
during: 2021
My favorite musical discoveries of 2021

Six of my favorite new music acquisitions in 2021
Scaling the Practice of Architecture, Conversationally
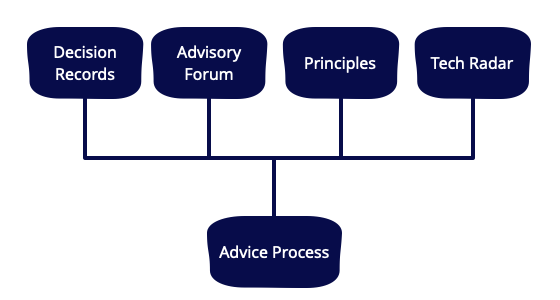
Architecture need not be a monologue; delivered top-down from the minds and mouths of a centralised few. This article describes another way to do architecture; as a series of conversations, driven by a decentralised and empowering decision-making technique, and supported by four learning and alignment mechanisms: Decision Records, Advisory Forum, Team-sourced Principles, and a Technology Radar
You Can't Buy Integration
Commercial integration tools are a couple decades old now, but there has been little in the way of overarching architectural principles describing when and how to use them. In this article, I argue that “buy” decision mechanics have caused us to exaggerate the value proposition of such tools, often leading to mandates to use a certain integration tool over a general purpose language. I claim that such tools thrive in a world that views integration as primarily about connecting systems, but that digital organizations have reimagined integration to be primarily about putting clean interfaces in front of digital capabilities, emphasizing capabilities over systems. Finally, I list some of the key principles behind a modern view of integration and claim they are best managed with a general purpose language, reorienting the primary value proposition of commercial integration tools towards simplifying tactical implementation concerns.
Engineering Room Conversation with Dave Farley
My old colleague Dave Farley has been running an increasingly popular YouTube channel on software development. It's good material, very much in line with my own views, after all his experience is a big influence on my thinking. We talk about a range of topics about the current role of software engineering, focusing particularly on the three large-scale writing projects I'm supporting at the moment: Data Mesh, Patterns of Distributed Systems, and Patterns of Legacy Displacement.
Default Trial Retire
Within each normal-sized team, limit the choice of alternatives for any class of technology to three. These are: the current sensible default, the one we're experimenting with as a trial, and the one that we hate and want to retire.
The strong and weak forces of architecture
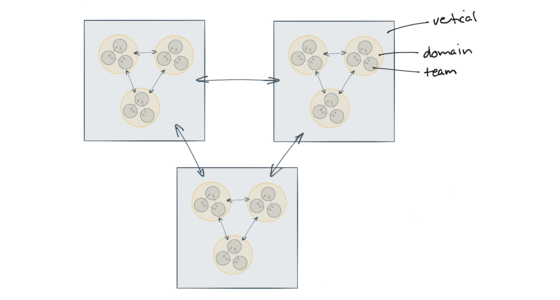
Good technical design decisions are very dependent on context. Teams that regularly work together on common goals are able to communicate regularly and negotiate changes quickly. These teams exhibit a strong force of alignment, and can make technology and design decisions that harness that strong force. As we zoom out in a larger organisation an increasingly weak force exists between teams and divisions that work independently and have less frequent collaboration. Recognising the differences in these strong and weak forces allows us to make better decisions and give better guidance for each level, allowing for more empowered teams that can move faster.
Compliance in a DevOps Culture
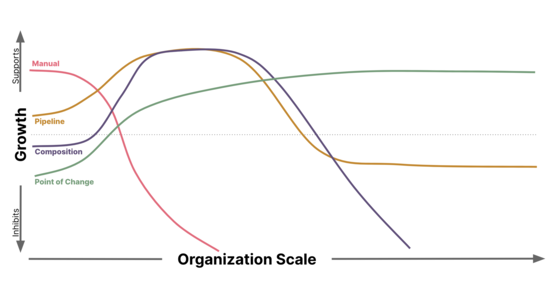
Integrating the necessary Security Controls and Audit capabilities to satisfy Compliance requirements within a DevOps culture can capitalize on CI/CD pipeline automation, but presents unique challenges as an organization scales. Understanding the second order implications and unintended consequences caused by the chosen implementation is key to building an effective, secure, and scalable solution.
