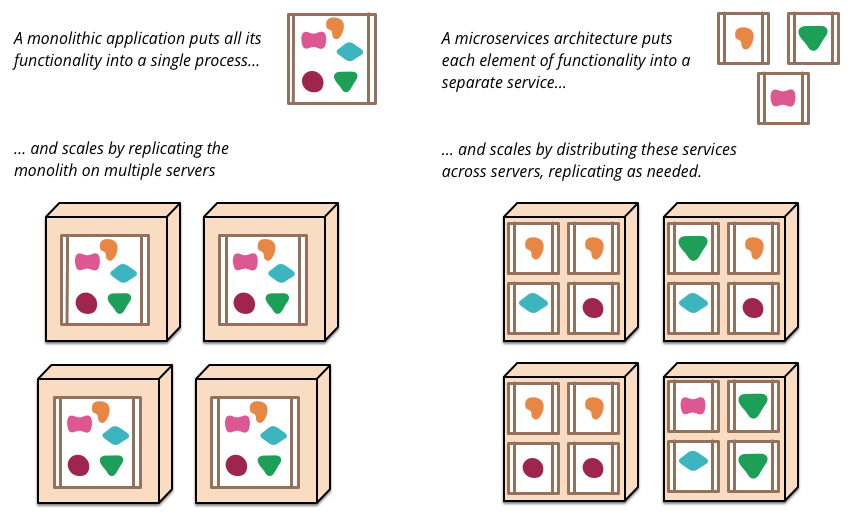
The term “Microservice Architecture” has sprung up over the last few years to describe a particular way of designing software applications as suites of independently deployable services. While there is no precise definition of this architectural style, there are certain common characteristics around organization around business capability, automated deployment, intelligence in the endpoints, and decentralized control of languages and data.
Micro Frontends
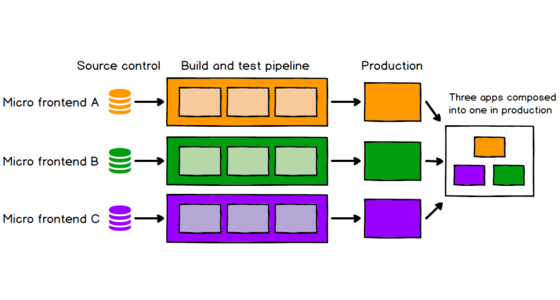
Good frontend development is hard. Scaling frontend development so that many teams can work simultaneously on a large and complex product is even harder. In this article we'll describe a recent trend of breaking up frontend monoliths into many smaller, more manageable pieces, and how this architecture can increase the effectiveness and efficiency of teams working on frontend code. As well as talking about the various benefits and costs, we'll cover some of the implementation options that are available, and we'll dive deep into a full example application that demonstrates the technique.
Emerging Patterns in Building GenAI Products

As we move software products using generative AI technology from proof-of-concepts into production systems, we are uncovering a range of common patterns. Evals play a central role in ensuring that these non-deterministic systems are operating within sensible boundaries. Large Language Models need enhancement to provide information beyond a generic and static training set. Most of the time we can do this with Retrieval Augmented Generation (RAG), although the basic RAG approach requires several patterns to overcome its limitations. When RAG isn't enough, Fine Tuning becomes worthwhile.
Principles of Mechanical Sympathy
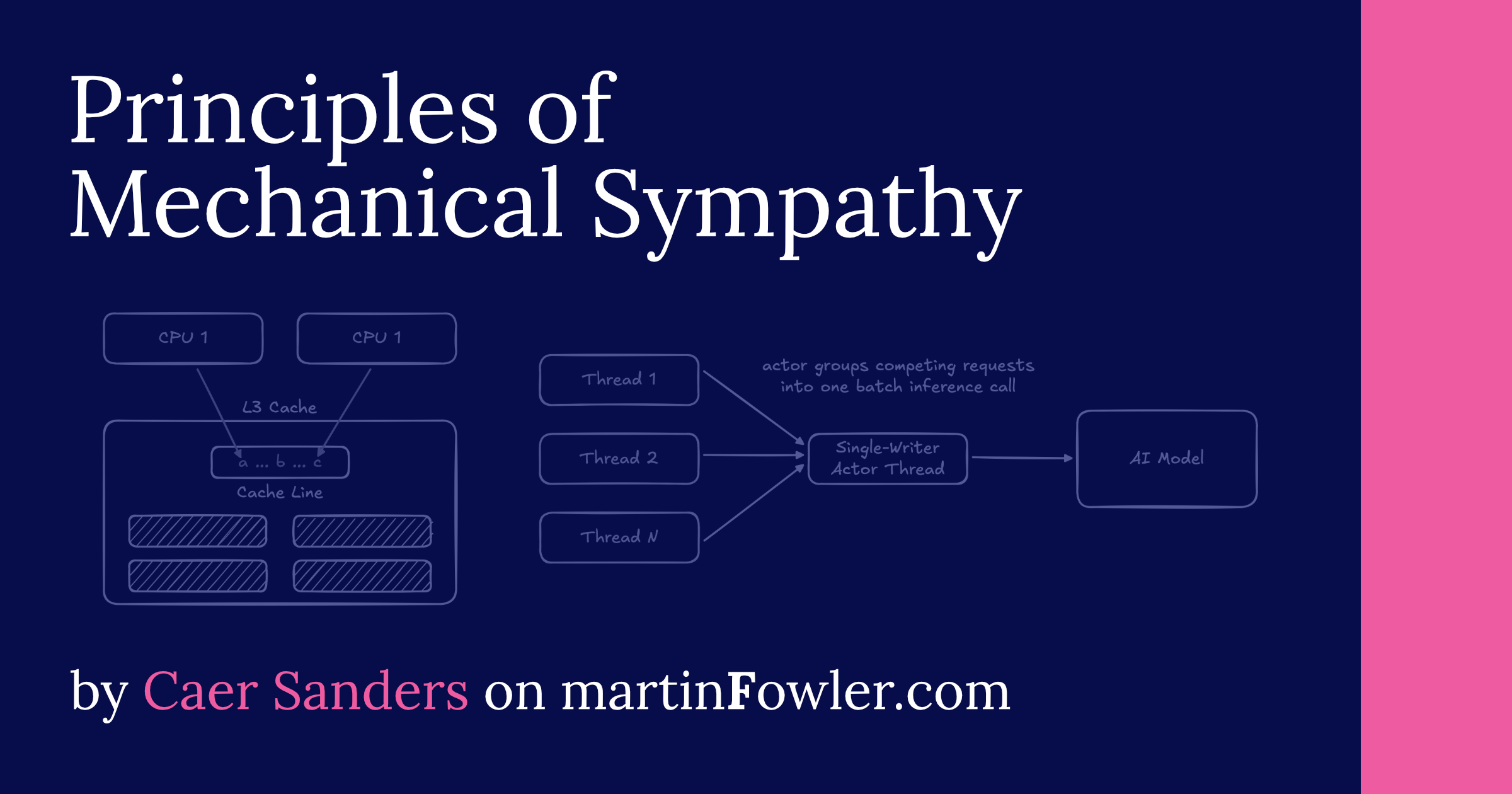
Modern hardware is remarkably fast, but software often fails to leverage it. Mechanical sympathy - a concept borrowed from racing and popularized in software by Martin Thompson - is the practice of creating software that is sympathetic to its underlying hardware. This practice can be distilled into a set of everyday principles: Predictable memory access, awareness of cache lines, the single-writer principle, and natural batching. Together, these principles can be used to optimize everything from an AI inference server to a distributed data platform.
