
Enterprise Integration Using REST
Most internal REST APIs are one-off APIs purpose built for a single integration point. In this article, I'll discuss the constraints and flexibility that you have with nonpublic APIs, and lessons learned from doing large scale RESTful integration across multiple teams.
18 November 2013

Brandon Byars is a technologist and principal consultant at Thoughtworks. He has experience leading teams in large scale engagements, with an interest in applying systems thinking to software development.
Why REST for enterprise integration?
Legacy replacements are hard. In fact, I'm willing to wager that large-scale legacy replacement is the hardest job in the entire IT industry. Most of us will never write software that companies continue to depend on for decades, but such software is commonplace in large legacy replacements, and its authors should be applauded. Nonetheless, such software predates much of what we've learned about design, testing, and good operational practices, and as such can be incredibly difficult to understand and change.
We often go into such replacements imagining the pristine architecture the new system will have and vastly underestimating the difficulty of the endeavor. Certain patterns emerge, understandable when seen against the backdrop of a massively entangled, custom built, difficult to change legacy system. First, we purchase vendor packages with the goal of reducing the in-house development effort to integration, vowing never again to be beholden to a bespoke system with no external support. Second, we land upon a service oriented architecture for integration, with the goal of baking in replaceability of the individual parts of the new system and reducing the pain of the inevitable future legacy replacement project.
Thoughtworks has been involved in several large scale legacy replacement projects, although we can't always publicly speak about them. REST over HTTP is an appealing option for many such projects, and one we commonly advocate for. It is simple to use and understand and requires no heavyweight framework or toolchain to get started. It lends itself well to testing and reduces many operational concerns to the same practices used to manage a web site. Achitecturally, REST has proven scalability and fits in well with domain modeling.
Many online discussions of REST dive into minutiae about content types and hypermedia as the engine of application state (HATEOAS), but leave off any advice for the engineering and management practices needed to make REST work for large integration projects. My hypothesis is that success in such projects has much less to do with understanding the nuances of HATEOAS, and much more to do with understanding such aspects as your deployment and testing strategies. The following lessons are the ones I've learned from doing large scale RESTful integration.
Define logical environments - one for each need
Many large IT organizations inherit a legacy of expensive environments from mainframes or large vendor installations and try to shoe-horn services into a predefined list of inflexible environments. Unfortunately, managing an enterprise-wide set of environments that all developers must use gives up one of the principal advantages of RESTful services: lightweight environments. While services may be a facade in front of applications that require substantial horsepower, the services themselves tend to be simple to deploy and host, and testable through a browser and a command line. Furthermore, techniques such as using ATOM-like event feeds avoid the need for extensive middleware infrastructure in spinning up a new environment. The key insight is to understand the concept of a logical environment:
A logical environment is an appropriately isolated set of interrelated applications, services, and infrastructural components needed to satisfy a business or development need.
The components needed to satisfy a development need may be quite different for the various teams and roles than the components needed to satisfy a business need. Few developers in large organizations expect to run an isolated full-stack environment, and isolation should go only as far as needed to make developers productive. For example, in a retail project, a developer in the order entry team may require services for the product catalog and customer management, but perhaps not for warehouse management. In production, each of those may have a load-balanced cluster supporting them, but developers and QAs value isolation over performance and availability. In the extreme case, different developers may have different logical environments on the same VM. In this case, the isolation can be accomplished by making ports and database names part of the environment configuration.
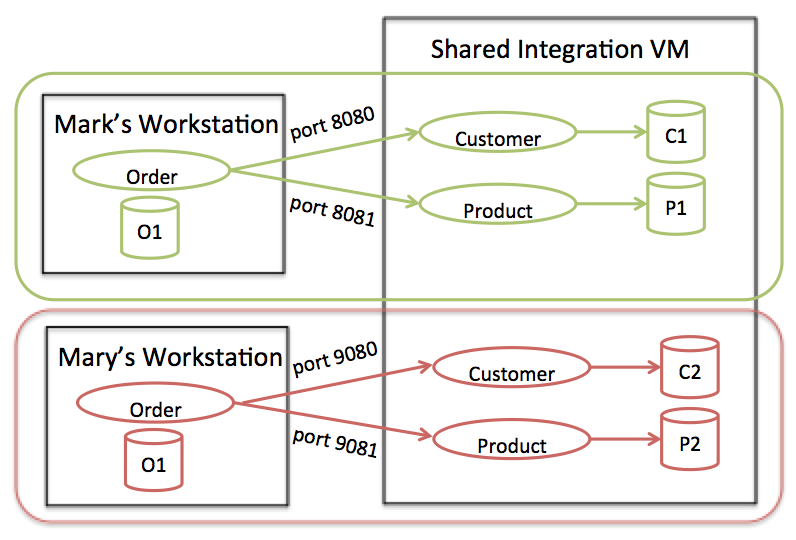
Figure 1: Environmental isolation is independent of the hardware hosting the environment
The other problem with shared environments is that everybody gets upgraded at the same time, which is often not appropriate in the chaotic world of development. Much better is to put the release schedule in the hands of the individuals affected by it - this is equally true for production releases as it is for developers upgrading a service they depend on in their sandbox environment. This can be particularly important for QAs, a role that has a stong need for managing the release cadence within their logical environment. Testing requires a known and stable set of versions for the services involved, and developers find fixing bugs considerably easier when the version is known.
