
during: 2013
Datensparsamkeit
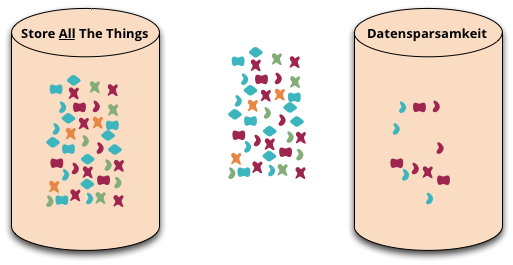
Datensparsamkeit is a German word that's difficult to translate properly into English. It's an attitude to how we capture and store data, saying that we should only handle data that we really need.
Enterprise Integration Using REST
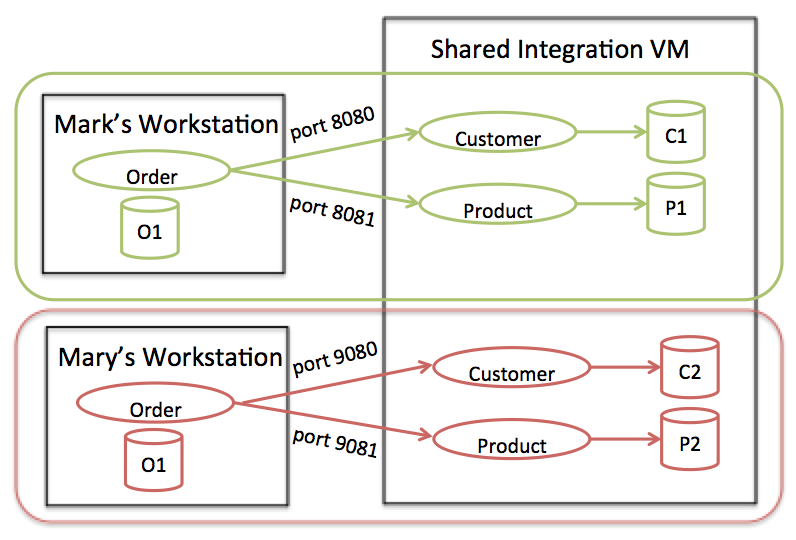
Most internal REST APIs are one-off APIs purpose built for a single integration point. In this article, I'll discuss the constraints and flexibility that you have with nonpublic APIs, and lessons learned from doing large scale RESTful integration across multiple teams.
Historically Discriminated Against
From time to time, I've written on this site about the problematic DiversityImbalance in the software development profession, and how we need to take deliberate action to increase the proportion of underrepresented groups. This is all well and good, but naturally leads to the questions of what underrepresented groups we should be concerned about. In Thoughtworks we've been using the term “historically-discriminated-against” to help focus our thinking for one of the main drivers for embracing diversity.
Nexus7
A few months ago, I bought a Google Nexus 7 tablet. I like to wait until I've used a device for a while before I post my experiences of it, but the disadvantage of that policy is that now the tablet I'm talking about has been superseded. That said, I'll pass on my comments anyway, since they may still be helpful to others considering their future tablet options.
Testing Asynchronous JavaScript
There seems to be a common misconception in the JavaScript community that testing asynchronous code requires a different approach than testing ‘regular’ synchronous code. In this post I’ll explain why that’s not generally the case. I’ll highlight the difference between testing a unit of code which supports async behavior, as opposed code which is inherently asynchronous. I’ll also show how promise-based async code lends itself to clean and succinct unit tests which can be tested in a clear, readable way while still validating async behaviour.
Huffpost live panel on “The Brogrammer Effect”
I took part in a 20 minute long panel discussion on the declining participation of women in tech and what we should do about it.