Modularizing React Applications with Established UI Patterns
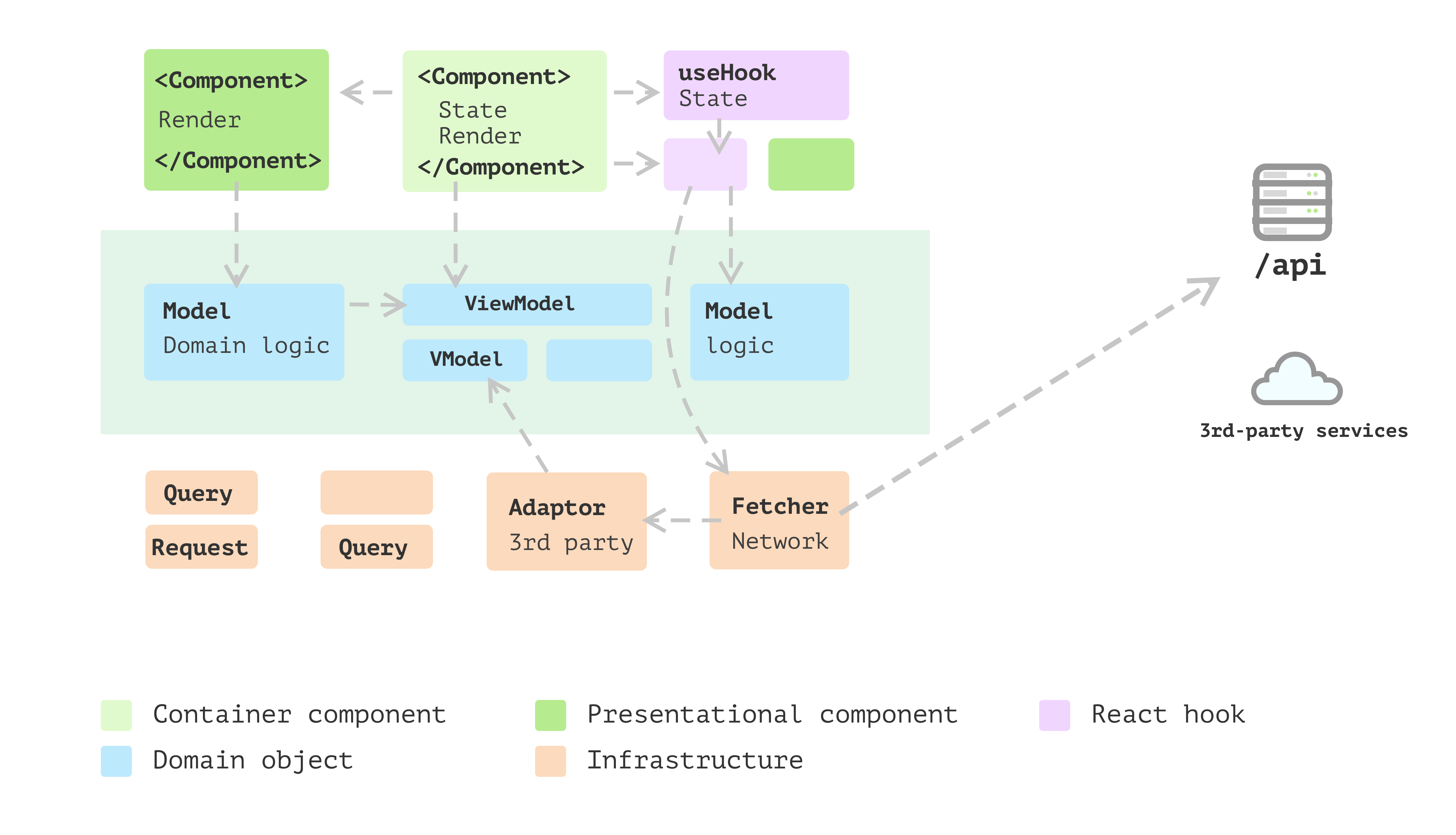
Established UI patterns are often underutilized in the frontend development world, despite their proven effectiveness in solving complex problems in UI design. This article explores the application of established UI building patterns to the React world, with a refactoring journey code example to showcase the benefits. The emphasis is placed on how layering architecture can help organize the React application for improved responsiveness and future changes.
Catalog of Patterns of Distributed Systems

Distributed systems provide a particular challenge to program. They often require us to have multiple copies of data, which need to keep synchronized. Yet we cannot rely on processing nodes working reliably, and network delays can easily lead to inconsistencies. Despite this, many organizations rely on a range of core distributed software handling data storage, messaging, system management, and compute capability. These systems face common problems which they solve with similar solutions. In 2020 Unmesh Joshi began collecting these solutions as patterns, publishing them on this site as he developed them. In 2023 these were published in the book Patterns of Distributed Systems. This page links to short summaries of each pattern, with deep links to the relevant chapters for the online eBook publication on oreilly.com
Serverless Architectures
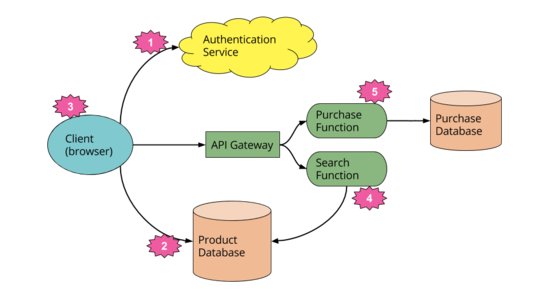
Serverless architectures are application designs that incorporate third-party “Backend as a Service” (BaaS) services, and/or that include custom code run in managed, ephemeral containers on a “Functions as a Service” (FaaS) platform. By using these ideas, and related ones like single-page applications, such architectures remove much of the need for a traditional always-on server component. Serverless architectures may benefit from significantly reduced operational cost, complexity, and engineering lead time, at a cost of increased reliance on vendor dependencies and comparatively immature supporting services.
Feature Toggles (aka Feature Flags)
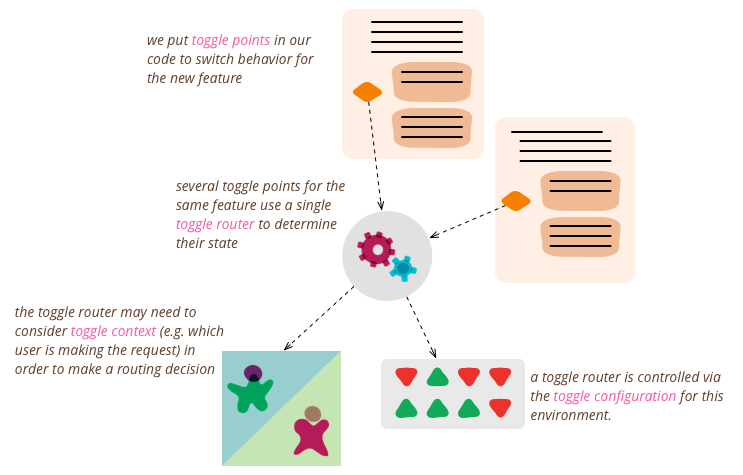
Feature Toggles (often also refered to as Feature Flags) are a powerful technique, allowing teams to modify system behavior without changing code. They fall into various usage categories, and it's important to take that categorization into account when implementing and managing toggles. Toggles introduce complexity. We can keep that complexity in check by using smart toggle implementation practices and appropriate tools to manage our toggle configuration, but we should also aim to constrain the number of toggles in our system.