In one large engagement, we defined a declarative description of environments using Yaml. A top level key would define an environment name, sub-keys defined the required services for that environment, and the next level of keys defined environment-specific configuration for each service:
order-entry-dev:
product:
webservers: [localhost]
port: 8080
logPath: /var/log/product
dbserver: localhost
dbname: product
customer:
webservers: [localhost]
port: 9080
logPath: /var/log/customer
dbserver: localhost
dbname: customer
Ruthless attention to deployment automation and appropriate investment in
infrastructure meant that some services existed in over 50 logical environments, a
mind-blowing number for a company accustomed to mainframes. Tools like Ansible help declaratively describe environments
without a heavy up-front investment. To
allow for the kind of lightweight ad-hoc environments that developers use, it's often helpful to
define a single environment with localhost as the server name, which can be spun up on a
local virtual machine using something like Vagrant.
This allows environmental elasticity by using the same environment configuration but different VMs.
What about packages?
Vendor packages complicate environment creation, as they are rarely built to support easy deployment and environmental elasticity. Many of them ship with an installation document that changes with every upgrade and no reliable mechanism to replay changes in multiple environments. Licensing also adds a hurdle, although most vendors will allow low cost development licenses.
If you find yourself burdened with a vendor package that is hard to deploy, there are a couple of remediation strategies. If the package does not require complicated licensing during installation, you may be able to do the vendor's work of automating the installation and upgrade. Alternatively you can set up a cloneable VM, which gives you elasticity but complicates upgrades. Essentially, this is the bake vs. fry distinction in configuration management discussions.
When neither option is available, there are other ways of achieving some level of isolation, although none will be comparable to actual environmental isolation. There may be a way of using natural data boundaries within the application to allow some measure of developer isolation. Different user accounts tend to be an easy data boundary, although users tend to share global state. Better still is to provide different tenants to individual developers, as multi-tenant applications are designed to prevent cross-tenant traffic. This approach is clearly a work-around, has scaling challenges, and does not provide release scheduling independence.
Ease of deployment and environment management should be one of the criteria by which packages are selected.
The best solution, of course, is to vet such operational considerations during the vendor selection process. Ease of deployment and environment management should be one of the criteria by which packages are selected. During the selection process, we have to consider not only feature set and fit-to-purpose, but ease of integration and the productivity of the integration developers.
Use versioning only as a last resort
An important corollary to the definition of a logical environment is the notion of cohesion - each environment should have only one instance of a given service. Unfortunately, in large projects where each team moves at a different pace, it is all too easy to run into the classic diamond dependency problem usually associated with compile time dependencies:
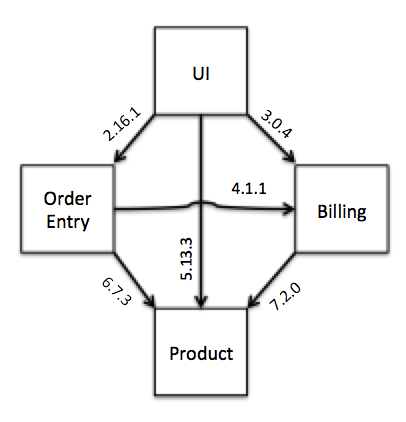
Figure 2: Incompatible version requirements
In my experience, one of the first solutions RESTful architects reach for is versioning. I take a more controversial view. To borrow Jamie Zawinski's famous dig on regular expressions:
Some people, when confronted with a problem, think “I know, I'll use versioning.” Now they have 2.1.0 problems.
The problem is that versioning can significantly complicate understanding, testing, and troubleshooting a system. As soon as you have multiple incompatible versions of the same service used by multiple consumers, developers have to maintain bug fixes in all supported versions. If they are maintained in a single codebase, developers risk breaking an old version by adding a new feature to a new version simply because of shared code pathways. If the versions are independently deployed, the operational footprint becomes more complex to monitor and support. This extra complexity is either overlooked or justified by simplifying the release process of interdependent services. However, the release complexity can be mitigated significantly with a disciplined use of consumer-based testing (discussed in the next section), an intriguing option available to enterprise APIs that is not available to public APIs.
