
Compliance in a DevOps Culture
Integrating Compliance Controls and Audit into CI/CD Processes
Integrating the necessary Security Controls and Audit capabilities to satisfy Compliance requirements within a DevOps culture can capitalize on CI/CD pipeline automation, but presents unique challenges as an organization scales. Understanding the second order implications and unintended consequences caused by the chosen implementation is key to building an effective, secure, and scalable solution.
02 November 2021

Carl Nygard is a Technical Principal at Thoughtworks. Carl has over 20 years of experience leading work across start-ups and large enterprises in various domains such as GIS/remote sensing, supply chain, real-time controls, online education, retail, and government. He works with organizations to develop technology strategy and determine optimal technology investments to enable digital transformation goals.
Across many industries, there are regulatory standards which mandate compliance with a wide variety of regulations. Examples include Sarbanes-Oxley defining financial system controls, ISO-27001 defining Information Security Management Systems (ISMS), or Authority to Operate (ATO) within governmental organizations. Teams building and deploying software within these environments must comply with the relevant standards and requirements before the team can deploy any software into production use.
One of the goals of DevOps is to meet the cross-functional requirements more effectively and efficiently by “shifting left”, essentially making security and quality concerns part of the normal developer feedback cycle. However, Compliance Controls and Audit activities remain essential for meeting regulatory standards.
Various methodologies have been developed to provide proof of compliance with the regulatory requirements, and each have their own benefits and tradeoffs. In this article, we will explore four major implementation methodologies and examine the tradeoffs and benefits of each approach under a variety of conditions.
Theory
Let's start by reviewing the fundamental theory of compliance processes, so that we have a common view of the compliance objectives, process components, and terminology to understand the context within which teams function.
Goal
Our objective is to be able to safely deliver changes to a system by deploying a release to the production environment in Compliance with the relevant regulations applicable to the system. These regulations may be organization-specific internal requirements, or they may be industry-wide regulations or governmental mandates.
The regulations and Compliance structures are meant to ensure quality and correctness of the system and are a form of risk management.
Context
Our development teams operate within a DevOps culture, which stresses team-centric capabilities such as team autonomy, frequent releases of small units of value, and low Mean Time To Recovery (MTTR) in order to minimize risk while accelerating software delivery.
Process Owner
Our organization has an Office of Compliance (OoC) which defines the desired set of outcomes to achieve (the What as opposed to the How) and the process by which systems must be validated before they can be deployed to production environments. This allows the teams to self-solution to meet the outcome, given agreement from the OoC that the solution leads to the desired outcome.
For example, an outcome might be “high quality software”, for which a team may get agreement from the OoC that code coverage > 80% as reported by CodeClimate satisfies the outcome.
As a more complicated example, an outcome might be “All changes are necessary changes”, which might lead to a solution which requires all commits to be associated with the relevant JIRA ticket, prioritized by the product owner, and PR reviewed by another developer. Instead of PR review, another team might use pair-programming combined with trunk-based development, and simply identify both developers and the JIRA issue in the commt log.
Compliance Process
From a high level, evaluating the state of compliance involves measuring the properties of the system, validating this evidence against a set of constraints, and recording the results.
- Property: an objectively measurable attribute of the system
- Measurement: a test which measures a property of the system
- Evidence: the resulting measured value of a property. Usually true or false (truthy values) or numerical.
- Constraints: limits within which a property value must fall in order to meet the requirement(s)
- Validation: comparison of the evidence to a specific constraint, which proves that the system is “in compliance” for a specific requirement.
Note: The concept of a fitness function1 is a composition of two tasks; the measurement to obtain evidence, and the validation that the evidence meets a specific threshold or value constraint.
1: See chapter 2 of Building Evolutionary Architectures
A simple example might be to extract from Kubernetes configuration (measure) a list of open ports (evidence) and validate that only ports 80 or 443 are open (constraint).
A more comprehensive fitness function might be to measure the code coverage (using any of the variety of available tools, such as JaCoCo, SonarQube, CodeClimate, etc), examine the report (evidence), and validate the reported value against the desired code coverage level of 80% (constraint).
A more complex example involving a variable constraint like the Common Vulnerabilities and Exposures (CVE) list might be to scan a container (measure) for the existence of CVEs (evidence), and validate that there exist no CVEs that have not been accepted as known risks (variable constraint).
Threat Model
One of the concerns in any Compliance process is the validity of the results and the integrity of the system. In other words, how much trust can be placed in the compliance process?
It's important to create a threat model in order to identify the specific risks to the Compliance process. Many companies assume a developer may be compromised, which leads to questions such as “Are there ways for changes to be introduced to the final system which are not visible or auditable?” For example, if developers have access to the build infrastructure, it would be possible for one to login during the build process and change the code in a way that isn't reflected in the SCM or in any audit logs.
Understanding the threat model will guide the organization toward the strategies which need to be implemented in order to mitigate the risks (i.e. implementing appropriate CI/CD infrastructure security). However, the threat model will be different depending on the organization and the specific Compliance methodology in use, and is beyond the scope of this article.
Audit Process
The Audit process is a form of meta-compliance, essentially validating that the Compliance Process is in fact operating and following defined requirements in a consistent, accurate manner. Since this is a test of the Compliance Process itself, it occurs at a higher level, but follows the same patterns described above. It has a smaller, simpler set of rules and requirements, and is generally accomplished by evaluating a random sample, rather than exhaustive validations of every compliance activity.
Patterns
Now that we have an understanding of the fundamental components of a Compliance process, we can examine some common implementation patterns with this lens. Understanding how each pattern maps back to the foundational concepts will help us evaluate and compare each pattern, and understand the root cause of the tradeoffs inherent in each implementation.
The patterns start off simple and gradually become more complex to deal with the second-order effects caused by the growth of organizational and delivery scale. We start with the simplest form, Manual Compliance. As an organization grows, Compliance activity may be incorporated into build pipelines. As the scope of solutions needed to run the business grows, it is common to start looking for ways to capitalize on shared capabilities, which often leads to leveraging a composition of compliant container images. Finally, we discuss how the single-responsibility principle leads to a complete reorganization of the Compliance domain boundaries as we shift Compliance verification to the point of change.
Manual Compliance
People carry out compliance checks, usually assisted by a checklist.
