
tagged by: refactoring
Refactoring Guide
![]()
Refactoring is a disciplined technique for restructuring an existing body of code, altering its internal structure without changing its external behavior. Its heart is a series of small behavior preserving transformations. Each transformation (called a “refactoring”) does little, but a sequence of these transformations can produce a significant restructuring. Since each refactoring is small, it's less likely to go wrong. The system is kept fully working after each refactoring, reducing the chances that a system can get seriously broken during the restructuring.
The Second Edition of “Refactoring”

I'm finishing a new edition of my Refactoring book. Here's details and periodic memos about my work.
Refactoring with Codemods to Automate API Changes
Refactoring is something developers do all the time—making code easier to understand, maintain, and extend. While IDEs can handle simple refactorings with just a few keystrokes, things get tricky when you need to apply changes across large or distributed codebases, especially those you don’t fully control. That’s where codemods come in. By using Abstract Syntax Trees (AST), codemods allow you to automate large-scale code changes with precision and minimal effort, making them especially useful when dealing with breaking API changes. This article looks at how codemods can help manage these challenges, with practical examples like removing feature toggles or refactoring complex React components. We’ll also discuss potential pitfalls and how to avoid them when using codemods at scale.
Refactoring a JavaScript video store
The simple example of calculating and formatting a bill for a video store opened my refactoring book in 1999. If done in modern JavaScript, there are several directions you could take the refactoring. I explore four here: refactoring to top level functions, to a nested function with a dispatcher, using classes, and transformation using an intermediate data structure.
Changes for the 2nd Edition of Refactoring
A short summary of the changes between the first and second editions of Refactoring
Refactoring: This class is too large
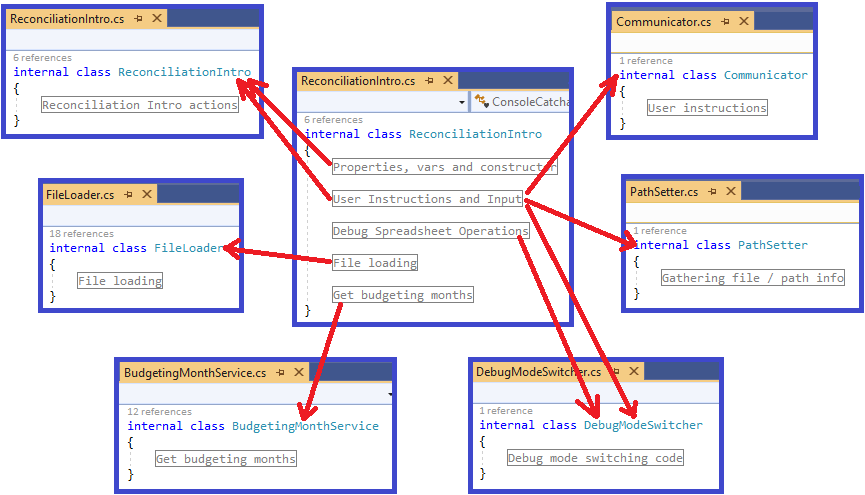
In this article I walk through a set of refactorings from a real code base. This is not intended to demonstrate perfection, but it does represent reality.
Refactoring Code to Load a Document
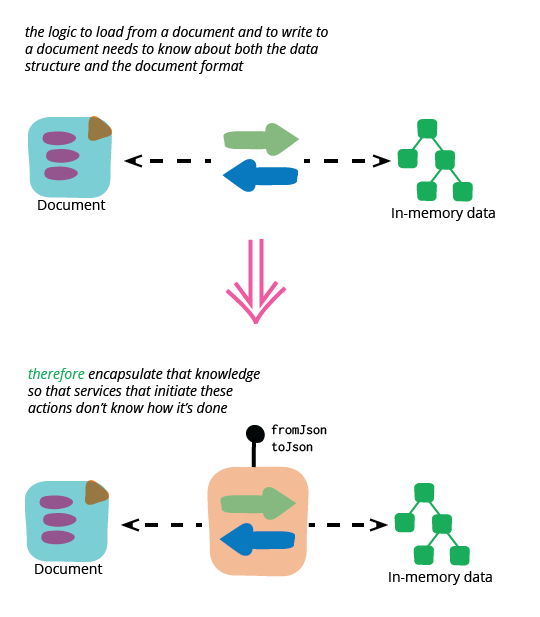
Much modern web server code talks to upstream services which return JSON data, do a little munging of that JSON data, and send it over to rich client web pages using fashionable single page application frameworks. Talking to people working with such systems I hear a fair bit of frustration of how much work they need to do to manipulate these JSON documents. Much of this frustration could be avoided by encapsulating a combination of loading strategies.
