
tagged by: testing
Testing Strategies in a Microservice Architecture
There has been a shift in service based architectures over the last few years towards smaller, more focussed “micro” services. There are many benefits with this approach such as the ability to independently deploy, scale and maintain each component and parallelize development across multiple teams. However, once these additional network partitions have been introduced, the testing strategies that applied for monolithic in process applications need to be reconsidered. Here, we plan to discuss a number of approaches for managing the additional testing complexity of multiple independently deployable components as well as how to have tests and the application remain correct despite having multiple teams each acting as guardians for different services.
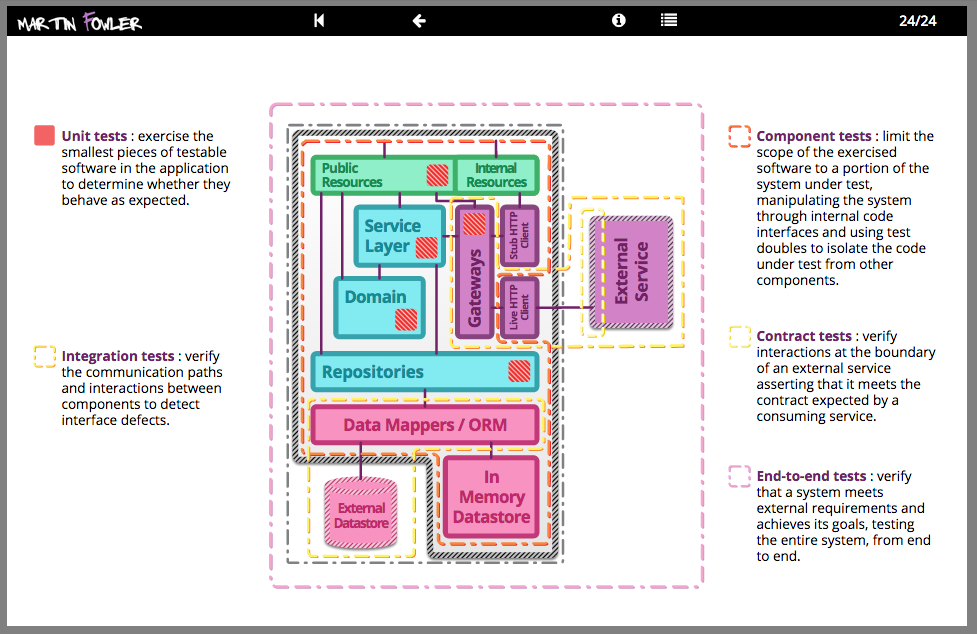
The Practical Test Pyramid

The “Test Pyramid” is a metaphor that tells us to group software tests into buckets of different granularity. It also gives an idea of how many tests we should have in each of these groups. Although the concept of the Test Pyramid has been around for a while, teams still struggle to put it into practice properly. This article revisits the original concept of the Test Pyramid and shows how you can put this into practice. It shows which kinds of tests you should be looking for in the different levels of the pyramid and gives practical examples on how these can be implemented.
Is TDD Dead?
David Heinemeier Hansson, the creator of Ruby on Rails, gave a keynote at RailsConf where he declared that TDD is Dead. This caused a predictably large amount of controversy in both the Rails and wider software development community. It also led to some interesting conversations between David, Kent, and myself. We decided that these conversations were interesting enough that others might like to watch them too, so recorded a series of video hangouts where we discuss the role of TDD in software development.
