
An example of preparatory refactoring
05 January 2015

There are various ways in which refactoring can fit into our programming workflow. One useful notion is that of Preparatory Refactoring. This is where I'm adding a new feature, and I see that the existing code is not structured in such a way that makes adding the feature easy. So first I refactor the code into the structure that makes it easy to add the feature, or as Kent Beck pithily put it “make the change easy, then make the easy change”.
In a recent Ruby Rogues podcast, Jessica Kerr gave a lovely metaphor for preparatory refactoring.
It’s like I want to go 100 miles east but instead of just traipsing through the woods, I’m going to drive 20 miles north to the highway and then I’m going to go 100 miles east at three times the speed I could have if I just went straight there. When people are pushing you to just go straight there, sometimes you need to say, “Wait, I need to check the map and find the quickest route.” The preparatory refactoring does that for me.
-- Jessica Kerr
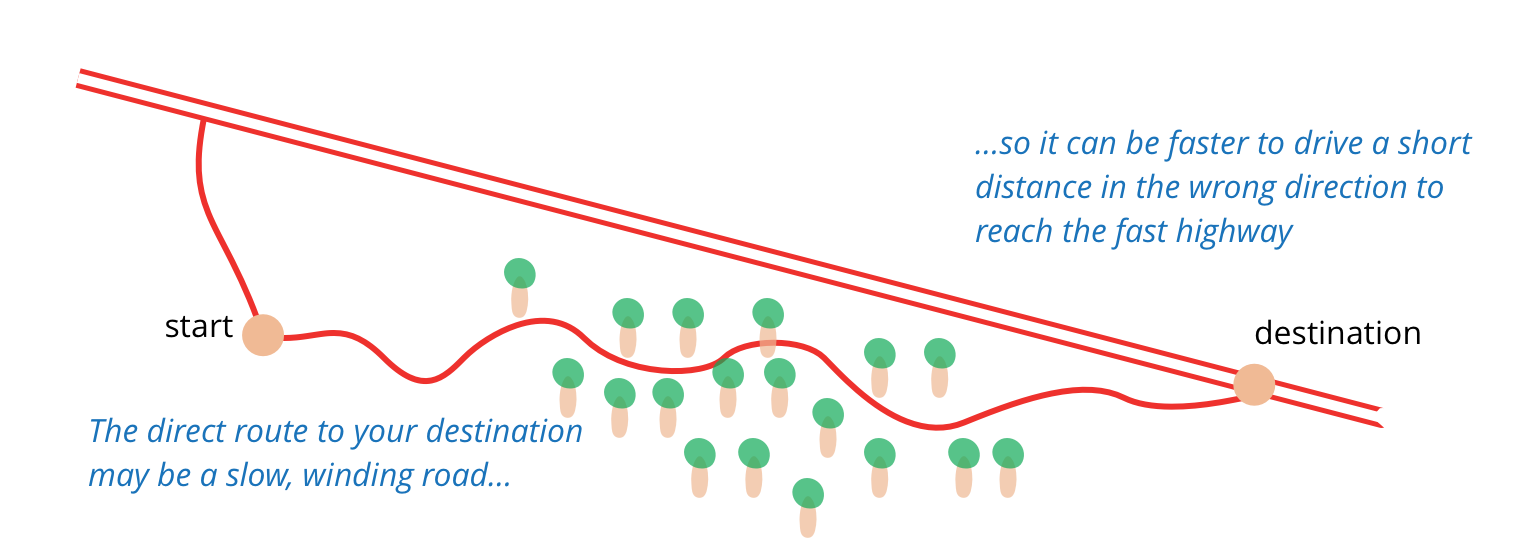
Another good metaphor I've come across is putting tape over electrical sockets, door frames, skirting boards and the like when painting a wall. The taping isn't doing the painting, but by spending the time to cover things up first, the painting can be much quicker and easier.
General statements and metaphors are all very nice, but it's good to show an example. And recently I ran into an example myself that I thought may be worth sharing.