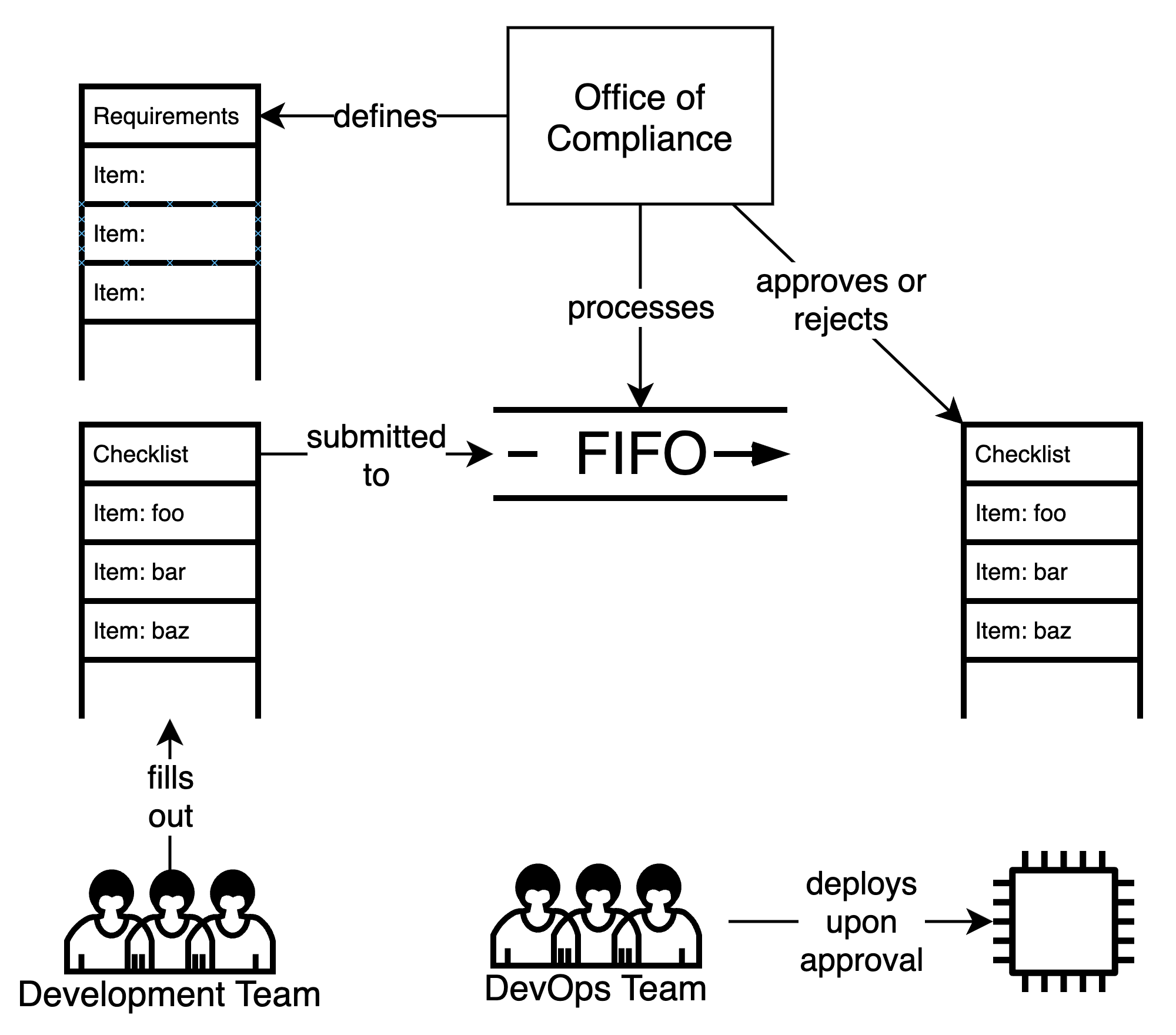
Manual Compliance is perhaps the simplest form of compliance process. In this methodology, the Office of Compliance has defined the set of properties to be measured and has implemented the measurements as a set of forms or questionnaires. These survey questions may have simple responses such as a yes/no checkbox, a list of open ports or URLs, or may require a narrative description, for example secure access rules or backup and recovery procedures.
Measuring the system properties for each release is manually performed by the development team by filling out the form or questionnaire, supplying the evidence in written form as they respond to each item.
The act of validating the evidence is performed by a compliance officer, who goes through the submission applying comparison heuristics to the evidence supplied by the development team. This rubric may vary depending on the item, for instance ensuring no ports other than 80 and 443 are listed on the form, or that no “unaccepted” CVEs are listed on the form. Regardless of the rubric, all such validations should be objective.
Auditing the compliance process is also a fairly simple exercise of reviewing a random selection of Compliance Forms to ensure that the information on the forms is an accurate representation of reality, and that the answers all pass the validation rubrics. However, because of the highly manual nature of this process, it can be highly inconsistent in both its application and the outcomes. The Audit process may need to be executed more frequently and in greater level of detail in order to achieve the desired level of reporting consistency.
When to use it
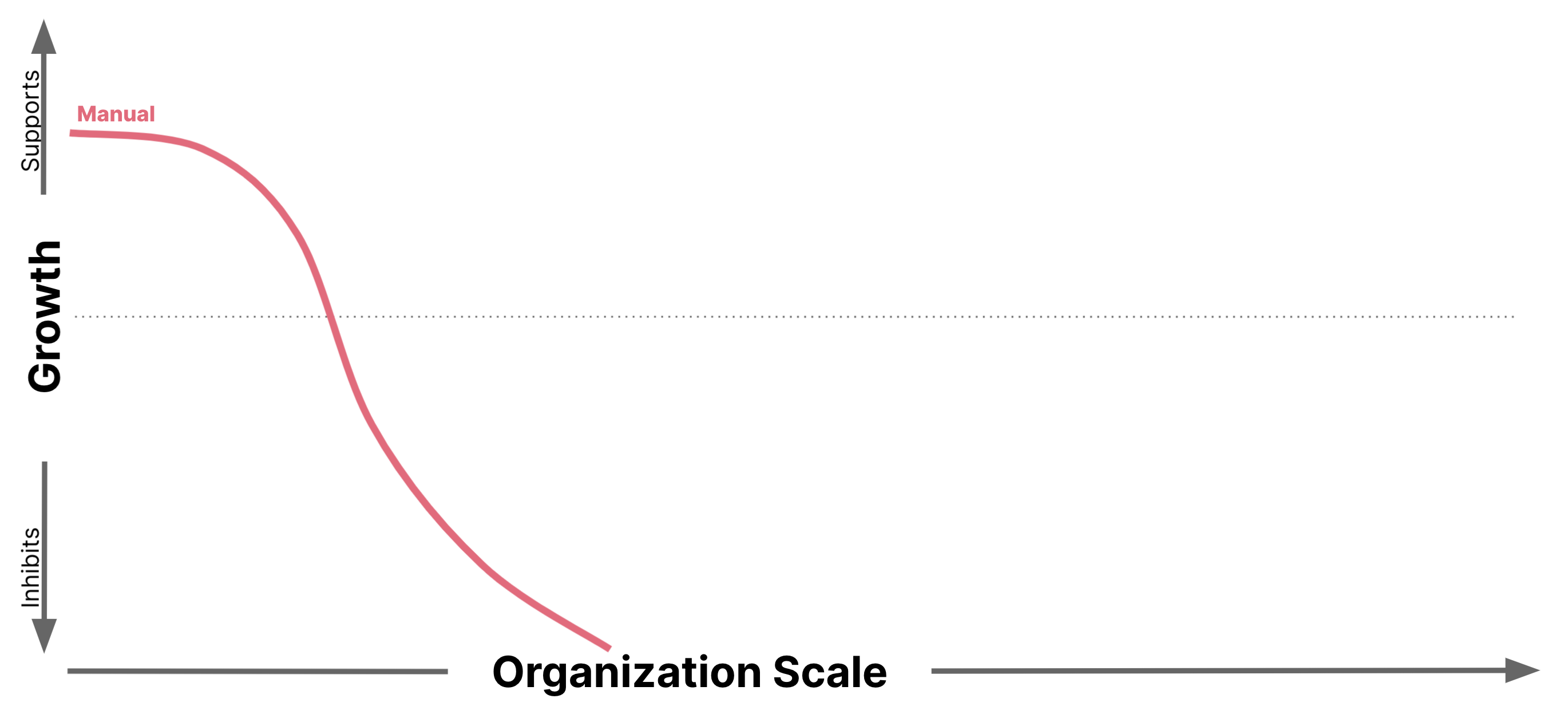
This can be a simple and easy process, if the set of properties to be measured is small, the releases are infrequent, and the responses are simple. Implementing this process for a small scale Compliance process does not require a large investment of resources or time. It can be as easy as creating a Google Form for teams to complete and submit. Typically an implementation of this type also involves a manual review process, often implemented as a formal approval tied to a review meeting.