Domain-Oriented Observability
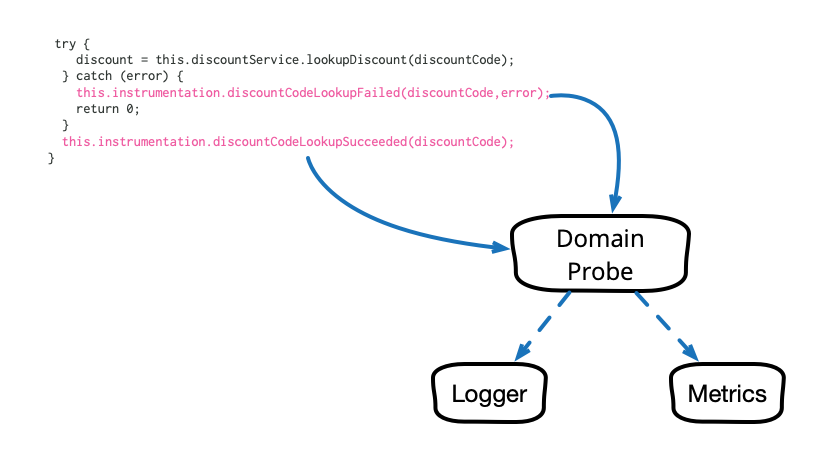
Observability in our software systems has always been valuable and has become even more so in this era of cloud and microservices. However, the observability we add to our systems tends to be rather low level and technical in nature, and too often it seems to require littering our codebase with crufty, verbose calls to various logging, instrumentation, and analytics frameworks. This article describes a pattern that cleans up this mess and allows us to add business-relevant observability in a clean, testable way.
Podcast on Agility and Architecture
Ryan Lockard (Agile Uprising) invited me to join Rebecca Wirfs-Brock for a podcast conversation on architecture on agile projects. Rebecca developed Responsibility-Driven Design, which was a big influence for me when I started my career. We talked about how we define architecture, the impact of tests on architecture, the role of domain models, what kind of documentation to prepare, and how much architecture needs to be done up-front.
Evolutionary Database Design
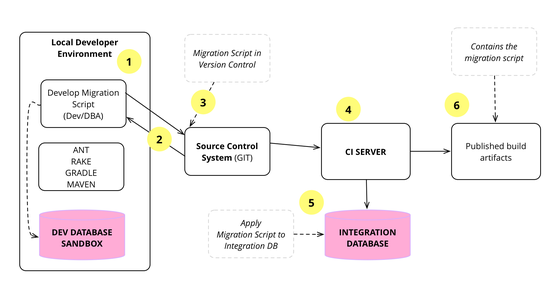
Over the last decade we've developed and refined a number of techniques that allow a database design to evolve as an application develops. This is a very important capability for agile methodologies. The techniques rely on applying continuous integration and automated refactoring to database development, together with a close collaboration between DBAs and application developers. The techniques work in both pre-production and released systems, in green field projects as well as legacy systems.
Refactoring Module Dependencies
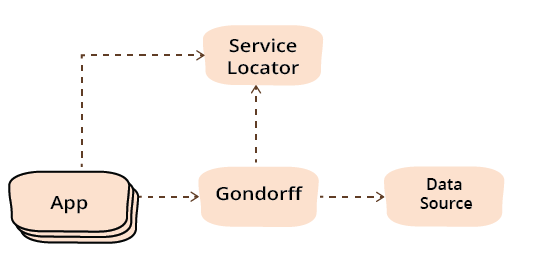
As a program grows in size it's important to split it into modules, so that you don't need to understand all of it to make a small modification. Often these modules can be supplied by different teams and combined dynamically. In this refactoring essay I split a small program using Presentation-Domain-Data layering. I then refactor the dependencies between these modules to introduce the Service Locator and Dependency Injection patterns. These apply in different languages, yet look different, so I show these refactorings in both Java and a classless JavaScript style.
Refactoring code that accesses external services
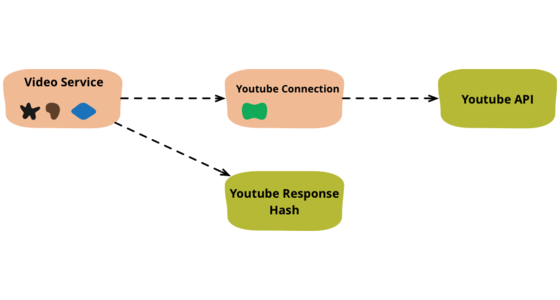
When I write code that deals with external services, I find it valuable to separate that access code into separate objects. Here I show how I would refactor some congealed code into a common pattern of this separation.
Hexagonal Architecture and Rails
A couple of videos of a conversation between me and my colleague Badri about hexagonal architecture and its role in a Rails application. In the first video we talk about what Hexagonal Architecture means and how this leads into the choice between the Active Record and Data Mapper patterns for a persistance framework. In the second we move more broadly into the architectural role Rails should play in an application - should you see it as a platform, or a suite of components.
Two Stack CMS
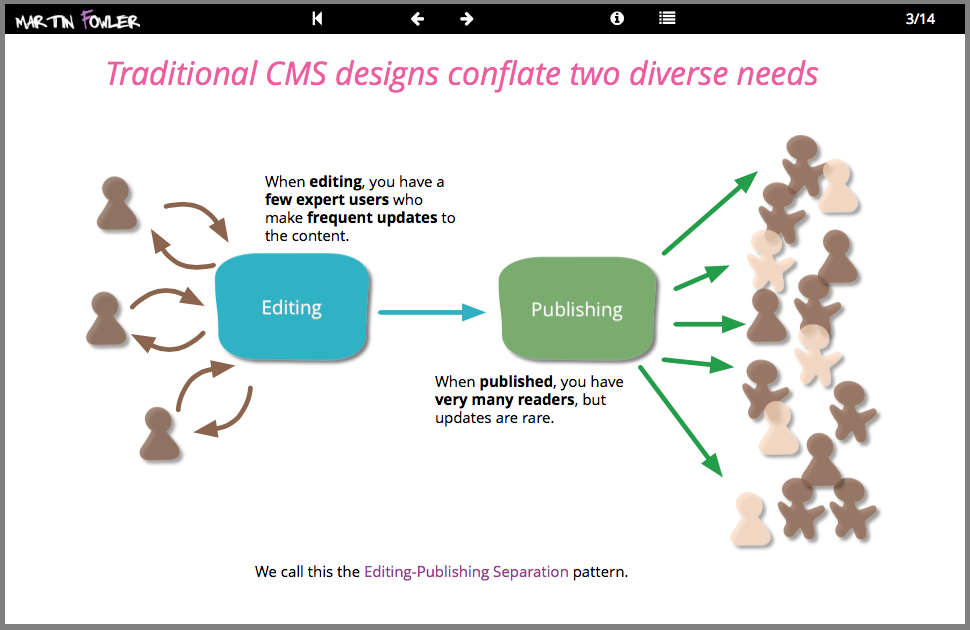
We build many websites with rich content, often using popular Content Management Systems (CMS). A recent project involved a marketing website for a global manufacturer which demanded complex interactive content with high availability and traffic needs. Our response was to apply the editing-publishing separation pattern and build two distinct stacks of software for content creation and delivery. In this deck you can see an overview of this architecture and our response to the issues of integration between the stacks, providing a secure preview of the live site, and handling the evolution and scaling of the system.
DIP in the Wild

The Dependency Inversion Principle (DIP) has been around since the early '90s, even so it seems easy to forget in the middle of solving a problem. After a few definitions, I'll present a number of applications of the DIP I've personally used on real projects so you'll have some examples from which to form your own conclusions.
