
Refactoring: This class is too large
An example of refactoring from a real (flawed) code base.
In this article I walk through a set of refactorings from a real code base. This is not intended to demonstrate perfection, but it does represent reality.
14 April 2020

Writer, speaker, asker of questions and enthusiast of Extreme Programming - Clare is an ex high school maths teacher and a consultant with 20 years of software engineering experience. She is on a mission to awaken the inner geek in people everywhere - particularly those not traditionally encouraged to geek out.
Contents
- Outline of the problem
- Why refactor?
- How do I do it?
- 1. Rearrange methods
- 2. Analyse relationships between file-loading methods
- Plan of action
- 3. Modify the methods that are staying behind
- 4. Create covering tests for the new FileLoader class
- 5. Create new FileLoader class and move two methods
- 6. Move the other methods to the new FileLoader class
- 7. Extract more new classes
- Recap
- What's next?
Sidebars
- Language and approach
- How to avoid getting here in the first place
- How to read this article
- Principle: Always commit moves and renames separately from edits.
- Abbreviated method names
- Principle: Do one thing at a time. Focus!
- Automated refactorings
- A note on member variables
- A note on the order of the commits
- The reality: Most teams own problematic code
This is a story about refactoring. It's the third item in the TDD red-green-refactor cycle1 and it's the thing we do all the time, right? Except when we don't.
1: TDD stands for Test-Driven Development, a technique to ensure that all units of code are tested, and that the tests describe the behaviour of the system. This is done by writing the tests before you write the code to make those tests pass. There's a lot more that can be said about it, but it's not the focus of this article. You can read more about it here.
I have an unruly code base which has suffered from refactoring neglect, so I've been bringing it back into line. In this article I will take a class that is too large, and make it smaller.
Outline of the problem
The story begins with a boring domestic chore. I've written some personal accounting software - Reconciliate. It works on the command line and performs the following actions:
- Loads my own comma-separated data:
- My record of recent bank and credit card transactions.
- My predicted monthly and annual transactions (based on data in a central spreadsheet).
- Any unreconciled previously-recorded data.
- Loads third-party comma-separated data (from bank and credit card companies).
- Reconciles the third-party data against my own data.
- Writes everything back to a central spreadsheet.
I have some bugs that need fixing and some features to add. But my typical workflow is to arrive at the laptop late at night after putting my youngest to bed, with only a small amount of time before it will be my bedtime, and often a few weeks after the last time I saw the code. In these circumstances it's horribly easy to think things like, “Well I know this code is a mess, but I don't have time to get my head round it and fix it now...”
Clearly this is not ideal.
There's one class in particular - the ReconciliationIntro class
- which is giving me a headache
whenever I look at it. It's bloated and convoluted and impossible to fit
in my head 2. This has created a nasty
feedback loop: “Because this code is
so hard to reason about, refactoring will take more time and energy than I
have, so I'll put up with it even longer - even though it means I can't
even make small changes any more because it takes so long for me to
understand the code's current state and decide where the change should
go.”
2: “Fits In My Head” is one of the patterns in Dan Terhorst-North's Software, Faster book (a work still in progress). He talks about the importance of being able to comprehend any chunk of code by “fitting it in your head.” The name came from James Lewis, and Dan describes it in this talk, but Dan tells me the concept may have originated with Alistair Jones.
For instance, I want to add the ability to handle another credit card.
In a lot of places I've used
polymorphism
and the strategy pattern
to keep the unique behaviour of each credit card neatly encapsulated. But
the ReconciliationIntro class is one place where, because of the poor
design of the code and the lack of clear
context separation,
if I add another
credit card I'll be making an already bloated class even worse. It
contains four duplicated code paths for each of four types of data (Bank In,
Bank Out, Credit Card 1 and Credit Card 2), and if I add Credit Card 3
right now I'll end up following the same anti-pattern.
My overall aim is to replace this code with more generic code, via the strategy pattern 3. But there are four problems standing in my way:
3: Refactoring to the strategy pattern: A large part of the aim of this refactoring is to enable use of the strategy pattern. The business of “refactoring to patterns” has a whole book devoted to it, by Joshua Kerievsky - and is worth a read if you want to know more. Indeed as Martin Fowler says, “Many people have said they find a refactoring approach to be a better way of learning about patterns, because you see in gradual stages the interplay of problem and solution.”
- This one large class, (
ReconciliationIntro), is taking too much responsibility. - There's a lot of private nested code, which is hard to unit-test because it has no public interface.
- Within
ReconciliationIntro, there's one large method that's doing too much. - There are several methods in
ReconciliationIntrowhich use the same repeated pattern but with different details.