For many types of changes, versioning can be avoided by other techniques. Postel's Law states that you should be liberal in what you accept and conservative in what you send. This is sage advice for service development. Unfortunately, the default behavior of some deserializers breaks this advice by throwing an exception when an unexpected field is provided by a consumer. This is unfortunate, as it could simply be the consumer passing additional diagnostics over the wire with no expectation of consumption, or it could be the consumer preparing for a future update of the producer, passing a new field before the producer is prepared to deal with it. It could be the producer adding a new field to a response body which the consumer is free to ignore. None of these situation warrants an exception.
Automatic deserialization usually falls into the pitfall of coupling consumers and producers.
It's usually possible to configure the deserializer to be more
tolerant. Though it's not mainstream advice, I prefer to avoid automatic
deserialization altogether. Automatic deserialization usually falls into
the WSDL pitfall of coupling consumers and producers by duplicating a static class structure in
both. Hand-coded deserialization also allows for fewer assumptions to be made in the incoming
data. As Martin Fowler describes in Tolerant Reader,
using XPath expressions like //order allows nesting changes above the
order element without breaking deserialization.
When it comes to service contract design, a little up-front design can pay big benefits.
In one project, a contract had been developed with inconsistent
casing of the attributes - firstName and LastName for example.
Developers on consumer teams no doubt swore under their breath when they developed against the
contract, but they swore quite loudly when the contract was subsequently “fixed” without
notice.
In large SOA projects, I prefer writing many stories at service boundaries. This does lead to the obvious challenge of making sure the end-to-end functionality aligns with business goals (a problem I discuss later), but has many advantages. First, they naturally tend to involve the tech lead or architect in the analysis, giving them time to think about the granularity of the concepts and mock out the contract to form a cohesive description of the resource. Writing the acceptance criteria requires thinking through the various error conditions and response codes. Having QA review at service boundaries gives another opportunity to catch the obvious mistakes, like the casing issue just mentioned. Finally, in much the same way that test-driven development encourages loose coupling by making sure each class has at least two consumers - the consumer it was written for and the tests - service boundary stories help ensure that the service endpoint is reusable rather than overly specific to the end-to-end functionality it is initially developed for. Being able to test a service endpoint in isolation prevents coupling it too tightly to the end-to-end workflow it supports.
Producers can also signal when they need to make a breaking change using semantic versioning. This is a simple scheme to add well known meanings to the MAJOR.MINOR.PATCH portions of a version, including incrementing the MAJOR version for breaking changes. If you have a disciplined set of consumer-driven tests (described shortly), you may be able to upgrade all consumers on the same release. Of course, that isn't always possible, and at some point the complexity of supporting multiple versions of the same service may be justified because coordinating a release of its dependencies is even more complex. Once you reach the point where you have to use versioning, there two principal techniques to choose between: URL versioning and HTTP header versioning. In your choice it is important to understand that the versioning scheme you select is first and foremost a release management strategy.
URL versioning involves including a version
number in the URL (such as /customers/v1/… - the
MAJOR version in semantic versioning is sufficient). For
this the consumer will have to wait until the producer has been
released. URL versioning has the advantage of being very
visible, and testable through a browser. Nevertheless, URL
versioning suffers an important flaw when one service provides
links to another service with the expectation that the consumer
will follow the link (this is most common when trying to use
hypermedia to drive workflow). If the hyperlinked service
upgrades to a new version, coordinating upgrades across such
dependencies can get tricky. For example, the customer service
links to the product service, and the UI follows that link blindly,
unaware of product versioning since the version is embedded in the
provided link. When we make a non-backwards compatible upgrade to
the product service, we ultimately want to upgrade the customer
service as well to update the link, but we have to be careful to
first upgrade the UI. In this situation, the simplest solution is
often to upgrade all three components at the same time, which is
effectively the same release management strategy as not versioning
at all.
Duncan Beaumont Cragg suggests simply extending the URL space rather than
versioning it. When you need to make an incompatible change,
simply create a new resource rather than versioning the existing one. On the
surface, there is a small change between /customers/v2/profile
and /customers/extendedProfile. They may even be implemented
the same way. However, from a communication standpoint, there is a world of
difference between the two options. Versioning
is a much broader topic, and in large organizations, versioning can often require
coordination with multiple outside teams, including architecture and release
management, whereas teams tend to have autonomy to add new resources.
HTTP header versioning puts information into the
HTTP header indicating which version the consumer will accept.
This is most commonly associated with the Content-Type,
for example, application/vnd.acme.customer-v1+json, which
allows content negotiation to manage the version. A client can send
a list of supported versions in the Accept header, and the
server can respond with the version used in the Content-Type
header, or send a 415 HTTP status code for an unsupported version request.
