
Domain-Oriented Observability
Observability in our software systems has always been valuable and has become even more so in this era of cloud and microservices. However, the observability we add to our systems tends to be rather low level and technical in nature, and too often it seems to require littering our codebase with crufty, verbose calls to various logging, instrumentation, and analytics frameworks. This article describes a pattern that cleans up this mess and allows us to add business-relevant observability in a clean, testable way.
09 April 2019

Pete Hodgson is an independent software delivery consultant based in the beautiful, rainy Pacific Northwest. He specializes in helping startup engineering teams improve their engineering practices and technical architecture.
Pete previously spent six years as a consultant with Thoughtworks, leading technical practices for their West Coast business. He also did several stints as a tech lead at various San Francisco startups.
Modern software systems are becoming more distributed—and running on less-reliable infrastructure—thanks to current trends like microservices and cloud. Building observability into our systems has always been necessary, but these trends are making it more critical than ever. At the same time, the DevOps movement means that the folks monitoring production are more likely than ever to have the ability to actually add custom instrumentation code within the running systems rather than having to make do with bolting observability onto the side.
But, how do we add observability to what we care about the most, our business logic, without clogging up our codebase with instrumentation details? And, if this instrumentation is important, how do we test that we've implemented it correctly? In this article, I demonstrate how a philosophy of Domain-Oriented Observability paired with an implementation pattern called Domain Probe can help, by treating business-focused observability as a first-class concept within our codebase.
What to Observe
“Observability” has a broad scope, from low-level technical metrics through to high-level business key performance indicators (KPIs). On the technical end of the spectrum, we can track things like memory and CPU utilization, network and disk I/O, thread counts, and garbage collection (GC) pauses. On the other end of the spectrum, our business/domain metrics might track things like cart abandonment rate, session duration, or payment failure rate.
Because these higher-level metrics are specific to each system, they usually require hand-rolled instrumentation logic. This is in contrast to lower-level technical instrumentation, which is more generic and often is achieved without much modification to a system's codebase beyond perhaps injecting some sort of monitoring agent at boot time.
It's also important to note that higher-level, product-oriented metrics are more valuable because, by definition, they more closely reflect that the system is performing toward its intended business goals.
By adding instrumentation that tracks these valuable metrics we achieve Domain-Oriented Observability.
The Problem with Observability
So, Domain-Oriented Observability is valuable, but it usually requires hand-rolled instrumentation logic. That custom instrumentation lives right alongside the core domain logic of our systems, where clear, maintainable code is vital. Unfortunately, instrumentation code tends to be noisy, and if we're not careful, it can lead to a distracting mess.
Let's see an example of the kind of mess that the introduction of instrumentation code can cause. Here's a hypothetical e-commerce system's (somewhat naive) discount code logic before we add any observability:
class ShoppingCart…
applyDiscountCode(discountCode){
let discount;
try {
discount = this.discountService.lookupDiscount(discountCode);
} catch (error) {
return 0;
}
const amountDiscounted = discount.applyToCart(this);
return amountDiscounted;
}
I'd say we have some clearly expressed domain logic here. We look up a discount based on a discount code and then apply the discount to the cart. Finally, we return the amount that was discounted. If we failed to find a discount, we do nothing and exit early.
This application of discounts to a cart is a key feature, so good observability is important here. Let's add some instrumentation:
class ShoppingCart…
applyDiscountCode(discountCode){
this.logger.log(`attempting to apply discount code: ${discountCode}`);
let discount;
try {
discount = this.discountService.lookupDiscount(discountCode);
} catch (error) {
this.logger.error('discount lookup failed',error);
this.metrics.increment(
'discount-lookup-failure',
{code:discountCode});
return 0;
}
this.metrics.increment(
'discount-lookup-success',
{code:discountCode});
const amountDiscounted = discount.applyToCart(this);
this.logger.log(`Discount applied, of amount: ${amountDiscounted}`);
this.analytics.track('Discount Code Applied',{
code:discount.code,
discount:discount.amount,
amountDiscounted:amountDiscounted
});
return amountDiscounted;
}
In addition to performing the actual business logic of looking up and applying a discount, we are now also calling out to various instrumentation systems. We're logging some diagnostics for developers, we're recording some metrics for the people operating this system in production, and we're also publishing an event into our analytics platform for use by product and marketing folks.
Unfortunately, adding observability has made a mess of our nice,
clean domain logic. We now have only 25% of the code in our applyDiscountCode method involved in its stated purpose of looking up and
applying a discount. The clean business logic that we started out with hasn't
changed and remains clear and concise, but it's lost among the low-level
instrumentation code that now takes up the bulk of the method. What's more,
we've introduced code duplication and magic strings into the middle of our
domain logic.
In short, our instrumentation code is a huge distraction to anyone trying to read this method and see what it actually does.
