
Maximizing Developer Effectiveness
Technology is constantly becoming smarter and more powerful. I often observe that as these technologies are introduced an organization’s productivity instead of improving has reduced. This is because the technology has increased complexities and cognitive overhead to the developer, reducing their effectiveness. In this article, the first of a series, I introduce a framework for maximizing developer effectiveness. Through research I have identified key developer feedback loops, including micro-feedback loops that developers do 200 times a day. These should be optimized so they are quick, simple and impactful for developers. I will examine how some organizations have used these feedback loops to improve overall effectiveness and productivity.
26 January 2021

Tim Cochran is a Technical Director for the US East Market at Thoughtworks. Tim has over 19 years of experience leading work across start-ups and large enterprises in various domains such as retail, financial services, and government. He advises organizations on technology strategy and making the right technology investments to enable digital transformation goals. He is a vocal advocate for the developer experience and passionate about using data-driven approaches to improve it.
I often help engineering organizations that are in the midst of a transformation. This is typically both a technology transformation and a cultural transformation. For example, these organizations might be attempting to break a core monolithic system into microservices, so that they can have independent teams and adopt a DevOps approach. They also might want to improve their agile and product techniques to respond faster to feedback and signals in the market.
Over and over, these efforts have failed at some point in the transformation journey. Managers are unhappy with delays and budget overruns, while technologists struggle to resolve roadblocks from every direction. Productivity is too low. The teams are paralyzed with a myriad of dependencies, cognitive overload, and a lack of knowledge in the new tools/processes. The promises that were made to executive leadership about the latest technology are not coming to fruition quickly enough.
There is a stark contrast of approach between companies that have high and low developer effectiveness
When we look into these scenarios, a primary reason for the problems is that the engineering organization has neglected to provide developers with an effective working environment. While transforming, they have introduced too many new processes, too many new tools and new technologies, which has led to increased complexity and added friction in their everyday tasks.
I work with various types of companies. These could be enterprises which are just at the beginning of their digital transformation or are halfway there, and companies which have adopted a DevOps culture culture from the very beginning. I have found there is a stark contrast of approach between companies that have high and low developer effectiveness.
The easiest way to explain is via a developer day in the life:
Day in the life in a highly effective environment
The developer:
- checks the team project management tool and then attends standup where she is clear about what she has to work on.
- notes that the development environment has been automatically updated with libraries matching development and production, and the CI/CD pipelines are green.
- pulls down the latest code, makes an incremental code change that is quickly validated by deploying to a local environment and by running unit tests.
- depends on another team’s business capabilities for her feature. She is able to find documentation and the API spec through a developer portal. She still has some queries, so she jumps into the team’s Slack room and quickly gets some help from another developer who is doing support.
- focuses on her task for a few hours without any interruptions.
- takes a break, gets coffee, takes a walk, plays some ping pong with colleagues.
- commits the code change, which then passes through a number of automated checks before being deployed to production. Releases the change gradually to users in production, while monitoring business and operational metrics.
The developer is able to make incremental progress in a day, and goes home happy.
Day in the life in a low effective environment
The developer:
- starts the day having to deal immediately with a number of alerts for problems in production.
- checks a number of logging and monitoring systems to find the error report as there are no aggregated logs across systems.
- works with operations on the phone and determines that the alerts are false positives.
- has to wait for a response from architecture, security and governance groups for a previous feature she had completed.
- has a day broken up with many meetings, many of which are status meetings
- notes that a previous feature has been approved by reviewers, she moves it into another branch that kicks off a long nightly E2E test suite that is almost always red, managed by a siloed QA team.
- depends on another team's API, but she cannot find current documentation. So instead she talks to a project manager on the other team, trying to get a query. The ticket to find an answer will take a few days, so this is blocking her current task.
We could go on. But ultimately the developer doesn’t achieve much, leaves frustrated and unmotivated
Developer effectiveness
What does being effective mean? As a developer, it is delivering the maximum value to your customers. It is being able to apply your energy and innovation in the best ways towards the company’s goals. An effective environment makes it easy to put useful, high-quality software into production; and to operate it so that the developers do not have to deal with unnecessary complexities, frivolous churn or long delays — freeing them to concentrate on value-adding tasks.