This process can become painful quite quickly as the organization scales. The additional scale creates challenges which manifest in multiple dimensions as a result of increased workload and complexity.
Capacity challenges arise from the increased scale of the workload driven by the increasing size of the organization. As the organization grows, the capacity for operating the Compliance process must grow in proportion to handle the additional requests for Compliance approval. Due to the random nature of deployment approval requests, the flow of work to the central Compliance team is highly variable, and therefore it is costly to size the central team for quick response. As the organization grows, this problem is magnified.
Complexity challenges arise as the organization scales, creating new and exciting failure modes, which in turn drive changes to the Compliance process. Compliance forms grow in size and complexity, requiring more time and effort from both the development team and the Compliance team to complete the process.
Second order effects may appear as the Compliance process shows its inefficiency at scale, and starts to become the limiting factor in how quickly development teams can deliver business value.
A team may focus on cost efficiency by batching the changes in a deployment such that the work to develop the value being released represents a significant fraction of the total cost required to deploy those changes to production.
The lead time for compliance processes will also dictate batch sizes, because limitations in the work capacity of the Office of Compliance put an upper limit on the number of deployment requests which can be processed in a given period of time. Given a constrained number of deployments, the only way to increase the value delivered to the customer is to increase the batch size.
If the Office of Compliance becomes overloaded (for any reason), then the queue of teams waiting for Compliance results grows - the compliance process itself is a bottleneck limiting value delivery. Quite often, the pressure of delivery overwhelms the Compliance process, and development teams actively abuse, subvert, or avoid the Compliance process altogether, resulting in “shadow IT”, compromised design and architecture decisions, or even falsifying Compliance responses.
We have seen all of these behaviors within organizations in both commercial and government spaces. We have seen manual compliance processes that realistically take 6-9 months to complete before a new service or system can be deployed to production. In another client, we were able to show that their processes not only limited the speed and scale at which the organization could deliver, but the process was highly inconsistent in its application and resulting outcomes.
The unfortunate reality is that our experience shows manual compliance processes to be a form of “security theater” resulting in delayed delivery of value without any material increase in the safety and security of the system. We have also seen these processes have disproportionate effects well beyond the delivery process, impacting organizational structures, architecture decisions, domain boundaries, and even staffing and talent retention.
Pipeline Compliance
Embed compliance checks in the deployment pipeline.
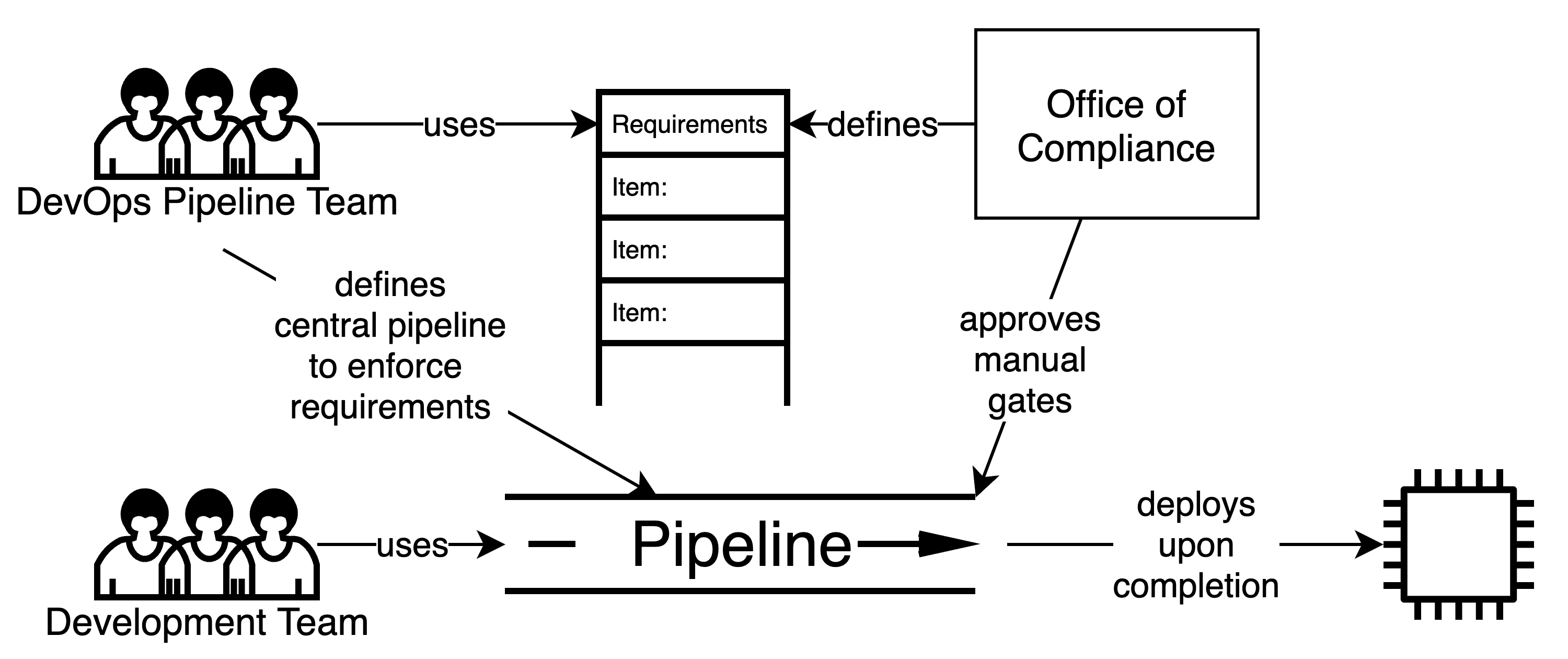
In this method, the compliance process is embedded in the CI/CD Deployment Pipeline as a set of fitness functions and manual gates between pipeline stages. The pipeline executes the fitness functions as part of the build pipeline to obtain the evidence and validate against the threshold values.
For fitness functions such as checking for open ports, software supply chain validations, or validating code coverage, it is fairly straightforward to incorporate into the pipeline. However, for some validations there may be challenges to automation (i.e. how to decide which CVEs are “approved” for a specific artifact) that result in manual gates in the pipeline.
Any failing fitness functions result in a failure of the pipeline, in effect preventing a release from being deployed to production if any Compliance validation fails.
In this way, successfully executing the pipeline implicitly proves that the system release has met the automatically verifiable Compliance requirements which are built into the pipeline. Passing the manual gates between pipeline stages explicitly indicates that the manually verifiable Compliance requirements have also been met.