Ship / Show / Ask
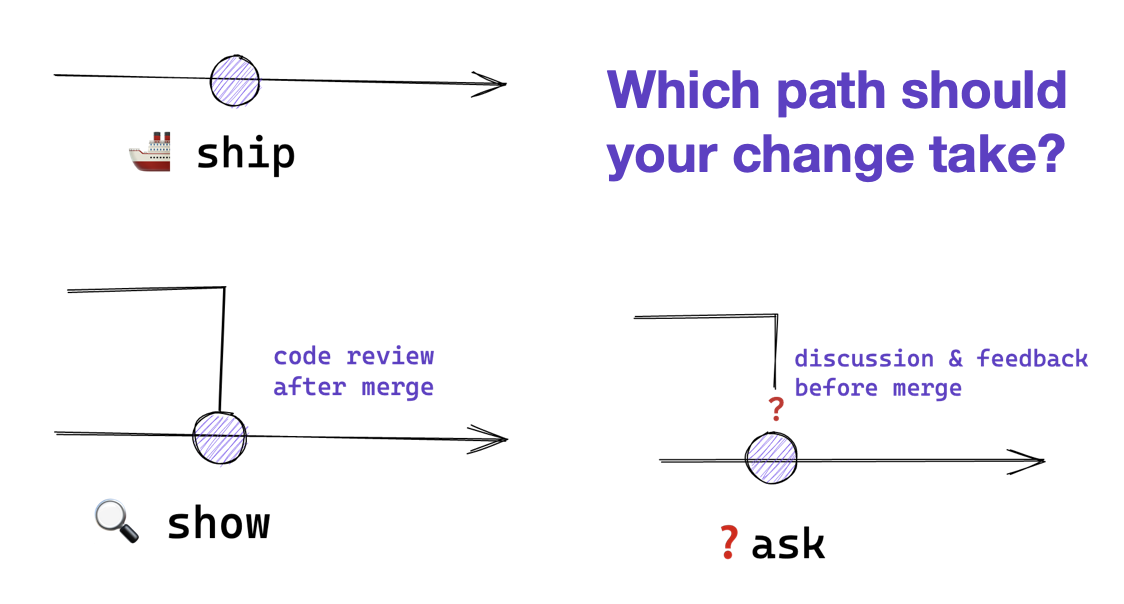
Ship/Show/Ask is a branching strategy that combines the features of Pull Requests with the ability to keep shipping changes. Changes are categorized as either Ship (merge into mainline without review), Show (open a pull request for review, but merge into mainline immediately), or Ask (open a pull request for discussion before merging).
Pattern: Gateway
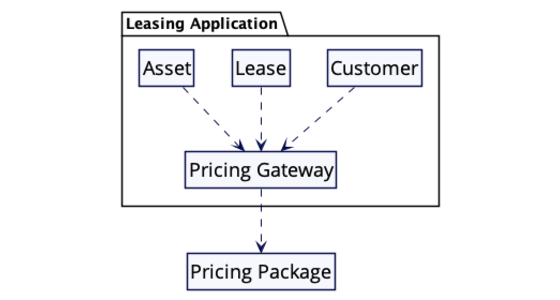
Interesting software rarely lives in isolation. The software a team writes usually has to interact with external systems, these may be libraries, remote calls to external services, interactions with a database, or with with files. Usually there will be some form of API for that external system, but that API will often seem awkward from the context of our software. The API may use different types, require strange arguments, combine fields in ways that don't make sense in our context. Dealing with such an API can result in jarring mismatches whenever its used.
A gateway acts as a single point to confront this foreigner. Any code within our system interacts with the interface of the gateway, which is designed to work in the terms that our system uses. The gateway then translates this convenient API into the API offered by the foreigner.