This appeals to purist RESTafarians, and is immune to the flaw
mentioned above with URL versioning, as the ultimate consumer
gets to decide which version to request. Of course, it becomes
harder to test through a browser and easier to overlook when
developing. It's helpful to augment header versioning by also
putting the version number in request and response bodies, when
present, to provide additional visibility. Header versioning also
introduces challenges with caching. The Vary
header was designed to enable the same URL to be cached in different
ways, but it adds complexity to your network configuration, and you
risk running into a misconfigured network cache that ignores the
Vary header.
Catch integration problems with consumer-based testing
Consumer-based testing is one of the most valuable practices I've seen that makes REST scale within an enterprise, but before we dive in, we need to understand the concept of a deployment pipeline.
Deployment Pipelines
In their groundbreaking book on Continuous Delivery, Jez Humble and Dave Farley portray the deployment pipeline as the path code takes from checkin to production. If we follow a checkin to a production release in a large organization, we might find the following steps:
- A developer checks in new code.
- The continuous integration tool compiles, packages, and runs unit tests against the source code (often called the commit stage).
- The continuous integration tool deploys to a sandbox environment to run a set of automated tests against the deployed service in isolation.
- The application team deploys to a showcase environment where internal user acceptance occurs by the business stakeholder.
- The central QA team deploys to a systems integration test (SIT) environment, where they test alongside other applications and services.
- Release management deploys into pre-production, where the application team, security, and operations perform some manual validation of the quality of the release.
- Release management deploys into production.
Modeling that workflow as a series of stages gives us our deployment pipeline, which lets us visualize the version of our service in each of the pipeline stages:

Figure 3: Simple deployment pipeline
The pipeline depicted above describes the flow for a single service in isolation. The reality of large-scale SOA projects is considerably more complicated as we add integration:
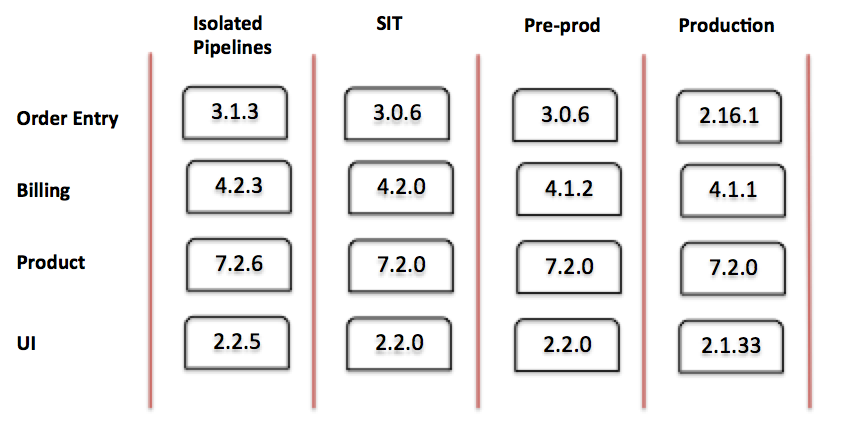
Figure 4: Integrated deployment pipeline
Note that in the integrated pipeline, I've left out a lot of detail in the early stages. Different teams often have different stages for the team-facing portions of the pipeline, which may be isolated from true external dependencies. Some teams, for example, may add manual QA or performance test stages. At the organizational stages - SIT, pre-prod, and production - it is fairly common for all code to progress the same way, and for those stages to test the services integrated together. The further you go down the pipeline, the more integrated it is and the more production-like are the environments.
An investment in stubbing can pay off large dividends in the early stages of a pipeline. It's comforting to know that when your build goes red it's because of broken code within your team and not a change in the environment you happen to be testing in. Using a test double helps eradicate a leading cause of non-determinism in your tests. Libraries like VCR allow you to record real service calls and replay the responses later during automated test runs. Using test doubles does leave you exposed to integration problems, though, and most of the complexity in enterprises involves integration. Fortunately, Ian Robinson describes a solution to tangling the integration complexity, which fits in well with our deployment pipeline.