When to use it
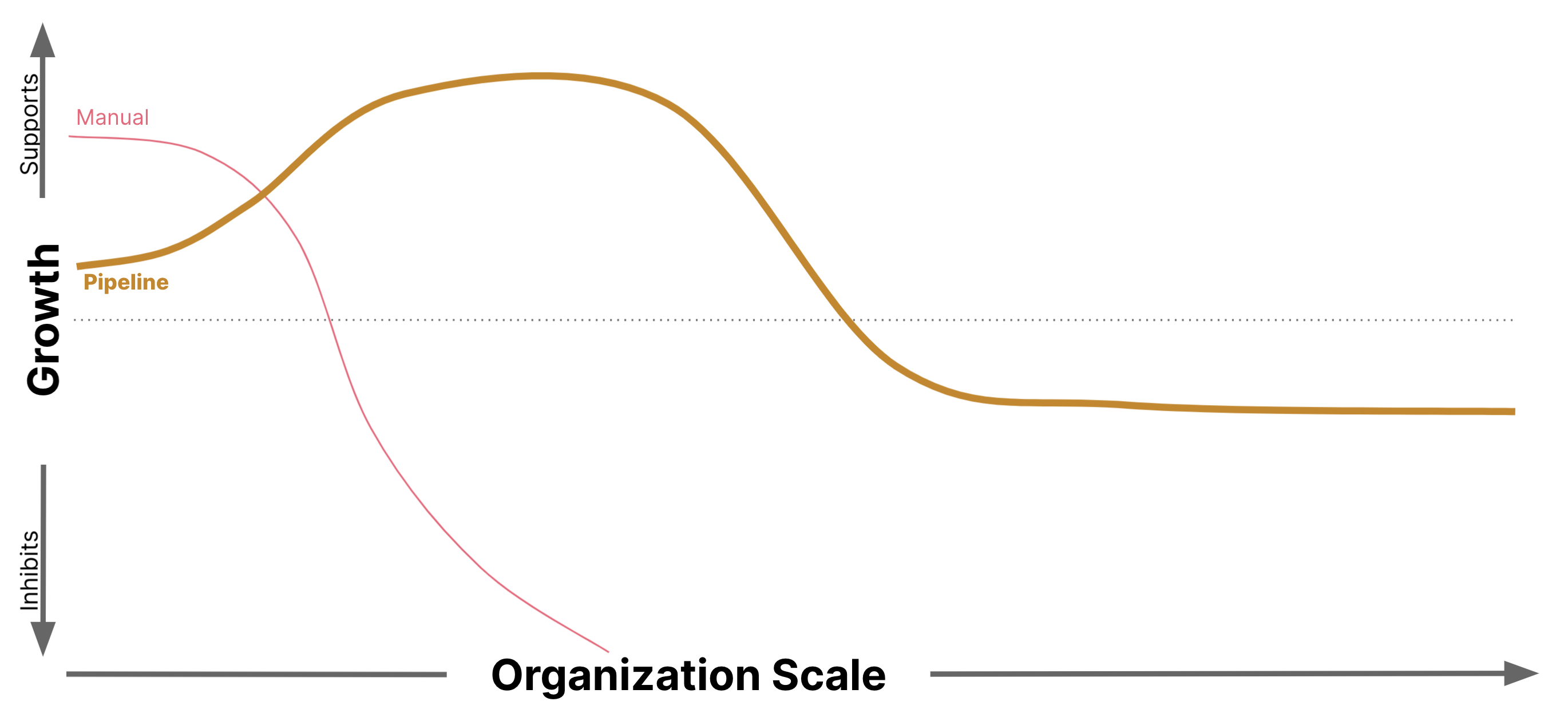
Clearly, automation of Compliance tests is an enormous benefit, both for the Office of Compliance and for the developers on the team.
The Office of Compliance can be assured that the proper Compliance fitness functions are being executed, and the pipeline logs can provide an Audit trail recording the fitness function executions and results. The team can focus their attention on delivering business value rather than gatekeeping individual changes by ensuring the pipeline does what is needed.
The developers on the team get much faster feedback in regards to whether the system release meets the Compliance requirements (at least for those requirements which have been automated as fitness functions), since a failure in the pipeline indicates a failure to meet Compliance.
In a homogeneous development environment, where every team is using the same stack, building roughly the same types of systems (e.g. REST services, etc), the teams can realize efficiency gains by copying a standard pipeline. At minimum, sharing the same Compliance fitness functions will yield economies of scale in a homogeneous environment.
A common organization response to a failure in production is to add manual verification steps to the deployment process. As an example, a Fitness Function might be defined as “all work has been completed and rollback plans exist” which must be manually verified by both the team Manager and the Security Officer. This is less than ideal as it results in a queue of work for a Role(s) nominally accountable for the system but not actually responsible for (i.e. familiar with) the changes that they are approving. 2 The net result is additional delay but no concrete improvement in the security or stability of the system.
2: See Chapter 7 of Accelerate
Another typical response is a desire to lock down the pipelines to guarantee Compliance. This may occur when some failure in production occurs, perhaps traced back to a team-specific deviation from the standard pipeline. The organization shifts responsibility for the pipeline Compliance process to one central team, with the intention of funneling every teams' system release through the same “golden” pipeline.
Our experience shows that due to the high frequency of change within a team's pipelines, central ownership of pipelines is one of the largest sources of friction within the development process. This centralization results in an overall slowdown in development, because the central team has become a bottleneck limiting teams' ability to evolve their systems.
The second-order effects are similar to the manual solution: “shadow IT”, compromised design and architecture decisions, or deploying to production without the updated Compliance pipeline.
We are aware of cases where such central “ownership” decisions are made with the express desire to slow down releases. Though not often stated publicly, the organization has realized that more frequent releases often expose systemic immaturity in its development processes. Shifting to central control is often an attempt to shift responsibility for delivery quality from the engineering and development teams to the Compliance organization.
The level of friction created over time is hard to understate. The primary reason for a pipeline to exist is to provide a central tool in the software development process. When it is co-opted and then controlled for orthogonal goals, the developer concerns tend to drift down in prioritization based on the way the pipeline team (often the DevOps team) is staffed, organized, incentivized and operationalized.
Composition Compliance
Combine components that have already been determined as compliant.