I plan to fix all of these problems, in the order listed above. This preparatory refactoring will get me to the point where I can easily encapsulate the behaviour of each credit card / account. As Kent Beck says, “Make the change easy, then make the easy change.”
This article is about tackling the first problem in the above list: This class is too large.
Why refactor?
I can't easily reason about the ReconciliationIntro class because it
has too many responsibilities. It was originally designed as the
entrance hall to the software, and all it did was display a few messages
and then instantiate the classes that do the main work.
But over time a lot of other code has snuck in. I want to make it easier to add
another credit card, so I'm going to start
by breaking this large class into smaller classes.
The benefits will be several:
- By moving groups of methods into separate classes I'll create clear contexts and minimise tight coupling. This means that:
- I'll know where to go when I want to make changes or fix issues.
- When I amend the code, I'll only have to work with small isolated sections that fit in my head 2 - I won't have to understand the whole system.
- Any manipulation of state will only happen locally in a small context - so I won't have to worry about one area of the system changing state in another.
2: “Fits In My Head” is one of the patterns in Dan Terhorst-North's Software, Faster book (a work still in progress). He talks about the importance of being able to comprehend any chunk of code by “fitting it in your head.” The name came from James Lewis, and Dan describes it in this talk, but Dan tells me the concept may have originated with Alistair Jones.
How do I do it?
To my mind, the most important principle when refactoring (and when writing new code) is to move in tiny steps. I have several connected aims:
- At every step, I want the code to compile and the tests to run.
- If a change causes any tests to fail, I want to be able to fix them instantly. By making small changes and small commits, I can see which change caused the tests to fail and I only need to rewind / examine a small amount of code to find the problem.
- I can keep track of where I am in in my head. It's horribly easy to embark on a relatively simple refactor, only to find it has repercussions beyond your original intention. At this point, if you're not in the habit of keeping the code compiling and the tests passing at every step, you can find yourself lost in a rabbit hole that's difficult to exit: Your code isn't compiling and your tests aren't even running, let alone passing.
For this to work, I need the code being refactored to be covered by tests. This has already been done before I start refactoring, although it's worth noting that one of my aims in a future refactoring will be to make the code even more testable.
Refactoring, by Martin Fowler is a recommended further read and lays out some basic refactoring principles. He also emphasises the value of moving in tiny steps and building the code / running your tests after every small commit.
Beyond these basic principles, I'll aim to follow a logical series of steps which are outlined below.
1. Rearrange methods
I'll start by using regions to rearrange all the
methods in the ReconciliationIntro class into sensible
groupings (commit f2d9932) 4:
4: Commit links: Don't feel obligated to follow the commit links! More on that in the How to read this article sidebar.
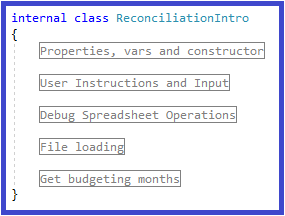
Figure 1: ReconciliationIntro after methods rearranged into regions
Now that I've grouped my methods into what feels like a reasonable set of
contexts,
I'd like to pull these out into separate classes. But where to
start? The file loading code contains the most duplication, and is causing the
most pain. Ultimately I want to make this code more generic, but first I want to
pull it out so I can see it without distraction. I'll extract a new FileLoader
class. The other groupings will also become separate classes but they'll be a
lot simpler, so I'll focus most of this article on the file-loading code.
2. Analyse relationships between file-loading methods
So far all I've done is move some code around in the same class. I rebuilt the code and ran all the tests before I committed, but unless I was clumsy I'd expect my previous commit to be trivial. I need to be a little more thoughtful about what I do next.
I've used one of my regions to identify methods to pull out into
a new FileLoader
class, but how can I be sure this will work? Are there any hidden
dependencies? I'll discover this by drawing out the relationships
between the methods I want to move. The ones to be moved are marked in
blue.
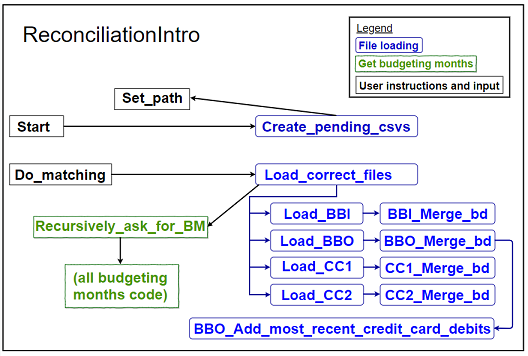
Figure 3: File-loading methods to be moved (abbreviations)
I can see straight away that it's not a strictly self-contained context: Some of the blue methods are calling back out to methods (shown in black and green) that I want to keep in a separate class. There are a couple of ways I could handle this, which I discuss below. But now I'm at a place where I can define a plan of action.