Refactoring to an Adaptive Model
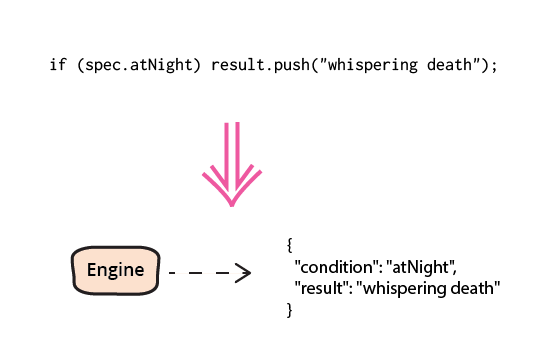
Most of our software logic is written in our programming languages, these give us the best environment to write and evolve such logic. But there are circumstances when it's useful to move that logic into a data structure that our imperative code can interpret - what I refer to as an adaptive model. Here I'll show some product selection logic in JavaScript and show how it can be refactored to a simple production rule system encoded in JSON. This JSON data allows us to share this selection logic between devices using different programming languages and to update this logic without updating the code on these devices.
Refactoring Module Dependencies
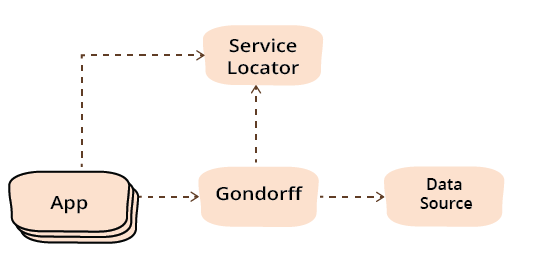
As a program grows in size it's important to split it into modules, so that you don't need to understand all of it to make a small modification. Often these modules can be supplied by different teams and combined dynamically. In this refactoring essay I split a small program using Presentation-Domain-Data layering. I then refactor the dependencies between these modules to introduce the Service Locator and Dependency Injection patterns. These apply in different languages, yet look different, so I show these refactorings in both Java and a classless JavaScript style.
Refactoring with Loops and Collection Pipelines

The loop is the classic way of processing collections, but with the greater adoption of first-class functions in programming languages the collection pipeline is an appealing alternative. In this article I look at refactoring loops to collection pipelines with a series of small examples.
Refactoring code that accesses external services
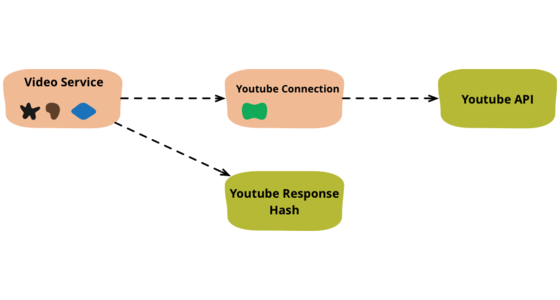
When I write code that deals with external services, I find it valuable to separate that access code into separate objects. Here I show how I would refactor some congealed code into a common pattern of this separation.
Replacing Throwing Exceptions with Notification in Validations

If you're validating some data, you usually shouldn't be using exceptions to signal validation failures. Here I describe how I'd refactor such code into using the Notification pattern.
An example of preparatory refactoring
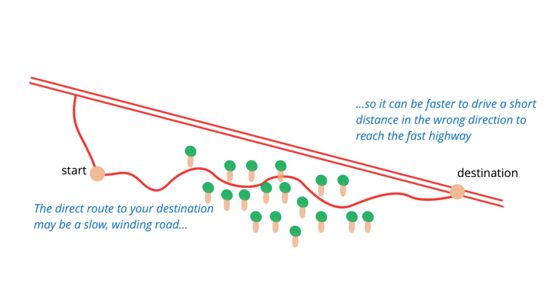
A simple example of how it can be easier to make a change by first refactoring the code to make the change easy.