Domain-Oriented Observability
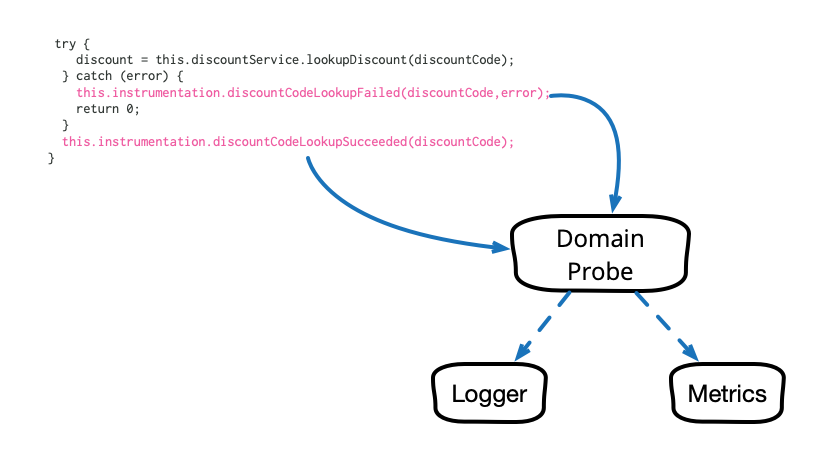
Observability in our software systems has always been valuable and has become even more so in this era of cloud and microservices. However, the observability we add to our systems tends to be rather low level and technical in nature, and too often it seems to require littering our codebase with crufty, verbose calls to various logging, instrumentation, and analytics frameworks. This article describes a pattern that cleans up this mess and allows us to add business-relevant observability in a clean, testable way.
Goto Fail, Heartbleed, and Unit Testing Culture
Two computer security flaws were discovered in early 2014: Apple’s “goto fail” bug and OpenSSL’s “Heartbleed” bug. Both had the potential for widespread and severe security failures, the full extent of which we may never know. Given their severity, it is important for the software development profession to reflect on how they could have been detected so we can improve our ability to prevent these kinds of defects in the future. This article considers the role unit testing could play, showing how unit tests, and more importantly a unit testing culture, could have identified these particular bugs. It goes on to look at the costs and benefits of such a culture and describes how such a culture was instilled at Google.
Eradicating Non-Determinism in Tests
An automated regression suite can play a vital role on a software project, valuable both for reducing defects in production and essential for evolutionary design. In talking with development teams I've often heard about the problem of non-deterministic tests - tests that sometimes pass and sometimes fail. Left uncontrolled, non-deterministic tests can completely destroy the value of an automated regression suite. In this article I outline how to deal with non-deterministic tests. Initially quarantine helps to reduce their damage to other tests, but you still have to fix them soon. Therefore I discuss treatments for the common causes for non-determinism: lack of isolation, asynchronous behavior, remote services, time, and resource leaks.
Demo Front-End
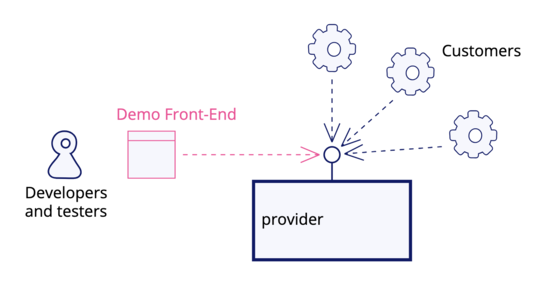
Have you ever attended a “demo” where developers were proudly showing screen after screen of JSON output from their API, while users were confused and distracted, unable to make any sense of it? Have you ever tried to use an API in development, and been frustrated by how difficult it is to find the correct JSON payload and header incantations to be able to test a feature? A Demo Front-End is a simple UI that provides basic features to demonstrate and explore such an API.
Engineering Practices for LLM Application Development

LLM engineering involves much more than just prompt design or prompt engineering. In this article, we share a set of engineering practices that helped us deliver a prototype LLM application rapidly and reliably in a recent project. We'll share techniques for automated testing and adversarial testing of LLM applications, refactoring, as well as considerations for architecting LLM applications and responsible AI.