Consumer-based testing
Consumer-based testing is counter-intuitive, as it relies on the consumers writing tests for the producer. When writing contract tests, a consumer writes a test against a service it uses to confirm that the service contract satisfies the consumer's needs. For example, the order entry team may depend on the code and description of the product service, and that the monthly charge is a number, and so they write a test like this:
[Test]
public void ValidateProductAttributes()
{
var url = UrlForTestProduct();
var response = new HttpResource(url)
.ThatAccepts("application/xml")
.Get();
Assert.That(response.StatusCode, Is.EqualTo(200));
AssertHasXPath(response.Body, "//productCode");
AssertHasXPath(response.Body, "//description");
AssertHasXPath(response.Body, "//monthlyCharge");
AssertNumeric(ValueFor(response.Body, "//monthlyCharge"));
}
This enables a neat trick in the deployment pipeline. After an individual service passes its internal pipeline, all services and consumers go through a unified contract test stage. It could be triggered by the consumer changing tests, or the producer committing changes to the service. Each consumer runs its tests against the new version of the changed service, and any failure prevents the new version from progressing in the pipeline.
In our example, let's say a new build of the order entry service progresses to the contract test stage:
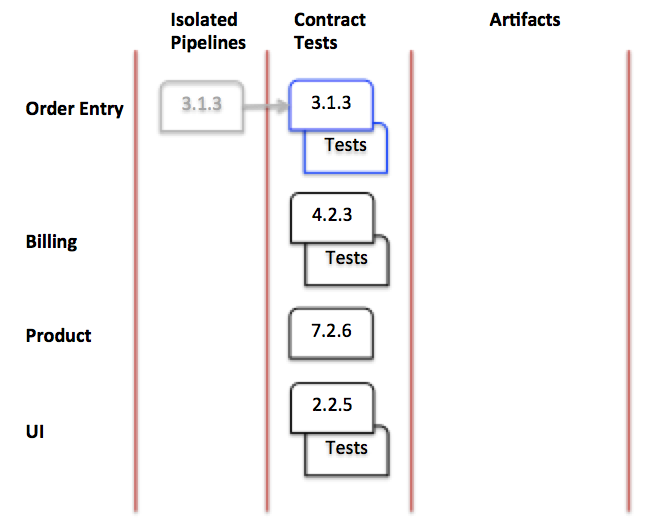
Figure 5: The contract test stage
It depends on the product and billing services, and since the new code could have changed its contract tests, it runs its tests against the last version of the product and billing services to make it into the contract test stage. The UI depends on the order entry service, so the last version of the UI code in the contract test stage runs its tests against order entry. This means that both the services and their consumer tests are required in the contract test stage. Since the product service has no dependencies, it has no consumer tests. Let's look at our diamond again; this time note that there is only one version of each service depended on.
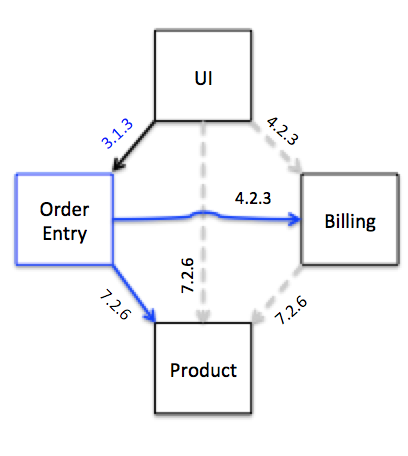
Figure 6: Sample contract test run
Triggering only the tests associated with a particular change can get tricky, but you can go a long way simply by running all contract tests each time a new service is deployed to the contract test stage of the pipeline. This would include the grey lines in Figure 6, which aren't relevant to the change that was introduced. It is a tradeoff between speed of the test run and how complex you're willing to make the dependency management.
{kind=link}
Assuming all the tests pass, we now have a set of services that have been shown to work together. We can record the set of them together, and their associated versions.
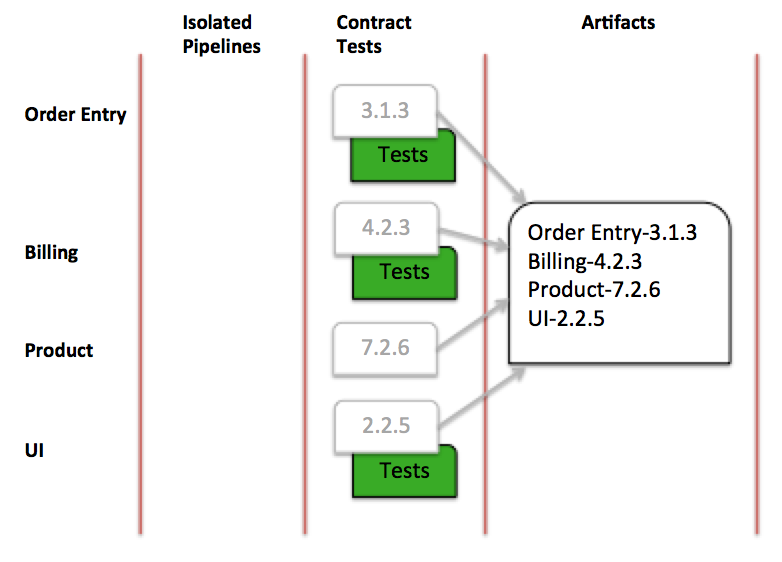
Figure 7: Successful contract test run
At this point, all versions of the services involved are captured in a single deployable artifact set, or DAS. This DAS can become the single deployable artifact for higher stages of the deployment pipeline. Alternatively, it can provide a compatibility reference if supporting independent releases is required. Either way, it represents a set of components that have been proven to speak the same language.