Threshold Test
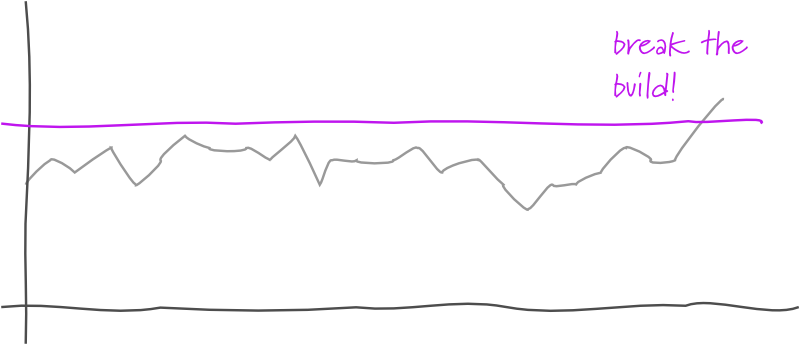
A threshold test is a test inserted into a DeploymentPipeline that monitors some measurable phenomenon by comparing the value in the current build against a threshold value. Should the current build's value pass the threshold, the test fails, failing the build.
Page Object
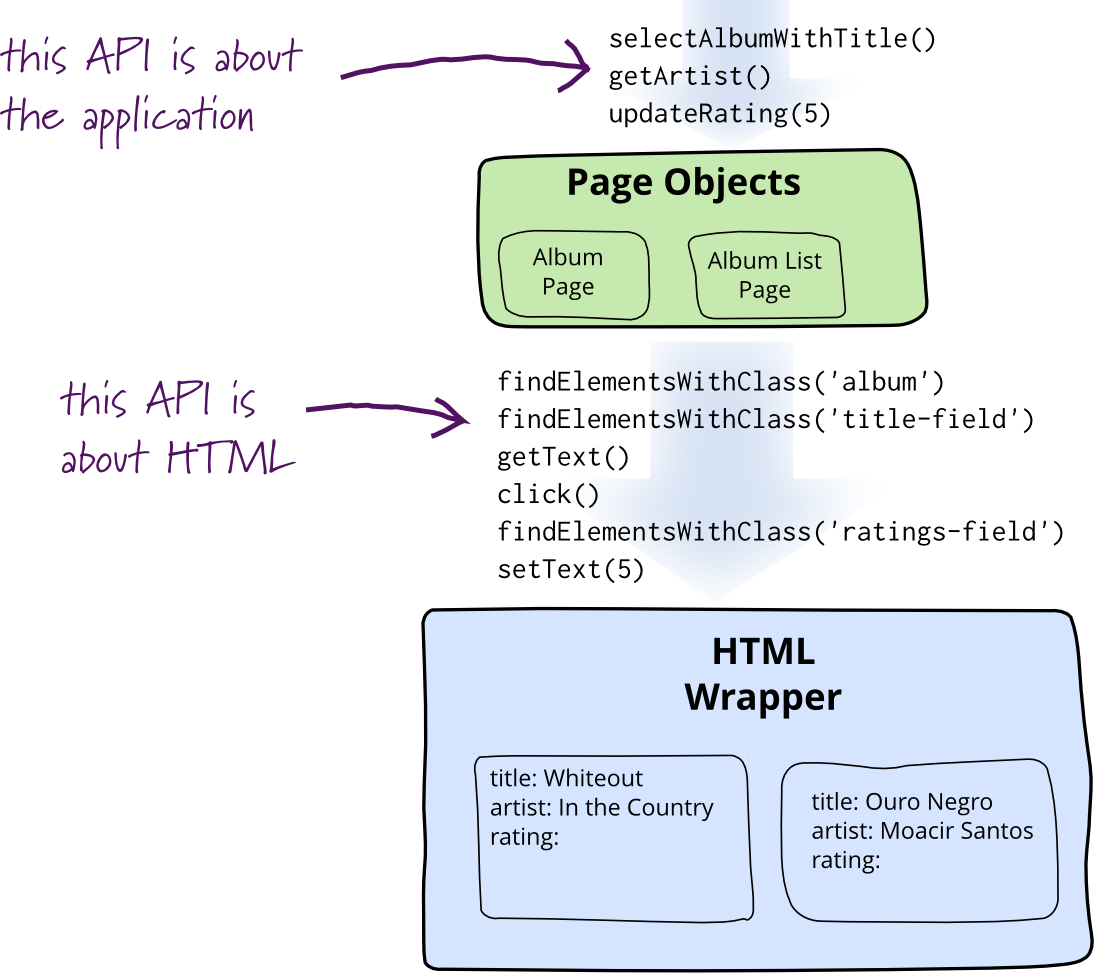
When you write tests against a web page, you need to refer to elements within that web page in order to click links and determine what's displayed. However, if you write tests that manipulate the HTML elements directly your tests will be brittle to changes in the UI. A page object wraps an HTML page, or fragment, with an application-specific API, allowing you to manipulate page elements without digging around in the HTML.