The LMAX Architecture
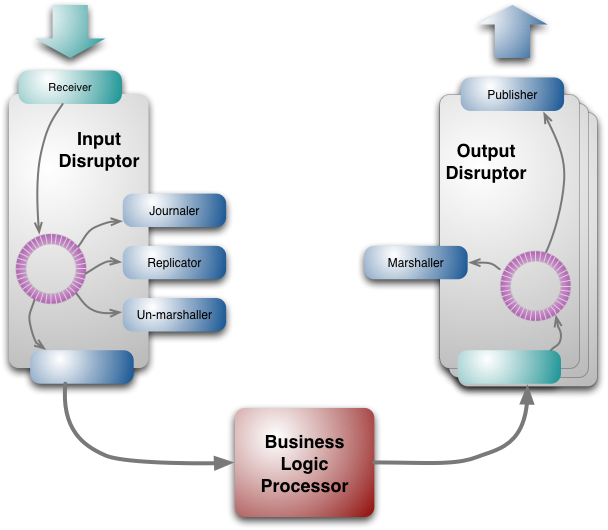
LMAX is a new retail financial trading platform. As a result it has to process many trades with low latency. The system is built on the JVM platform and centers on a Business Logic Processor that can handle 6 million orders per second on a single thread. The Business Logic Processor runs entirely in-memory using event sourcing. The Business Logic Processor is surrounded by Disruptors - a concurrency component that implements a network of queues that operate without needing locks. During the design process the team concluded that recent directions in high-performance concurrency models using queues are fundamentally at odds with modern CPU design.
Developing Patterns in Enterprise Software
A personal survey of various efforts to catalog patterns for enterprise software development.
Ruby Rogues episode discussing P of EAA
The Ruby Rogues are a popular podcast where a regular panel discusses topics in the Ruby programming community. They have a regular book club and recently selected P of EAA as their featured book. Consequently they asked me to appear as a guest on their show to discuss the book and the patterns that it describes, in particular the interesting relationship between these patterns and the Rails framework.
Inversion of Control Containers and the Dependency Injection pattern
In the Java community there's been a rush of lightweight containers that help to assemble components from different projects into a cohesive application. Underlying these containers is a common pattern to how they perform the wiring, a concept they refer under the very generic name of “Inversion of Control”. In this article I dig into how this pattern works, under the more specific name of “Dependency Injection”, and contrast it with the Service Locator alternative. The choice between them is less important than the principle of separating configuration from use.
Dependency Composition
Based on frustrations with conventional framework-based dependency injection, I have adopted a composition strategy that utilizes partial application to inject context into modules. When combined with test-driven development as the design process and a focus on functions over classes, modules can be kept clear, clean, and mostly free of unintended coupling.
Errant Architectures
Software Development magazine adapted chapter 7 (Distribution Strategies) of my book Patterns of Enterprise Application Architecture as an article in their magazine. I suspect they liked it due to its tone and the inclusion of the First Law of Distributed Object Design.
Focusing on Events
A pattern narrative that looks at how events can be used as the focus for how a system operates and collaborates with peers. Summarizes how you represent events, how to use events to integrate between systems and using event sourcing in the architecture of a system.
GUI Architectures
Graphical User Interfaces provide a rich interaction between the user and a software system. Such richness is complex to manage, so it's important to contain that complexity with a thoughtful architecture. The Forms and Controls pattern works well for systems with a simple flow, but as it breaks down under the weight of greater complexity, most people turn to “Model-View-Controller” (MVC). Sadly MVC is one of the most misunderstood architectural patterns around, and systems using that name display a range of important differences, sometimes described under names like Application Model, Model-View-Presenter, Presentation Model, MVVM, and the like. The best way to think of MVC is as set of principles including the separation of presentation from domain logic and synchronizing presentation state through events (the observer pattern).
Organizing Presentation Logic
Narrative overview of patterns in user interfaces. Discusses how and why to separate domain logic from the presentation and how layers of data are separated and synchronized.
Foreword to Building Evolutionary Architectures

Recently my colleagues: Neal Ford, Rebecca Parsons, and Pat Kua, wrote a book entitled “Building Evolutionary Architectures”. I was honored that they asked me to write the foreword.
Reckoning with the force of Conway's Law
Conway's Law (formulated in 1968 by Melvin Conway) says that a system's design is constrained by the communication patterns of its designers. Birgitta, Mike, James, and I discuss the meaning of this principle and how we've seen it play out in our careers. We talk about its impact on the concept of Microservices, the importance of aligning with business capabilities, and the role of the inverse Conway maneuver.
Anemic Domain Model
This is one of those anti-patterns that's been around for quite a long time, yet seems to be having a particular spurt at the moment. I was chatting with Eric Evans on this, and we've both noticed they seem to be getting more popular. As great boosters of a proper Domain Model, this is not a good thing.
Application Boundary
One of the undecided problems of software development is deciding what the boundaries of a piece of software is. (Is a browser part of an operating system or not?) Many proponents of Service Oriented Architecture believe that applications are going away - thus future enterprise software development will be about assembling services together.
I don't think applications are going away for the same reasons why application boundaries are so hard to draw. Essentially applications are social constructions:
Architecture Decision Record
An Architecture Decision Record (ADR) is a short document that captures and explains a single decision relevant to a product or ecosystem. Documents should be short, just a couple of pages, and contain the decision, the context for making it, and significant ramifications. They should not be modified if the decision is changed, but linked to a superseding decision.
CQRS
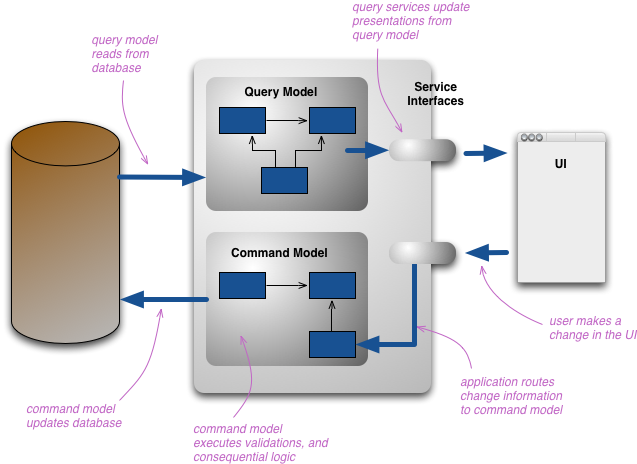
CQRS stands for Command Query Responsibility Segregation. It's a pattern that I first heard described by Greg Young. At its heart is the notion that you can use a different model to update information than the model you use to read information. For some situations, this separation can be valuable, but beware that for most systems CQRS adds risky complexity.
Circuit Breaker
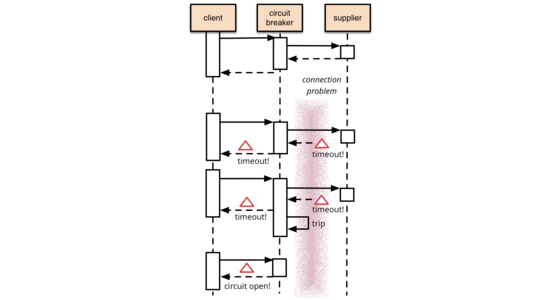
It's common for software systems to make remote calls to software running in different processes, probably on different machines across a network. One of the big differences between in-memory calls and remote calls is that remote calls can fail, or hang without a response until some timeout limit is reached. What's worse if you have many callers on a unresponsive supplier, then you can run out of critical resources leading to cascading failures across multiple systems. In his excellent book Release It, Michael Nygard popularized the Circuit Breaker pattern to prevent this kind of catastrophic cascade.