The Starting Point
My publication toolchain includes the ability to insert code from a live file into an article. By a “live file”, I mean code that compiles and runs, usually a pedagogical (ie toy) example. Being able to slurp code from live files is really helpful as it avoids copy-paste problems and gives me confidence that the code in the article is code that actually compiles and passes tests. I mark the code sections by markers contained in comments. 1
1: There's an enjoyable irony here, in that this approach doesn't work very well when I'm describing some refactoring like this. I still use the code import mechanism, as I find it handy to separate the code from the text when I'm writing, but I have to pull it in from a (dead) snips file.
One thing I'm adding just now is the ability to highlight specific parts of these code fragments. This way I can take a line, or part of a line of code, and surround it with span elements in the html, allowing me to then use css to highlight it any way I want. You'll see examples of me doing this later on in this article, as it's particularly handy when discussing refactorings.
At the start of the programming episode I'm talking about here, I already had the ability to highlight a given line, or a span of code within a given line. I wanted to add a third capability, to highlight a range of lines.
In the source document for my article, I indicate I want to
insert a code fragment with an insertCode XML
element. My
current highlighting then allows me to define a bunch of
highlights. Here's an example
<insertCode file = "Notification.java" fragment = "notification-with-error">
<highlight line="add\(" span="new.*e\)"/>
<highlight line="map"/>
</insertCode>
This highlights some code like this
public void addError(String message, Exception e) {
errors.add(new Error(message, e));
}
public String errorMessage() {
return errors.stream()
.map(e -> e.message)
.collect(Collectors.joining(", "));
}
The insertCode element has attributes for the
file path and the name of the fragment that I want to extract. I
can then specify highlights with child elements. Each highlight
specifies a line by providing a regexp which I use to match the
line. I may provide a span attribute, another regexp, in which
case the highlighting is only for the part of the line that
matches that regexp. If I don't provide a span the highlight is
applied to the entire line.
I had put the code that does the highlighting into its own class. Some separate code (which we don't need to worry about) extracts the code fragment from the source file, it then looks to see if we need any highlighting, if so it creates a CodeHighlighter object and tells it to do the highlighting. The invocation of the code highlighter looks something like this:
output << CodeHighlighter.new(insertCodeElement, codeFragment).call
This is using the method object pattern, where I use an object to represent a first-class function. I create the object with the arguments to that function, invoke another method to run the function which returns the result, and then let the method object be garbage collected away.
Here's the implementation of that highlighter:
class CodeHighlighter
def initialize insertCodeElement, fragment
@data = insertCodeElement
@fragment = fragment
end
def call
@fragment.lines.map{|line| highlight_line line}.join
end
def highlight_line line
highlights
.select{|h| Regexp.new(h['line']).match(line)}
.reduce(line){|acc, each| apply_markup acc, each}
end
def highlights
@data.css('highlight')
end
def apply_markup line, element
open = "<span class = 'highlight'>"
close = "</span>"
if element.key? 'span'
r = Regexp.new(element['span'])
m = r.match line
m.pre_match + open + m[0] + close + m.post_match
else
open + line.chomp + close + "\n"
end
end
end
The toolchain code is ruby, it uses the Nokogiri library to manipulate XML
I haven't worried much about edge cases here, such as if I specify multiple highlights that overlap in ways that will mess up the display. After all, if I run into any of these problems I know where I live. Such is the luxury of writing code where I'm the only user.
