
during: 2020
My favorite musical discoveries of 2020

Six of my favorites new music acquisitions in 2020
Data Mesh Principles and Logical Architecture
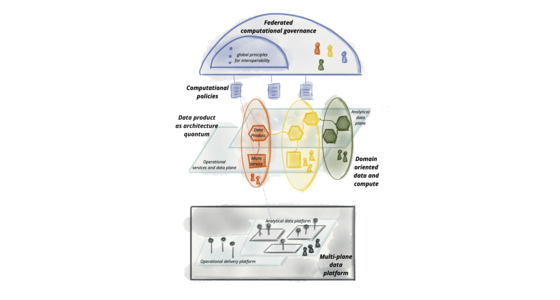
Our aspiration to augment and improve every aspect of business and life with data, demands a paradigm shift in how we manage data at scale. While the technology advances of the past decade have addressed the scale of volume of data and data processing compute, they have failed to address scale in other dimensions: changes in the data landscape, proliferation of sources of data, diversity of data use cases and users, and speed of response to change. Data mesh addresses these dimensions, founded in four principles: domain-oriented decentralized data ownership and architecture, data as a product, self-serve data infrastructure as a platform, and federated computational governance. Each principle drives a new logical view of the technical architecture and organizational structure.
Computational Notebook
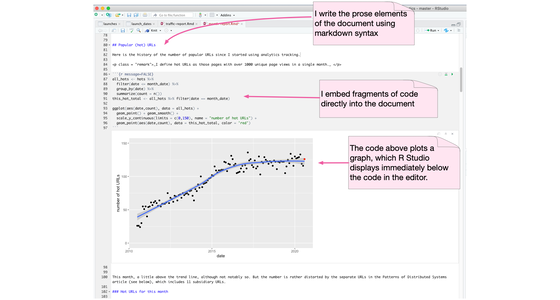
A computational notebook is an environment for writing a prose document that allows the author to embed code which can be easily executed with the results also incorporated into the document. It's a platform particularly well-suited for data science work. Such environments include Jupyter Notebook, R Markdown, Mathematica, and Emacs's org-mode.
Don't put data science notebooks into production
We've come across many clients who are interested in taking the computational notebooks developed by their data scientists, and putting them directly into the codebase of production applications. Data science ideas do need to move out of notebooks and into production, but trying to deploy that notebooks as a code artifact breaks a multitude of good software practices. Predictably, that results in a number of observed pain points. This behavior is a symptom of a deeper problem: a lack of collaboration between data scientists and software developers.
The Death of Goldman Sachs

A misleading title to draw readers into an occasionally true story
Should social media dampen uncertain stories?
When a news story of dubious provenance appears, should social media use a temporary block to slow its spread?
Thoughts writing a Google App script
A google sheets script is a handy way to share a short script for non-programmers.
Vote Against Trump, Again
Why it's important to vote against President Trump and his enablers.
Don't Compare Averages
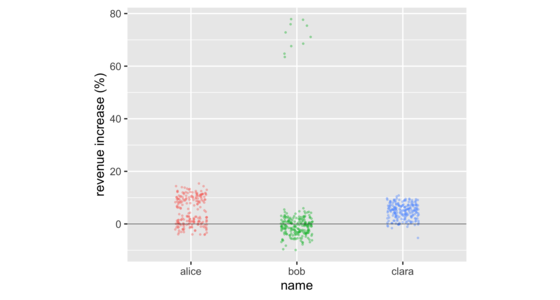
In business meetings, it's common to compare groups of numbers by comparing their averages. But doing so often hides important information in the distribution of the numbers in those groups. There are a number of data visualizations that shine a light on this information. These include strip charts, histograms, density plots, box plots, and violin plots. These are easy to produce with freely available software, working on groups as small as a dozen, or as large as thousands.
The Evolving Role of Data in Software Development
Unable to travel to Australia for their 2020 XConf, I instead had a zoom conversation with Scott Shaw: Thoughtworks Head of Technology for Australia. We talked about the changing role data plays in modern application development: the divide between application developers and databases, the changes due to the appearance of big (and messy) data, the need to improve data literacy, and the societal impact of hoovering up speculative data.