Mocks Aren't Stubs
The term 'Mock Objects' has become a popular one to describe special case objects that mimic real objects for testing. Most language environments now have frameworks that make it easy to create mock objects. What's often not realized, however, is that mock objects are but one form of special case test object, one that enables a different style of testing. In this article I'll explain how mock objects work, how they encourage testing based on behavior verification, and how the community around them uses them to develop a different style of testing.
Testing Asynchronous JavaScript
There seems to be a common misconception in the JavaScript community that testing asynchronous code requires a different approach than testing ‘regular’ synchronous code. In this post I’ll explain why that’s not generally the case. I’ll highlight the difference between testing a unit of code which supports async behavior, as opposed code which is inherently asynchronous. I’ll also show how promise-based async code lends itself to clean and succinct unit tests which can be tested in a clear, readable way while still validating async behaviour.
Continuous Delivery
We give a one-hour overview of Continuous Delivery. Topics include the justification of Continuous Delivery, the deployment pipeline, continuous integration, devops, and deployment strategies. The highlight is Jez's personification of a release candidate as a hero in a greek myth.
Modern Mocking Tools and Black Magic
The positive effect modern mocking tools can have on our ability to work with legacy code and the possible negative implications of using those tools.
QA in Production
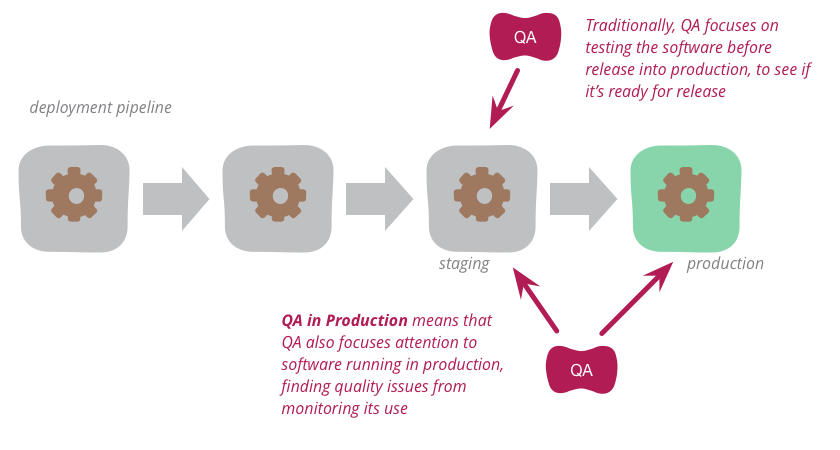
Traditionally, QA focuses on testing the software before release into production to see if it's ready for such release. But increasingly, modern QA organizations are also focusing attention onto the software running in production. By analyzing logs and other monitoring tools, they find quality problems to highlight to the development organization. This approach works particularly well with organizations that use continuous delivery to put new versions of the software into production rapidly and reliably.