Cleaning Up the Mess
Let's see if we can clean up this mess by refactoring our implementation. First, let's extract that icky low-level instrumentation logic into separate methods:
…
class ShoppingCart {
applyDiscountCode(discountCode){
this._instrumentApplyingDiscountCode(discountCode);
let discount;
try {
discount = this.discountService.lookupDiscount(discountCode);
} catch (error) {
this._instrumentDiscountCodeLookupFailed(discountCode,error);
return 0;
}
this._instrumentDiscountCodeLookupSucceeded(discountCode);
const amountDiscounted = discount.applyToCart(this);
this._instrumentDiscountApplied(discount,amountDiscounted);
return amountDiscounted;
}
_instrumentApplyingDiscountCode(discountCode){
this.logger.log(`attempting to apply discount code: ${discountCode}`);
}
_instrumentDiscountCodeLookupFailed(discountCode,error){
this.logger.error('discount lookup failed',error);
this.metrics.increment(
'discount-lookup-failure',
{code:discountCode});
}
_instrumentDiscountCodeLookupSucceeded(discountCode){
this.metrics.increment(
'discount-lookup-success',
{code:discountCode});
}
_instrumentDiscountApplied(discount,amountDiscounted){
this.logger.log(`Discount applied, of amount: ${amountDiscounted}`);
this.analytics.track('Discount Code Applied',{
code:discount.code,
discount:discount.amount,
amountDiscounted:amountDiscounted
});
}
}
This is a good start. We extracted the instrumentation details
into focused instrumentation methods, leaving our business logic with a simple
method call at each instrumentation point. It's easier to read and understand applyDiscountCode now that the distracting details of the various instrumentation
systems have been pushed down into those _instrument... methods.
However, it doesn't seem right that ShoppingCart now has a bunch of private methods that are entirely focused on
instrumentation—that's not really ShoppingCart's responsibility. A cluster of
functionality within a class that is unrelated to that class's primary
responsibility is often an indication that there's a new class trying to
emerge.
Let's follow that hint by gathering up those instrumentation
methods and moving them out into their own DiscountInstrumentation class:
class ShoppingCart…
applyDiscountCode(discountCode){
this.instrumentation.applyingDiscountCode(discountCode);
let discount;
try {
discount = this.discountService.lookupDiscount(discountCode);
} catch (error) {
this.instrumentation.discountCodeLookupFailed(discountCode,error);
return 0;
}
this.instrumentation.discountCodeLookupSucceeded(discountCode);
const amountDiscounted = discount.applyToCart(this);
this.instrumention.discountApplied(discount,amountDiscounted);
return amountDiscounted;
}
We don't make any changes to the methods; we just move them out to their own class with an appropriate constructor:
class DiscountInstrumentation {
constructor({logger,metrics,analytics}){
this.logger = logger;
this.metrics = metrics;
this.analytics = analytics;
}
applyingDiscountCode(discountCode){
this.logger.log(`attempting to apply discount code: ${discountCode}`);
}
discountCodeLookupFailed(discountCode,error){
this.logger.error('discount lookup failed',error);
this.metrics.increment(
'discount-lookup-failure',
{code:discountCode});
}
discountCodeLookupSucceeded(discountCode){
this.metrics.increment(
'discount-lookup-success',
{code:discountCode});
}
discountApplied(discount,amountDiscounted){
this.logger.log(`Discount applied, of amount: ${amountDiscounted}`);
this.analytics.track('Discount Code Applied',{
code:discount.code,
discount:discount.amount,
amountDiscounted:amountDiscounted
});
}
}
We now have a nice, clear separation of responsibilities: ShoppingCart is entirely focused on domain concepts like applying discounts,
whereas our new DiscountInstrumentation class encapsulates all the
details of instrumenting the process of applying a discount.
Domain Probe
A Domain Probe[...] enables us to add observability to domain logic while still talking in the language of the domain
DiscountInstrumentation is an example of a pattern I
call Domain Probe. A Domain
Probe presents a high-level instrumentation API that is oriented around
domain semantics, encapsulating the low-level instrumentation plumbing required
to achieve Domain-Oriented Observability. This enables us to add observability
to domain logic while still talking in the language of the domain,
avoiding the distracting details of the instrumentation technology. In our
preceding example, our ShoppingCart implemented observability by
reporting Domain Observations—discount codes being applied and discount code
lookups failing—to the DiscountInstrumentation probe rather than working
directly in the technical domain of writing log entries or tracking analytics
events. This might seem a subtle distinction, but keeping domain code focused
on the domain pays rich dividends in terms of keeping a codebase readable,
maintainable, and extensible.
Testing Observability
It's rare to see good test coverage of instrumentation logic. I don't often see automated tests that verify that an error is logged if an operation fails, or that an analytics event containing the correct fields is published when a conversion occurs. This is perhaps partially due to observability historically being regarded as less valuable, but it's also because it's a pain to write good tests for low-level instrumentation code.
Testing Instrumentation Code Is a Pain
To demonstrate, let's look at some instrumentation for a different part of our hypothetical e-commerce system and see how we might write some tests that verify the correctness of that instrumentation code.
ShoppingCart has an addToCart
method, which is currently instrumented with direct calls to various
observability systems (rather than using a Domain
Probe):
class ShoppingCart…
addToCart(productId){
this.logger.log(`adding product '${productId}' to cart '${this.id}'`);
const product = this.productService.lookupProduct(productId);
this.products.push(product);
this.recalculateTotals();
this.analytics.track(
'Product Added To Cart',
{sku: product.sku}
);
this.metrics.gauge(
'shopping-cart-total',
this.totalPrice
);
this.metrics.gauge(
'shopping-cart-size',
this.products.length
);
}
Let's look at how we might begin to test this instrumentation logic:
shoppingCart.test.js
const sinon = require('sinon');
describe('addToCart', () => {
// ...
it('logs that a product is being added to the cart', () => {
const spyLogger = {
log: sinon.spy()
};
const shoppingCart = testableShoppingCart({
logger:spyLogger
});
shoppingCart.addToCart('the-product-id');
expect(spyLogger.log)
.calledWith(`adding product 'the-product-id' to cart '${shoppingCart.id}'`);
});
});
In this test, we're setting up a shopping cart for test, wired
up with a spy logger (a
“spy” is a type of test double used to verify how our test
subject is interacting with other objects). In case you're wondering, testableShoppingCart is just a little helper function that creates an instance of ShoppingCart with faked-out dependencies by default. With our spy in place,
we call shoppingCart.addToCart(...) and then check that the shopping
cart used the logger to log an appropriate message.