Interview with Sam Newman about Microservices
goto conferences asked me to do an interview with Sam Newman on his book: “Monoliths to Microservices”. This turned into a general conversation about microservices and when to use them. Sam considers the three main reasons for them to be independent deployability, isolation of data, and reflecting the organizational structure. I'm more skeptical of the first, but consider data and people to be complicated parts of software development.
Coup 53

A short review of Coup 53: a documentary of the coup in Iran in 1953.
Kinesis Advantage2 - Review after three years of use

A brief review of the Kinesis Advantage2 ergonomic keyboard, now I've been using it for three-and-a-half years.
It's Different with Data
Em Grasmeder, our European “Data Witch”, and I had planned to keynote our XConf series in Europe. Being 2020, instead we Zoomed, and talked about the role of data scientists: what the role actually is, the tools they need to acquire, and their relationship with other forms of software development.
Patterns for Managing Source Code Branches
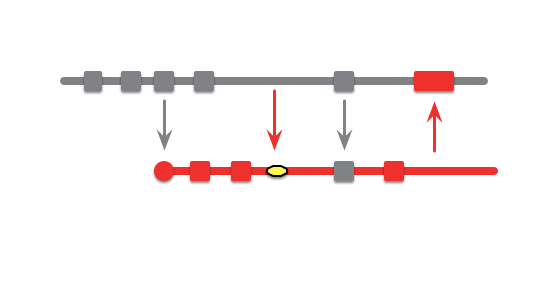
Modern source-control systems provide powerful tools that make it easy to create branches in source code. But eventually these branches have to be merged back together, and many teams spend an inordinate amount of time coping with their tangled thicket of branches. There are several patterns that can allow teams to use branching effectively, concentrating around integrating the work of multiple developers and organizing the path to production releases. The over-arching theme is that branches should be integrated frequently and efforts focused on a healthy mainline that can be deployed into production with minimal effort.
Feature Branch
A feature branch is a source code branching pattern where a developer opens a branch when she starts working on a new feature. She does all the work on the feature on this branch and integrates the changes with the rest of the team when the feature is done.
Dark Launching
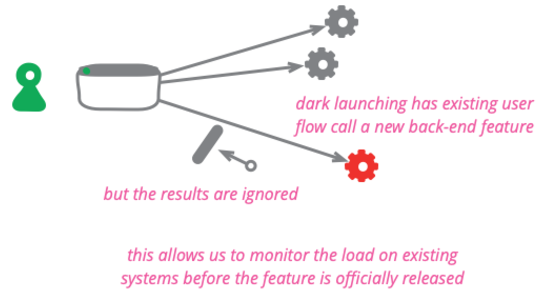
Dark launching a feature means taking a new or changed back-end behavior and calling it from existing users without the users being able to tell it's being called. It's done to assess the additional load and performance impacts upon the system before making a public announcement of the new capability.
Humble Object
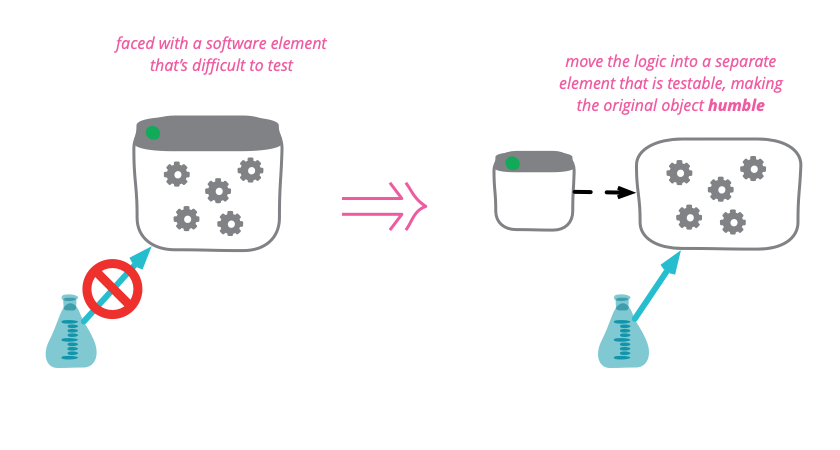
Some program elements are inherently difficult, or even impossible to test. Any logic in these elements is thus prone to bugs and difficult to evolve. To mitigate this problem, move as much as logic as possible out of the hard-to-test element and into other more friendly parts of the code base. By making untestable objects humble , we reduce the chances that they harbor evil bugs.