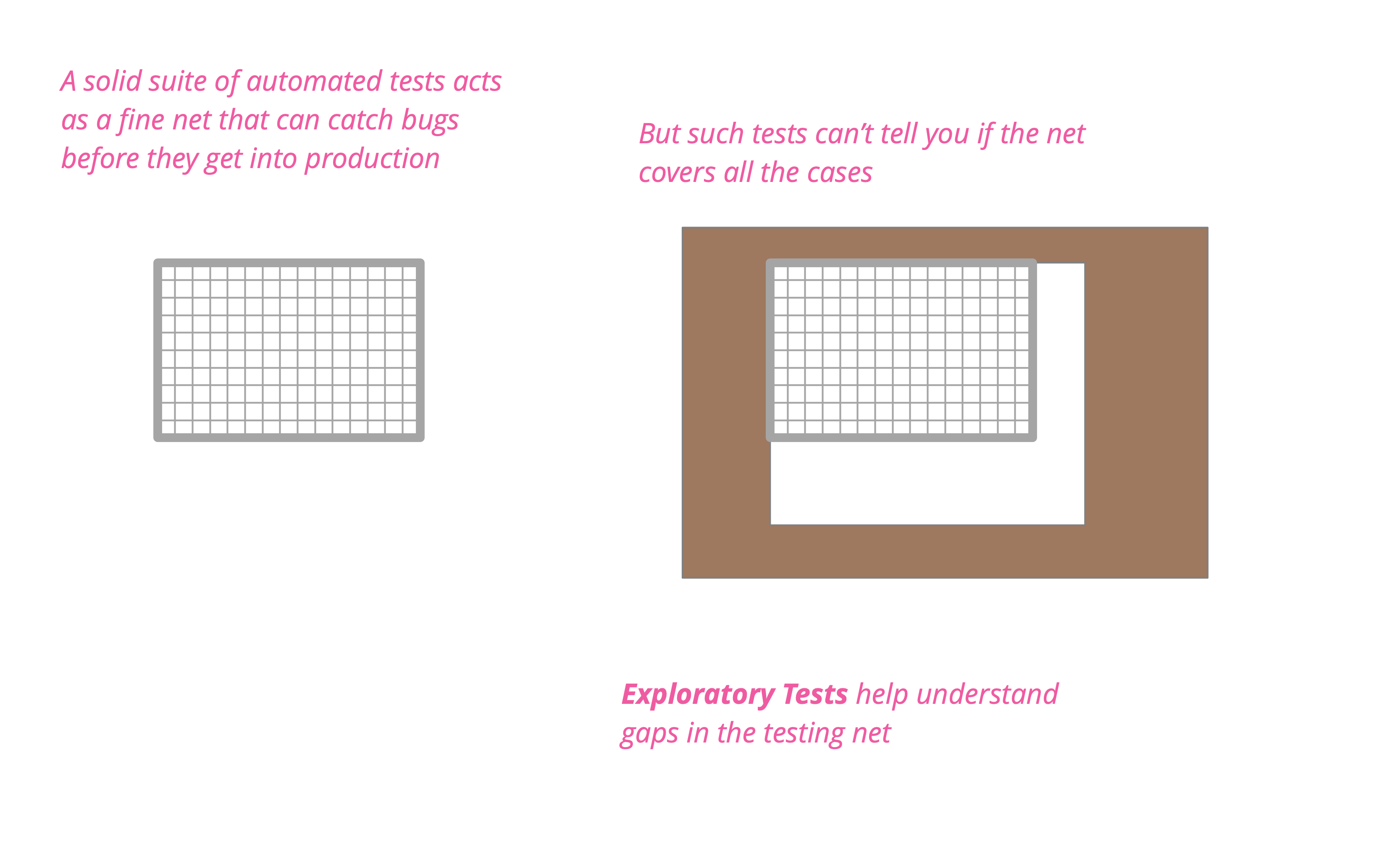
The Rise of Test Impact Analysis
Test Impact Analysis (TIA) is a modern way of speeding up the test automation phase of a build. It works by analyzing the call-graph of the source code to work out which tests should be run after a change to production code. Microsoft has done some extensive work on this approach, but it's also possible for development teams to implement something useful quite cheaply.
Agiledox
My colleague Joe Walnes pointed me to a fascinatingly simple tool developed by our colleague Chris Stevenson. TextDox (part of AgileDox) is a tool to automatically generate documentation from JUnit test cases. Sounds ridiculous, but then that's what Wardish ideas are like.
Assertion Free Testing
Here's a story from a friend of a friend. I'm sure it must be true, at least somewhere.
Clock Wrapper
If you need to get the current date or time in your code, don't access the system routines for that data directly. Put some form of wrapper around it that allows you to override it by setting the “current date/time” to a particular value. This is important to simplify testing.
Database And Build Time
Here's an interesting contrast I recently picked up. Two enterprise application projects of a similar size (~100 KLOC), similar environments (Java and .NET). One can do a full build and test in an hour, the other takes 2-3 minutes.