As written, this test does provide reasonable assurance that we are logging when products are added to a cart. However, it is very much coupled to the details of that logging. If we decided to change the format of the log message at some point in the future, we'd break this test for no good reason. This test shouldn't be concerned with the exact details of what was logged, just that something was logged with the correct contextual data.
We could try to reduce how tightly the test is coupled to the details of the log message format by matching against a regular expression (regex) instead of an exact string. However, this would make the validation a little opaque. Additionally, the effort required to craft a robust regex is usually a poor investment of time.
Moreover, this was just a simple example of testing how things are logged. More complex scenarios (e.g., logging exceptions) are even more of a pain—the APIs of logging frameworks and their ilk don't lend themselves to easy verification when they're being mocked out.
Let's move on and take a look at another test, this time verifying our analytics integration:
shoppingCart.test.js
const sinon = require('sinon');
describe('addToCart', () => {
// ...
it('publishes analytics event', () => {
const theProduct = genericProduct();
const stubProductService = productServiceWhichAlwaysReturns(theProduct); ➋
const spyAnalytics = {
track: sinon.spy()
};
const shoppingCart = testableShoppingCart({
productService: stubProductService, ➊
analytics: spyAnalytics ➌
});
shoppingCart.addToCart('some-product-id');
expect(spyAnalytics.track).calledWith( ➍
'Product Added To Cart',
{sku: theProduct.sku}
);
});
});
This test is a little more involved because we need to control
the product that is passed back to the shopping cart from productService.lookupProduct(...), which means that we need to inject a stub product
service
①
that is rigged to always return a specific product
②
.
We also inject a spy analytics
③
, just as we injected a spy logger
in our previous test. After that's all set up, we call shoppingCart.addToCart(...) and then, finally, verify
④
that our analytics
instrumentation was asked to create an event with the expected parameters.
I'm reasonably happy with this test. It's a bit of a pain to get that product sent into the cart as indirect input, but that's an acceptable trade-off in exchange for gaining confidence that we include that product's SKU in our analytics event. It's also a bit of a shame that our test is coupled to the exact format of that event: as with our logging test above, I'd prefer that this test didn't care about the details of how observability is achieved, just that it's being done using the correct data.
After completing that test, I'm daunted by the fact that if I
also want to test the other bits of instrumentation logic (the shopping-cart-total and shopping-cart-size metric gauges), I'll need to
create two or three extra tests that will look remarkably similar to this one.
Each test will need to go through the same fiddly dependency setup work, even
though that's not the focus of the test. When confronted with this task, some
developers would grit their teeth, copy and paste the existing test, change
what needs to be changed, and go on with their day. In reality, many developers
would decide that the first test is good enough and risk a bug being introduced
in our instrumentation logic later on (a bug that could go unnoticed for a
while, given that broken instrumentation is not always immediately apparent).
Domain Probes Enable Cleaner, More-Focused Tests
Let's see how using the Domain
Probe pattern can improve the testing story. Here's our ShoppingCart again, now refactored to use a Domain Probe:
class ShoppingCart…
addToCart(productId){
this.instrumentation.addingProductToCart({
productId:productId,
cart:this
});
const product = this.productService.lookupProduct(productId);
this.products.push(product);
this.recalculateTotals();
this.instrumentation.addedProductToCart({
product:product,
cart:this
});
}
And here are the tests for the instrumentation of addToCart:
shoppingCart.test.js
const sinon = require('sinon');
describe('addToCart', () => {
// ...
it('instruments adding a product to the cart', () => {
const spyInstrumentation = createSpyInstrumentation();
const shoppingCart = testableShoppingCart({
instrumentation:spyInstrumentation
});
shoppingCart.addToCart('the-product-id');
expect(spyInstrumentation.addingProductToCart).calledWith({ ➊
productId:'the-product-id',
cart:shoppingCart
});
});
it('instruments a product being successfully added to the cart', () => {
const theProduct = genericProduct();
const stubProductService = productServiceWhichAlwaysReturns(theProduct);
const spyInstrumentation = createSpyInstrumentation();
const shoppingCart = testableShoppingCart({
productService: stubProductService,
instrumentation: spyInstrumentation
});
shoppingCart.addToCart('some-product-id');
expect(spyInstrumentation.addedProductToCart).calledWith({ ➋
product:theProduct,
cart:shoppingCart
});
});
function createSpyInstrumentation(){
return {
addingProductToCart: sinon.spy(),
addedProductToCart: sinon.spy()
};
}
});
The introduction of a Domain Probe has raised the level of abstraction a little, making the code and the tests a bit easier to read as well as less brittle. We're still testing that instrumentation has been implemented correctly—in fact, our tests now completely verify our observability requirements—but our test expectations ①② no longer need to include the details of how the instrumentation is implemented, just that the appropriate context is passed over.