Workflows of Refactoring
Refactoring has grown into a well-known technique, and most software development teams at least claim to be doing refactoring regularly. Many teams, however, don't appreciate the different workflows that refactoring can be used in, and thus miss opportunities to effectively incorporate refactoring into their development activities. In this deck I explore various different workflows. I hope it will encourage teams to integrate refactoring more deeply into their work, resulting in a better designed code-bases that will make it quicker and easier to add new features.
Agile Book Club: Refactoring
James Shore's Art of Agile Development is my favorite single-volume book on agile software development. A reason for that is its serious emphasis on the technical practices that are essential to making it work effectively. James and I discuss the role of refactoring for software development, the nature of design changes we see, and how to break down big changes into small pieces.
Workflows of Refactoring (OOP 2014)
Over the last decade or so, Refactoring has become a widely used technique to keep a high internal quality for a codebase. However most teams don't make enough use of refactoring because they aren't aware of the various workflows in which you can use it. In this keynote talk from OOP 2014 in Munich, I explore some of these workflows: such as Litter-Pickup Refactoring, Comprehension Refactoring, and Preparatory Refactoring. I also remind people why common justifications for refactoring will sabotage your best efforts. (This talk also has a treatment as an infodeck.)
Evolutionary Database Design
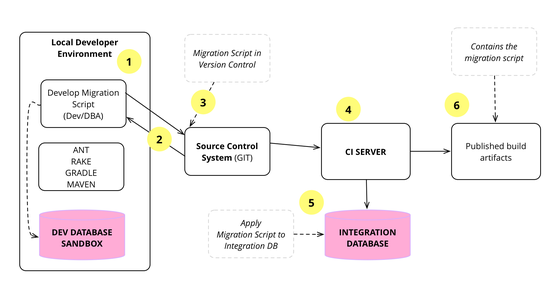
Over the last decade we've developed and refined a number of techniques that allow a database design to evolve as an application develops. This is a very important capability for agile methodologies. The techniques rely on applying continuous integration and automated refactoring to database development, together with a close collaboration between DBAs and application developers. The techniques work in both pre-production and released systems, in green field projects as well as legacy systems.
Ruby Rogues Podcast on Refactoring
The Ruby Rogues is a popular podcast on programming in the Ruby world. They invited me back to discuss the Ruby edition of Refactoring. We talked about the definition of refactoring, why we find we don't use debuggers much, what might be done to modernize the book, the role of refactoring tools, whether comments can be used for good, the trade-off between refactoring and rewriting, modularity and microservices, and how the software industry has changed over the last twenty years.
Crossing Refactoring's Rubicon
In January 2001 two Java tools crossed Refactoring's Rubicon. Refactoring in Java now has serious tool support
Beck Design Rules
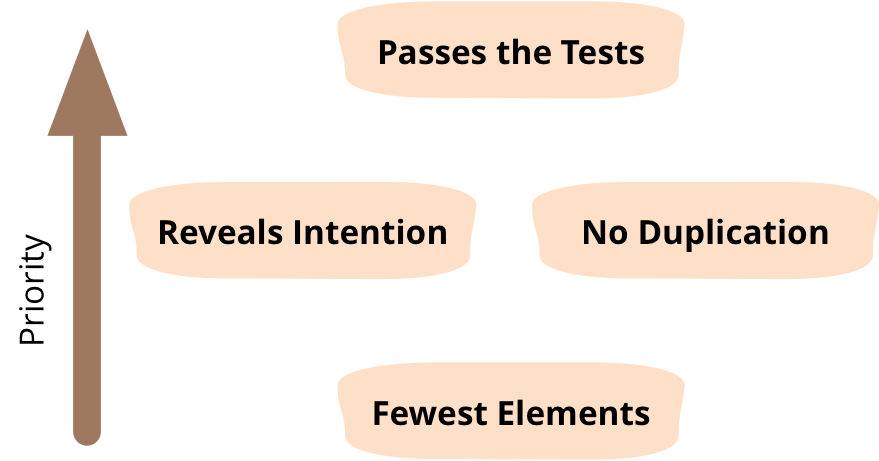
Kent Beck came up with his four rules of simple design while he was developing ExtremeProgramming in the late 1990's. I express them like this.