Tell Dont Ask
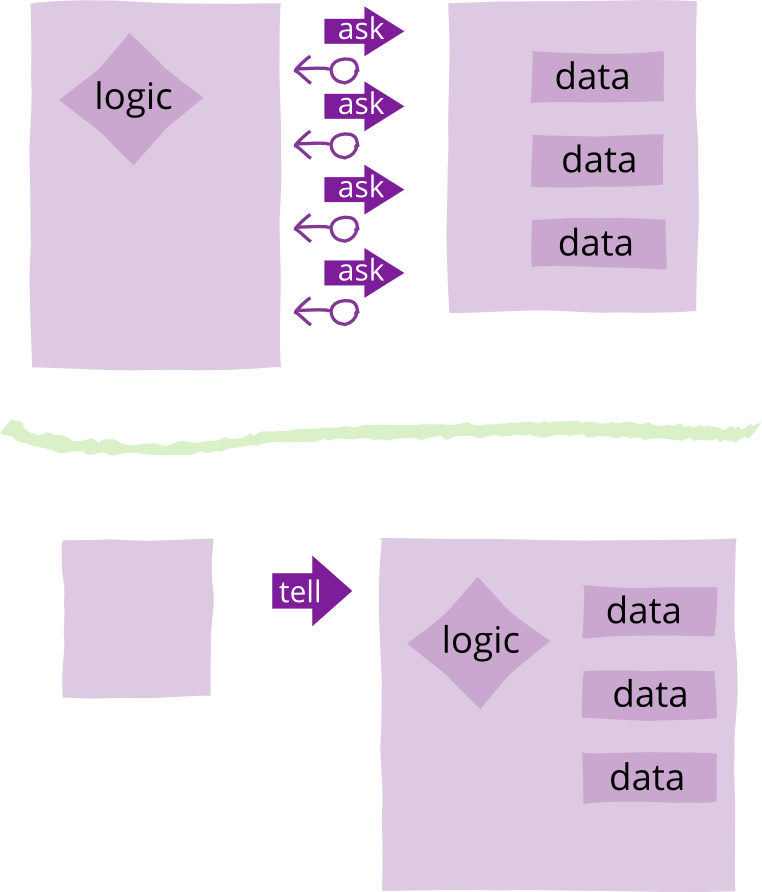
Tell-Don't-Ask is a principle that helps people remember that object-orientation is about bundling data with the functions that operate on that data. It reminds us that rather than asking an object for data and acting on that data, we should instead tell an object what to do. This encourages to move behavior into an object to go with the data.
Goto Amsterdam Keynote
My keynote at Goto Amsterdam in 2013. As usual it follows my 'Software Design in the 21st Century' template with a pair of short talks. I begin with talking about Schemaless data structures, explaining why there is always an implicit schema and the consequences of that. Second up (at 25m24s) I talk about the essence of agile software development and the agile fluency model.