Our tests capture the essential complexity of adding observability without dragging in too much accidental complexity.
It would still be wise to verify that the mucky lower-level instrumentation
details are correctly implemented though; neglecting to include the right
information in our instrumentation can be a costly mistake. Our
ShoppingCartInstrumentation Domain Probe is
responsible for implementing these details, so the tests for that class are the
natural place to verify that we get these details correct:
ShoppingCartInstrumentation.test.js
const sinon = require('sinon');
describe('ShoppingCartInstrumentation', () => {
describe('addingProductToCart', () => {
it('logs the correct message', () => {
const spyLogger = {
log: sinon.spy()
};
const instrumentation = testableInstrumentation({
logger:spyLogger
});
const fakeCart = {
id: 'the-cart-id'
};
instrumentation.addingProductToCart({
cart: fakeCart,
productId: 'the-product-id'
});
expect(spyLogger.log)
.calledWith("adding product 'the-product-id' to cart 'the-cart-id'");
});
});
describe('addedProductToCart', () => {
it('publishes the correct analytics event', () => {
const spyAnalytics = {
track: sinon.spy()
};
const instrumentation = testableInstrumentation({
analytics:spyAnalytics
});
const fakeCart = {};
const fakeProduct = {
sku: 'the-product-sku'
};
instrumentation.addedProductToCart({
cart: fakeCart,
product: fakeProduct ➊
});
expect(spyAnalytics.track).calledWith(
'Product Added To Cart',
{sku: 'the-product-sku'}
);
});
it('updates shopping-cart-total gauge', () => {
// ...etc
});
it('updates shopping-cart-size gauge', () => {
// ...etc
});
});
});
Here again our tests can become a little more focused. We can
pass product in directly
①
rather than the previous
indirect injection dance via the mocked-out productService in our ShoppingCart tests.
Because our tests for ShoppingCartInstrumentation are focused on how that class
uses the third-party instrumentation libraries, we can make our tests a little
terser by using a before block to set up prewired spies
for those dependencies:
shoppingCartInstrumentation.test.js
const sinon = require('sinon');
describe('ShoppingCartInstrumentation', () => {
let instrumentation, spyLogger, spyAnalytics, spyMetrics;
before(()=>{
spyLogger = { log: sinon.spy() };
spyAnalytics = { track: sinon.spy() };
spyMetrics = { gauge: sinon.spy() };
instrumentation = new ShoppingCartInstrumentation({
logger: spyLogger,
analytics: spyAnalytics,
metrics: spyMetrics
});
});
describe('addingProductToCart', () => {
it('logs the correct message', () => {
const spyLogger = {
log: sinon.spy()
};
const instrumentation = testableInstrumentation({
logger:spyLogger
});
const fakeCart = {
id: 'the-cart-id'
};
instrumentation.addingProductToCart({
cart: fakeCart,
productId: 'the-product-id'
});
expect(spyLogger.log)
.calledWith("adding product 'the-product-id' to cart 'the-cart-id'");
});
});
describe('addedProductToCart', () => {
it('publishes the correct analytics event', () => {
const spyAnalytics = {
track: sinon.spy()
};
const instrumentation = testableInstrumentation({
analytics:spyAnalytics
});
const fakeCart = {};
const fakeProduct = {
sku: 'the-product-sku'
};
instrumentation.addedProductToCart({
cart: fakeCart,
product: fakeProduct
});
expect(spyAnalytics.track).calledWith(
'Product Added To Cart',
{sku: 'the-product-sku'}
);
});
it('updates shopping-cart-total gauge', () => {
const fakeCart = {
totalPrice: 123.45
};
const fakeProduct = {};
instrumentation.addedProductToCart({
cart: fakeCart,
product: fakeProduct
});
expect(spyMetrics.gauge).calledWith(
'shopping-cart-total',
123.45
);
});
it('updates shopping-cart-size gauge', () => {
// ...etc
});
});
});
Our tests are now very clear and focused. Each test verifies that one specific part of our low-level technical instrumentation is correctly triggered as part of a higher-level Domain Observation. The tests capture the intent of the Domain Probe: presenting a domain-specific abstraction over the boring technical details of our various instrumentation systems.
Including Execution Context
Instrumentation events always need to include contextual metadata; that is, the information used to understand the broader context around the event that's been observed.
Types of Metadata
One commonly seen piece of metadata for web services is a request identifier, used to facilitate distributed tracing—tying together the various distributed calls that make up a single logical operation (you might also see these identifiers referred to as correlation identifiers, or trace and span identifiers).
Another common piece of request-specific metadata is a user identifier, recording which user is making a request or, in some cases, information on the “principal”—the actor on whose behalf an external system is making its request. Some systems will also record feature flag metadata—information on which experimental “buckets” into which this request has been placed, or even just the raw state of every flag. These bits of metadata are critical when using web analytics to correlate user behavior with a feature change.
There are some other, more-technical bits of metadata that can be helpful when trying to understand how events correlate to a change in the system, such as software version, process and thread identifier, perhaps server hostname.
One piece of metadata is so critical to correlating instrumentation events that it's almost too obvious to mention: a timestamp indicating when the event occurred.
Injecting Metadata
Providing this contextual metadata to a Domain Probe can be a bit of a pain. Domain Observation calls are usually made by domain code, which hopefully won't have direct exposure to technical details like request ID or feature flag configuration; these technical details shouldn't be domain code's concern. So, how do we make sure that our Domain Probe has the technical details it needs without polluting our domain code with those details?
