
during: 2019
Heavy Cardboard
Heavy Cardboard is a media channel dedicated to board games, run by Edward Uhler. I first ran into it when it was purely a podcast, enjoying it because it reviewed the kind of games I was interested in, and gave enough depth to the reviews that I could get a good picture of whether the game would interest me. It then added a video channel, streaming live games on Youtube. I rarely watch the live games, but often found watching a recording useful to see if I would like a game. I also find Edward's teaching of the rules, which he does before every stream, an effective way to learn how to play a game. I liked the show enough to become a patron, and enjoy the patron-only slack channel. It's a useful discussion forum and one of the most pleasant online groups I've been involved in.
Exploratory Testing
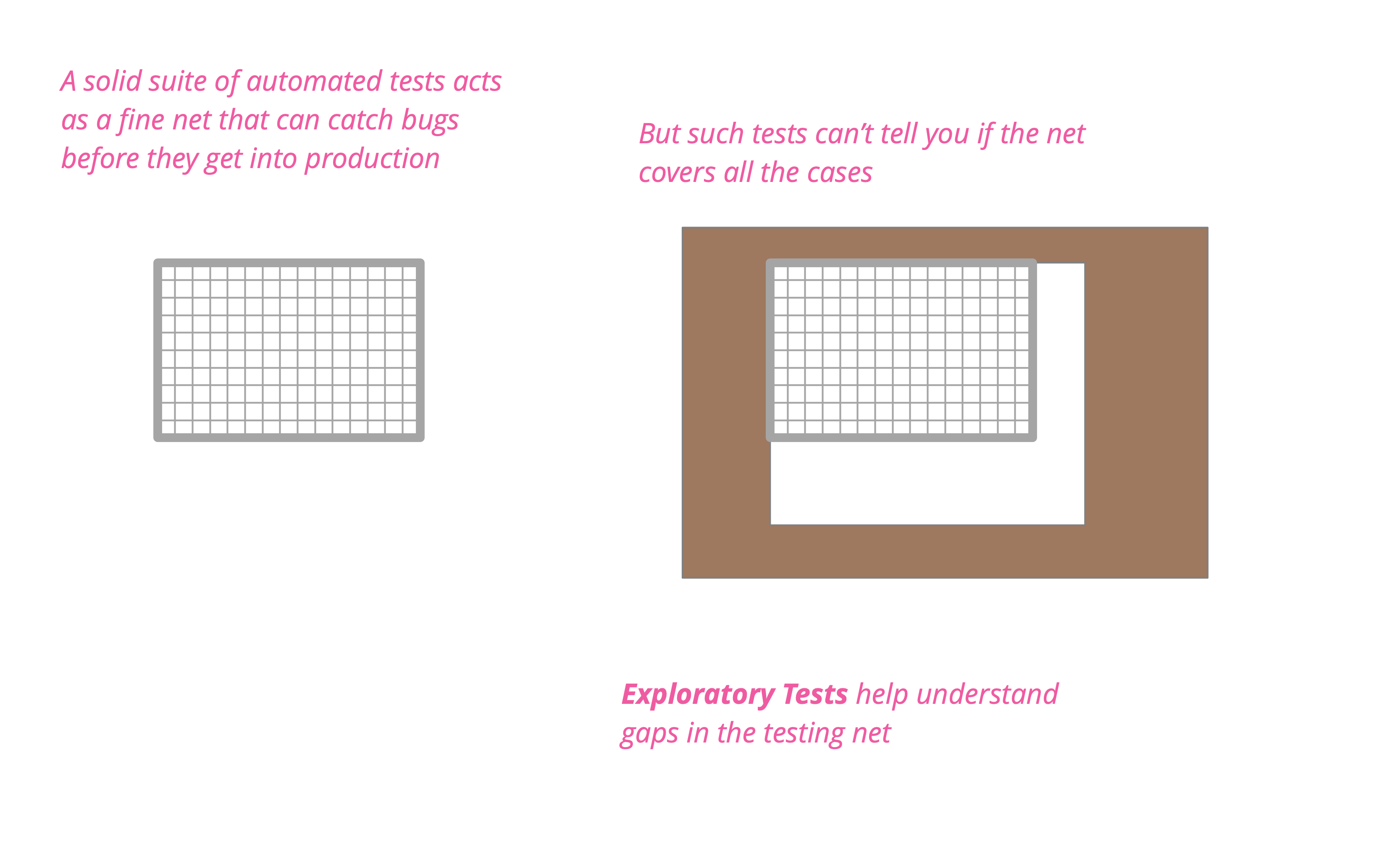
Exploratory testing is a style of testing that emphasizes a rapid cycle of learning, test design, and test execution. Rather than trying to verify that the software conforms to a pre-written test script, exploratory testing explores the characteristics of the software, raising discoveries that will then be classified as reasonable behavior or failures.