Given When Then
Given-When-Then is a style of representing tests - or as its advocates would say - specifying a system's behavior using SpecificationByExample. It's an approach developed by Daniel Terhorst-North and Chris Matts as part of Behavior-Driven Development (BDD). It appears as a structuring approach for many testing frameworks such as Cucumber. You can also look at it as a reformulation of the Four-Phase Test pattern.
What It's Like to Work at...Thoughtworks
In an interview with InformIT I give my (rather skewed) view of why I like working at Thoughtworks. We talk about how I got there, why I stay, and what people can do to join and prosper at our interesting company.
Expression Builder
One of the problems with a FluentInterface is that it results in some odd looking methods. Consider this example:
Privacy Protects Bothersome People
We need to support privacy, not for those of us who have "nothing to hide", but for bothersome people like investigative journalists and activists, without which our democracy would crumble
User Defined Field
A common feature in software systems is to allow users to define their own fields in data structures. Consider an address book - there's a host of things that you might want to add. With new social networks popping up every day, users might want to add a new field for a Bunglr id to their contacts.
Story Point
Story points are a common name for sizing stories in agile projects. Combined with XpVelocity they provide a technique to aid planning by providing a forecast of when stories can be completed.
Story Counting
Story counting is a technique for planning and estimation. Similarly to StoryPoints it works with XpVelocity to help you figure out how many stories you can deliver in a fixed period of time. It differs, however, in that you just consider the number of stories per unit of time and (mostly) ignore their relative sizes.
Ideal Time
Ideal time was a term used in early ExtremeProgramming to help with estimation of effort. It's been mostly superseded now by StoryPoints or StoryCounting.
Extreme Programming
Extreme Programming (XP) is a software development methodology developed primarily by Kent Beck. XP was one of the first agile methods, indeed XP was the dominant agile method in the late 90s and early 00s before Scrum became dominant as the noughties passed. Many people (including myself) consider XP to be the primary catalyst that got attention to agile methods, and superior to Scrum as a base for starting out in agile development.
Cloud Computing
“Cloud” has become a very over-hyped term over the last few years. One of the characteristics of over-hyped words is that they have little or no definition to them (yes NosqlDefinition I'm looking at you).
As it turns out there is an excellent definition of cloud computing available, from none other that NIST. It's available by a wonderfully short and easy to understand standards document (no, I'm not kidding).
Immutable Server
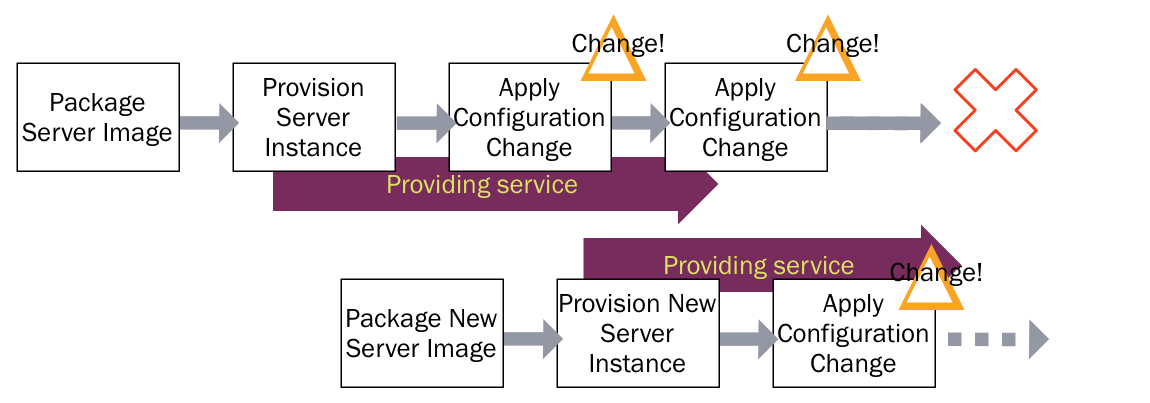
Automated configuration tools (such as CFEngine, Puppet, or Chef) allow you to specify how servers should be configured, and bring new and existing machines into compliance. This helps to avoid the problem of fragile SnowflakeServers. Such tools can create PhoenixServers that can be torn down and rebuilt at will. An Immutable Server is the logical conclusion of this approach, a server that once deployed, is never modified, merely replaced with a new updated instance.