What we have here is a pretty typical Dependency Injection scenario: we need to inject a correctly configured Domain Probe dependency into a domain class without dragging all of that Domain Probe's transitive dependencies into the domain class. We can choose our preferred solution from the menu of dependency injection patterns available to us.
Let's take the shopping cart discount code example from earlier
and examine a few alternatives. To refresh our memory, here's where we left our
instrumented ShoppingCart's applyDiscountCode implementation:
class ShoppingCart…
applyDiscountCode(discountCode){
this.instrumentation.applyingDiscountCode(discountCode);
let discount;
try {
discount = this.discountService.lookupDiscount(discountCode);
} catch (error) {
this.instrumentation.discountCodeLookupFailed(discountCode,error);
return 0;
}
this.instrumentation.discountCodeLookupSucceeded(discountCode);
const amountDiscounted = discount.applyToCart(this);
this.instrumention.discountApplied(discount,amountDiscounted);
return amountDiscounted;
}
Now, the question is, how does this.instrumentation (our Domain Probe) get set up in our ShoppingCart class? We could simply pass it in to our constructor:
class ShoppingCart…
constructor({instrumentation,discountService}){
this.instrumentation = instrumentation;
this.discountService = discountService;
}
Alternatively, if we want more control over how our Domain Probe obtains additional contexual metadata, we could pass in some sort of instrumentation factory:
constructor({createInstrumentation,discountService}){
this.createInstrumentation = createInstrumentation;
this.discountService = discountService;
}
We can then use this factory function to create instances of our Domain Probe on demand:
applyDiscountCode(discountCode){
const instrumentation = this.createInstrumentation();
instrumentation.applyDiscountCode(discountCode);
let discount;
try {
discount = this.discountService.lookupDiscount(discountCode);
} catch (error) {
instrumentation.discountCodeLookupFailed(discountCode,error);
return 0;
}
instrumentation.discountCodeLookupSucceeded(discountCode);
const amountDiscounted = discount.applyToCart(this);
instrumention.discountApplied(discount,amountDiscounted);
return amountDiscounted;
}
On the face of it, introducing a factory function like this adds
needless indirection. However, it also gives us more flexibility in how we
create our Domain Probe, and how we
configure it with contextual information. For example, let's take a look at the
way that we include the discount code into our instrumentation. With our
existing implementation, we pass discountCode as a parameter to each
instrumentation call. But within a given invocation of applyDiscountCode, that discountCode stays constant. Why don't we
just pass it to our Domain Probe
once, when we create it:
applyDiscountCode(discountCode){
const instrumentation = this.createInstrumentation({discountCode});
instrumentation.applyDiscountCode(discountCode);
let discount;
try {
discount = this.discountService.lookupDiscount(discountCode);
} catch (error) {
instrumentation.discountCodeLookupFailed(discountCode,error);
return 0;
}
instrumentation.discountCodeLookupSucceeded(discountCode);
const amountDiscounted = discount.applyToCart(this);
instrumention.discountApplied(discount,amountDiscounted);
return amountDiscounted;
}
That's nicer. We're able to pass context into our Domain Probe once, and avoid passing the same information repeatedly.
Collecting Instrumentation Context
If we take a step back and look at what we're doing here, we're essentially creating a more targeted version of our Domain Probe, specifically configured to record Domain Observations in this one particular context.
We can take this idea further, using it to ensure that our Domain Probe has access to the relevant
technical context that it needs to include in instrumentation records—for
example, a request identifier—without having to expose those technical details
to our ShoppingCart domain class at all. Here's a sketch of one way to do that, by
creating a new Observation Context class:
class ObservationContext {
constructor({requestContext,standardParams}){
this.requestContext = requestContext;
this.standardParams = standardParams; ➊
}
createShoppingCartInstrumentation(extraParams){ ➌
const paramsFromContext = { ➋
requestId: this.requestContext.requestId
};
const mergedParams = { ➍
...this.standardParams,
...paramsFromContext,
...extraParams
};
return new ShoppingCartInstrumentation(mergedParams);
}
}
ObservationContext acts as a clearinghouse for all
the bits of context that are needed by ShoppingCartInstrumentation in order to record Domain
Observations. Some standard, fixed parameters are specified in the ObservationContext's constructor
①
. Other parameters that are more
dynamic (the request identifier) are filled in by ObservationContext at the point a Domain
Probe is requested, within its createShoppingCartInstrumentation method
②
.
At the same point, the caller can also itself pass in additional context to createShoppingCartInstrumentation via the extraParams parameter
③
. These three sets of contextual
parameters are then merged together
④
, and used to create an instance
of ShoppingCartInstrumentation.
In functional programming terms, essentially what we're doing
here is creating a partially
applied Domain Observation. The fields that make up our Domain
Observation are partially applied (specified) when we construct the ObservationContext, then a few more are applied when we ask that ObservationContext for an instance of ShoppingCartInstrumentation. Finally, the remaining fields
are applied when we call the methods on ShoppingCartInstrumentation to actually record our Domain
Observation. If we were working in a functional style we might literally implement
our Domain Probe using partial application, but in this context, we're using OO equivalents, like the Factory pattern.