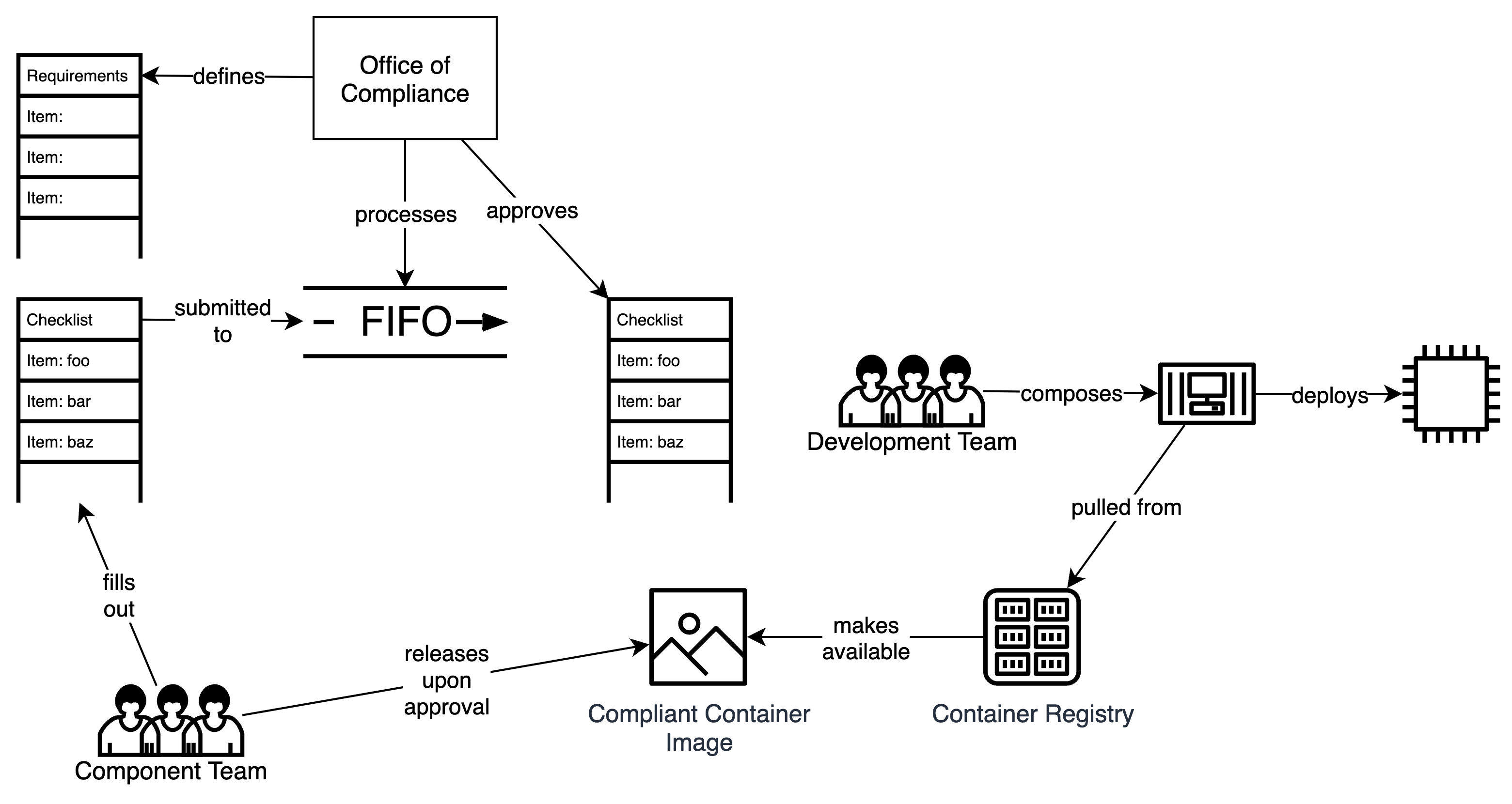
This method is based on the premise that compliance is distributive, making it possible to build a compliant system via composition of compliant components. For example, the distributive property in mathematics states that a function C is “distributive over addition” if C(A) + C(B) = C(A+B). Likewise, one may posit that Compliance is distributive over composition in similar fashion, allowing the organization to capitalize on the reusable and composable nature of containerization to efficiently achieve compliance for a broad range of solutions.
In practice, a business or technology capability which has already been tested to be “in Compliance” is made available to development teams as a container image. Over time, different parts of the organization may add or evolve new capabilities to the set of available images. The Compliance status of these images is achieved by a traditional Compliance process (either a manual or pipeline-based process). These “golden images” are locked down, and in isolation each has met the requirements of the Compliance process at that current moment in time.
The expectation is that, with training, teams can then compose these “golden images” in specific ways to build and deploy a system release. For example, a team that needs persistence can choose between a PostgreSQL image or a Cassandra image. As long as their needs fit within the bounds of what the “golden image” provides (for example, no PII, encryption at rest), they are meeting the Compliance requirements.
Processes to ensure that the “golden images” continue to meet compliance requirements are a critical part of this process. For example, CVEs may be discovered which affect currently “golden” images, requiring an updated image which resolves the issue. This will require all teams using the (now non-golden) image to update and test with the newly released images.
Auditing the compliance is a two stage process. From a team perspective, achieving compliance for a team-specific solution can be as simple as verifying the infrastructure configuration uses only “golden images” and adds no customized configuration which might violate the Compliance status of the image.
The audit of the “golden images” would follow a separate process depending on whether they were certified by means of a manual or pipeline-based process, and is a concern of the team providing the images.
When to use it
For teams having requirements that fit within the capabilities of the building blocks, this is a great solution. The “golden images” represent business or technology capabilities that the team would otherwise have to implement, and the images are already passing Compliance requirements. For example, relying on a golden PostgreSQL image means the team doesn't need to think about how to configure backup/restore, database tuning, deployment, logging, or operational considerations. All of that activity is already complete as part of the PostgreSQL building block which passes Compliance.
Given a mature collection of building blocks, a homogeneous development environment, and business needs which have low variance, this could provide efficiency gains by avoiding duplicate work across many development teams.
The friction associated with a component-composition strategy appears when these fundamental assumptions and restrictions are violated. Any product development which would require capabilities outside the scope of existing “golden images” would also require a development team to go through the same onerous Compliance process for these “non-golden” components of their system. Some teams may perceive considerable schedule risk in doing so, which may have undue influence on the architecture and design of the system.
Additionally, this is a slippery slope; at the bottom of which, the organization is no better off as every team is managing compliance for their own special-case solutions. One may argue that using compliant images as the basis for customization limits the Compliance effort to the incremental changes. However, the coupling across teams due to these shared “baseline” images increases. The unit of Compliance is still the image as a whole, so the marginal cost of Compliance over time may be larger than one might think.
Shifting responsibility to a central team for providing compliant images has all the same characteristics as noted above when pipelines are centralized.
As the component-composition solution shows its inefficiency at scale, it also starts to become the limiting factor in how quickly development teams can deliver business value. The second-order effects are similar to the manual and pipeline-based solutions: “shadow IT”, compromised design and architecture decisions, or deploying to production components which have not passed Compliance requirements.
We have observed different behaviors in systems following this pattern depending on the scale of the organization. At small scale, or during the early phases of implementing this pattern, it is easy to find teams that have similar needs, where the economies of relying on compliant building blocks are evident and provide acceleration for the teams. However, past a certain scale, the needs of the solutions being delivered diverge, resulting in familiar sources of friction wherever teams are unable to rely on the compliant building blocks.
NOTE: We are deliberately side-stepping the issue of whether Compliance is actually distributive over composition for a set of compliant container images. Assuming it is true, it may only be true for the exact container image with zero customizability, which in turn may limit the solution space to such degree that it provides no actual utility. We encourage you to think hard about what types of configurability are achievable within the bounds of compositional Compliance relative to your use-cases.
Point-of-Change Compliance
Carry out compliance checks as a change is made.