Configuration Synchronization
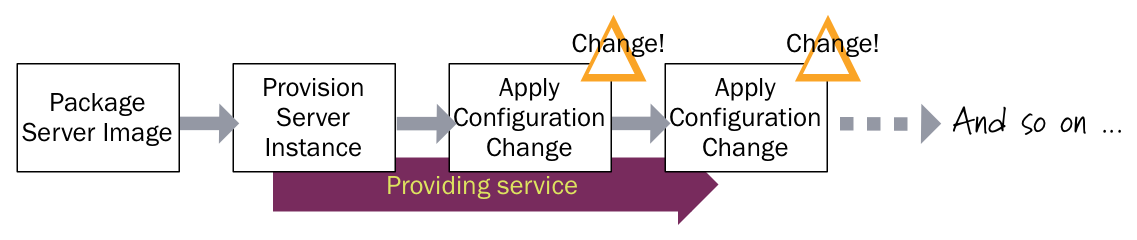
Automated configuration tools (such as CFEngine, Puppet, or Chef) allow you to avoid SnowflakeServers by providing recipes to describe the configuration of elements of a server. Configuration synchronization continually applies these specifications, either on a regular schedule or when it changes, to server instances throughout their lifetime. If someone makes a change to a server outside the tool, it will be reverted to the centrally specified configuration the next time the server is synchronized. If some configuration change is needed, it's made in the configuration specification (recipes, manifests, or whatever the particular configuration tool calls it), and is then applied to all relevant servers across the infrastructure.
Evolving a Mobile Implementation Strategy
Mobile is still a smaller part of traffic than the traditional web, but its share is growing, so we need to think about our strategy for developing effective mobile applications. We discuss thinking about a product vision, separating the styles of user engagement into “Lean-forward”, “Lean-back”, and “Look-down” styles; while integrating them into a transmedia application. We talk about why its more important to focus on value than on traffic, the laser and cover-your-bases platform strategies, and opine that Android, iOS, and the Web are the three viable platform choices. Giles finishes with a case-study of our work with a major airline.
Embedded Document
Flowing JSON data structures through a server is something I'm seeing more these days. JSON documents can be persisted directly, either by using an AggregateOrientedDatabase or a serialized LOB in a relational database. JSON documents can also be served directly to web browsers or used to transfer data to server-side page renderers. When JSON is being used in this way, I hear people saying that using an object-oriented language gets in the way because the JSON needs to be translated into objects only to be rendered out again - a waste of programming effort . I agree with the point about waste, but I argue that it's not a problem with objects but a failure to understand encapsulation.
Continuous Delivery
Continuous Delivery is a software development discipline where you build software in such a way that the software can be released to production at any time.
You’re doing continuous delivery when:
- Your software is deployable throughout its lifecycle
- Your team prioritizes keeping the software deployable over working on new features
- Anybody can get fast, automated feedback on the production readiness of their systems any time somebody makes a change to them
- You can perform push-button deployments of any version of the software to any environment on demand
Deployment Pipeline
One of the challenges of an automated build and test environment is you want your build to be fast, so that you can get fast feedback, but comprehensive tests take a long time to run. A deployment pipeline is a way to deal with this by breaking up your build into stages. Each stage provides increasing confidence, usually at the cost of extra time. Early stages can find most problems yielding faster feedback, while later stages provide slower and more through probing. Deployment pipelines are a central part of ContinuousDelivery.
DIP in the Wild

The Dependency Inversion Principle (DIP) has been around since the early '90s, even so it seems easy to forget in the middle of solving a problem. After a few definitions, I'll present a number of applications of the DIP I've personally used on real projects so you'll have some examples from which to form your own conclusions.