Stepping Back from Speaking
Giving talks has been one of the pillars of my career. I've given keynotes at software events all over the world. Some of these talks have tens, even hundreds, of thousands of views on youtube. But I've long loathed giving talks, and thus decided to retire from giving them.
On the Diverse And Fantastical Shapes of Testing
There are arguments about whether a testing portfolio should be a pyramid or more like honeycomb. My second biggest issue with this argument is that it's rendered opaque by the fact that it's not clear what people see as the difference between unit and integration tests.
Mind the platform execution gap
Developer productivity platforms are increasingly recognised as a way to manage the cognitive load of engineering teams and decrease time to market for new features. However, there are baseline capabilities that organisations need to cultivate in order to successfully execute on a plaform strategy. The platform team needs to think of the platform as a software product, needing dialog with its users, attention to reliable operations, and a healthy team environment.
Muted spaghetti line charts with R's ggplot2
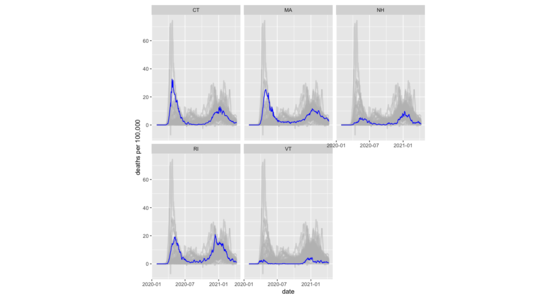
How I plot a muted-spaghetti chart with R, including facets.
Bitemporal History
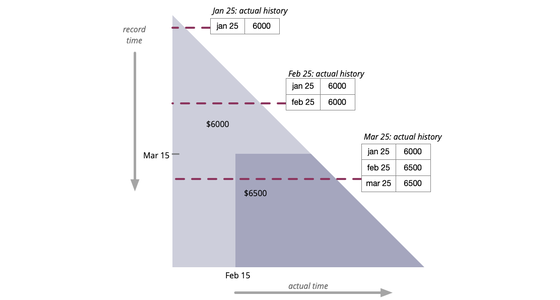
It's often necessary to access the historical values of some property. But sometimes this history itself needs to be modified in response to retroactive updates. Bitemporal history treats time as two dimensions: actual history records what history should be given perfect transmission of information, while record history captures how our knowledge of history changes.
Refinement Code Review
When people think of code reviews, they usually think in terms of an explicit step in a development team's workflow. These days the Pre-Integration Review, carried out on a Pull Request is the most common mechanism for a code review, to the point that many people witlessly consider that not using pull requests removes all opportunities for doing code review. Such a narrow view of code reviews doesn't just ignore a host of explicit mechanisms for review, it more importantly neglects probably the most powerful code review technique - that of perpetual refinement done by the entire team.
Pull Request
Pull Requests are a mechanism popularized by github, used to help facilitate merging of work, particularly in the context of open-source projects. A contributor works on their contribution in a fork (clone) of the central repository. Once their contribution is finished they create a pull request to notify the owner of the central repository that their work is ready to be merged into the mainline. Tooling supports and encourages code review of the contribution before accepting the request. Pull requests have become widely used in software development, but critics are concerned by the addition of integration friction which can prevent continuous integration.
Maximizing Developer Effectiveness
Technology is constantly becoming smarter and more powerful. I often observe that as these technologies are introduced an organization’s productivity instead of improving has reduced. This is because the technology has increased complexities and cognitive overhead to the developer, reducing their effectiveness. In this article, the first of a series, I introduce a framework for maximizing developer effectiveness. Through research I have identified key developer feedback loops, including micro-feedback loops that developers do 200 times a day. These should be optimized so they are quick, simple and impactful for developers. I will examine how some organizations have used these feedback loops to improve overall effectiveness and productivity.
The Lies that can Undermine Democracy
Recent events highlight our need to take serious measures to counter lies that are undermining democracies.