A significant advantage of this partial application approach is that
the domain objects that are recording Domain Observations don't need to be
aware of every field that goes into that event. In the preceding example, we
can make sure that request identifiers are included in our instrumentation
while keeping our ShoppingCart domain class blissfully unaware
of such tedious technical metadata. We're also able to apply these standard
fields in a centralized, consistent way, rather than relying on every client of
our instrumentation system to consistently include them.
Scope of Domain Probes
When designing our Domain Probes, we have a choice to make in how granular each object should be. We can create a lot of highly-specialized objects that have a lot of contextual information preapplied, like the earlier discount code example. Alternatively, we can create a few general-purpose objects that require consumers to pass more context each time they record a Domain Observation. The trade-off here is between more verbosity at each observability call site (if we use less-specialized Domain Probes with less context preapplied) versus more “observability plumbing” being passed around if we opt to create lots of specialized objects with context preapplied.
There's not really a right or wrong approach here—every team expresses their own stylistic preferences in their code base. Teams that tend toward a more functional style might lean toward layers of partially applied Domain Probes. Teams that have a more “enterprise Java” style might prefer a few large, general-purpose Domain Probes, in which most instrumentation context is passed in as parameters to those methods. However, both teams should be using the ideas of partial application to hide metadata like request identifiers from Domain Probe clients that wouldn't otherwise care about such technical detail.
Alternative Implementations
The Domain Probe pattern that I've laid out in this article is just one way to add Domain-Oriented Observability to a codebase. I briefly touch on some alternative approaches here.
Event-Based Observability
In our examples so far, the Shopping Cart domain object makes direct calls to a Domain Probe, which in turn invokes our lower-level instrumentation systems, as shown in Figure 1.
{kind=link}
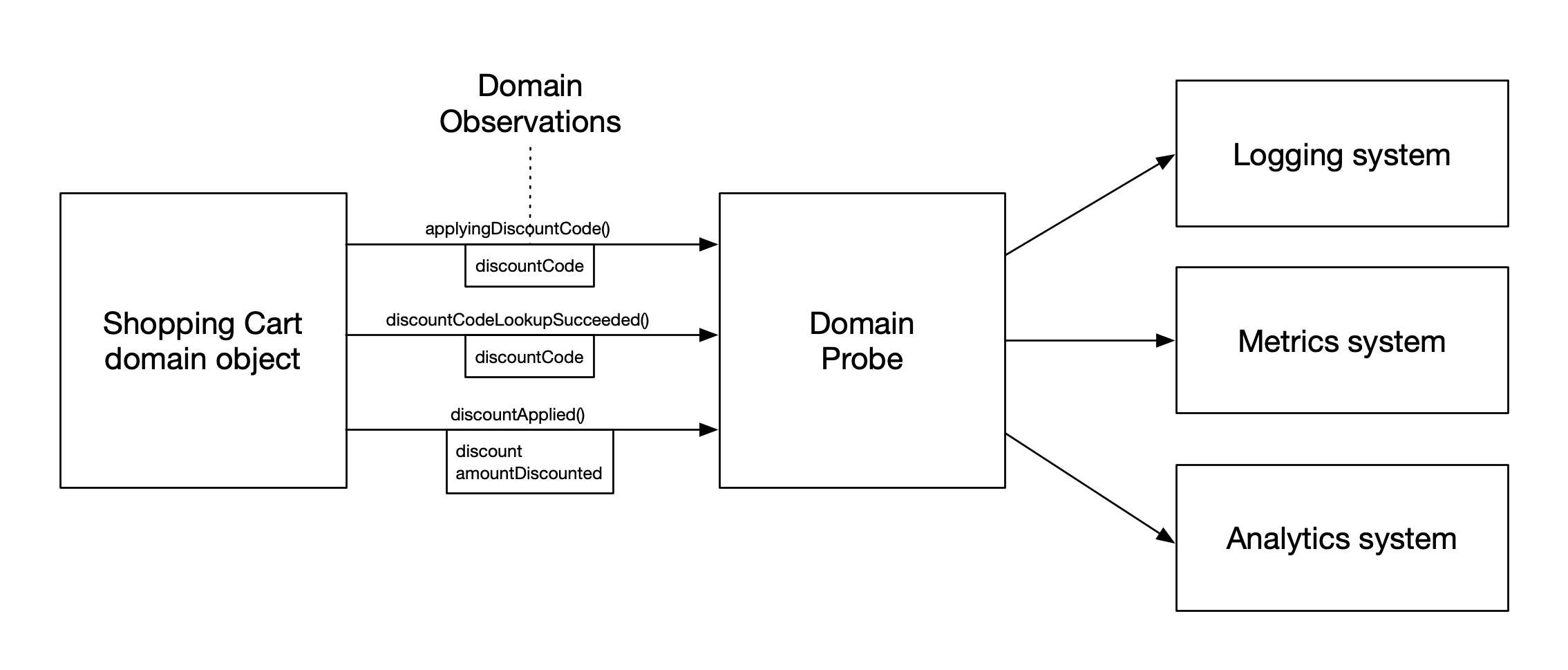
Figure 1: A direct Domain Probe design
Some teams prefer a more event-oriented design for their Domain Observability API. Rather than the domain object making a direct method call, it instead emits Domain Observation events (which we'll call Announcements) that announce its progress to any interested observer, as demonstrated in Figure 2 .