Testing the highlighter
Testing the highlighter is pretty simple, it's a pure function that takes some input and emits some output. But there's a little machinery I put in my test class to make it easier to write tests. The first thing is that I like to keep the hunks of text for input and output in a separate file, which looks like this
codeHighlighterHunks.txt…
input
private void validateDate(Notification note) {
if (date == null) {
note.addError("date is missing");
return;
}
LocalDate parsedDate;
try {
parsedDate = LocalDate.parse(getDate());
}
} //end
%% one-line
private void validateDate(Notification note) {
if (date == null) {
<span class = 'highlight'> note.addError("date is missing");</span>
return;
}
LocalDate parsedDate;
try {
parsedDate = LocalDate.parse(getDate());
}
} //end
%% one-span
private void validateDate(Notification note) {
if (date == null) {
note.<span class = 'highlight'>addError</span>("date is missing");
return;
}
LocalDate parsedDate;
try {
parsedDate = LocalDate.parse(getDate());
}
} //end
…
Here you see three hunks of text, separated by
%%. The first hunk is my (first) input string, the
next two are outputs for what happens with one line, and one span
within a line. Each hunk has a key, which is the text following
the %% on the line. I can then easily get at the
hunks in my tester class
class CodeHighlighterTester…
def hunks
raw = File.read('test/codeHighlighterHunks.txt').split("\n%%")
raw.map {|r| process_raw_hunk r}.to_h
end
def process_raw_hunk hunk
lines = hunk.lines
key = lines.first.strip
value = lines
.drop(1)
.drop_while {|line| (/[^[:space:]]/ !~ line)}
.join
return [key, value]
end
With the ability to extract hunks easily, I can then reference them in my tests.
class CodeHighlighterTester…
def test_no_highlights
assert_equal hunks['input'], with_highlights(form_element(""))
end
def test_one_line_highlight
element = form_element "<highlight line = 'missing'/>"
assert_equal hunks['one-line'], with_highlights(element)
end
def test_highlight_span
element = form_element "<highlight line = 'missing' span = 'addError'/>"
assert_equal hunks['one-span'], with_highlights(element)
end
def form_element s
Nokogiri::XML("<insertCode>" + s + "</insertCode").root
end
def with_highlights element, input = nil
input ||= hunks['input']
CodeHighlighter.new(element,input).call
end
I could have used multi-line strings or here docs for this, but I think hunks of text are easier to work with.
Adding a highlight range
The new feature I wanted to add was to highlight a range of lines like this.
<insertCode file = "BookingRequest.java" fragment = "done"> <highlight-range start-line = "missing" end-line = "return"/> </insertCode>
The start-line and end-line attributes are again regexps, to match the first and last lines in the range.
I started by adding a test for the new markup behavior, checked that it failed, then marked it to be skipped. I like to start by writing the test for the final behavior I want, since that clarifies to me both exactly what the outcome I want is, and also how I want my API to work. But if I'm going to do any preparatory refactoring, I don't want that test's failure to clutter my test output, so after watching it fail once, I skip it while I'm working on it.
class CodeHighlighterTester…
def test_highlight_range
skip
e = '<highlight-range start-line = "(date == null)" end-line = "}"/>'
assert_equal hunks['range'], with_highlights(form_element(e))
end
codeHighlighterHunks.txt…
%% range
private void validateDate(Notification note) {
<span class = 'highlight'> if (date == null) {
note.addError("date is missing");
return;
}</span>
LocalDate parsedDate;
try {
parsedDate = LocalDate.parse(getDate());
}
} //end
As I was thinking about how to approach it, I began by deciding that I could treat the code highlighting as a sequence of transformations on the supplied text. I could first apply any highlight-range transformation, and then follow them with the existing highlights. I can now transfer that thought from my mind to the code.
My first step is to simply use Extract Method on the entire body of call
class CodeHighlighter…
def call
apply_highlights @fragment.lines
end
def apply_highlights lines
lines.map{|line| highlight_line line}.join
end
Now I introduce a nested, no-op function - that is one that just returns what you give it, without any change.
class CodeHighlighter…
def call
apply_highlights(apply_ranges(@fragment.lines))
end
def apply_ranges lines
lines
end
This single refactoring is really the essence of this whole
article, boiled down to a simple step. With this refactoring I'm
doing a couple of things. First, by placing the
apply_ranges method into the call, I'm making a
place for my new functionality to go. But secondly, and perhaps
more importantly, I'm immediately implementing this new function
in such a way that it preserves the current behavior. To some
extent, this ability to easily insert placeholder functions is one
of the great advantages of structuring the highlighting
behavior as a series of smaller transformations - which is one of
the reasons why the Pipes and Filters
pattern is such powerful way of structuring computation.