Detestable
(Here's an addition to your dictionary.)
Detestable (adjective): software that isn't testable.
Erratic Test Failure
I was working on some of my book example code the other day. I made some changes, got everything working, ran tests, and committed it to my personal repository. I then moved over to a different area and made a couple of changes - and some unexpected tests broke in the previous area. Now part of the point of running automated tests is to find unexpected breaks, but this book code has completely independent areas. This was odd.
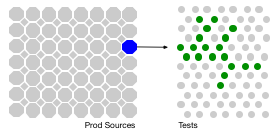
Exploratory Testing
Exploratory testing is a style of testing that emphasizes a rapid cycle of learning, test design, and test execution. Rather than trying to verify that the software conforms to a pre-written test script, exploratory testing explores the characteristics of the software, raising discoveries that will then be classified as reasonable behavior or failures.
Given When Then
Given-When-Then is a style of representing tests - or as its advocates would say - specifying a system's behavior using SpecificationByExample. It's an approach developed by Daniel Terhorst-North and Chris Matts as part of Behavior-Driven Development (BDD). It appears as a structuring approach for many testing frameworks such as Cucumber. You can also look at it as a reformulation of the Four-Phase Test pattern.
Humble Object
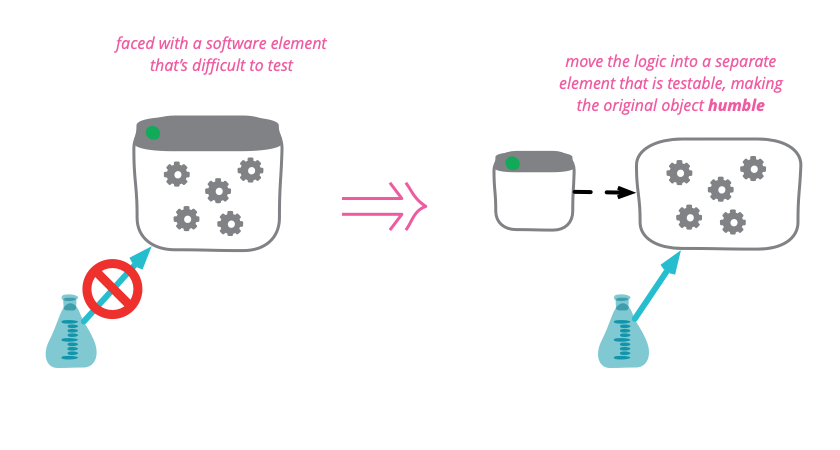
Some program elements are inherently difficult, or even impossible to test. Any logic in these elements is thus prone to bugs and difficult to evolve. To mitigate this problem, move as much as logic as possible out of the hard-to-test element and into other more friendly parts of the code base. By making untestable objects humble , we reduce the chances that they harbor evil bugs.
In Memory Test Database
An in-memory database is a database that runs entirely in main memory, without touching a disk. Often they run as an embedded database: created when a process starts, running embedded within that process, and is destroyed when the process finishes.
Junit New Instance
I often get questions that surround one of the design choices in the JUnit testing framework - the decision to make a new object for each test method run. Enough to warrant a quick bliki entry. (However I feel almost compelled to point out that my writing about JUnit does not mean that that I don't think that other forms of testing are important. There are lots of useful testing activities, and although JUnit and its cousins are valuable for many of them it isn't the solution for everything. For more blogging on testing I suggest you look at the blogs of Brett Pettichord, Brian Marick, and James Bach. You should also not assume that my writing about xUnit testing implies suggests the unimportance of refactoring, use cases, or flossing.)
Legacy Seam
When working with a legacy system it is valuable to identify and create seams: places where we can alter the behavior of the system without editing source code. Once we've found a seam, we can use it to break dependencies to simplify testing, insert probes to gain observability, and redirect program flow to new modules as part of legacy displacement.