Keystone Interface
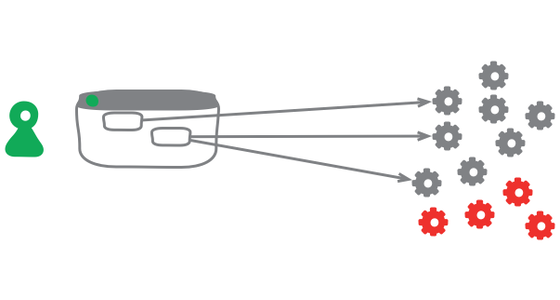
Software development teams find life can be much easier if they integrate their work as often as they can. They also find it valuable to release frequently into production. But teams don't want to expose half-developed features to their users. A useful technique to deal with this tension is to build all the back-end code, integrate, but don't build the user-interface. The feature can be integrated and tested, but the UI is held back until the end until, like a keystone, it's added to complete the feature, revealing it to the users.
Domain Driven Design
Domain-Driven Design is an approach to software development that centers the development on programming a domain model that has a rich understanding of the processes and rules of a domain. The name comes from a 2003 book by Eric Evans that describes the approach through a catalog of patterns. Since then a community of practitioners have further developed the ideas, spawning various other books and training courses. The approach is particularly suited to complex domains, where a lot of often-messy logic needs to be organized.
Refactoring: This class is too large
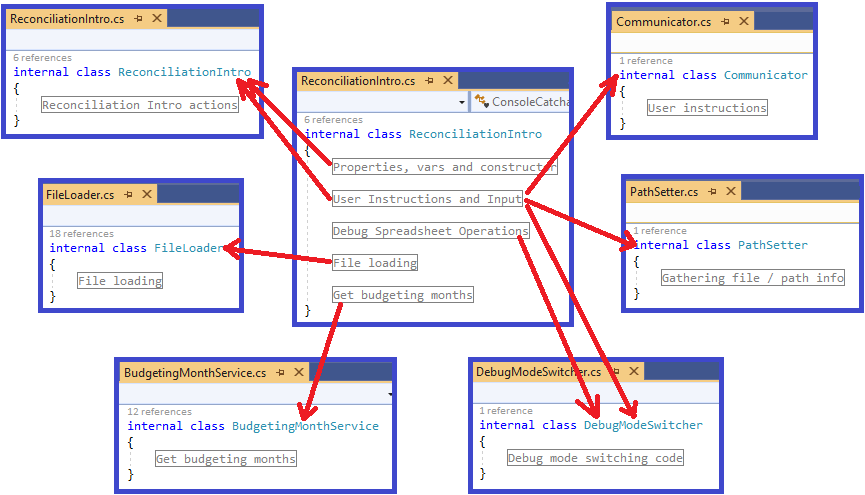
In this article I walk through a set of refactorings from a real code base. This is not intended to demonstrate perfection, but it does represent reality.
Pair Programming
Pair Programming is a software development practice that has the developers work in groups of two. All serious code is written by two programmers, typically sitting side-by-side with a single monitor, often with a single keyboard. As they add code, they discuss each step together.
How to do effective video calls
Get good audio, use gallery view, mute if not talking, and welcome the cat.