If the new order entry code broke the UI consumer tests, the combined artifact does not progress. This doesn't necessarily indicate a problem in the service; it could be a misunderstanding of the contract by the consumer. Or, it could be an intentional breaking change from the producer, although according to semantic versioning etiquette, they should have incremented their MAJOR number if it was intentional. In any case, failing contract tests triggers a conversation between the two teams early, rather than days or weeks later when the consumer updates their environment.

Figure 8: Breaking contract change
What about data?
One of the harder challenges with getting comprehensive consumer-based testing is generating valuable
test data. The contract test above assumes a known test product. I hid this assumption away
with a UrlForTestProduct method, which presumably requires having a URL for a
specific product. Hard-coding assumptions about data available at the time of the test can be a
fragile approach, as there are no guarantees that product will continue to exist in the future.
Furthermore, some endpoints may require data consistency across multiple services to work. For
instance, order entry may submit an order to billing with a set of associated products. The
billing endpoint will need to have a consistent set of product data.
One of the more robust strategies is to create the test data during the test run, as you guarantee the data exists before using it. This presupposes that each service allows creating new resources, which isn't always the case, although at one client we added test-only endpoints to facilitate test data creation. These endpoints were not exposed in production. This strategy can still require complicated test setup in the billing example above. After creating a test product, you would have to force synchronization with the order entry and billing services, an operation that is often asynchronous in nature. An alternate strategy is to have each service publish a cohesive set of golden test data that it guarantees to be stable. This is usually best encapsulated in some higher level data boundary. For example, you may create a test marketing brand or line of business that crosses all the services for the sole purpose of providing fake data that won't have production impacts. Either way, wrangling test data should be a first class concern for enabling a robust service deployment pipeline.
Do not let systems monopolize resources
Defining data boundaries poorly is one of the most expensive mistakes an architect can make. A common anti-pattern is to attempt to store all information about an entity in a single data store, and export it to dependent systems as needed, a strategy encouraged by a superficial misunderstanding of master data management (MDM). The problem with such a strategy is that it violates Conway's Law, which states that software architectures are bound to reflect the structure of the organization that built them 1.
1:
There are several different viewpoints on Conway's Law, and some see it as a purely descriptive tautology. I'm using it more in line with the variation that Wikipedia associates with James Coplien and Neil Harrison. It may indeed be a descriptive law of software within an organization, but I believe that's only because software that attempts to work against Conway's Law is doomed to fail.
Let's look at an example of a product catalog. In the legacy system, one team entered new product codes and their associated rates. A provisioning team used another tool to enter appropriate configuration, such as the codes downstream phone provisioning systems needed, and the service codes to turn on TV channels in another application. The finance team entered general ledger information about the product in their financial tool, and the invoicing team added special invoicing rules in yet a different application. The communication between these teams was managed by the business, not by technology.
Transitioning to a single application for all product data can be a disastrous exercise, primarily because those different business teams all have a different definition of what a product is. What a customer service representative thinks of as a single product may have to split in two to support proper accounting. The invoicing team, highly concerned with reducing call rates by simplifying the invoice, often needs to merge two product codes into a single line on the bill. And of course there's always marketing, who redefines products with reckless abandon. Attempting to rationalize the entire enterprise view of a product into a single catalog simply makes that catalog both fragile and inflexible. Effectively, the entire enterprise must now descend into the product catalog to make a change. The surface area of change is significantly increased, and the ripple effects from a change become hard to reason about. Conway's Law is violated, as the communication paths of the system no longer represent the communication paths of the organization.
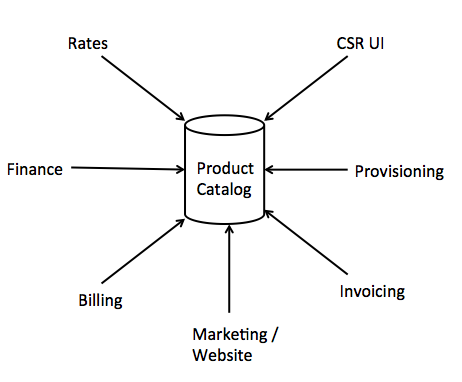
Figure 9: A data modeling disaster
I am more than a little skeptical of universal data models that try to standardize the canonical representation of something as important as a product across an enterprise and its integration partners. The telecommunications industry made just such a data model, called the TM Forum Shared Information/Data Model (TMF SID). The claim is that, by standardizing on the SID, different companies, or departments within a company, can use the same terms to describe the same logical entities. I suspect such a massive undertaking would not be sustained without some successes, but I've not seen them.