Waterfall Process
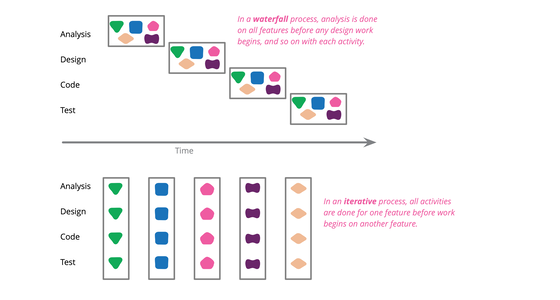
In the software world, “waterfall” is commonly used to describe a style of software process, one that contrasts with the ideas of iterative, or agile styles. Like many well-known terms in software it's meaning is ill-defined and origins are obscure - but I find its essential theme is breaking down a large effort into phases based on activity.
Continuous Delivery for Machine Learning
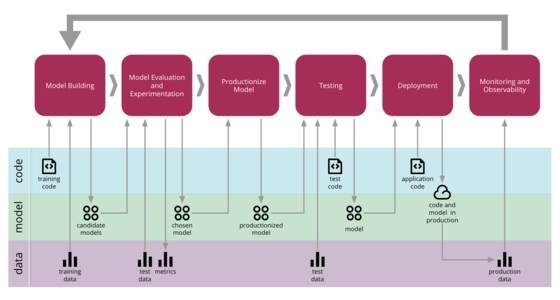
Machine Learning applications are becoming popular in our industry, however the process for developing, deploying, and continuously improving them is more complex compared to more traditional software, such as a web service or a mobile application. They are subject to change in three axis: the code itself, the model, and the data. Their behaviour is often complex and hard to predict, and they are harder to test, harder to explain, and harder to improve. Continuous Delivery for Machine Learning (CD4ML) is the discipline of bringing Continuous Delivery principles and practices to Machine Learning applications.
Don't get locked up into avoiding lock-in

A significant share of architectural energy is spent on reducing or avoiding lock-in. That's a rather noble objective: architecture is meant to give us options and lock-in does the opposite. However, lock-in isn't a simple true-or-false matter: avoiding being locked into one aspect often locks you into another. Also, popular notions, such as open source automagically eliminating lock-in, turn out to be not entirely true. Time to have a closer look at lock-in, so you don't get locked up into avoiding it!
Heavy Cardboard Review of Brass Birmingham
Brass Birmingham is a modern board game where players build up an industrial empire of coal mines, breweries, and railways in the industrial revolution. Edward and I do a detailed review of the game: assessing its weight, reviewing the components, and outlining what we like about the game. The podcast begins with a general chat of our recent gaming experiences, and I talk a bit about my background in gaming - the actual review starts at 1:16.
Site Report for 2018
At the start of 2019, it seems like a good idea to review the state of martinfowler.com. I did a brief review of the site back in 2014, so it's well past time to take another look at the traffic it generates.
Micro Frontends
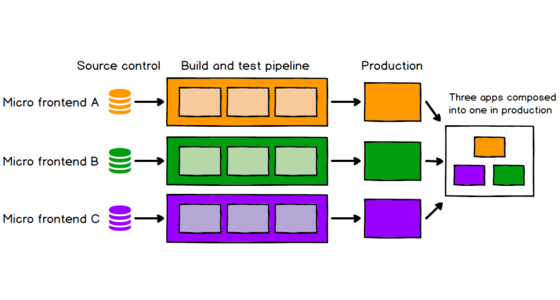
Good frontend development is hard. Scaling frontend development so that many teams can work simultaneously on a large and complex product is even harder. In this article we'll describe a recent trend of breaking up frontend monoliths into many smaller, more manageable pieces, and how this architecture can increase the effectiveness and efficiency of teams working on frontend code. As well as talking about the various benefits and costs, we'll cover some of the implementation options that are available, and we'll dive deep into a full example application that demonstrates the technique.
State Of Dev Ops Report
The State of DevOps Report is an annual report that uses a statistical analysis of survey data to determine effective practices for software delivery organizations. Its principal authors are Nicole Forsgren, Jez Humble, and Gene Kim.
Is High Quality Software Worth the Cost?