By defining apply_ranges with this simple
behavior-preserving implementation, as opposed to just leaving it
blank, I can continue to run my tests and keep my refactoring hat
on.
I may have any number of highlight-range elements to apply, so I'll let each one compose on top the others.
class CodeHighlighter…
def apply_ranges lines
highlight_ranges.reduce(lines){|acc, each| apply_one_range(acc, each)}
end
def highlight_ranges
@data.css('highlight-range')
end
def apply_one_range lines, element
lines
end
You'll see I'm doing the same trick again, I implement
apply_ranges by reducing the result of running
apply_one_range for each highlight-range element. I
provide an initial implementation of apply_one_range
that preserves existing behavior and get to keep my trilby
on. What I'm doing is steadily narrowing down the scope of the change in
behavior I'm about to add.
At this point, I add a no-op test for the highlight range condition.
class CodeHighlighterTester…
def test_highlight_range_noop
e = '<highlight-range start-line = "(date == null)" end-line = "}"/>'
assert_equal hunks['input'], with_highlights(form_element(e))
end
This might seem like an odd move, essentially all this test says is that when I add a highlight-range element, I don't want any changes to the output. This is a temporary test, just while I'm working on the preparatory refactoring. While I'm doing this refactoring, I'm operating on the assumption that the refactorings I'm doing will result in no changes, even when the element is present. So I want to confirm that assumption with a test, since it's so easy to write. (This follows a general rule of mine: if I ever feel the urge to run the code and look at some output to see if things are correct, I should instead write a test. With a test the computer can check if the output is correct, so I don't have to.)
My next move is back to the highlighter itself. I've now isolated a method to highlight a single range. I think that a good thing to do next is to identify the line where I want to add the opening tag, and split the lines into three lists: before the matched line, the line alone, and after the matched line. I'll worry about the closing tag later.
class CodeHighlighter…
def apply_one_range lines, element
start_ix = lines.find_index {|line| line =~ Regexp.new(element['start-line'])}
pre = 0 == start_ix ? [] : lines[0..(start_ix - 1)]
start = [lines[start_ix]]
rest = lines.size == (start_ix + 1) ? [] : lines[(start_ix + 1)..-1]
return pre + start + rest
end
The essence of this refactoring is breaking down the text and putting it back together again, until I've broken it down to the right point to slip in the new behavior.
By doing this I can test that I can correctly break the list of lines into pieces and put them back together. Since there aren't always three pieces, this is a bit more awkward than you might first think. Since I had to put conditional logic in to check if the range started on the first or last-but-one line, I added some tests to check for these cases.
I'm only checking for the opening so far, and am almost ready to actually change the observable behavior, but first I need to move the html span strings into something at object scope.
class CodeHighlighter…
def apply_markup line, element open = "<span class = 'highlight'>" close = "</span>" if element.key? 'span' r = Regexp.new(element['span']) m = r.match line raise "unable to match span %s" % element['span'] unless m m.pre_match + opening + m[0] + closing + m.post_match else opening + line.chomp + closing + "\n" end end def opening "<span class = 'highlight'>" end def closing "</span>" end
I could make them constants, but it's my habit to just use methods in this situation. 2
2: You may be wondering how this code allows me to highlight some code with a strike-through, as I do here. I only added that feature to the code highlighter when I was writing this article. (I did it by adding an attribute to specify a css class.)