Plan of action
By the time I'm done, the original large ReconciliationIntro class
will have been broken down into
the pared-down version plus five new classes, as shown in
the diagram below. Note that there isn't a one-to-one mapping between
regions and classes, because later on when I reach
step 7, I'll end up refining my first groupings
into some finer-grained boundaries.
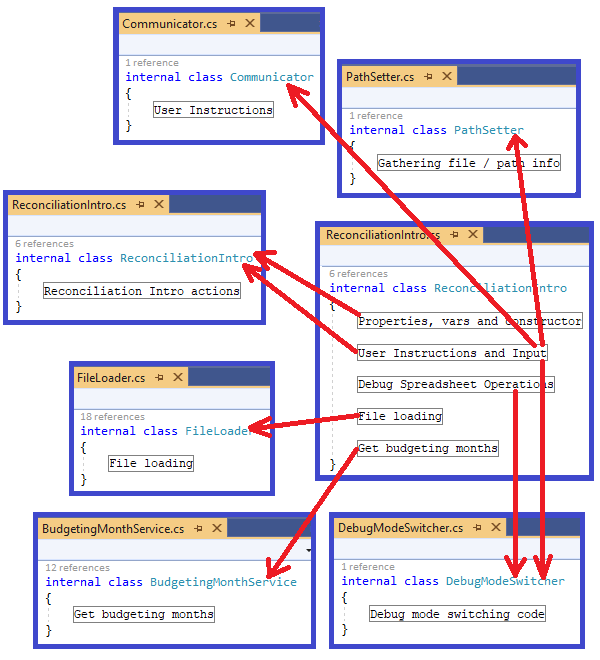
Figure 4: Plan of action
My overall aim is to break this large class down into smaller classes. In steps 1 and 2 above, I used regions and a diagram to identify distinct areas of code and then analyse relationships between some of the methods. That gave me enough information to start thinking about how I can tackle this job in tiny steps.
The resulting plan is summarised below and then described in detail further down. I reached this plan by thinking about how I could proceed using steps that were as small as possible. Often what I'm doing is setting things up so that the next change will be as small and simple as possible. I'm making small changes to facilitate more small changes - yet again following Kent Beck's dictum to “Make the change easy, then make the easy change.”
Depending on your circumstances you might not follow the same plan, but it's not a bad template if you're not sure how to proceed. Your priority is to set yourself up for safe incremental changes:
-
Group all the methods in the class into sensible groupings, as described above.
-
Analyse relationships between file-loading methods
Identify how the file-loading code is connected to the rest of the code in the
ReconciliationIntroclass, as described above. -
Modify the methods that are staying behind
There are methods which will stay in the parent class but are currently called by those that are moving. Some modification will be required to make this work.
-
Create covering tests for the new
FileLoaderclassThe new
FileLoaderclass needs to be covered by tests. The tests for the code to be moved already exist, but they'll be moved into a newFileLoaderTestsclass. -
Create new
FileLoaderclass and move two methodsFollowing the principle of tiny steps, I'll move just two methods (a public method and a private method called by it) before I move the rest.
-
Move the other methods to the new
FileLoaderclassThis is where it gets exciting. All that file-loading code I'm interested in will finally get a new home!
-
Once I've dealt with the file-loading code, I'll create some more new classes for the other code regions.
The new FileLoader class will be responsible for loading various
sources of comma-separated data and merging them ready for reconciliation.
This file-loading code is where most of the pain currently lies, so that's the
bit I'll describe in the most detail.
You can see the original code before refactoring here, but if you follow that link all you'll
learn is that it's too big to fit in your head! The slimmed down
post-refactor version is here.
So, now I can continue with the plan:
3. Modify the methods that are staying behind
I've identified two methods - Set_path and
Recursively_ask_for_budgeting_months - which are called by file-loading
methods:
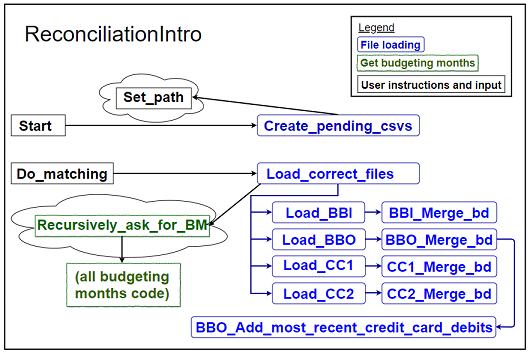
Figure 5: Methods called by file-loading methods (abbreviations)
As long as those methods are not too tightly coupled with the file-loading class, I can either
- Make them public so I can call back to them from
the new
FileLoaderclass. - Move the client calls out of the file-loading code and into other native
ReconciliationIntromethods instead.