Making Stubs
A common problem with test-enhanced designs is how to create Service Stubs in test mode while letting the real thing be there for production (and for some tests). A couple of my colleagues have shared their ideas.
Nashville Project
I spent some time recently with one of my favorite ever Thoughtworks projects. It's a project that started in 1998, using then new J2EE technology. Over the years it's had a fascinating history: starting with EJBs, ripping them out, going offshore to Bangalore, coming back to Chicago. Many people have moved in and out of the project and the project has varied in head-count between 6 and 60. Overall the project has had over 300 staff-years of effort on it and weighs in at around 100 KLOC.
Object Mother
An object mother is a kind of class used in testing to help create example objects that you use for testing.
Page Object
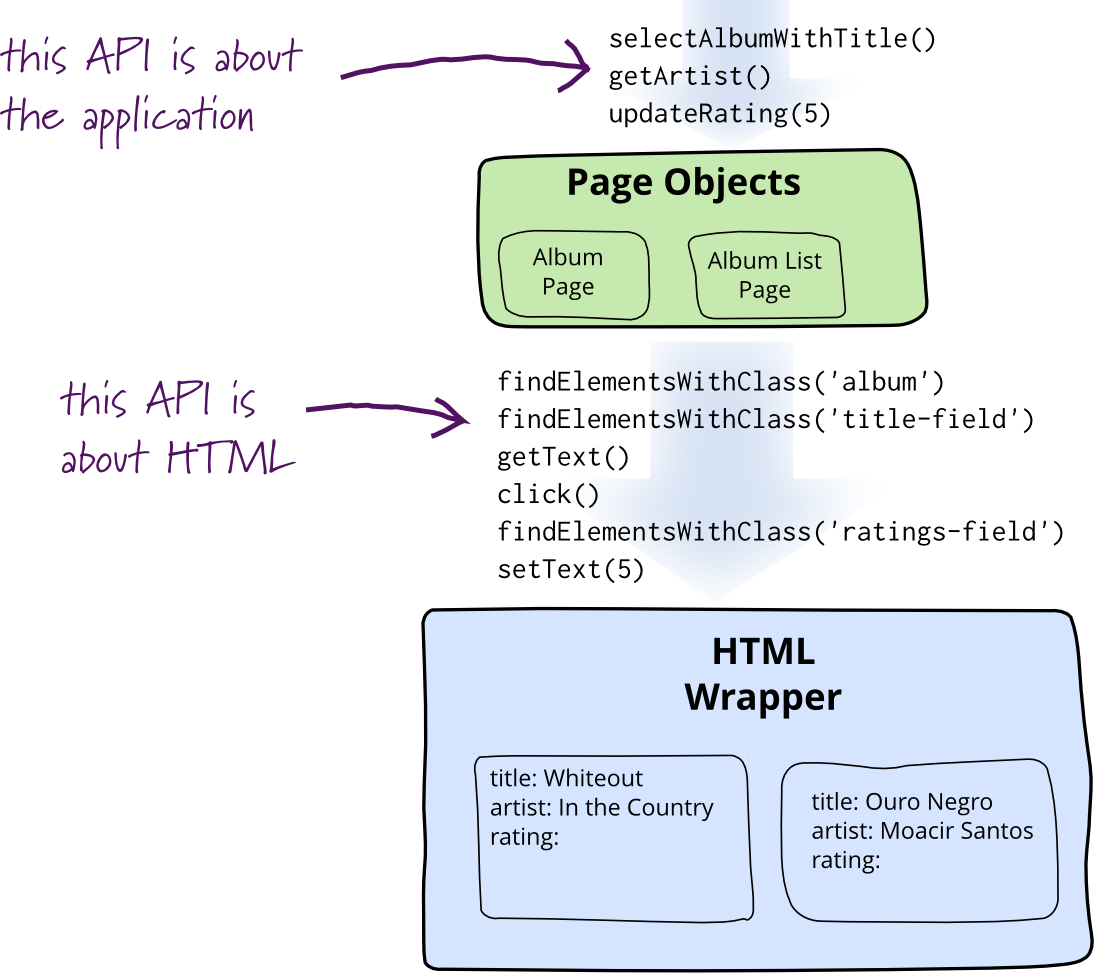
When you write tests against a web page, you need to refer to elements within that web page in order to click links and determine what's displayed. However, if you write tests that manipulate the HTML elements directly your tests will be brittle to changes in the UI. A page object wraps an HTML page, or fragment, with an application-specific API, allowing you to manipulate page elements without digging around in the HTML.