Coping with Covid-19, part 2
A second post on how Thoughtworks is coping with the Coronavirus Disease 2019 (Covid-19) outbreak
The Elephant in the Architecture
We, and our colleagues, are often called on to perform architectural assessments for our clients. When we do this, the architects involved with these systems will talk about the performance of these systems, how resilient they are to faults, and how they are designed to evolve to easily support new capabilities. The elephant that rarely comes up, however, is how different systems contribute to business value, and how this value interacts with these other architectural attributes.
Coping with Covid-19
What we've learned so far from dealing with the Coronavirus Disease 2019 (Covid-19) outbreak
Product-Service Partnerships
When customer companies buy software products, they usually need skilled staff to install them. This staff is usually provided by a service provider company, since software product vendors don't find it makes business sense to build their own services arm. Customers need to be aware of the relationship between product vendors and service providers, and should require transparency on the relationship from those they work with. A transparency that is increasingly important as these partnerships grow in prominence with the rise of cloud vendors.
Outcome Over Output
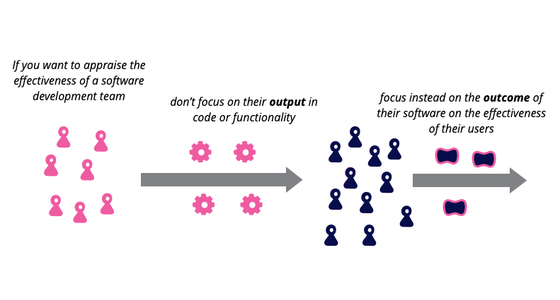