The basic idea behind the circuit breaker is very simple. You wrap a protected function call in a circuit breaker object, which monitors for failures. Once the failures reach a certain threshold, the circuit breaker trips, and all further calls to the circuit breaker return with an error, without the protected call being made at all. Usually you'll also want some kind of monitor alert if the circuit breaker trips.
Cloud Computing
“Cloud” has become a very over-hyped term over the last few years. One of the characteristics of over-hyped words is that they have little or no definition to them (yes NosqlDefinition I'm looking at you).
As it turns out there is an excellent definition of cloud computing available, from none other that NIST. It's available by a wonderfully short and easy to understand standards document (no, I'm not kidding).
Contextual Validation
In my writing endeavors, I've long intended to write a chunk of material on validation. It's an area that leads to a lot of confusion and it would be good to get some solid description of some of the techniques that work well. However life is full of things to write about, rather more than time allows.
Conway's Law
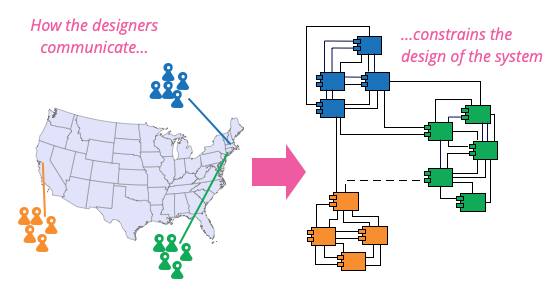
Pretty much all the practitioners I favor in Software Architecture are deeply suspicious of any kind of general law in the field. Good software architecture is very context-specific, analyzing trade-offs that resolve differently across a wide range of environments. But if there is one thing they all agree on, it's the importance and power of Conway's Law. Important enough to affect every system I've come across, and powerful enough that you're doomed to defeat if you try to fight it.
Domain Driven Design
Domain-Driven Design is an approach to software development that centers the development on programming a domain model that has a rich understanding of the processes and rules of a domain. The name comes from a 2003 book by Eric Evans that describes the approach through a catalog of patterns. Since then a community of practitioners have further developed the ideas, spawning various other books and training courses. The approach is particularly suited to complex domains, where a lot of often-messy logic needs to be organized.
Eager Read Derivation
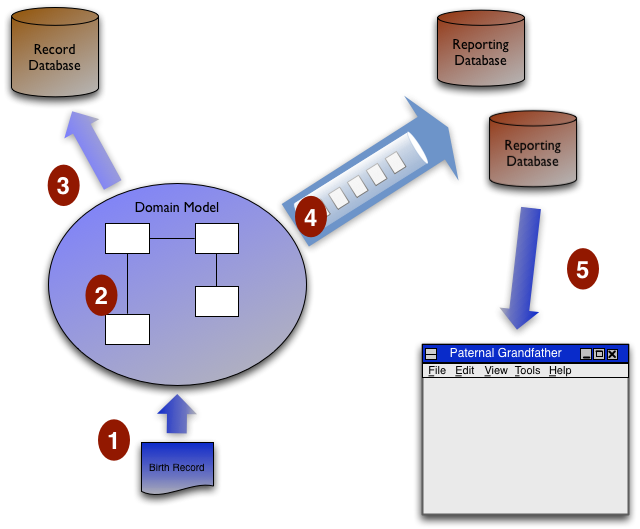
One of the interesting talks I attended at QCon San Francisco, was one given by Greg Young about a particular architecture he'd used on a recent system. Greg is a big fan of Domain Driven Design, in this case it needs to be used with a system that has to process a high transaction rate and provide data to lots of users. There were a number of things I found interesting about his design, particularly his use of Event Sourcing, but for this post I want to dwell on just one aspect - what I'll call Eager Read Derivation.
Editing Publishing Separation
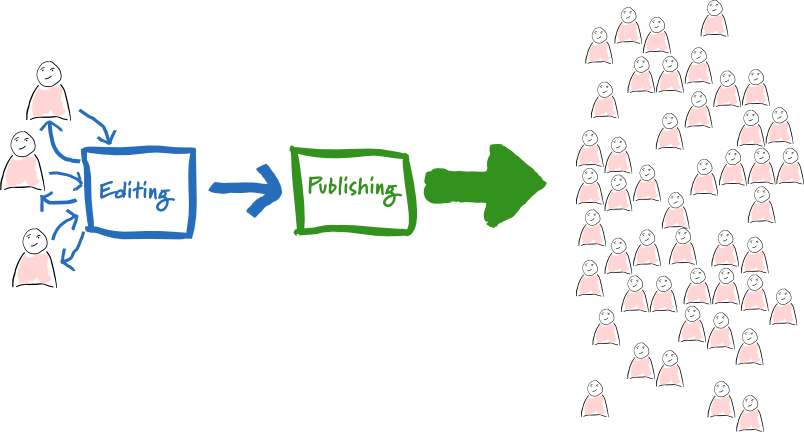
In my conversations with Thoughtworks project teams over the last year or so, a regular theme has been the growing impact of content management systems (CMS). They aren't usually seen as helpful, indeed there is a clear sign that they are becoming a worryingly invasive tool - used for more than their core purpose in such a manner that they hinder overall development.
Amongst the other irritations, a common failing is that they keep one copy of each article. This single copy is edited as part of creating the content and published to readers (usually on some kind of state-change flag).
Enterprise Application
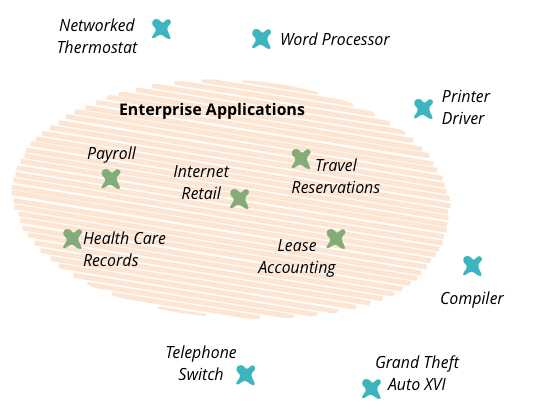
In the early part of this century, I worked on my book Patterns of Enterprise Application Architecture. One of the problems I had when writing the book was how to title it, or rather what to call the kinds of software systems that I was writing about. I've always been conscious that my experience of software development has always been focused on one particular form of software - things like health care records, foreign exchange trading, payroll, and lease accounting. These are very different to embedded software inside printers, games, flight control software, or telephone switches. I needed a name to describe these kinds of systems and settled on the term “enterprise application”.
Enterprise Architecture
Just recently I've picked up a couple of bad reviews on Amazon for P of EAA because there is nothing in the book about enterprise architecture. Of course there's a good reason for that - the book is about enterprise application architecture, that is how to design enterprise applications. Enterprise architecture is a different topic, how to organize multiple applications in an enterprise into a coherent whole.
Event Poster
This a style of application I've come across a couple of times. The application is primarily a reporting application that gives users real time information about the state of something. It is an active application, in that the users have a lot of control about what kinds of things they are looking at they're able to drill down in particular areas and generally manipulate their display; however it is still, at least primarily a read-only application.
Expositional Architecture
One of the problems with growing our understanding of software systems is that we don't see enough examples. In many professional disciplines, people learn by looking at what's already been done. Examples serve as inspiration, a source of good ideas, and warnings of difficulties. For a long time it's been much harder to learn about software this way.
Fixed Length String
Look at most libraries that talk between application programming languages and relational databases, and you'll notice that they map the string type in the database (char or varchar) to a string type in the programming language. Simple, obvious, but perhaps it's wrong.
