
tagged by: metrics
An Appropriate Use of Metrics
Management love their metrics. The thinking goes something like this, “We need a number to measure how we’re doing. Numbers focus people and help us measure success.” Whilst well intentioned, management by numbers unintuitively leads to problematic behavior and ultimately detracts from broader project and organizational goals. Metrics inherently aren’t a bad thing; just often, inappropriately used. This essay demonstrates many of the issues caused by management’s traditional use of metrics and offers an alternative to address these dysfunctions.
Don't Compare Averages
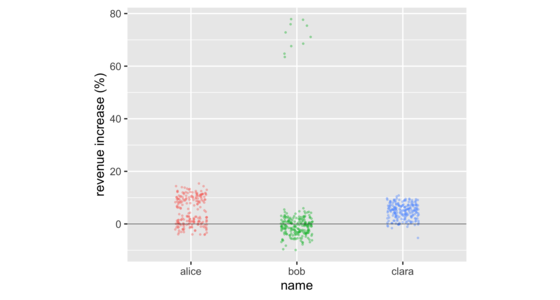
In business meetings, it's common to compare groups of numbers by comparing their averages. But doing so often hides important information in the distribution of the numbers in those groups. There are a number of data visualizations that shine a light on this information. These include strip charts, histograms, density plots, box plots, and violin plots. These are easy to produce with freely available software, working on groups as small as a dozen, or as large as thousands.
Measuring Developer Productivity via Humans

Measuring developer productivity is a difficult challenge. Conventional metrics focused on development cycle time and throughput are limited, and there aren't obvious answers for where else to turn. Qualitative metrics offer a powerful way to measure and understand developer productivity using data derived from developers themselves. Organizations should prioritize measuring developer productivity using data from humans, rather than data from systems.
The Reformist CTO’s Guide to Impact Intelligence
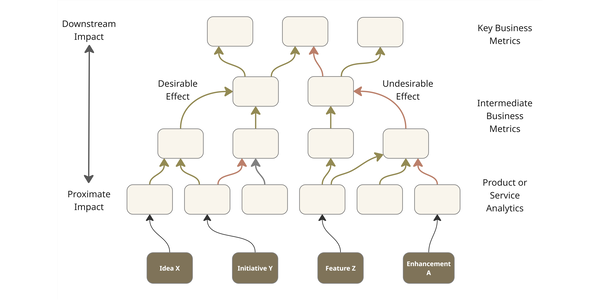
The productivity of knowledge workers is hard to quantify and often decoupled from direct business outcomes. The lack of understanding leads to many initiatives, bloated tech spend, and ill-chosen efforts to improve this productivity. Technology leaders need to avoid this by developing an intelligence of the business impact of their work across a network connecting output to proximate and downstream impact. We can do this by introducing robust demand management, paying down measurement debt, introducing impact validation, and equipping delivery teams to build a picture of how their work translates to business impact.
Team OKRs in Action
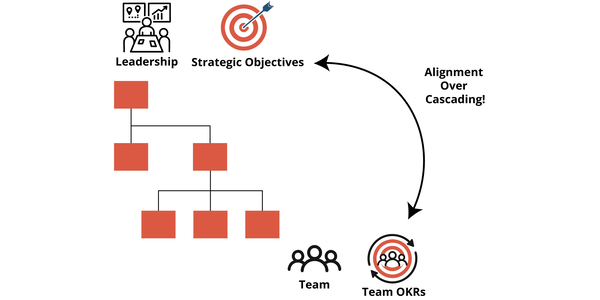
OKRs have become a popular way to connect strategy with execution in large organizations. But when they are set in a top‑down cascade, they often lose their meaning. Teams receive objectives they didn’t help create, and the result is weak commitment and little real change. High‑performing teams work in another way. They define their own objectives in an organization that uses a collaborative process to align the team’s OKRs with the broader strategy. With these Team OKRs in place, they create a shared purpose and become the base for a regular cycle of planning, check‑ins, and retrospectives.
Cannot Measure Productivity
We see so much emotional discussion about software process, design practices and the like. Many of these arguments are impossible to resolve because the software industry lacks the ability to measure some of the basic elements of the effectiveness of software development. In particular we have no way of reasonably measuring productivity.