In the example illustrating a low effective environment, everything takes longer than it should. As a developer, your day is made up of endless blockers and bureaucracy. It is not just one thing; it is many. This is akin to death by a 1,000 cuts. Slowly, productivity is destroyed by small inefficiencies, which have compounding effects. The feeling of inefficiency spreads throughout the organization beyond just engineering. Engineers end up feeling helpless; they are unproductive. And worse they accept it, the way of working becomes an accepted routine defining how development is done. The developers experience a learned helplessness.
Whereas in the organization that provides a highly effective environment, there is a feeling of momentum; everything is easy and efficient, and developers encounter little friction. They spend more time creating value. It is this frictionless environment, and the culture that supports it by fostering the desire and ability to constantly improve, that is the hardest thing for companies to create when they are doing a digital transformation.
Being productive motivates developers. Without the friction, they have time to think creatively and apply themselves
Organizations look for ways to measure developer productivity. The common anti-pattern is to look at lines of code, feature output or to put too much focus on trying to spot the underperforming developers. It is better to turn the conversation around to focus on how the organization is providing an effective engineering environment. Being productive motivates developers. Without the friction, they have time to think creatively and apply themselves. If organizations do not do this, then in my experience the best engineers will leave. There is no reason for a developer to work in an ineffective environment when lots of great innovative digital companies are looking to hire strong technical talent.
Let's look at an example of a company that has optimized developer effectiveness.
Case Study: Spotify
Spotify conducted user research among their engineers to better understand developer effectiveness. Through this research, they uncovered two key findings:
- Fragmentation in the internal tooling. Spotify’s internal infrastructure and tooling was built as small isolated “islands” leading to context switching and cognitive load for engineers.
- Poor discoverability. Spotify had no central place to find technical information. As information was spread all over, engineers did not even know where to start looking for information.
Spotify's developer experience team describes these problems as a negative flywheel; a vicious cycle where developers are presented with too many unknowns, forcing them to make many decisions in isolation, which in turn compounds fragmentation and duplication of efforts, and ultimately erodes the end-to-end delivery time of products.
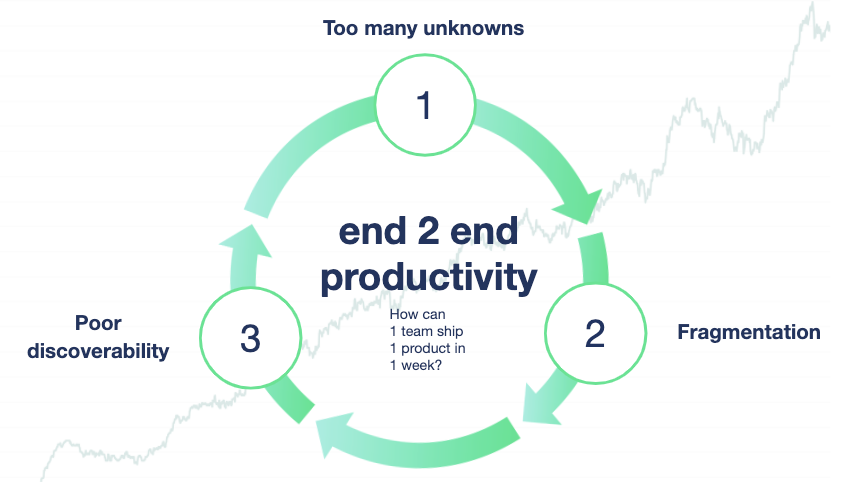
Figure 1: Spotify's negative flywheel
To mitigate these complexities, they developed Backstage, an Open Source developer portal with a plugin architecture to help expose all infrastructure products in one place, offering a coherent developer experience and a starting point for engineers to find the information they need.
How to get started?
What I am describing in the highly effective environment is what it feels like to work in a company that has fully embraced a DevOps culture, continuous delivery and product thinking. Very sensibly, most companies are on a journey towards achieving this environment. They have read Accelerate and the State of DevOps report. They know what type of organization they are striving to build. The four key metrics (lead time, deployment frequency, MTTR and change fail percentage) are great measures of DevOps performance.
One way to look at the DevOps measures is that they are lagging indicators. They are useful measurements to understand where you are, and to indicate when there is work to be done to figure out what tangible things the company should do to get better. Ideally, we want to identify leading lower level metrics of effectiveness that are more actionable. There is a correlation to the higher level metrics. It will ladder up. This should also be combined with other sources of research such as surveys on developer satisfaction.