Internal Reprogrammability
I was programming away and wanted to add an empty line above where I was currently typing. The editor I was using doesn't have this feature built-in, and I'd finally had this desire enough that I really wanted it. I did a quick google search, found a few lines of code, pasted them into my startup file, executed them, and lo I could now create empty lines above with a single keystroke. It took just a couple of minutes, I didn't have to install any plugins, or restart the editor - this is normal everyday business for an Emacs user.
Inversion Of Control
Inversion of Control is a common phenomenon that you come across when extending frameworks. Indeed it's often seen as a defining characteristic of a framework.
Keystone Interface
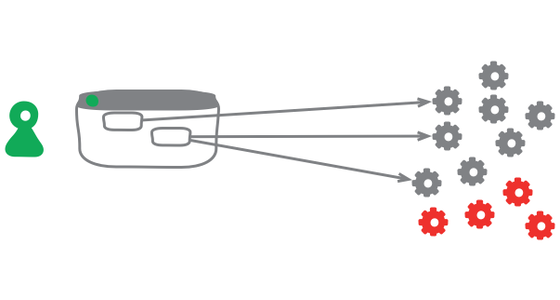
Software development teams find life can be much easier if they integrate their work as often as they can. They also find it valuable to release frequently into production. But teams don't want to expose half-developed features to their users. A useful technique to deal with this tension is to build all the back-end code, integrate, but don't build the user-interface. The feature can be integrated and tested, but the UI is held back until the end until, like a keystone, it's added to complete the feature, revealing it to the users.
Layering Principles
For the last few days I've been attending a workshop on enterprise software in Norway, hosted by Jimmy Nilsson. During the workshop we had a session where we came up and voted on a bunch of design principles.
Local D T O
If you've been keeping an eye on my fellow ThoughtBloggers you'll know that it seems one of my fowlbots has blown a fuse, the Australian sun obviously frizzles these Swedish models.
Jon's annoyed with Data Transfer Objects, but it's not that DTOs are a bad thing, just like any pattern they are useful in a certain context. Patterns always have two parts: the how and the when. Not just do you need to know how to implement them, you also have to know when to use them and when to leave them alone.
Lock In Cost

In my recent client engagement, I foresaw that serverless architecture was a perfect fit. The idea of adopting serverless architecture, though, didn’t fly to our client well due to the fear of vendor lock-in. It was an interesting time for retailers as staying in AWS might mean that Amazon, as another retail business, will be given a competitive advantage. Given the idea of not supporting a competitor, my client was interested to ensure that the solution chosen by us is fully portable to other cloud vendors.
Memory Image
When people start an enterprise application, one of the earliest questions is “how do we talk to the database”. These days they may ask a slightly different question “what kind of database should we use - relational or one of these NOSQL databases?”. But there's another question to consider: “should we use a database at all?”
Orm Hate
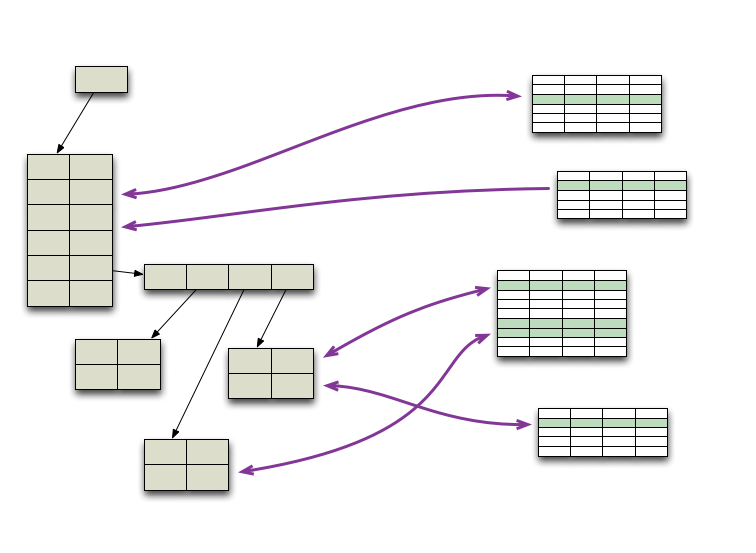
While I was at the QCon conference in London a couple of months ago, it seemed that every talk included some snarky remarks about Object/Relational mapping (ORM) tools. I guess I should read the conference emails sent to speakers more carefully, doubtless there was something in there telling us all to heap scorn upon ORMs at least once every 45 minutes. But as you can tell, I want to push back a bit against this ORM hate - because I think a lot of it is unwarranted.
Polyglot Persistence
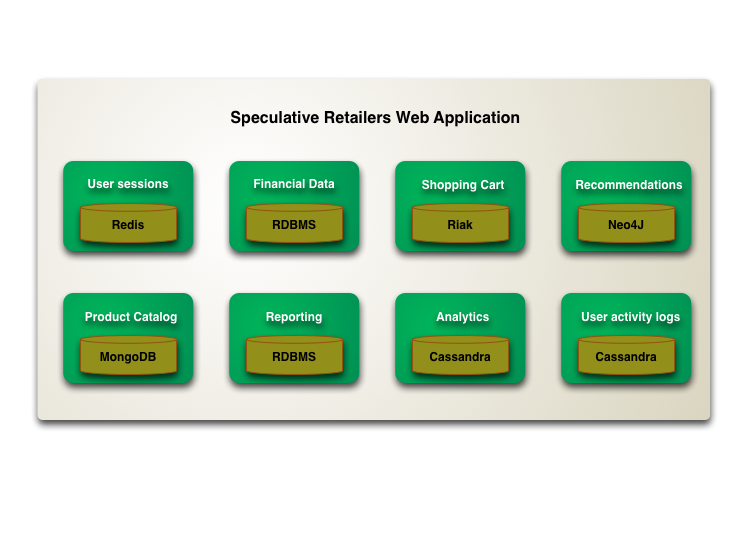
In 2006, my colleague Neal Ford coined the term Polyglot Programming, to express the idea that applications should be written in a mix of languages to take advantage of the fact that different languages are suitable for tackling different problems. Complex applications combine different types of problems, so picking the right language for the job may be more productive than trying to fit all aspects into a single language.
Over the last few years there's been an explosion of interest in new languages, particularly functional languages, and I'm often tempted to spend some time delving into Clojure, Scala, Erlang, or the like. But my time is limited and I'm giving a higher priority to another, more significant shift, that of the DatabaseThaw. The first drips have been coming through from clients and other contacts and the prospects are enticing. I'm confident to say that if you starting a new strategic enterprise application you should no longer be assuming that your persistence should be relational. The relational option might be the right one - but you should seriously look at other alternatives.
Presentation Domain Data Layering
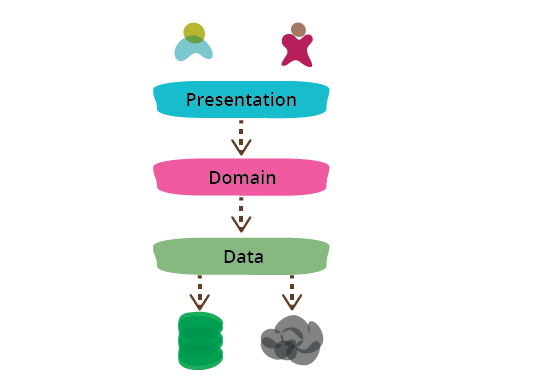
One of the most common ways to modularize an information-rich program is to separate it into three broad layers: presentation (UI), domain logic (aka business logic), and data access. So you often see web applications divided into a web layer that knows about handling HTTP requests and rendering HTML, a business logic layer that contains validations and calculations, and a data access layer that sorts out how to manage persistent data in a database or remote services.