Xp Velocity
Velocity is a notion that helps calibrate a plan by tying broad statements of effort into elapsed time. Velocity is a statement of how much stuff a team (or a person if it's personal velocity) gets done in a time period. You should usually determine velocity by measuring how much got done in past periods, following the principle of YesterdaysWeather. A typical approach is to average the velocity the past three time periods to determine velocity for future time periods. Velocity was originally formed as part ExtremeProgramming but has since spread and is now used widely in agile software development of all flavors.
User Journey Test
User-journey tests are a form of BusinessFacingTest, designed to simulate a typical user's “journey” through the system. Such a test will typically cover a user's entire interaction with the system in order to achieve some goal. They act as one path in a use case.
Story Test
Story tests are BusinessFacingTests used to describe and verify the software delivered as part of a UserStory. When a story is elaborated the team creates several story tests that act as acceptance criteria for the story. The story tests can be combined into a regression suite for the software and provide traceability from the requirements (user stories) to tests and (through execution) to the behavior of the system. Story tests are usually BroadStackTests.
Business Facing Test
A business-facing test is a test that's intended to be used as an aid to communicating with the non-programming members of a development team such as customers, users, business analysts and the like. When automated, they describe the system in domain-oriented terms, ignoring the component architecture of the system itself. Business-facing tests are often used as acceptance criteria, having such tests pass indicates the system provides the functionality that the customer expects.
The Architecture of Gap Inc's SCMS
SCMS PO is an application that helps Gap Inc. manage purchase orders. The architecture of the application is well liked by its development team and thus makes a good expositional architecture for a system with a rich javascript front end working with a back-end serving json. Interesting design features include using knockout.js form of the Presentation Model pattern, a javascript validator running on both client and server, encapsulating data access with repositories, using MongoDB as an application database, and the testing portfolio.
D D D_ Aggregate
Aggregate is a pattern in Domain-Driven Design. A DDD aggregate is a cluster of domain objects that can be treated as a single unit. An example may be an order and its line-items, these will be separate objects, but it's useful to treat the order (together with its line items) as a single aggregate.
User Story
User Stories are chunks of desired behavior of a software system. They are widely used in agile software approaches to divide up a large amount of functionality into smaller pieces for planning purposes. You also hear the same concept referred to as a feature, but the term “story” or “user story” has become prevalent in agile circles these days.
Component Test
A component test is a test that limits the scope of the exercised software to a portion of the system under test. It is in contrast to a BroadStackTest that's intended to exercise as much of the system as is reasonable.
Broad Stack Test
A broad-stack test is a test that exercises most of the parts of a large application. It's often referred to as an end-to-end test or full-stack test. It lies in contrast to a ComponentTest, which only exercises a well-defined part of a system.
Javascript Promise
In Javascript, promises are objects which represent the pending result of an asynchronous operation. You can use these to schedule further activity after the asynchronous operation has completed by supplying a callback.
Expositional Architecture
One of the problems with growing our understanding of software systems is that we don't see enough examples. In many professional disciplines, people learn by looking at what's already been done. Examples serve as inspiration, a source of good ideas, and warnings of difficulties. For a long time it's been much harder to learn about software this way.
Ruby Rogues episode discussing P of EAA
The Ruby Rogues are a popular podcast where a regular panel discusses topics in the Ruby programming community. They have a regular book club and recently selected P of EAA as their featured book. Consequently they asked me to appear as a guest on their show to discuss the book and the patterns that it describes, in particular the interesting relationship between these patterns and the Rails framework.
Purpose Of Estimation
My first encounter with agile software development was working with Kent Beck at the dawn of Extreme Programming. One of the things that impressed me about that project was the way we went about planning. This included an approach to estimating which was both lightweight yet more effective than what I'd seen before. Over a decade has now passed, and now there is an argument amongst experienced agilsts about whether estimation is worth doing at all, or indeed is actively harmful . I think that to answer this question we have to look to what purpose the estimates will be used for.