There is an overwhelming amount of good advice, practices, tools, and processes that you should use to improve. It is very hard to know what to do. My research has shown that there are a number of key developer feedback loops. I recommend focusing on optimizing these loops, making them fast and simple. Measure the length of the feedback loop, the constraints, and the resulting outcome. When new tools and techniques are introduced, these metrics can clearly show the degree to which developer effectiveness is improved or at least isn't worse.
Feedback Loops
The key loops I have identified are:
| Feedback Loop | Low Effectiveness | High Effectiveness |
|---|---|---|
| Validate a local code change works | 2 mins | 5-15 seconds (depending on tech choice) |
| Find root cause for defect | 4-7 days | 1 day |
| Validate component integrates with other components | 3 days - 2 weeks | 2 hours |
| Validate a change meets non-functional requirements | 3 months | 1 day - 1 week (depending on scope of change) |
| Become productive on new team | 2 months | 4 weeks |
| Get answers to an internal technical query | 1-2 weeks | 30 mins |
| Launch a new service in production | 2-4 months | 3 days |
| Validate a change was useful to the customer | 6 months or never | 1 - 4 weeks (depending on scope of change) |
The metrics are based on what I have observed is possible. Not every company needs every feedback loop to be in the high effectiveness bucket, but they provide concrete goals to guide decision-making. Engineering organizations should conduct research within their specific context to figure out what cycles and metrics are important technology strategy.
It is useful to look at what techniques have been applied to optimize the feedback loops and the journey that companies have taken to get there. Those case studies can provide many ideas to apply in your own organization.
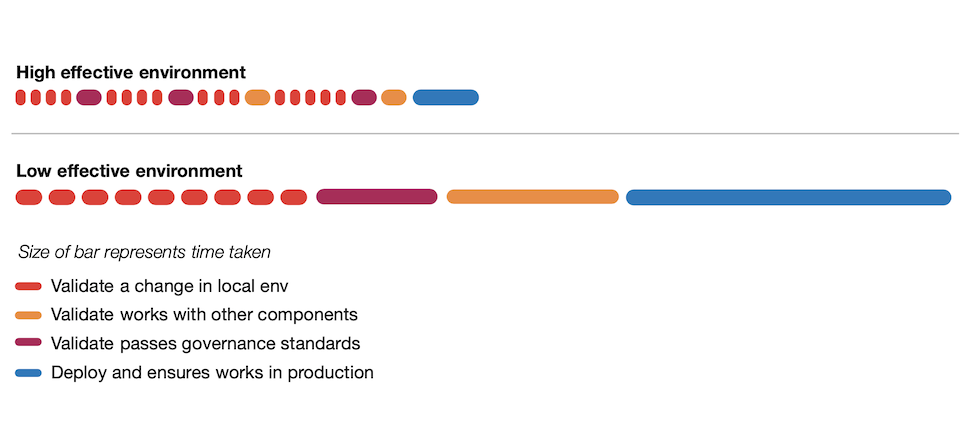
Figure 2: Feedback Loops during feature development
The diagram above shows a simplified representation of how developers use feedback loops during development. You can see that the developer validates their work is meeting the specifications and expected standards at multiple points along the way. The key observations to note are:
- Developers will run the feedback loops more often if they are shorter.
- Developers will run more often and take action on the result, if they are seen as valuable to the developer and not purely bureaucratic overhead.
- Getting validation earlier and more often reduces the rework later on.
- Feedback loops that are simple to interpret results, reduce back and forth communications and cognitive overhead.
When organizations fail to achieve these results, the problems are quickly compounded. There is a great deal of wasted effort for the developers. Embodied in the time spent waiting, searching, or trying to understand results. It adds up, causing significant delays in product development, which will manifest as lower scores in the four key metrics (particularly deployment frequency and lead time).
Introducing micro feedback loops
From what I have observed, you have to nail the basics, the things that developers do 10, 100 or 200 times a day. I call them micro-feedback loops. This could be running a unit test while fixing a bug. It could be seeing a code change reflected in your local environment or development environments. It could be refreshing data in your environment. Developers, if empowered, will naturally optimize, but often I find the micro-feedback loops have been neglected. These loops are intentionally short, so you end up dealing with some very small time increments.