Presentation Domain Separation
One of the most useful design principles that I've found and followed is that of keeping a good separation between the presentation aspects of a program (the user interface) and the rest of the functionality. Over the years where I've seen this done, I've seen plenty of benefits:
Published Interface
Published Interface is a term I used (first in Refactoring) to refer to a class interface that's used outside the code base that it's defined in. As such it means more than public in Java and indeed even more than a non-internal public in C#. In my column for IEEE Software I argued that the distinction between published and public is actually more important than that between public and private.
Reporting Database
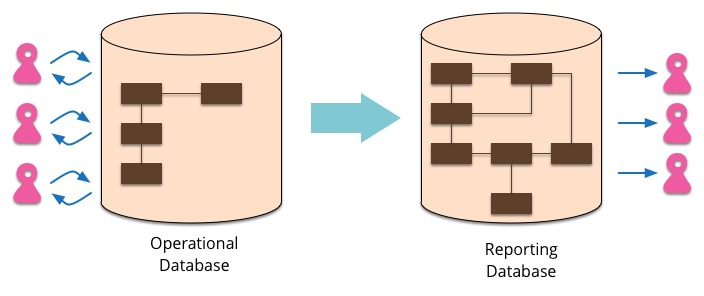
Most EnterpriseApplications store persistent data with a database. This database supports operational updates of the application's state, and also various reports used for decision support and analysis. The operational needs and the reporting needs are, however, often quite different - with different requirements from a schema and different data access patterns. When this happens it's often a wise idea to separate the reporting needs into a reporting database, which takes a copy of the essential operational data but represents it in a different schema.
Request Stream Map
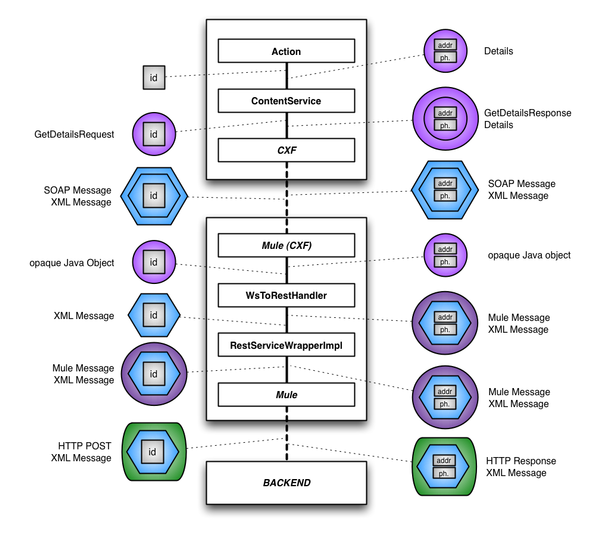
Hang around my colleagues at Thoughtworks and you soon get the impression that the only good Enterprise Service Bus (ESB) is a dead ESB. Jim Webber refers to them as Erroneous Spaghetti Boxes. So it's not uncommon to hear tales of attempts to get them out of systems that don't need them.
Resource Pool
Many programs need to make use of resources that are expensive to create and maintain. Examples of these are database connections and threads. A resource pool provides a good way to manage these resources.
Sacrificial Architecture
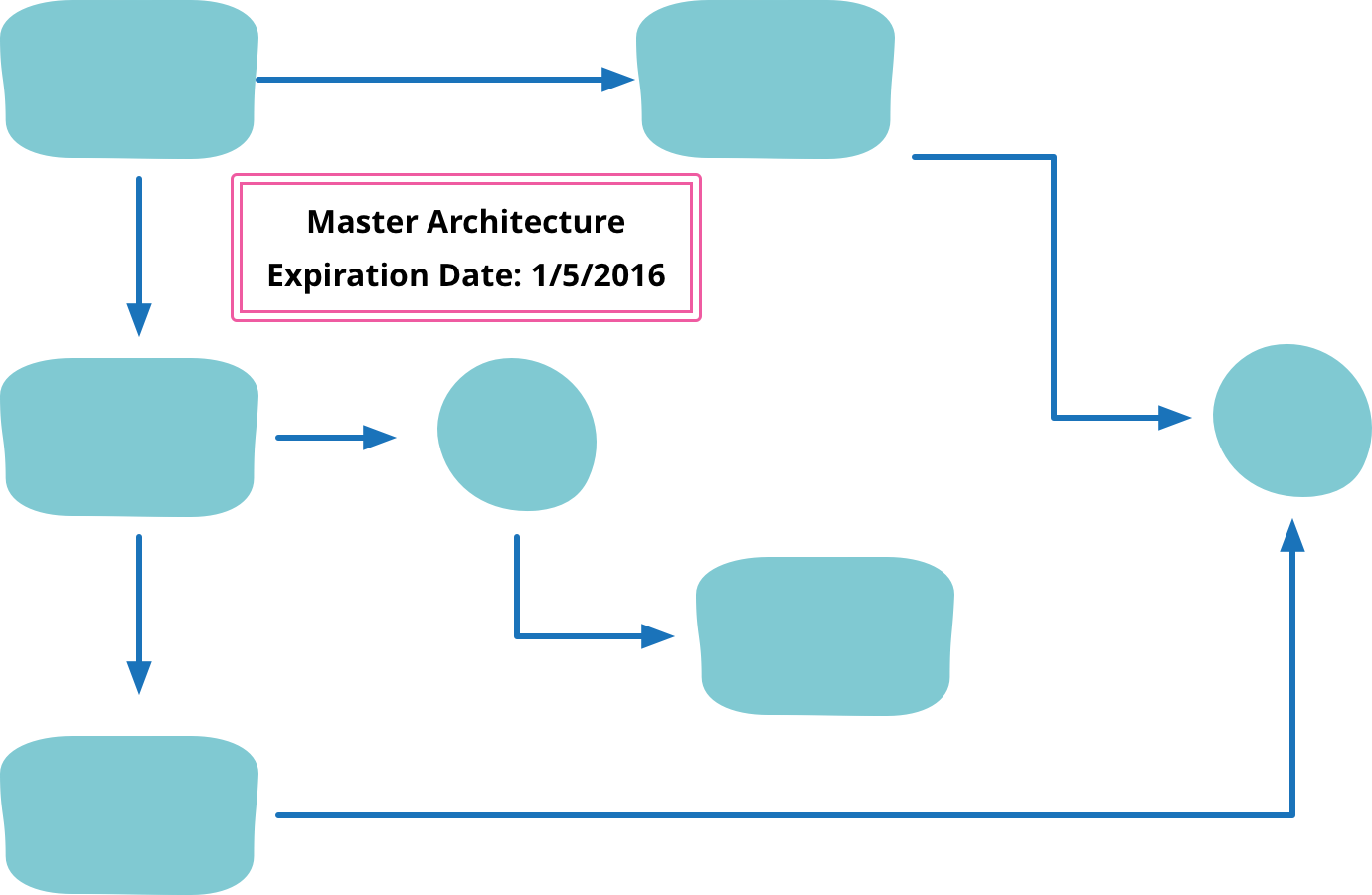
You're sitting in a meeting, contemplating the code that your team has been working on for the last couple of years. You've come to the decision that the best thing you can do now is to throw away all that code, and rebuild on a totally new architecture. How does that make you feel about that doomed code, about the time you spent working on it, about the decisions you made all that time ago?