C- Refactory
So far refactoring tools have appeared for a number of languages. After Smalltalk's lead, we've seen several tools for Java and a couple for C#. One language conspicuous by its absence is C++, despite appeals. All this despite the fact that the first refactoring thesis was done by Bill Opdyke, who's background is in C++.
Code Smell
A code smell is a surface indication that usually corresponds to a deeper problem in the system. The term was first coined by Kent Beck while helping me with my Refactoring book.
Data Clump
Whenever two or three values are gathered together - turn them into a $%#$%^ object.
-- Me (it was funnier with the voices)
This is one of my favorite CodeSmells from the refactoring book. You spot it when you constantly see the same few data items passed around together. start and end are a good example of a data clump wanting to be a range. Often data clumps are primitive values that nobody thinks to turn into an object.
Definition Of Refactoring
In my refactoring book, I gave a couple of definitions of refactoring.
Etymology Of Refactoring
Where did the word refactoring come from?
Opportunistic Refactoring
From the very beginning of when I started to talk and write about refactoring people have asked me how it should be incorporated into the wider software development process. Should there be refactoring phases in the software development lifecycle, what proportion of an iteration should be devoted to refactoring tasks, how should we figure out who should be assigned to refactoring duties? Although there are places for some scheduled refactoring efforts, I prefer to encourage refactoring as an opportunistic activity, done whenever and wherever code needs to cleaned up - by whoever.
Parallel Change
Making a change to an interface that impacts all its consumers requires two thinking modes: implementing the change itself, and then updating all its usages. This can be hard when you try to do both at the same time, especially if the change is on a PublishedInterface with multiple or external clients.
Parallel change, also known as expand and contract, is a pattern to implement backward-incompatible changes to an interface in a safe manner, by breaking the change into three distinct phases: expand, migrate, and contract.
Platform Building
Can you use refactoring to build a platform?
Refactoring Cringely
A recent piece by Robert Cringely caused a small stir in the refactoring community recently, as he criticized refactoring. Phlip summed the response on the refactoring mailing list with an unusually restrained '...he sounds like a “skeptic” who writes reviews of books he has no intention of reading.'
Refactoring Malapropism
Once a term known to only a few, “Refactoring” is now commonly tossed around the computer industry. I like to think that I'm partly responsible for this and hope it's improved some programmers lives and some business's bottom lines. (Important point, I'm not the father or the inventor of refactoring - just a documenter.)
Refactoring Photran
It looks like those devious people at UIUC getting ready to refactor Fortran. Brian Foote writes about the project in his unparallelled style. (He's one of the most amusing writers in software - but getting him to write anything is usually like trying to pull teeth from a live sabre-tooth tiger while wearing a necklace of freshly killed lamb chops.) (Yes I know it's old news, but I saw something else on his blog and then found this.)
Refinement Code Review
When people think of code reviews, they usually think in terms of an explicit step in a development team's workflow. These days the Pre-Integration Review, carried out on a Pull Request is the most common mechanism for a code review, to the point that many people witlessly consider that not using pull requests removes all opportunities for doing code review. Such a narrow view of code reviews doesn't just ignore a host of explicit mechanisms for review, it more importantly neglects probably the most powerful code review technique - that of perpetual refinement done by the entire team.
Self Testing Code

Self-Testing Code is the name I used in Refactoring to refer to the practice of writing comprehensive automated tests in conjunction with the functional software. When done well this allows you to invoke a single command that executes the tests - and you are confident that these tests will illuminate any bugs hiding in your code.
Static Substitution
As I listen to our development teams talk about their work, one common theme is their dislike of things held in statics. Typically we see common services or components held in static variables with static initializers. One of the big problems with statics (in most languages) is you can't use polymorphism to substitute one implementation with another. This bits us a lot because we are great fans of testing - and to test well it's important to be able to replace services with a Service Stub.