No DBA

In many organizations, it's expected that any persistent data will be stored in relational databases that are managed by a central database management group. There are various reasons for such central control, usually centered around using IntegrationDatabases. Central data groups worry about keeping out malformed data, queries that can slow down important shared resources, and consistent data models across the enterprise.
Worthy these aims may be, but one consequence of them is considerable ceremony about storing data. I often hear complaints about change orders that take weeks to add a column to a database. For modern application developers, used to short-cycle evolutionary design, such ceremony is too slow, not to mention too annoying.
So application development groups tell me of using NoSQL databases to do an end-run around the DBAs. It helps that they are using a “mere datastore” here, not a “proper database”. That way the DBAs can be kept out of the loop, often not told or happy to not care.
Talks on schemalessness, consistency in NoSQL, and economics of software design
I gave a talk at a Thoughtworks event in San Francisco, using my usual Suite of Talks style. For this one the segments cover how and when to use schemaless data structures, why consistency in NoSQL databases is more than just ACID versus BASE, and the economic justification for well-designed software.
An Appropriate Use of Metrics
Management love their metrics. The thinking goes something like this, “We need a number to measure how we’re doing. Numbers focus people and help us measure success.” Whilst well intentioned, management by numbers unintuitively leads to problematic behavior and ultimately detracts from broader project and organizational goals. Metrics inherently aren’t a bad thing; just often, inappropriately used. This essay demonstrates many of the issues caused by management’s traditional use of metrics and offers an alternative to address these dysfunctions.
Eliminating Sales Commissions
Sales commissions are almost universally used in the software business, as in all business sectors. They are liked because they align incentives between sales staff and the companies that employ them. Nevertheless there are serious problems with the sales commission model, problems that led Thoughtworks to get rid of all sales commissions in 2013.
Transparent Compilation
Increasingly web developers are using languages like CoffeeScript and SCSS that compile to other textual source languages that execute in the browser. Such source-to-source compilers (also called transpilers ) are not new, Cfront was widely used in the early days of C++ to generate target C code. But for me there is a difference that picks out CoffeeScript and SCSS as transparent compilers
Saba

Recently we returned to one of our favorite places in the world, Saba - a very small island in the Caribbean, close to St Martin. In many ways the best things about Saba are the things it doesn't have. There are no beaches, no golf courses, no casinos. The mass tourism and resort complexes that litter so much of the Caribbean have ignored Saba since it's too small and too hilly. As a result the island is wonderfully quiet and relaxed.
Thinking about Big Data
“Big Data” has leapt rapidly into one of the most hyped terms in our industry, yet the hype should not blind people to the fact that this is a genuinely important shift about the role of data in the world. The amount, speed, and value of data sources is rapidly increasing. Data management has to change in five broad areas: extraction of data from a wider range of sources, changes to the logistics of data management with new database and integration approaches, the use of agile principles in running analytics projects, an emphasis on techniques for data interpretation to separate signal from noise, and the importance of well-designed visualization to make that signal more comprehensible. Summing up this means we don't need big analytics projects, instead we want the new data thinking to permeate our regular work.
Internal Reprogrammability
I was programming away and wanted to add an empty line above where I was currently typing. The editor I was using doesn't have this feature built-in, and I'd finally had this desire enough that I really wanted it. I did a quick google search, found a few lines of code, pasted them into my startup file, executed them, and lo I could now create empty lines above with a single keystroke. It took just a couple of minutes, I didn't have to install any plugins, or restart the editor - this is normal everyday business for an Emacs user.
Schemaless Data Structures

In recent years, there's been an increasing amount of talk about the advantages of schemaless data. Being schemaless is one of the main reasons for interest in NoSQL databases. But there are many subtleties involved in schemalessness, both with respect to databases and in-memory data structures. These subtleties are present both in the meaning of schemaless and in the advantages and disadvantages of using a schemaless approach.