I'll use the first approach for Recursively_ask_for_budgeting_months and
the second for Set_path, which will bring me to the following situation:
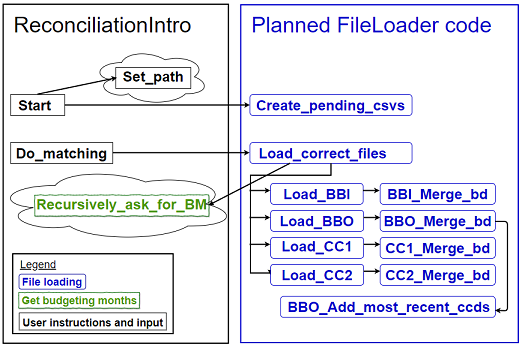
Figure 6: File-loading methods after moving (abbreviations)
Note that the methods marked as FileLoader methods in the diagram
will still be in the ReconciliationIntro class at the end of this step,
but this will enable me to move them into the FileLoader class, which
will happen in step 5
and step 6 below.
Recursively_ask_for_budgeting_months will eventually be a public
method in another class, but for now I just want to make sure I can call
it from elsewhere. It turns out it already is public, which was done so
that it could be tested. This in itself is a code smell - it's a sign
that it would be better off as part of the public interface of a separate
class.
The other method called from the file-loading code is Set_path. This
changes the value of an internal path variable, so I'll choose option 2:
I'll call it separately and pass the resulting data into the file-loading
method via a parameter.
Note that these might not normally stay as separate commits (I could use micro-commits and then squash them into larger commits), but I'm keeping the small commits intact to make the steps clear. I compile and run the tests at every step:
-
Modify the calling method (
Create_pending_csvs) so that it takes a parameter, but initially give it a default value (commit acc3519) 4 so that the code still compiles:4: Commit links: Don't feel obligated to follow the commit links! More on that in the How to read this article sidebar.
private void Create_pending_csvs() { // Some code }⇓private void Create_pending_csvs(string path = "") { // Some code } -
Call
Set_pathseparately before callingCreate_pending_csvs. Take the resulting new_pathmember variable (see sidebar), and pass it intoCreate_pending_csvs(commit c5ebc2f) 4:4: Commit links: Don't feel obligated to follow the commit links! More on that in the How to read this article sidebar.
case "1": { Create_pending_csvs(); } break;⇓case "1": { Set_path(); Create_pending_csvs(_path); } break; -
Remove the call to
Set_pathfrom withinCreate_pending_csvs, and use the passed-in value instead of the member variable (commit 6df8f97) 4:4: Commit links: Don't feel obligated to follow the commit links! More on that in the How to read this article sidebar.
private void Create_pending_csvs(string path = "") { try { Set_path(); var pending_csv_file_creator = new PendingCsvFileCreator(_path);⇓private void Create_pending_csvs(string path = "") { try { Set_path(); var pending_csv_file_creator = new PendingCsvFileCreator(path); -
Finally, remove the default value from the
Create_pending_csvsparameter - thereby forcing all clients to pass a value in (commit 2be56ea) 4. Note that by doing things in this order, I keep the code compiling at all times:4: Commit links: Don't feel obligated to follow the commit links! More on that in the How to read this article sidebar.
private void Create_pending_csvs(string path = "") { // Some code }⇓private void Create_pending_csvs(string path = "") { // Some code }
4. Create covering tests for the new FileLoader class
My first choice of method to move will be
Bank_and_bank_out_ _Merge_bespoke_data_with_pending_file. And the first
thing I want to do is copy any covering tests into a new test class for
the about-to-be-created FileLoader class. There is already one test
for this method -
M_MergeBespokeDataWithPendingFile_
WillAddMostRecentCredCardDirectDebits
- and its job is to make sure this method merges new direct debit data
correctly with a 'pending' file (which is being built to contain all new
transaction data).
Note that I'm only moving tests, not writing new ones. People can get so used to the TDD 1 concept of writing tests before writing code that they assume you need to write new tests whenever you work on code. This is often not the case when refactoring. Ideally my functionality will already be covered by tests, and when refactoring I'm not changing the functionality. So instead of writing new tests, I'm using the existing ones to verify the functionality still works as originally intended.
1: TDD stands for Test-Driven Development, a technique to ensure that all units of code are tested, and that the tests describe the behaviour of the system. This is done by writing the tests before you write the code to make those tests pass. There's a lot more that can be said about it, but it's not the focus of this article. You can read more about it here.