My recommended solution, borrowing from Eric Evans' Domain Driven Design , is to wrap each team's definition of a product behind a bounded context. A bounded context is a linguistic boundary, within which a term is guaranteed to mean the same thing wherever it is used. Outside the bounded context, no such guarantees exist, and a combination of integration and business process must manage the translation. That a financial product is different from a provisionable product can now be modeled in a way that abides by Conway's Law.
Providing well-defined bounded contexts around packages is a great use of facade services. A natural consequence of vendors evolving their package to support multiple businesses is that the feature set of the package likely extends beyond your enterprise needs. Wrapping all communication with the package behind a facade service allows you to limit and shape the package data into the bounded context that your business process defines, and provide a clean API that transforms the package-specific vernacular into the language defined by your enterprise.
Use a small subset of data for centralized entities
The way we do this technically is to shrink the set of master data that resides in the product catalog, and replicate that data to other systems, where it is augmented. This technique is sometimes associated with “swivel chair integration,” but it's not the same. In true swivel chair integration, the same information is entered in multiple applications that do not directly integrate. With bounded contexts, master data is replicated, and is contextually augmented and transformed in dependent applications.
The key to defining a central resource entity like a product is to understand what the business team that creates new products thinks a product is. In our hypothetical example, they decide that a product defines some basic rates and common descriptive information used by all departments. That gives us our definition of a product in the product service: a product is something we can sell to a customer that has a single rate. In the legacy world, after creating a product, the product team sends out an email to other departments. This event is likely worth automating, which we can do by publishing on a queue or a change feed exposed on our service. However, we should not pretend that we can automate away the business process that this event triggers, nor should we move that business process inside the central catalog.
When finance receives it, they have to
decide how to decompose the product. Let's say it was a bundled package of TV sports channels
at a discounted price, a concept that neatly fits the product teams definition of a product.
However, finance needs to make sure that each sports station within the bundle gets their
royalty fees, and so they need to send the single rate to different general ledger buckets.
Now we have a financial definition: a product is a association of revenue to a general
ledger account. In the use case just described, we can imagine the finance
application receiving the NewProduct event, and providing an interface for the
user to assign portions of the revenue to ledger
accounts.
Each business unit has a different model for common entities with explicit translation between their bounded contexts
When billing receives the event, they need to decide whether or not to prorate the package. Perhaps, concerned with too many customers ordering a prorated sports channel only to cancel the next day after watching the Big Game, they decide that this particular sports package requires paying for a full month up front. We start with the definition that a product is a recurring charge to a customer, and augment with a set of potentially complex configuration beyond the simple monthly rate.
Invoicing defines a product as a line on a bill. They may decide, perhaps driven
by a marketing strategy, that customers who purchased two separate sports bundles should see
only one line on the bill called “Super Sports Package,” with the summed amount. Again, we
can imagine an application facilitating receiving the NewProduct event and allowing
such combining, or we can imagine developers coding new rules upon such product introductions.
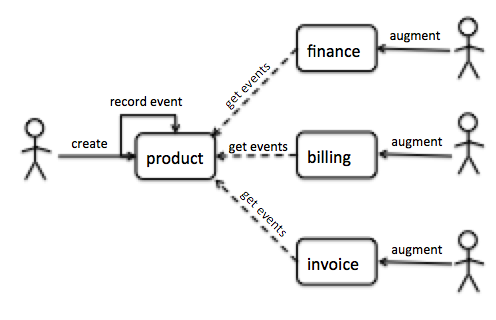
Figure 10: Example integration using bounded contexts
This example shows four different bounded contexts, and the NewProduct event being
propagated using a notification feed, which is a common RESTful approach. When a new product
is created, the product service records the new product as an event which it exposes on an endpoint.
Consumers poll the endpoint to receive all events since the last time they polled at an endpoint
that may look like /notifications?since=2013-10-01.
Use epics to coordinate business features
Earlier, I recommended considering service endpoints as story boundaries, with the caveat that we may lose the benefit of traditional agile stories - namely, that they are aligned with business functionality. Since teams work with different priorities and at different speeds, this problem is exacerbated in large scale SOA, with the risk that we lose the forest for the trees. Imagine a business feature to bill for the first month of a product. A true business flow may require a series of service calls prior to that point, involving customer creation, product lookup, order creation, and field technician approval. At scale, those service endpoints will be implemented by different teams.