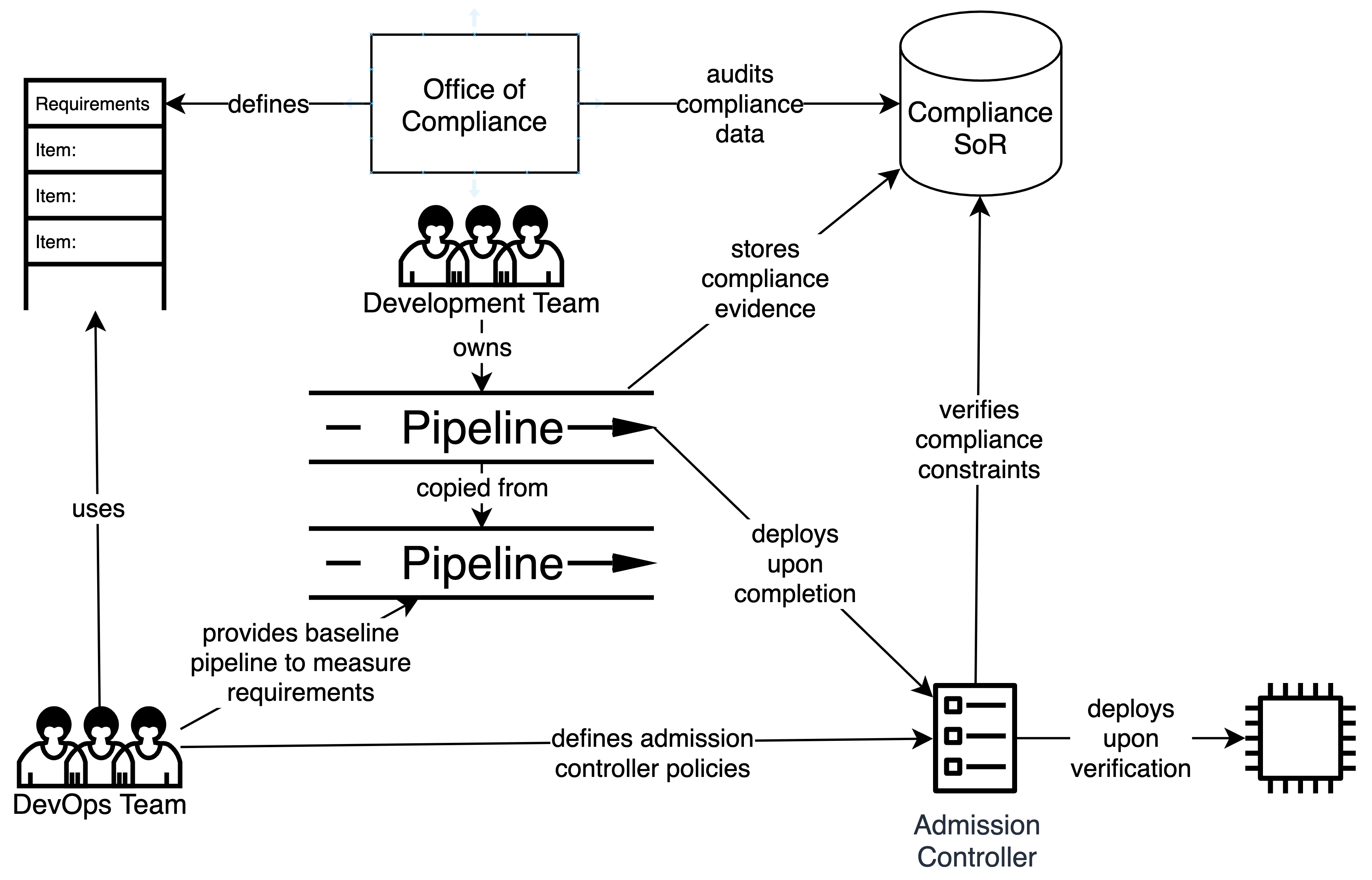
In this method, Compliance is enforced at the point of change, before the change is made. By validating that all Compliance-related constraints and requirements have been met, we can ensure that the desired outcomes (quality, security, auditability, etc) will be achieved.
In order to shift verification of Compliance to the point of change, we will need to break our process down to its fundamental steps. We refactor the application of a fitness function into its fundamental single-responsibility actions of measurement and validation. It is this split which provides the seam we need to create new domain bounds, allowing a more flexible and efficient Compliance process to be implemented.
In this process, the development team is responsible for gathering the evidence (i.e. the first half of a conventional fitness function), typically via pipeline automation. For example, the team may add steps to their pipeline to extract the list of open ports from the Kubernetes configuration files, measure the code coverage, or perform the CVE scans.
We introduce the concept of a System of Record (SoR) to store the evidence gathered by the development team. There may be one or more SoR, depending on the data being recorded or the tests being performed. For example, code coverage or CVE scans may be performed by a SaaS tool which would be the logical choice as SoR for those data elements.
Validation of Compliance is verified at the point of change, for example by Kubernetes operators which manage non-Kubernetes infrastructure components, or by an admission controller in a Kubernetes cluster. Each application has its own set of exceptions to the master list of controls, managed jointly by the team and the Office of Compliance, allowing deployment even though the evidence may indicate non-compliance. For example, a system may have a set of perpetual exceptions for controls which are not applicable. It may also have a set of temporary exceptions (e.g. for a newly discovered CVE) which give the team time to resolve accepted risks without delaying delivery of value.
Since we have split the act of measuring from the act of validating, we have introduced some uncertainty in the process when the act of measuring is not managed by the SoR directly (for example, the team has written a pipeline step to extract the open ports from the Kubernetes configuration). When querying the SoR for the evidence, how do we know the source of the evidence, or whether the evidence is reliable? When the validation was bundled with the measurement in the pipeline Fitness Function, we knew the measurement was valid. To mitigate this risk of uncertainty, we introduce the concept of cryptographically signed evidence to provide the ability to validate the provenance of the data and enable a cohesive, trusted distributed process.
Putting it all together, Compliance verification requires that all evidence exists in a SoR, the evidence gathered outside the SoR has a cryptographically verifiable signature, and that all Compliance validations of the evidence succeed. In essence, we have externalized the Compliance validation process using Policy-as-Code principles. One of the powerful capabilities enabled by this solution is the ability to change Compliance policies independently, and even evaluate a new Compliance policy against the existing evidence stored in the SoR in order to understand the impact of policy changes on currently deployed systems.
A starter kit, or centrally developed baseline pipeline, could provide a set of baseline measurement tests that have already been approved for the Compliance process. This set of baseline resources provides economies of scale across the development teams without locking the team into any specific process constraint.
If a team wishes to self-manage some part of the measurement process, a new measurement test must be approved by the Office of Compliance and integrated into the team's development process, likely into their pipeline(s). The team which desires to use the new method would need to own that approval process, but the incremental work is reduced to the smallest unit of change (i.e. an individual measurement test as opposed to a container image). Any measurements intended to be used by more than a single team should be implemented in a fully API-consumable way, enabling self-service adoption across consumers.
Auditing the process also becomes a straightforward review of the logs of the deployment step, ensuring that all outcomes have been verified by evidence that has been cryptographically signed by an approved cert.
When to use it
This solution helps to minimize bottlenecks which exist in the previously described solutions. It is inherently more complex compared to the solutions described above, and so may be limited to environments in which the organizational scale creates the types of bottlenecks which this method is capable of solving.
By separating the concerns of Compliance, we can achieve the loose coupling required to avoid the friction associated with centrally managed compliance methodologies. Teams can choose to adopt a centrally provided set of pipeline controls, while still being able to efficiently self-manage any unique requirements the team may have.
If Compliance constraints change often, the organization can efficiently determine the impact to existing systems, reducing the planning effort and simplifying the implementation process. The Policy-as-Code principles shield the teams from additional work, since the process of gathering evidence by applying measurement tests hasn't changed.
Since all inputs to the Compliance process are based on data and configuration, Audit processes are significantly more streamlined. At any given point in time, the set of evidence and the results of the validation process can be obtained by querying the SoR.
As mentioned above, the solution is a bit more complex, due to the separation of concerns. However, the complexity resides appropriately within the Office of Compliance, rather than delegated to every development team across the organization.
Issues of trust in the process must be explicitly addressed as part of the SoR and the associated secret key management, which must be managed by the Office of Compliance. While familiar bottlenecks exist in the approval process for new measurement tests, these bottlenecks are more limited in scope because the individual work items (i.e. agreement on the suitability of a measurement test) are significantly smaller, and do not significantly block the team from development.
There is still risk of “shadow IT” or deploying to production components which have not passed Compliance requirements. However, the risk of compromised design and architecture decisions is greatly reduced.
