
tagged by: noSQL
Introduction to NoSQL

At goto Aarhus, we had a track on some practical experiences with NoSQL. I was asked to give an initial talk to explain the basic principles of NoSQL datastores. I talk about the origins of NoSQL, forms of NoSQL data models, the way many NoSQL databases consider the problem of consistency, and the importance of Polyglot Persistence.
Schemaless Data Structures

In recent years, there's been an increasing amount of talk about the advantages of schemaless data. Being schemaless is one of the main reasons for interest in NoSQL databases. But there are many subtleties involved in schemalessness, both with respect to databases and in-memory data structures. These subtleties are present both in the meaning of schemaless and in the advantages and disadvantages of using a schemaless approach.
Key Points from NoSQL Distilled
When we designed the book, NoSQL Distilled, we concluded most chapters with some summary key points to act as a refresher for people re-reading the book. We've included these on the website as another way for readers to remind themselves of these key points.
The People vs. NoSQL Databases: Panel Discussion
One of the tracks at goto Aarhus gave NoSQL vendors the chance to talk about their various tools. At the end of the track the various speakers were put on a panel to discuss some of the common issues involving NoSQL. Although I wasn't involved in the track (my talk came a couple of days later) I was involved on the panel.
The Evolving Panorama of Data
Our keynote at QCon London 2012 looks at the role data is playing in our lives (and that it's doing more than just getting bigger). We start by looking at how the world of data is changing: its growing, becoming more distributed and connected. We then move to the industry's response: the rise of NoSQL, the shift to service integration, the appearance of event sourcing, the impact of clouds and new analytics with a greater role for visualization. We take a quick look at how data is being used now, with a particular emphasis from Rebecca on data in the developing world. Finally we consider what does all this mean to our personal responsibilities as software professionals.
The Future is not NoSQL but Polyglot Persistence
An infodeck on the future of data storage in the enterprise, written primarily for those involved in the management of application development. Explains why relational databases have been the dominant, why NoSQL is challenging this assumption and sketches out the future of Polyglot Persistence, where multiple data storage technologies will be used for applications depending on their varied needs.
Aggregate Oriented Database
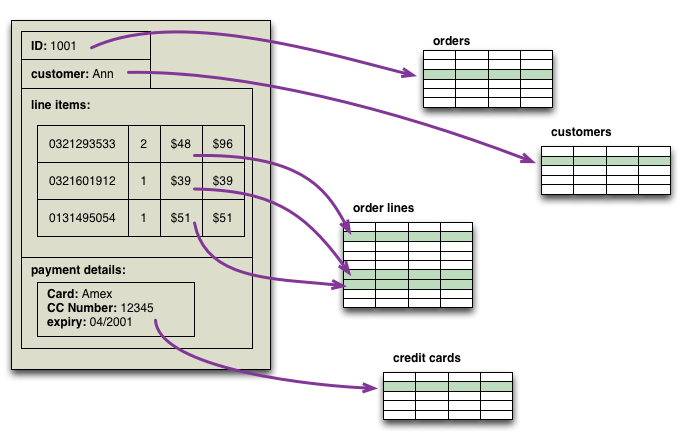
One of the first topics to spring to mind as we worked on Nosql Distilled was that NoSQL databases use different data models than the relational model. Most sources I've looked at mention at least four groups of data model: key-value, document, column-family, and graph. Looking at this list, there's a big similarity between the first three - all have a fundamental unit of storage which is a rich structure of closely related data: for key-value stores it's the value, for document stores it's the document, and for column-family stores it's the column family. In DDD terms, this group of data is an DDD_Aggregate.
Database Thaw
A few years ago I heard programming language people talk about the “Nuclear Winter” in languages caused by Java. The feeling was that everyone had so converged on Java's computational model (C# at that point seen as little more than a rip-off) that creativity in programming languages had disappeared. That feeling is now abating, but perhaps a more important thaw that might be beginning - the longer and deeper freeze in thinking about databases.
Embedded Document
Flowing JSON data structures through a server is something I'm seeing more these days. JSON documents can be persisted directly, either by using an AggregateOrientedDatabase or a serialized LOB in a relational database. JSON documents can also be served directly to web browsers or used to transfer data to server-side page renderers. When JSON is being used in this way, I hear people saying that using an object-oriented language gets in the way because the JSON needs to be translated into objects only to be rendered out again - a waste of programming effort . I agree with the point about waste, but I argue that it's not a problem with objects but a failure to understand encapsulation.
No DBA

In many organizations, it's expected that any persistent data will be stored in relational databases that are managed by a central database management group. There are various reasons for such central control, usually centered around using IntegrationDatabases. Central data groups worry about keeping out malformed data, queries that can slow down important shared resources, and consistent data models across the enterprise.
Worthy these aims may be, but one consequence of them is considerable ceremony about storing data. I often hear complaints about change orders that take weeks to add a column to a database. For modern application developers, used to short-cycle evolutionary design, such ceremony is too slow, not to mention too annoying.
So application development groups tell me of using NoSQL databases to do an end-run around the DBAs. It helps that they are using a “mere datastore” here, not a “proper database”. That way the DBAs can be kept out of the loop, often not told or happy to not care.
Nosql Definition
As soon as we started work on Nosql Distilled we were faced with a tricky conundrum - what are we writing about? What exactly is a NoSQL database? There's no strong definition of the concept out there, no trademarks, no standard group, not even a manifesto.
Polyglot Persistence
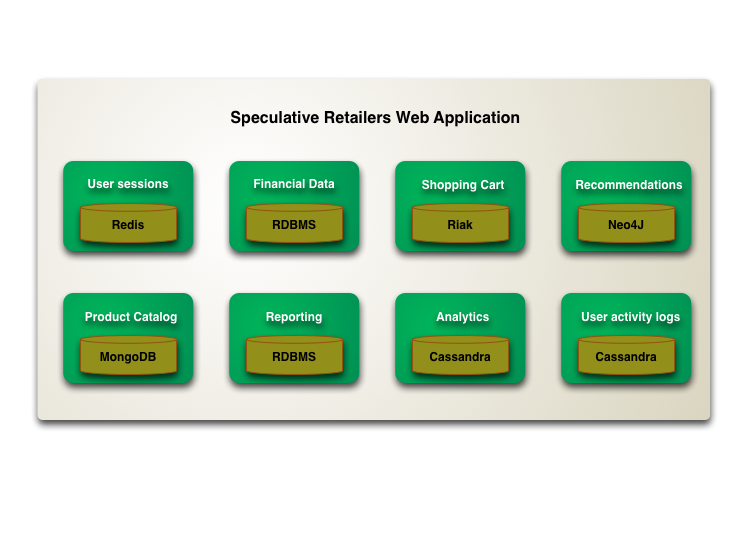
In 2006, my colleague Neal Ford coined the term Polyglot Programming, to express the idea that applications should be written in a mix of languages to take advantage of the fact that different languages are suitable for tackling different problems. Complex applications combine different types of problems, so picking the right language for the job may be more productive than trying to fit all aspects into a single language.
Over the last few years there's been an explosion of interest in new languages, particularly functional languages, and I'm often tempted to spend some time delving into Clojure, Scala, Erlang, or the like. But my time is limited and I'm giving a higher priority to another, more significant shift, that of the DatabaseThaw. The first drips have been coming through from clients and other contacts and the prospects are enticing. I'm confident to say that if you starting a new strategic enterprise application you should no longer be assuming that your persistence should be relational. The relational option might be the right one - but you should seriously look at other alternatives.