This is a good time to review this test: It's a while since I wrote
it, so I should be able to spot quickly whether it makes sense. I want
my tests to be clear and easy to read - they should act as documentation
for my system behaviour. The first thing I notice is that it contains an
assert method - Assert_direct_debit_details_are_correct - whose name
is inadequate. What is the definition of “correct”? I rewrite the test
to make it easier to read, which involves quite a lot of changes. In the
interest of keeping this a digestible read I won't go into the changes
made, but you can view them in commit f090f26
and commit 6a6cece. 4
4: Commit links: Don't feel obligated to follow the commit links! More on that in the How to read this article sidebar.
Now that I've refactored the test I'll copy it into a new test
class, along with some associated private helper methods. Note that
although this and other tests are destined to operate on a new
FileLoader class, they'll still act on the old ReconciliationIntro
class until I'm sure my new test class has everything it needs. Also
note that until everything is safely moved, my test code is duplicated.
I first create the new test class in the same file as the original (commit 491c795) 4, so that it's easy to see what I'm copying. Then I can get Resharper 5 and Visual Studio to move everything into a new file for me (commit c9317c0) 4.
4: Commit links: Don't feel obligated to follow the commit links! More on that in the How to read this article sidebar.
5: Resharper is a commonly-used Visual Studio extension used for things such as code editing. However it is not free, and is being increasingly eclipsed by native Visual Studio tooling.
4: Commit links: Don't feel obligated to follow the commit links! More on that in the How to read this article sidebar.
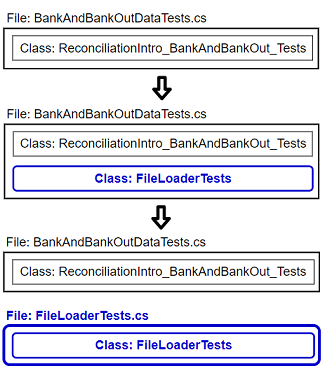
Figure 7: Move BBO tests
5. Create new FileLoader class and move two methods
Now that my test class is up and running, I can create the new
FileLoader class.
The method that's furthest down the chain - the lowest leaf in my
tree of methods - is
Bank_and_bank_out__Add_most_recent_credit_card_direct_debits. This is
a private method with no independent tests (it's tested via the public
calling method), so I'm going to move both it and its caller
(Bank_and_bank_out__Merge_bespoke_data_with_pending_file). These will
be the first two methods to be moved into my new class.
Again, I'll move in baby steps to avoid my tests going red and keep my code building at all times. After each of the following steps I make sure the code builds and the tests are passing.
-
This is the situation I begin with. A
FileLoaderTestsclass has been created, but it is testing code that still lives in theReconciliationIntroclass: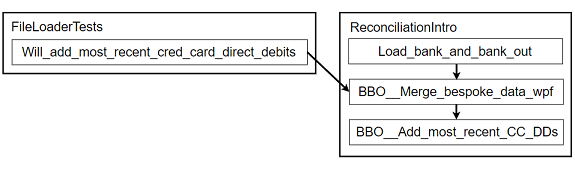
Figure 8: New FileLoader class part 1 (abbreviations)
-
I start by creating a new
FileLoaderclass. One of my file-loading methods (Bank_and_bank_out__ Add_most_recent_credit_card_direct_debits) is private, and will also be private at the end of this process. It will only ever be called by the method that's about to follow it into the new class. It's not individually covered by tests, so I can just copy it over to the new class and have it ready and waiting when its caller is moved (see commit 0341476) 4. But I will need to make it temporarily public:4: Commit links: Don't feel obligated to follow the commit links! More on that in the How to read this article sidebar.
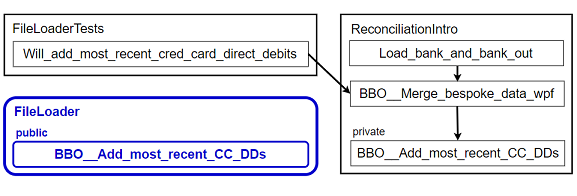
Figure 9: New FileLoader class part 2 (abbreviations)
-
Now I can create an instance of my new
FileLoaderclass in theReconciliationIntroclass and call its new public method, instead of the old private method. I can also delete the old private method (see commit bde2ae2) 4:4: Commit links: Don't feel obligated to follow the commit links! More on that in the How to read this article sidebar.
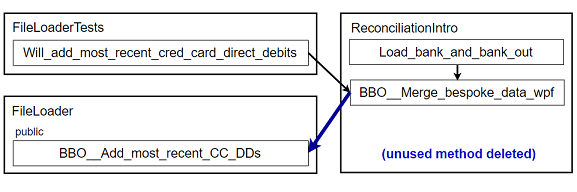
Figure 10: New FileLoader class part 3 (abbreviations)
-
Copy the original caller into the new class (see commit f0a5a59) 4. Note that at this point it's duplicated:
4: Commit links: Don't feel obligated to follow the commit links! More on that in the How to read this article sidebar.