We have been implementing this pattern across multiple clients for a number of years. For one large enterprise organization, we implemented a custom admission controller which ensures compliance with deployment requirements, security, and certs, uses trusted container registries supplying CVE-scanned containers, and validates the existence of (or creates) the proper documentation. At another organization, we implemented similar capabilities, in addition to integrating a Policy-as-Code solution performing CIS Benchmark tests on the Kubernetes configurations prior to deployment.
Observations and Experience
As we take a step back and look at the range of solutions, a pattern starts to become clear. My colleague Zhamak Dehgani uses the concept of Architectural Quanta 3 to label the concept of a unit of architecture in her discussion of the concepts underpinning Data Mesh, and I think it's interesting to apply similar ideas to our Compliance domain. When we think in terms of Architectural and Compliance Quanta, some useful insights emerge.
3: In her discussion, she notes that Architectural Quantum originally came from Building Evolutionary Architecture
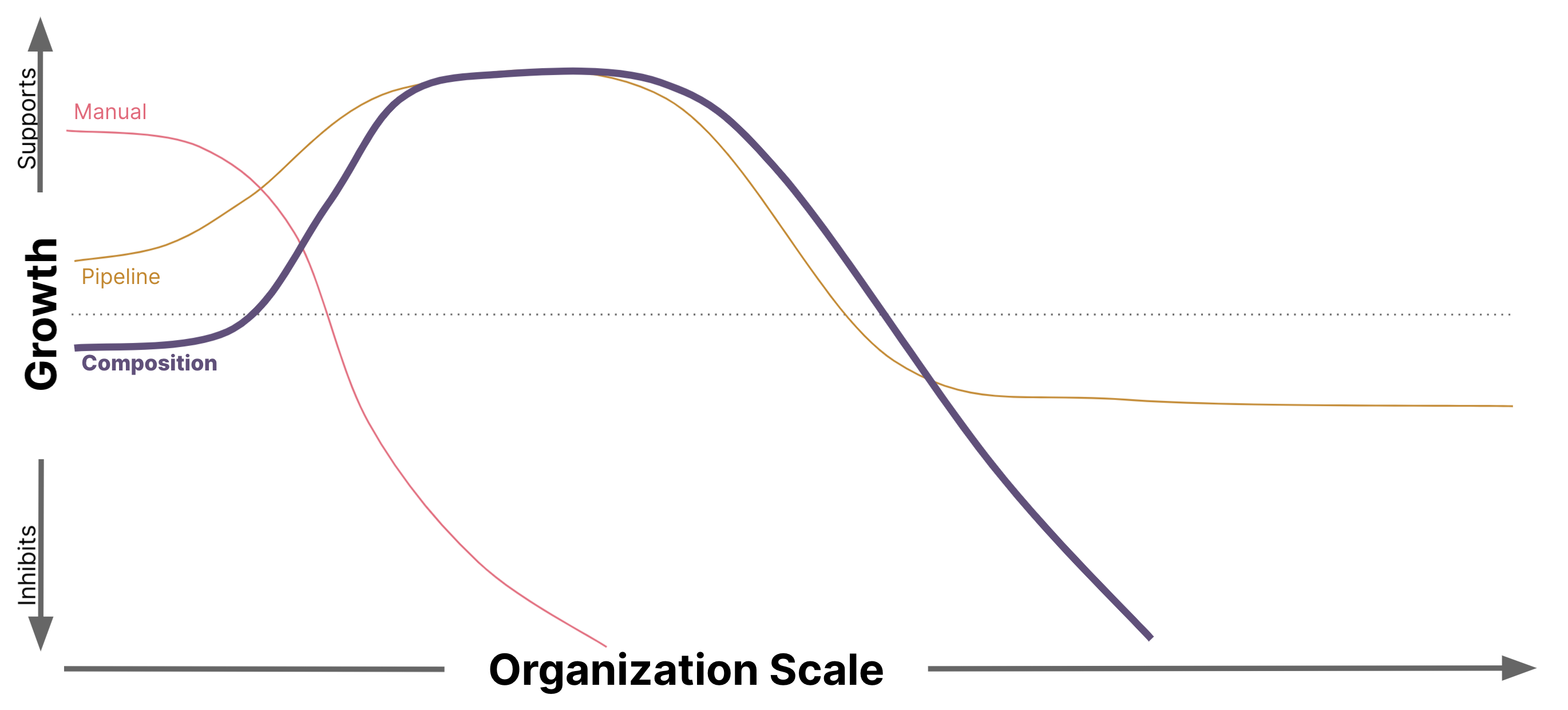
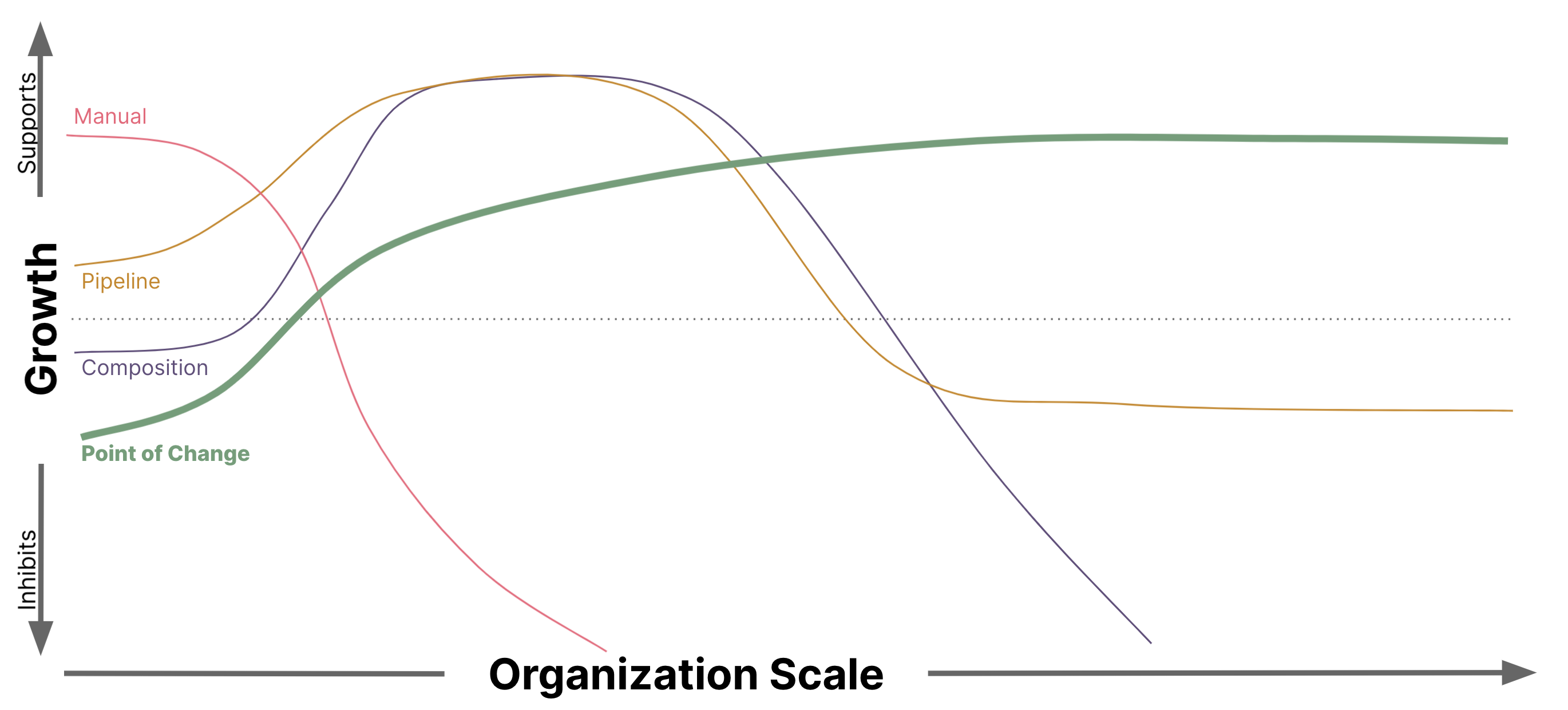
The Manual Compliance process treats each system as both the Architectural Quanta and the Compliance Quanta. This means that systems are unique entities; no matter how similar they may be, each system requires its own set of Compliance work / output. Any similarities between systems represents wasted work within the Compliance effort, especially at scale.