The agile toolbox has always included epics for coordinating groups of stories along a single high level feature. I recommend treating them as first class citizens of program management for large scale SOA. In fact, I believe much of the ceremony we attach user stories deserves to be at the epic level for such projects, since the epics often stand in for our business friendly accounts of requirements.
For example, a Create Customer epic may involve the order entry and billing teams in addition to the customer management team, each of which have individual service-oriented or application-specific stories for tracking their work. In our hypothetical example where the services are used by a user interface developed by a separate team, we may not be able to showcase the fruits of our labor to the business until we've completed the full system flow.
Some of the care and management of epics can be lifted from story practices on smaller engagements. Getting architectural review of an epic to define cross-functional requirements, and business analysts to define acceptance requirements can help keep the whole picture in mind. Cross-team showcases should be managed at the epic level, and these may be the first showcases where the actual business user flow is shown.
Program-level metrics keep epics as the principal metric for tracking velocity, as team user-story velocity can give a false sense of progress.
The important consideration is that program-level metrics keep epics as the principal metric for tracking velocity, as team user-story velocity can give a false sense of progress. The symptom to watch for is when velocity burnups show the program delivering on time, but nothing seems to work. I was on one project where this was the case based on individual story velocity tracked by the individual teams. Some teams were on time, others slightly behind schedule, but we were unable to showcase anything to the business after months of development. Simply changing the program-level burnups to show the number of epics completed instead of the number of stories completed was illuminating. Despite individual teams showing significant progress, we had only completed one epic. Worse yet, at least one story from a full two-thirds of all epics needed to release was in play at the same time. Traditional software kanban approaches attempt to limit work in progress at the story level. When we realized the scope of the problem, we were able to course correct by resequencing the story development to limit the number of epics in progress at the same time.
Wrapping up
Regardless of the technology or architecture, scaling software development is tricky business. We often fool ourselves into thinking otherwise by pretending that it's “just integration.” Eric Evans' once said that, in any large system, some of it will be poorly designed. My experience - even with highly skilled teams - has led me to believe that he's right. Our principal goal of integration, therefore, is to ensure that we insulate ourselves from another subsystem's design.
I am an advocate for a RESTful service integration strategy. I believe REST makes for simpler development and, because RESTful messages tend to be self-descriptive, simpler testing and troubleshooting. However, it is far from the silver bullet some imagine it to be, and RESTful integration at scale requires paying attention to the lessons described above. My own experience has led me to believe that:
- Environmental isolation matters. Paying attention to deployment automation is critical. Selecting packages that disregard good deployment practices will slow everyone who needs to integrate with that package down.
- Versioning prematurely adds unnecessary complexity to the system. Practices such as tolerant deserialization and endpoint-based story analysis help you delay versioning, and are useful practices even if you subsequently add semantic versioning support.
- Using consumer tests greatly reduces the release management complexity of upgrading a set of inter-dependent services, and further helps delay versioning.
- Attempting to let a service control all data about an entity is disastrous. Do not ignore business process and the different definitions the business has for an entity.
- Coordinating business functionality is unlikely to happen at the user story level at scale. Epics are required to sequence business releases.
Using hypermedia, content negotiation, and a uniform interface get all the attention in RESTful discussions, and they are valuable techniques, but making integration solutions scale requires us to step away from the mechanics of REST and look at social and organizational issues. Navigating such issues successfully does not mean that each individual service, or component, will be well designed. It does mean that you will have solid practices in place to incrementally deliver business value and ensure appropriate robustness at the integration layer, and those practices may spell the difference between a successful delivery and a failed one.
Acknowledgments
Special thanks to Martin Fowler, Damien Del Russo, Danilo Sato, Duncan Beaumont Cragg, and Jennifer Smith for early feedback on this article. Many of the ideas came from using my Thoughtworks colleagues as sounding boards on different projects. While there are too many to name here, I would like to call out Ryan Murray, Mike Mason, and Manoj Mahalingam for their particular influence on some of the ideas presented here.
Footnotes
1: Conways' Law
There are several different viewpoints on Conway's Law, and some see it as a purely descriptive tautology. I'm using it more in line with the variation that Wikipedia associates with James Coplien and Neil Harrison. It may indeed be a descriptive law of software within an organization, but I believe that's only because software that attempts to work against Conway's Law is doomed to fail.
Significant Revisions
18 November 2013: added option of extending the URL space to avoid versioning, and a footnote to clarify Conway's Law usage
12 November 2013: added section on using epics, thus completed initial publication
08 November 2013: added section against letting systems monopolize resources
31 October 2013: added section on consumer-based testing
24 October 2013: added section on versioning
21 October 2013: release first edition with logical environments section