{kind=link}
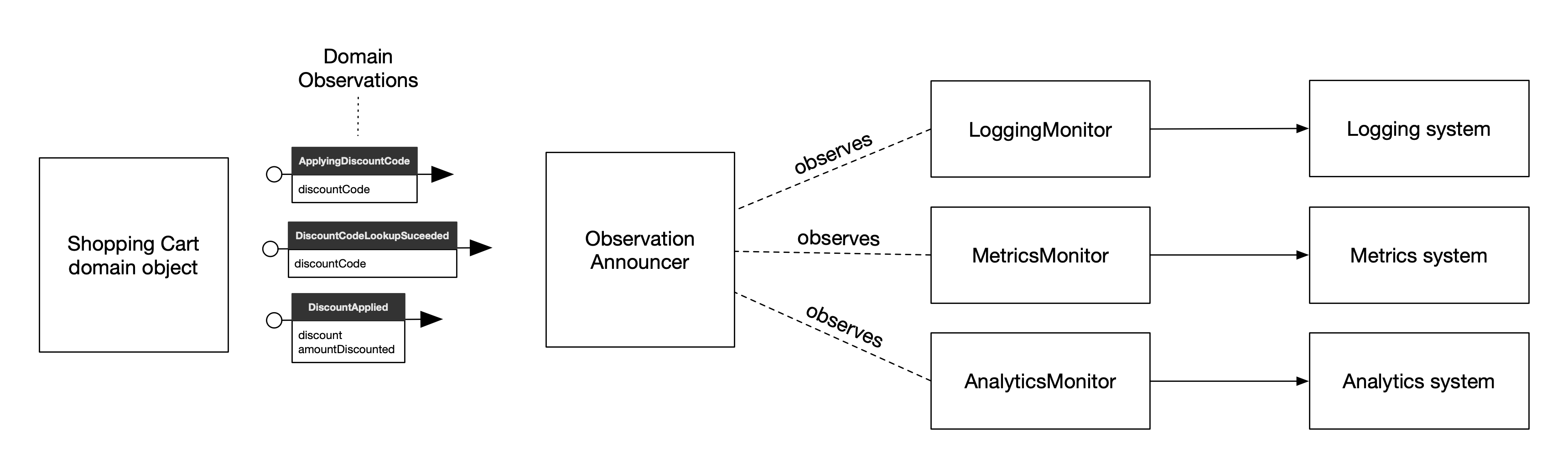
Figure 2: A decoupled, event-oriented design
Here's a sketch of how this might look for our example ShoppingCart:
class ShoppingCart {
constructor({observationAnnouncer,discountService}){
this.observationAnnouncer = observationAnnouncer;
this.discountService = discountService;
}
applyDiscountCode(discountCode){
this.observationAnnouncer.announce(
new ApplyingDiscountCode(discountCode)
);
let discount;
try {
discount = this.discountService.lookupDiscount(discountCode);
} catch (error) {
this.observationAnnouncer.announce(
new DiscountCodeLookupFailed(discountCode,error)
);
return 0;
}
this.observationAnnouncer.announce(
new DiscountCodeLookupSucceeded(discountCode)
);
const amountDiscounted = discount.applyToCart(this);
this.instrumention.discountApplied(discount,amountDiscounted);
this.observationAnnouncer.announce(
new DiscountApplied(discountCode)
);
return amountDiscounted;
}
}
For each domain observation that we might want to instrument, we
have a corresponding Announcement class. As relevant domain events occur, our
domain logic creates an Announcement with the relevant contextual information
(discount code, amount discounted, etc.), and publishes it via an observationAnnouncer service. We can then wire these announcements to the
appropriate instrumentation systems by creating Monitors that react to specific
announcements by invoking those instrumentation systems. Here's a Monitor class
that is specialized to handle announcements that we want to record to our
logging system:
class LoggingMonitor {
constructor({logger}){
this.logger = logger;
}
handleAnnouncement(announcement){
switch (announcement.constructor) {
case ApplyingDiscountCode:
this.logger.log(
`attempting to apply discount code: ${announcement.discountCode}`
);
return;
case DiscountCodeLookupFailed:
this.logger.error(
'discount lookup failed',
announcement.error
);
return;
case DiscountApplied:
this.logger.log(
`Discount applied, of amount: ${announcement.amountDiscounted}`
);
return;
}
}
}
And here's a second Monitor, specialized in announcements for domain observations that we are keeping a count of in our metrics system:
class MetricsMonitor {
constructor({metrics}){
this.metrics = metrics;
}
handleAnnouncement(announcement){
switch (announcement.constructor) {
case DiscountCodeLookupFailed:
this.metrics.increment(
'discount-lookup-failure',
{code:announcement.discountCode});
return;
case DiscountCodeLookupSucceeded:
this.metrics.increment(
'discount-lookup-success',
{code:announcement.discountCode});
return;
}
}
}
Each of these Monitor classes are registered with a central EventAnnouncer - the same event announcer to which our ShoppingCart domain object is sending announcements. These Monitor classes
are performing the same work as our Domain
Probe did earlier, we've just rearranged where that implementation lives.
The more decoupled nature of this event-oriented approach has also allowed us
to split the instrumentation details up into these separate specialized Monitor
classes, one for each instrumentation system, rather than having a single Domain Probe class which ends up being
responsible for the messy implementation details of multiple different
instrumentation technologies.