Serverless
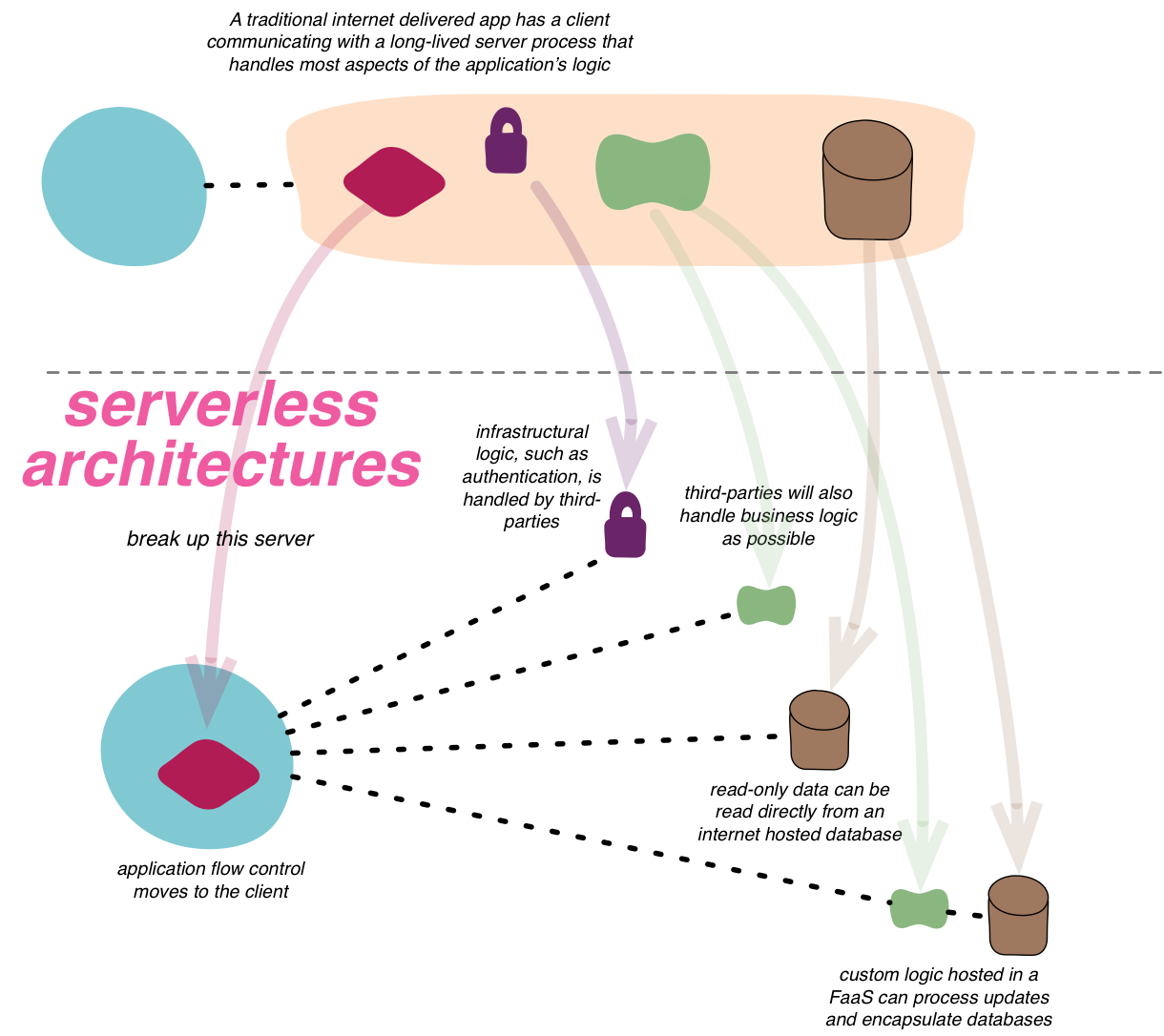
Serverless architectures are internet based systems where the application development does not use the usual server process. Instead they rely solely on a combination of third-party services, client-side logic, and service hosted remote procedure calls (FaaS).
Software Component
The notion of changing software development from laboriously crafting code to building powerful systems by simple assembly of components has been a target since I entered our profession. It's target that is sometimes glimpsed, but never really attained - although many technologies have dangled the carrot of industrial reuse.
Static Substitution
As I listen to our development teams talk about their work, one common theme is their dislike of things held in statics. Typically we see common services or components held in static variables with static initializers. One of the big problems with statics (in most languages) is you can't use polymorphism to substitute one implementation with another. This bits us a lot because we are great fans of testing - and to test well it's important to be able to replace services with a Service Stub.
Strangler Fig

During a vacation in the rain forests of Queensland in 2001, we saw some strangler figs. These are vines that germinate in a nook of a tree. As it grows, it draws nutrients from the host tree until it reaches the ground to grow roots and the canopy to get sunlight. It can then become self-sustaining, and its original host tree may die leaving the fig as an echo of its shape. This gradual process of replacing the host tree struck me as a striking analogy to the way I saw colleagues doing modernization of legacy software systems. A couple of years later I posted a brief blog post about this metaphor. While I've not used the term in my writing since then, it caught attention anyway, and the term “Strangler Fig” is now often used to describe a gradual approach to legacy modernization.
Sunk Cost Driven Architecture
I find this to be a sadly common architectural style. Your company buys some very expensive piece of infrastructure software. You are then told you must use it on a project even if it's not suitable for the project and causes you extra effort. After paying all that money for it you don't want it to go to waste do you?
Trans Media Application
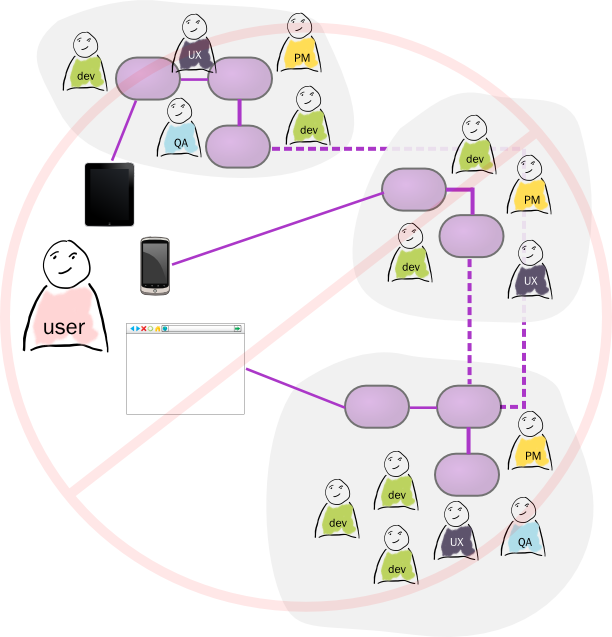
Mobile applications have been a hot item in software development over the past couple of years. Like many software delivery companies, Thoughtworks get a lot of requests from clients asking us to build a mobile application for them. However most of the time a company asks us (or anyone) to build a mobile application they are starting off on the wrong foot. I'd argue that for most situations, even though you want users to interact with a mobile device, you should never think of building a mobile application. Instead you need to think about building a single application that presents across multiple devices: mobile, desktop, tablet - or whatever device your users might use.
Transactionless
A couple of years ago I was talking to a couple of friends of mine who were doing some work at eBay. It's always interesting to hear about the techniques people use on high volume sites, but perhaps one of the most interesting tidbits was that eBay mostly hardly ever uses database transactions.
Ui Patterns Readings
In the summer of 2006 I did a major chunk of work on UI patterns. Since then they've been very much on ice as my primary writing focus has shifted (although not very visibly) to DomainSpecificLanguages. On this page I'll keep a note of links to writings I've liked that are connected with that work.
User Defined Field
A common feature in software systems is to allow users to define their own fields in data structures. Consider an address book - there's a host of things that you might want to add. With new social networks popping up every day, users might want to add a new field for a Bunglr id to their contacts.