Self Initializing Fake
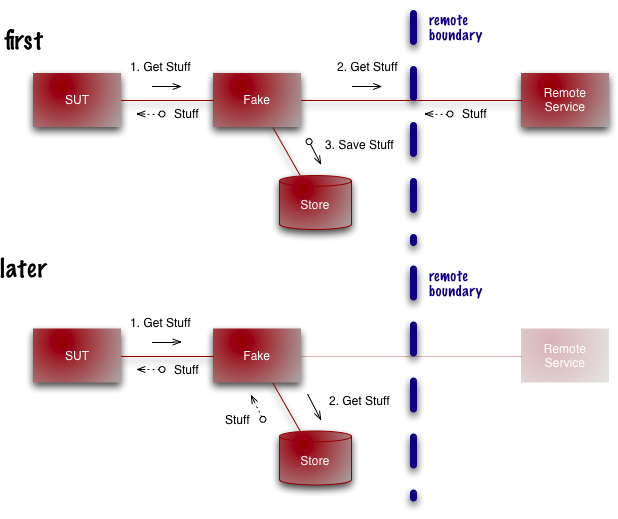
One of the classic cases for using a TestDouble is when you call a remote service. Remote services are usually slow and often unreliable, so using a double is a good way to make your tests faster and more stable.
Self Testing Code

Self-Testing Code is the name I used in Refactoring to refer to the practice of writing comprehensive automated tests in conjunction with the functional software. When done well this allows you to invoke a single command that executes the tests - and you are confident that these tests will illuminate any bugs hiding in your code.
Specification By Example
I was attending a workshop at XP/Agile Universe in 2002 when the phrase 'Specification By Example' struck me as a way to describe one of roles of testing in XP.
Static Substitution
As I listen to our development teams talk about their work, one common theme is their dislike of things held in statics. Typically we see common services or components held in static variables with static initializers. One of the big problems with statics (in most languages) is you can't use polymorphism to substitute one implementation with another. This bits us a lot because we are great fans of testing - and to test well it's important to be able to replace services with a Service Stub.
Synthetic Monitoring
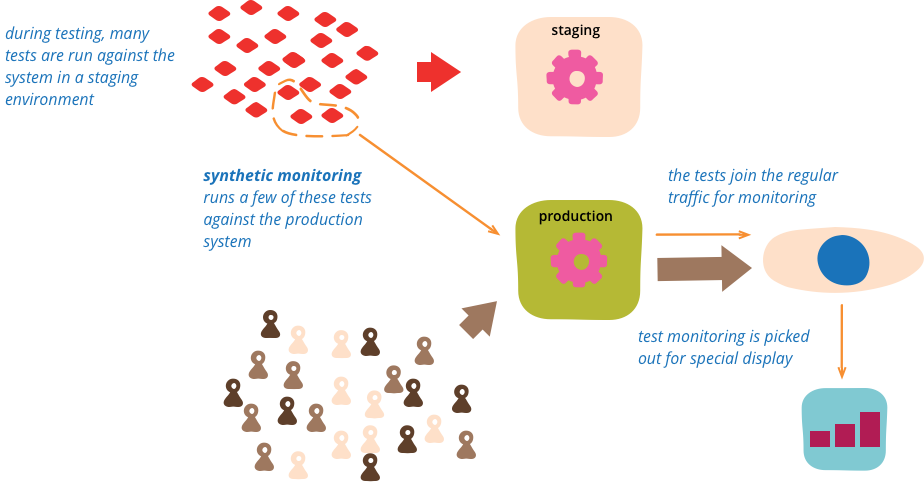
Synthetic monitoring (also called semantic monitoring ) runs a subset of an application's automated tests against the live production system on a regular basis. The results are pushed into the monitoring service, which triggers alerts in case of failures. This technique combines automated testing with monitoring in order to detect failing business requirements in production.