Aspect-Oriented Programming
The techniques for applying Domain-Oriented Observability that we've discussed so far can remove low-level instrumentation calls from our domain code, but we're still left with some amount of Domain Observability code interspersed through our domain logic. It's cleaner and easier to read than direct invocations of low-level instrumentation libraries, but it's still there. If we wanted to remove the observability noise from our domain code entirely, we could perhaps turn to Aspect-Oriented Programming (AOP). AOP is a paradigm that attempts to extract cross-cutting concerns, like observability, from the main code flow. An AOP framework modifies the behavior of our program by injecting logic that's not directly expressed in source code. We control how that behavior is injected via a sort of meta-programming, in which we annotate our source code with metadata that controls where that cross-cutting logic is injected and how it behaves.
The observability behavior that we've been talking about in this article is exactly the type of cross-cutting concern that AOP is intended to target. Indeed, adding logging to a codebase is pretty much the canonical example used to introduce AOP. And if your codebase is already leveraging some sort of aspect-oriented meta-programming, it's certainly worth considering whether you can achieve Domain-Oriented Observability using AOP techniques. However, if you're not already using AOP, I'd counsel caution here. Although in the abstract it can seem like a very elegant approach, in the details it can turn out to be less so.
The fundamental issue is that AOP works at the level of source code, but the granularity of Domain Observability does not exactly line up with the granularity of our code. On the one hand, we don't want observability around every single method call in our domain code, tracking every parameter and every return value. On the other hand, we sometimes do want observability around either side of a conditional statement—for example, is the user who just logged in an admin or not—and we sometimes want to include additional contextual information in our observations that might not be directly available at the point that the domain event we're observing occurs. If AOP is being used to implement Domain-Oriented Observability then we must work around this impedance mismatch by decorating our domain code with abstruse annotations, to the point that the annotation code becomes just as distracting as the direct observability calls we wanted to remove from our domain code.
Besides this impedance mismatch issue, there are also some general drawbacks to meta-programming, which apply just as much when using it for DOO. The observability implementation can become somewhat “magical” and difficult to understand.1 Testing AOP-powered observability is also a lot less straightforward, in contrast to the clear testability that we identified previously as of the big wins of moving to Domain Probes.
1: Dan Tao, a former colleague and very thoughtful person, posed an interesting question when reviewing this article. Although reducing the amount of observability noise from our domain logic is clearly a goal, should we be aiming to remove all observability logic? Or, would that be too much, too “magical”? How much is the right amount?
When to Apply Domain-Oriented Observability?
This is a useful pattern; where should we apply it? My recommendation is to always use some sort of Domain-Oriented Observability abstraction when adding observability to domain code—the areas of your codebase that are focused on business logic, as opposed to technical plumbing. Using something like a Domain Probe keeps that domain code decoupled from the technical details of your instrumentation infrastructure, and makes testing your observability a feasible endeavor. The type of observability that is added within your domain code is usually product oriented and high value. It's worth investing in the more rigorous approach of Domain-Oriented Observability here.
A simple rule to follow is that your domain classes should never have a direct reference to any instrumentation systems, only to Domain-Oriented Observability classes that abstract over the technical details of those systems.
Retro-Fitting an Existing Codebase
You might be wondering how to introduce these patterns into an existing codebase, perhaps where observability has so far been implemented in only an ad hoc fashion. My advice here is the same advice I would give for introducing test automation: only retrofit areas of your codebase that you're already working on for other reasons. Don't allocate a dedicated effort to moving everything over in one go. This way you will be sure that “hot spots” in your code—areas that are frequently changing and likely more valuable to the business—are made more observable and easier to test. Conversely, you avoid investing energy into areas of your codebase that are “dormant.”
Acknowledgments
Domain-Oriented Observability isn't something I invented or personally discovered. As with any pattern write-up, I'm just documenting a practice that I've seen various teams apply over the years, and that many other teams have undoubtedly used elsewhere.
My earliest introduction to some of the ideas laid out here was via the fantastic book Growing Object-Oriented Software Guided by Tests. Specifically, the “Logging Is a Feature” section in Chapter 20 discusses raising logging up to a domain-level concern, and the testability advantages that brings.
I think either Andrew Kiellor or Toby Clemson first showed me how to apply an approach similar to Domain Probe while we were on a Thoughtworks project together (I believe under the name Semantic Logging), and I'm sure that this concept has been doing the rounds within the broader Thoughtworks hivemind for a long time.
I haven't seen a write up of this same pattern applied to observability more broadly; hence this article. The closest analog I could find is the Semantic Logging Application Block from Microsoft's Patterns & Practices group. From what I can tell, their take on Semantic Logging is a concrete library that makes it easier to do structured logging within .NET applications.
Thanks to Charlie Groves, Chris Richardson, Chris Stevenson, Clare Sudbery, Dan Richelson, Dan Tao, Dan Wellman, Elise McCallum, Jack Bolles, James Gregory, James Richardson, Josh Graham, Kris Hicks, Michael Feathers, Nat Pryce, Pam Ocampo, and Steve Freeman for thoughtful feedback on early drafts of this article.
Thanks to Bob Russell for copyediting.
Many thanks to Martin Fowler for graciously offering to host this article on his site, along with an abundance of advice and editorial support.
Footnotes
1: Dan Tao, a former colleague and very thoughtful person, posed an interesting question when reviewing this article. Although reducing the amount of observability noise from our domain logic is clearly a goal, should we be aiming to remove all observability logic? Or, would that be too much, too “magical”? How much is the right amount?
Significant Revisions
09 April 2019: published final installment
08 April 2019: published installment on including execution context
03 April 2019: published installment on testing
02 April 2019: Published first installment