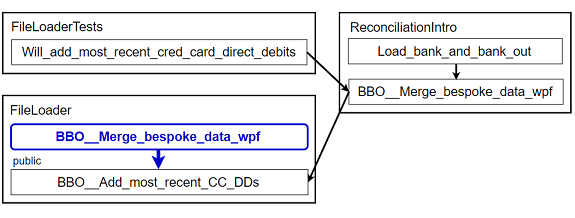
Figure 11: New FileLoader class part 4 (abbreviations)
-
Change the object I'm testing from being a
ReconciliationIntroinstance to being a newFileLoaderinstance. Point the tests at the new copy of the original caller. Note that because the private method it calls has also been copied, my tests will pass (see commit 3d573e3) 4:4: Commit links: Don't feel obligated to follow the commit links! More on that in the How to read this article sidebar.
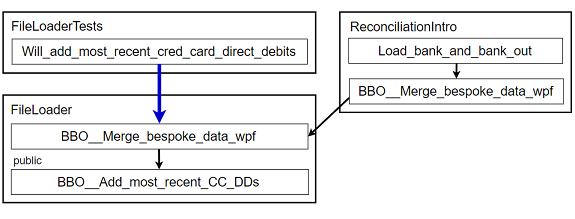
Figure 12: New FileLoader class part 5 (abbreviations)
-
Now I can call the original caller directly from the
ReconciliationIntroclass (see commit 77c0b14) 4:4: Commit links: Don't feel obligated to follow the commit links! More on that in the How to read this article sidebar.
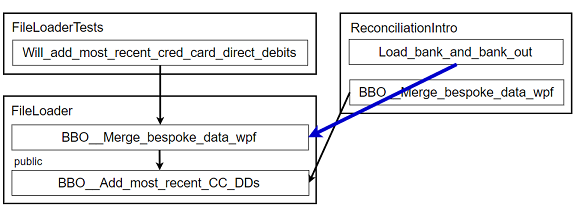
Figure 13: New FileLoader class part 6 (abbreviations)
-
Make the originally-private method private again, and delete the original caller. I'll delete the old test class too, as all its tests have now been duplicated in
FileLoaderTests. (see commit 27f1a59) 4:4: Commit links: Don't feel obligated to follow the commit links! More on that in the How to read this article sidebar.
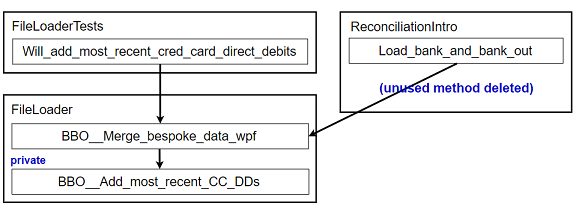
Figure 14: New FileLoader class part 7 (abbreviations)
6. Move the other methods to the new FileLoader class
Now I can move all the other methods. I'll handle them one by one, starting with the simplest and keeping an eye out for dependencies (between methods, and on any member data). I'll need to consider the following:
- Do I want to rename any methods?
- Do I want to replace any parameter lists with new objects?
- Are there any redundant parameters?
- Are any of the internal nested callees altering state? What impact does this have?
I could inline those lower down in the chain before moving them, but if I did I'd break the tests which call them as public methods. So instead I move them on their own. I do it in the order explained below, acting on one at a time and starting with those at the end of the chain - ie the outermost leaves on the following tree:
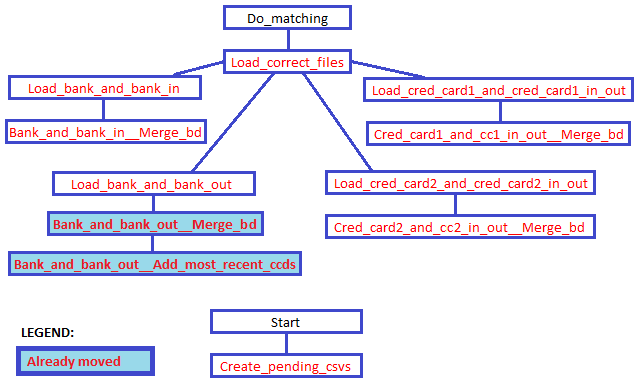
Figure 15: FileLoader method tree (abbreviations)
For each one, I use the following approach:
- Create a copy of the method in the destination class, keeping the original in place. Make the new method public.