Imagine a team writing software for a shopping website. If we look at the team's output, we might consider how many new features they produced in the last quarter, or a cross-functional measure such as a reduction in page load time. An outcome measure, however, would consider measure increased sales revenue, or reduced number of support calls for the product. Focusing on outcomes, rather than output, favors building features that do more to improve the effectiveness of the software's users and customers.
How to manage a program in a product-mode organization
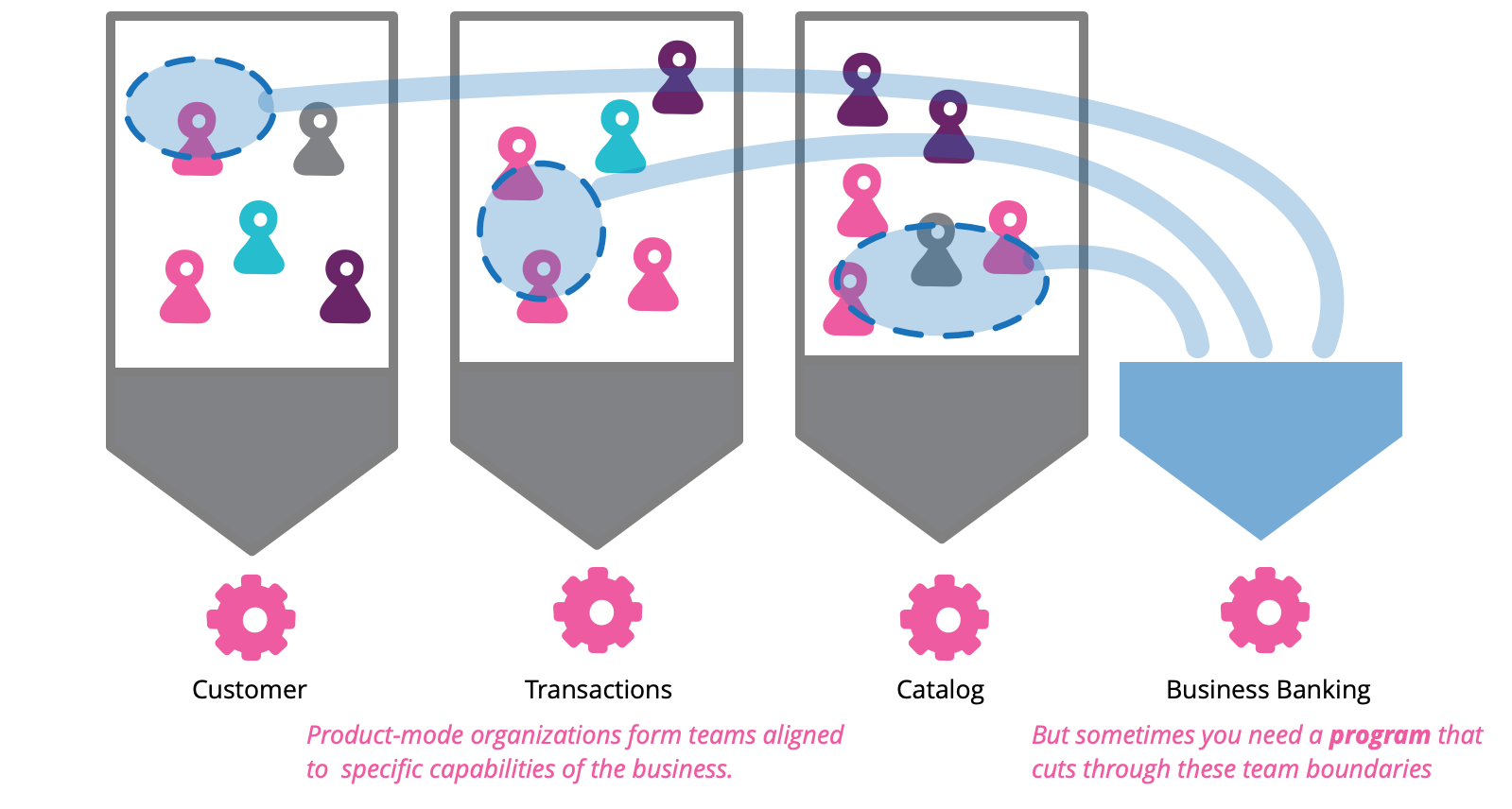
In their ideal state, product-mode organizations are formed of loosely coupled, autonomous teams that respond rapidly to articulated and unarticulated user needs. On occasion however, opportunities arise that require a response involving coordination across multiple teams. If not managed effectively the outcome will result in missed revenue, unsatisfied customers and wasted team capacity. We refer to the organizational initiatives that respond to these opportunities as programs. In this article, we’ll share our experience managing programs in product-mode organizations through an example of a program gone bad.
On Pair Programming
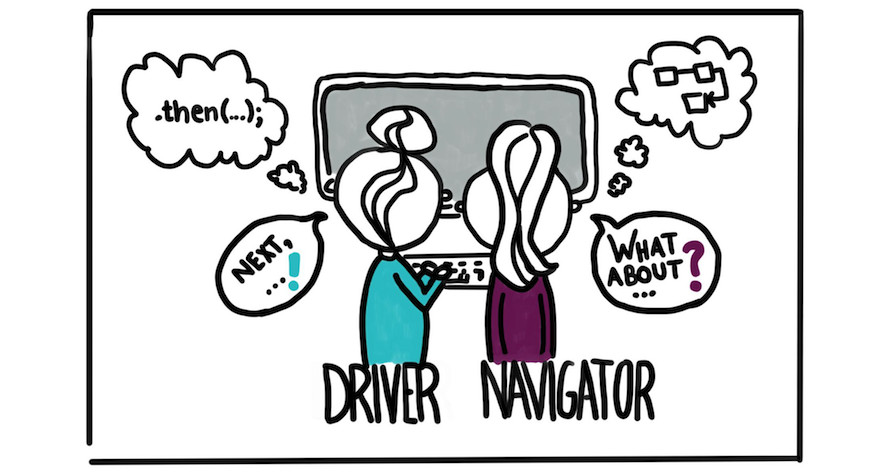
Many people who work in software development today have heard of the practice of pair programming, yet it still only has patchy adoption in the industry. One reason for its varying acceptance is that its benefits are not immediately obvious, it pays off more in the medium- and long-term. And it's also not as simple as “two people working at a single computer”, so many dismiss it quickly when it feels uncomfortable. However, in our experience, pair programming is vital for collaborative teamwork and high quality software.