Cycle Time

Cycle Time is a measure of how long it takes to get a new feature in a software system from idea to running in production. In Agile circles, we try to minimize cycle time. We do this by defining and implementing very small features and minimizing delays in the development process. Although the rough notion of cycle time, and the importance of reducing it, is common, there is a lot of variations on how cycle time is measured.
Estimated Interest
TechnicalDebt is a very useful concept, but it raises the question of how do you measure it? Sadly technical debt isn't like financial debt, so it's not easy to tell how far you are in hock (although we seem to have had some trouble with measuring the financial kind recently).
Five Pound Bag
You can't put ten pounds of shit into a five pound bag
-- Anyone who has tried
When Kent and I wrote Planning Extreme Programming, we included this whimsical quote to help get the essence of what planning is about.
Function Length
During my career, I've heard many arguments about how long a function should be. This is a proxy for the more important question - when should we enclose code in its own function? Some of these guidelines were based on length, such as functions should be no larger than fit on a screen . Some were based on reuse - any code used more than once should be put in its own function, but code only used once should be left inline. The argument that makes most sense to me, however, is the separation between intention and implementation. If you have to spend effort into looking at a fragment of code to figure out what it's doing, then you should extract it into a function and name the function after that “what”. That way when you read it again, the purpose of the function leaps right out at you, and most of the time you won't need to care about how the function fulfills its purpose - which is the body of the function.
Outcome Over Output
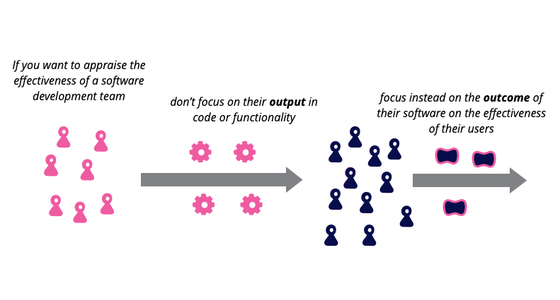
Imagine a team writing software for a shopping website. If we look at the team's output, we might consider how many new features they produced in the last quarter, or a cross-functional measure such as a reduction in page load time. An outcome measure, however, would consider measure increased sales revenue, or reduced number of support calls for the product. Focusing on outcomes, rather than output, favors building features that do more to improve the effectiveness of the software's users and customers.
Purpose Of Estimation
My first encounter with agile software development was working with Kent Beck at the dawn of Extreme Programming. One of the things that impressed me about that project was the way we went about planning. This included an approach to estimating which was both lightweight yet more effective than what I'd seen before. Over a decade has now passed, and now there is an argument amongst experienced agilsts about whether estimation is worth doing at all, or indeed is actively harmful . I think that to answer this question we have to look to what purpose the estimates will be used for.
Rigorous Agile
I often run into a complaint that agile methods don't have a rigorous definition. The complainer may talk about how this means that you can't tell if a particular team is using an agile method or not. They may also say that this makes it hard to teach people how to do agile methods - what's the curriculum?
To some degree I do feel the pain of this complaint - but I accept there is no cure. This lack of rigorousness is part of the defining nature of agile methods, part of its core philosophy.
Standard Story Points
I've heard a couple of questions recently about coming up with a standard story point mechanism for multiple teams using extreme programming's planning approach. The hope is have several teams all using equivalent story points, so that three story points of effort on one team is the same as on another.
I think trying to come up with this at best of limited value, and at worst dangerous.
Test Coverage
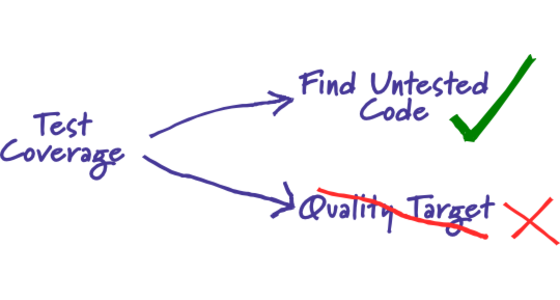
From time to time I hear people asking what value of test coverage (also called code coverage) they should aim for, or stating their coverage levels with pride. Such statements miss the point. Test coverage is a useful tool for finding untested parts of a codebase. Test coverage is of little use as a numeric statement of how good your tests are.
What Is Failure
CHAOS report says only 34% of projects succeed.
The Standish Group's CHAOS report has been talking of billions of wasted dollars on IT projects for many years. The 34% success rate is actually a improvement over 2001's figure of 28%. But what do we really mean by 'failure'?