- Call the new method instead of the original.
- Copy any covering tests into the new test class, and make sure they test the new code.
- Delete the old method and the old tests.
I already moved
Bank_and_bank_out__ Merge_bespoke_data_with_pending_file and
Bank_and_bank_out__ Add_most_recent_credit_card_direct_debits
(commit 0341476 to commit 27f1a59),
so now I repeat the same actions for each of the other
methods (commit 7cd53f6
to commit 7ab95f2) 4. I don't
commit every tiny step this time, but I still go through the same set of
steps. After each step, I make sure the code builds and the tests are
passing (apart from when I deliberately make a test fail).
4: Commit links: Don't feel obligated to follow the commit links! More on that in the How to read this article sidebar.
I refactored some tests earlier, and I can repeat those changes for tests that follow the same pattern. For some methods the move is very simple, because they have no test coverage. This is part of why I'm doing this refactor, to make that code more easily testable.
7. Extract more new classes
When adding regions at the start,
I identified some Get budgeting months functionality which
creates its own clear context,
so I extract these methods out into
a new BudgetingMonthService class. This is very quick and
simple because these methods only have one public entry point
(see commit 6103f0b) 4.
4: Commit links: Don't feel obligated to follow the commit links! More on that in the How to read this article sidebar.
ReconciliationIntro is still too big, but the methods all
call one another and now that I've spent more time refamiliarising myself
with the code I'm not convinced my two remaining regions of User
Instructions and Input and Debug Spreadsheet Operations are
the best ways of dividing the remaining code. To help myself think about
it, I use a spreadsheet to quickly illustrate the call hierarchy.
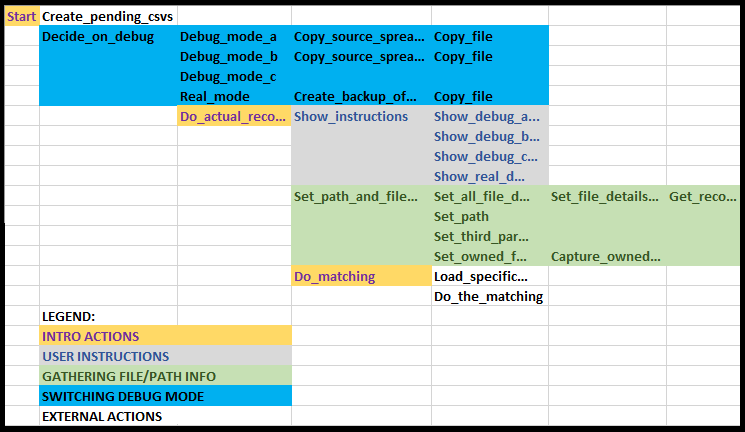
Figure 16: Call hierarchy
This allows me to see that there are THREE self-contained areas of
code, not two: User instructions, Gathering file / path info and
Debug mode switching code.
I remove the original regions (commit 4c57927) and replace
them with four new regions (commit 3446a54)
4. I rearrange the
methods to fit in the new regions, and these will now translate into three
new classes: Communicator, PathSetter and
DebugModeSwitcher (FileLoader and BudgetingMonthService
are not shown on this diagram because they have already been extracted):
4: Commit links: Don't feel obligated to follow the commit links! More on that in the How to read this article sidebar.
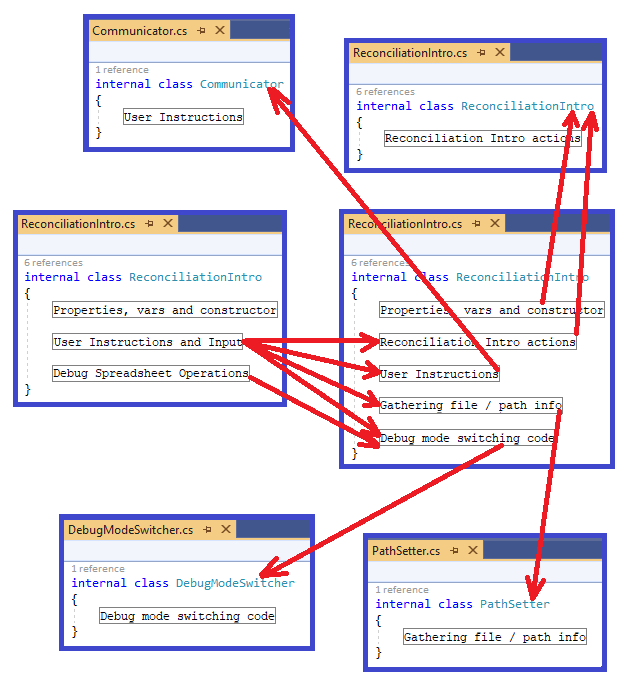
Figure 17: Identifying final ReconciliationIntro classes
I create these new classes gradually and safely using the same
principles as for BudgetingMonthService, removing the new regions once
they've served their purpose (see commit 7f464a4 to
commit 7e118c1).