Test Cancer
As my career has turned into full-time authorship, I often worry about distancing myself from the realities of day-to-day software development. I've seen other well-known figures lose contact with reality, and I fear the same fate. My greatest source of resistance to this is Thoughtworks, which acts as a regular dose of reality to keep my feet on the ground.
Thoughtworks also acts as a source of ideas from the field, and I enjoy writing about useful things that my colleagues have discovered and developed. Usually these are helpful ideas, that I hope that some of my readers will be able to use. My topic today isn't such a pleasant topic. It's a problem and one that we don't have an answer for.
Test Coverage
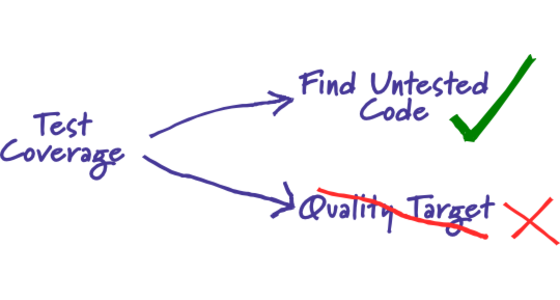
From time to time I hear people asking what value of test coverage (also called code coverage) they should aim for, or stating their coverage levels with pride. Such statements miss the point. Test coverage is a useful tool for finding untested parts of a codebase. Test coverage is of little use as a numeric statement of how good your tests are.
Test Double
Gerard Meszaros is working on a book to capture patterns for using the various Xunit frameworks. One of the awkward things he's run into is the various names for stubs, mocks, fakes, dummies, and other things that people use to stub out parts of a system for testing. To deal with this he's come up with his own vocabulary which I think is worth spreading further.
Test Driven Development
Test-Driven Development (TDD) is a technique for building software that guides software development by writing tests. It was developed by Kent Beck in the late 1990's as part of Extreme Programming. In essence we follow three simple steps repeatedly:
Test Invariant
There's been a long-running, if low-key, argument between the advocates of Design by Contract (DbC) and Test Driven Development (TDD). I'm not going to delve into that right now, but I will pass on an idea to merge the two that came up when I was talking with Daniel Jackson.
Test Pyramid
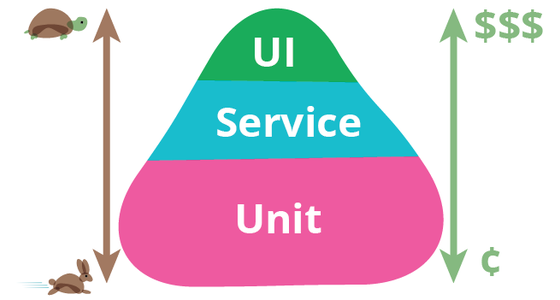
The test pyramid is a way of thinking about how different kinds of automated tests should be used to create a balanced portfolio. Its essential point is that you should have many more low-level UnitTests than high level BroadStackTests running through a GUI.
Testing Language
I'm currently sitting in a session at XP day where Owen Rogers and Rob Styles are talking about the differences between XP's unit and acceptance tests. This triggered a thought in my mind - what should a language for writing acceptance tests be?
Testing Resource Pools
I was digging through some old notes, and came across a simple but useful tip that Rich Garzaniti gave me.