The Pipeline Compliance process starts to differentiate between Architectural and Compliance Quanta. Each system is a unique Architectural Quanta, but now we split the Compliance Quanta into smaller units encapsulated by Fitness Functions. This allows the organization to share these new Compliance Quanta across systems by virtue of common shared Fitness Functions in the (possibly shared) pipelines, while the team remains responsible for any unique team-specific Fitness Functions.
The Composition Compliance process takes another step by decomposing the system into smaller composable Architectural Quanta which each possess their own Compliance. Now a system composed of these Architectural Quanta is no longer responsible for executing in toto the validation process because it is now sharing the results of the Compliance process in the form of composable compliant container images. The team is now only responsible for the Compliance of their unique team-specific container images.
And finally, Point-of-Change Compliance takes the last step of decomposing the Compliance Quanta into the individual properties which predict the outcomes, and decomposing the Fitness Function into separate measurement and validation steps. By doing so, we have maximized the reusability of the Compliance Quanta (measurements and validations), while minimizing what needs to be uniquely managed by each development team (custom measurements).
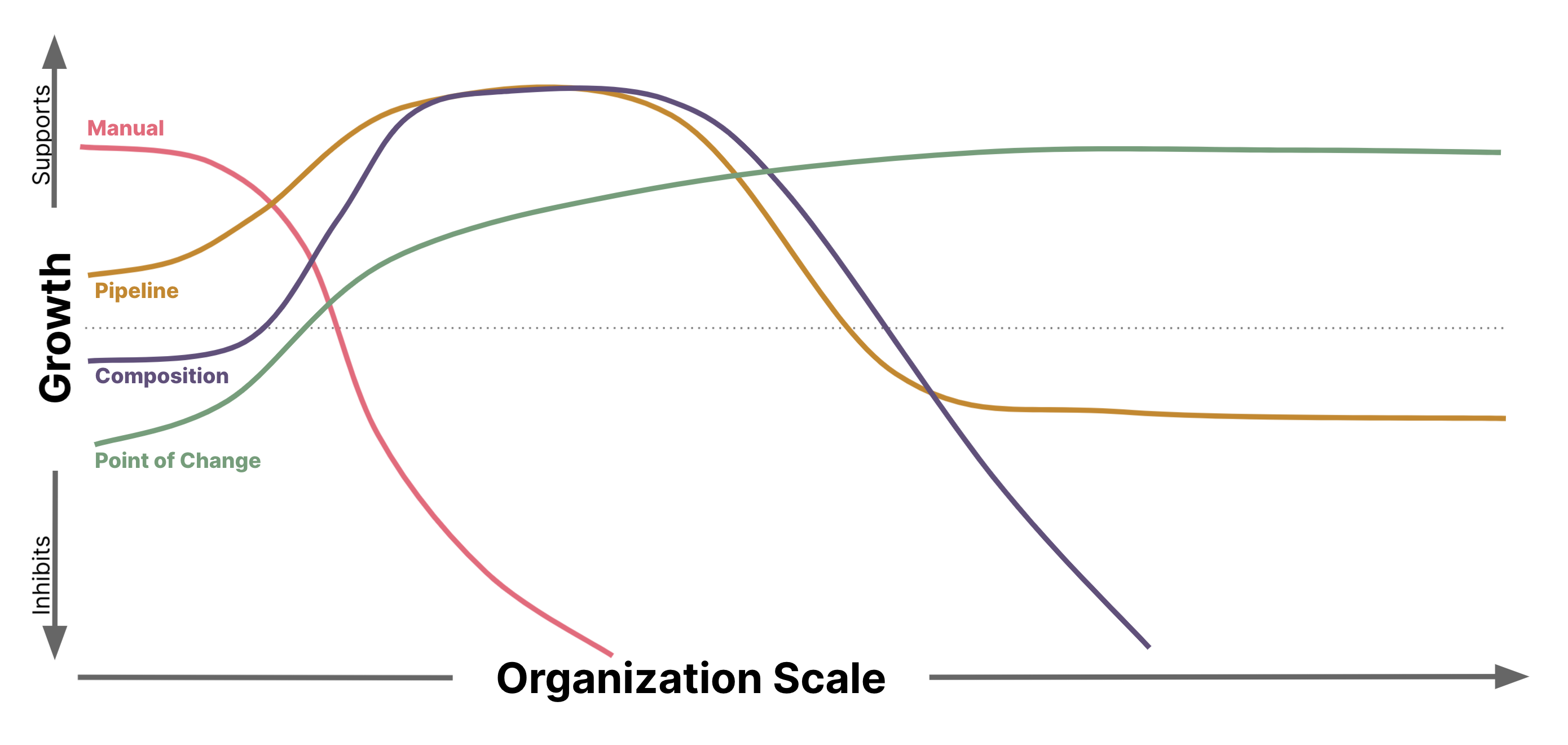
Each solution progressively shrinks the unique work that is necessary for validating Compliance by shrinking the scope of the Architectural and Compliance Quanta necessary for each process. As the unique work is minimized, so too are the second order effects reduced. In addition, new capabilities emerge as a result of the reorganized domain bounds. In the process, we have returned ownership of the pipeline to the development team, while retaining economies of scale wherever appropriate.
Within Digital Platform Strategy engagements at Thoughtworks, we pay close attention to sources of developer friction. Across the wide variety of changes we introduce to a client, the acceleration factor of returning pipeline ownership to development teams is consistently in the top three value-returning investments the engineering organization can make.
Conclusion
As in all architectural decisions, it's more about evaluating the tradeoffs than finding the perfect solution. The conclusions drawn after evaluating the costs and benefits will be different for each organization, depending on the type of work being done, the size and scale of the organization, and the complexity of the solutions being delivered to the customer.
However, from an architectural perspective, if you adopt a fundamental separation of concerns in your Compliance architecture, you can position your solution to have the best chance of evolving to meet the needs of your organization. You have the freedom to bundle the measurement with the validation to create Fitness Functions in a pipeline if tight coupling makes sense based on your organization. And when your organization has achieved a certain scale, these principles enable the organization to refactor the Compliance solution in order to achieve the loose coupling that promotes team efficiency at scale.
Footnotes
1: See chapter 2 of Building Evolutionary Architectures
2: See Chapter 7 of Accelerate
3: In her discussion, she notes that Architectural Quantum originally came from Building Evolutionary Architecture
Acknowledgements
This article benefits enormously from the comments, suggestions, and constructive criticism from many colleagues. My thanks to Tim Cochran, Martin Fowler, Neal Ford, Nic Cheneweth, Dan Kunnath, Kief Morris, Ranbir Chawla, Brandon Byars, Andrew Buchanan, Jim Gumbley, Patrick McFadden, and Shree Damani.
Significant Revisions
02 November 2021: published