It's worth noting that when extracting new classes from a larger class, I want them to be independent. For this reason I'm deliberately avoiding the anti-pattern which can sometimes arise, where extracted classes are automatically injected as a dependency into the constructor of the original class.
The PathSetter class turns out to be non-trivial - see
commit 2921220 to commit 398539a4. This is due to the
currently-slightly-tortuous nature of the path-setting code, something I
noticed at the end of
step 3. By extracting this code into a separate class and giving it
its own clear context,
I'm already making this code a bit better -
but it will still need some attention.
4: Commit links: Don't feel obligated to follow the commit links! More on that in the How to read this article sidebar.
Finally, my ReconciliationIntro class is
cleaner and simpler, and the
original 41 methods have been reduced to three:
Start, Reconciliate and
Do_matching:

Figure 18: Final ReconciliationIntro class
Recap
My class was too large. I had developed undesirable coding habits and I wanted to stop and make things better before adding any new functionality.
To fix my too-large class, I took the following actions:
- Rearranged methods into sensible groupings, to help identify new classes.
- Analysed
relationships between file-loading methods, so that I could work out
how to create a new
FileLoaderclass with minimum coupling with the rest of the code. - Modified the methods that were staying behind, so that they could be called by those that are moving (if necessary).
- Created covering
tests for the new
FileLoaderclass, by creating a newFileLoaderTestsclass. - Created the new
FileLoaderclass and moved two methods. - Moved the other
methods to the new
FileLoaderclass. - Extracted more new classes.
I moved in tiny steps, and I compiled and ran the tests at every step. Now I have a much smaller class which calls functionality from several other also-smaller classes, and each one of them is easier to fit in my head.
What's next?
Note that this article ends in the middle of the refactor, so if you want to see the relevant state of the code before moving on to the next steps, you need to checkout the commit 6103f0b. Note also that I completed most of step 7 in this article after that commit (explanation here).
At commit 6103f0b,
I've pulled the file-loading code out into the FileLoader class and have
a clearer view of the main challenge.
The following four methods (visible in situ here)
are clearly problematic:
Load_bank_and_bank_inLoad_bank_and_bank_outLoad_cred_card1_and_cred_card1_in_outLoad_cred_card2_and_cred_card2_in_out
They have the following problems:
- There is a lot of duplication - at a glance, they look identical.
- They are way too long.
- They create objects internally and pass them into one another in a closely inter-dependent way which is not testable.
These are all problems I want to solve, but before I do any more refactoring I really need some tests around those methods. That's what I'll do next. My desire is to write about it in a follow-up article, but I've learnt better than to make promises about that kind of thing, so for now it's an exercise for the reader.
Acknowledgements
Many thanks to the following people, who very kindly read early drafts of this article and contributed invaluable feedback and suggestions: Paula Paul, Martin Fowler, Priti Biyani, Riccardo Novaglia, Dan Terhorst-North, Kevlin Henney, Steve Freeman, Jon Skeet, Sal Freudenberg, Joe Ray, Chris Shepherd, Luke Morton, Scott Giminiani, Richard Foster, Marcos Bezerra, Sam Carrington.
Footnotes
1: TDD stands for Test-Driven Development, a technique to ensure that all units of code are tested, and that the tests describe the behaviour of the system. This is done by writing the tests before you write the code to make those tests pass. There's a lot more that can be said about it, but it's not the focus of this article. You can read more about it here.
2: “Fits In My Head” is one of the patterns in Dan Terhorst-North's Software, Faster book (a work still in progress). He talks about the importance of being able to comprehend any chunk of code by “fitting it in your head.” The name came from James Lewis, and Dan describes it in this talk, but Dan tells me the concept may have originated with Alistair Jones.
3: Refactoring to the strategy pattern: A large part of the aim of this refactoring is to enable use of the strategy pattern. The business of “refactoring to patterns” has a whole book devoted to it, by Joshua Kerievsky - and is worth a read if you want to know more. Indeed as Martin Fowler says, “Many people have said they find a refactoring approach to be a better way of learning about patterns, because you see in gradual stages the interplay of problem and solution.”
4: Commit links: Don't feel obligated to follow the commit links! More on that in the How to read this article sidebar.
5: Resharper is a commonly-used Visual Studio extension used for things such as code editing. However it is not free, and is being increasingly eclipsed by native Visual Studio tooling.
Significant Revisions
14 April 2020: first published