Now I'm finally ready to put my hard-hat on, and the change I need to make is too trivial to be easy.
class CodeHighlighter…
def apply_one_range lines, element
start_ix = lines.find_index {|line| line =~ Regexp.new(element['start-line'])}
raise "unable to match %s in code insert" % element['start-line'] unless start_ix
pre = 0 == start_ix ? [] : lines[0..(start_ix - 1)]
start = [opening + lines[start_ix]]
rest = lines.size == (start_ix + 1) ? [] : lines[(start_ix + 1)..-1]
return pre + start + rest
end
I now remove the no-op test I added a couple of minutes ago, and modify the skipped test so it only includes the opening.
class CodeHighlighterTester…
def test_highlight_range
skip
e = '<highlight-range start-line = "(date == null)" end-line = "}"/>'
assert_equal hunks['range'], with_highlights(form_element(e))
end
codeHighlighterHunks.txt…
%% range
private void validateDate(Notification note) {
<span class = 'highlight'> if (date == null) {
note.addError("date is missing");
return;
}</span>
LocalDate parsedDate;
try {
parsedDate = LocalDate.parse(getDate());
}
} //end
This testing allows me to do a little preparatory refactoring before I add the closing tag.
class CodeHighlighter…
def apply_one_range lines, element
start_ix = lines.find_index {|line| line =~ Regexp.new(element['start-line'])}
raise "unable to match %s in code insert" % element['start-line'] unless start_ix
finish_offset = lines[start_ix..-1].find_index do |line|
line =~ Regexp.new(element['end-line'])
end
raise "unable to match %s in code insert" % element['end-line'] unless finish_offset
finish_ix = start_ix + finish_offset
pre = 0 == start_ix ? [] : lines[0..(start_ix - 1)]
start = [opening + lines[start_ix]]
mid = (lines[(start_ix + 1)..(finish_ix -1)])
finish = [lines[finish_ix]]
rest = lines.size == (finish_ix + 1) ? [] : lines[(finish_ix + 1)..-1]
return pre + start + mid + finish + rest
end
The method is rather long for my taste, but I can't think of how to sensibly shorten it. It does keep everything green and set things up for my final easy change.
class CodeHighlighter…
def apply_one_range lines, element
start_ix = lines.find_index {|line| line =~ Regexp.new(element['start-line'])}
raise "unable to match %s in code insert" % element['start-line'] unless start_ix
finish_offset = lines[start_ix..-1].find_index do |line|
line =~ Regexp.new(element['end-line'])
end
raise "unable to match %s in code insert" % element['end-line'] unless finish_offset
raise "start and end match same line" unless finish_offset > 0
finish_ix = start_ix + finish_offset
pre = 0 == start_ix ? [] : lines[0..(start_ix - 1)]
start = [opening + lines[start_ix]]
mid = (lines[(start_ix + 1)..(finish_ix -1)])
finish = [lines[finish_ix].chomp + closing + "\n"]
rest = lines.size == (finish_ix + 1) ? [] : lines[(finish_ix + 1)..-1]
return pre + start + mid + finish + rest
end
Final Thoughts
I hope this little episode has given you some sense of what preparatory refactoring can be like:
for each desired change, make the change easy (warning: this may be hard), then make the easy change
-- Kent Beck
I made the change easy by creating a no-op function that simply returned what it was given, and then decomposing that function, gradually breaking it down while still retaining its no-opiness. Then once it was simple to add the new feature, it just slipped in.
Every episode of preparatory refactoring is different. Some take a few minutes, some can take days. But I find that when I can spot how to do a preparatory refactoring it results in a faster and less-stressful programming experience, because the trilby is faster and less stressful than the hard hat.
Footnotes
1: There's an enjoyable irony here, in that this approach doesn't work very well when I'm describing some refactoring like this. I still use the code import mechanism, as I find it handy to separate the code from the text when I'm writing, but I have to pull it in from a (dead) snips file.
2: You may be wondering how this code allows me to highlight some code with a strike-through, as I do here. I only added that feature to the code highlighter when I was writing this article. (I did it by adding an attribute to specify a css class.)
Significant Revisions
05 January 2015: First published