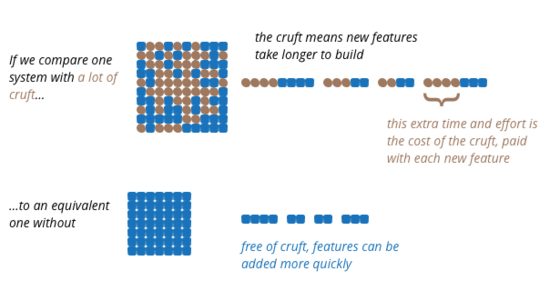
A common debate in software development projects is between spending time on improving the quality of the software versus concentrating on releasing more valuable features. Usually the pressure to deliver functionality dominates the discussion, leading many developers to complain that they don't have time to work on architecture and code quality. This debate is based on the assumption that increasing quality also increases costs, which is our common experience. But the counter-intuitive reality is that internal software quality removes the cruft that slows down developing new features, thus decreasing the cost of enhancing the software.
Technical Debt

Software systems are prone to the build up of cruft - deficiencies in internal quality that make it harder than it would ideally be to modify and extend the system further. Technical Debt is a metaphor, coined by Ward Cunningham, that frames how to think about dealing with this cruft, thinking of it like a financial debt. The extra effort that it takes to add new features is the interest paid on the debt.
How to Move Beyond a Monolithic Data Lake to a Distributed Data Mesh
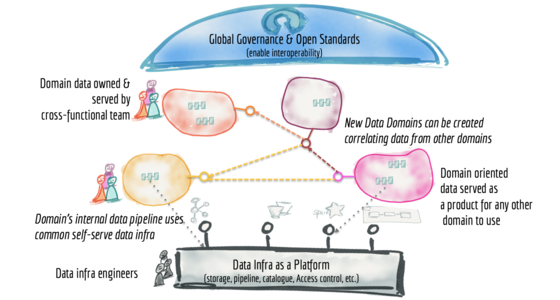
Many enterprises are investing in their next generation data lake, with the hope of democratizing data at scale to provide business insights and ultimately make automated intelligent decisions. Data platforms based on the data lake architecture have common failure modes that lead to unfulfilled promises at scale. To address these failure modes we need to shift from the centralized paradigm of a lake, or its predecessor data warehouse. We need to shift to a paradigm that draws from modern distributed architecture: considering domains as the first class concern, applying platform thinking to create self-serve data infrastructure, and treating data as a product.
Domain-Oriented Observability
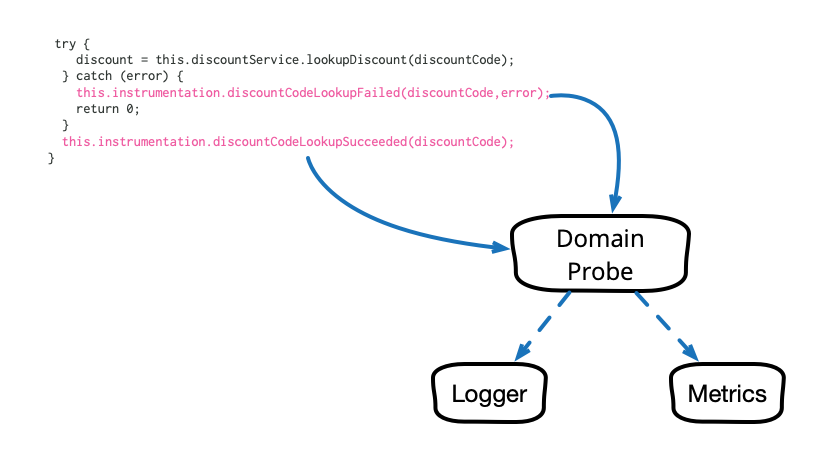
Observability in our software systems has always been valuable and has become even more so in this era of cloud and microservices. However, the observability we add to our systems tends to be rather low level and technical in nature, and too often it seems to require littering our codebase with crufty, verbose calls to various logging, instrumentation, and analytics frameworks. This article describes a pattern that cleans up this mess and allows us to add business-relevant observability in a clean, testable way.
Lock In Cost

In my recent client engagement, I foresaw that serverless architecture was a perfect fit. The idea of adopting serverless architecture, though, didn’t fly to our client well due to the fear of vendor lock-in. It was an interesting time for retailers as staying in AWS might mean that Amazon, as another retail business, will be given a competitive advantage. Given the idea of not supporting a competitor, my client was interested to ensure that the solution chosen by us is fully portable to other cloud vendors.