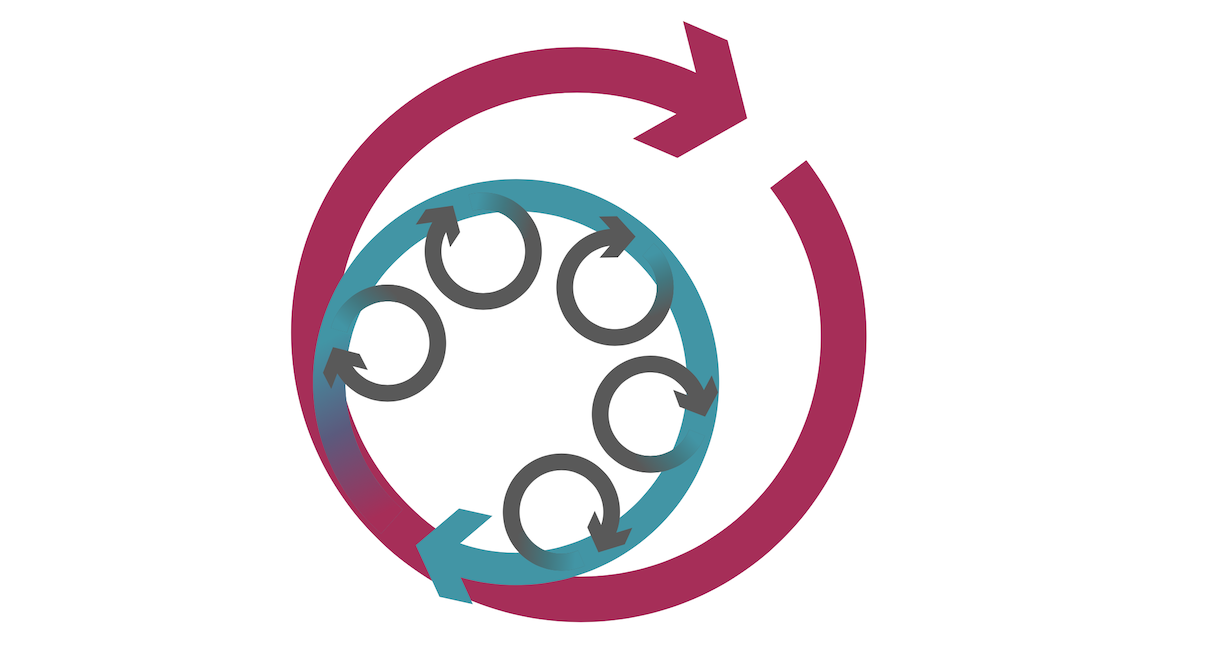
Figure 3: Micro-feedback loops compound to affect larger feedback loops.
It is hard to explain to management why we have to focus on such small problems. Why do we have to invest time to optimize a compile stage with a two minute runtime to instead take only 15 seconds? This might be a lot of work, perhaps requiring a system to be decoupled into independent components. It is much easier to understand optimizing something that is taking two days as something worth taking on.
Those two minutes can add up quickly, and could top 100 minutes a day. These small pauses are opportunities to lose context and focus. They are long enough for a developer to get distracted, decide to open an email or go and get a coffee, so that now they are distracted and out of their state of flow, there is research that indicates it can take up to 23 minutes to get back into the state of flow and return to high productivity. I am not suggesting that engineers should not take breaks and clear their head occasionally! But they should do that intentionally, not enforced by the environment.
In reality, developers will compensate by filling these moments of inactivity with useful things. They might have two tasks going on and toggle between them. They might slow their compile frequency by batching up changes. In my research both of these will lead to a delay in integration of code, and development time.
How far do you take optimizing? When is enough? Imagine that now we have that change down to 15 seconds, but we think we can get it to three seconds. Is that worth the investment? It depends on how difficult it is to make that change and the impact it will bring. If you can develop a tool or capability that will speed up 10 teams then it might be worth it. This is where platform thinking, rather than optimizing for individual teams, comes into play.
Distributed systems are a particular challenge. There are many valid reasons for splitting systems into different deployable units (usually microservices). However, distributed systems also make many things difficult (see Microservice Prerequisites), including developer effectiveness. Sometimes teams might optimize for team autonomy or for runtime performance, but they sacrifice developer effectiveness because they do not invest in maintaining fast feedback loops. This is a very common situation my company runs into.
Organizational Effectiveness
Highly effective organizations have designed their engineering organization to optimize for effectiveness and feedback loops. Leadership over time creates a culture that leads to empowering developers to make incremental improvements to these feedback loops.
It starts with a recognition by leadership that technology — and removing friction from development teams — is vital to the business.
It starts with a recognition by leadership that technology — and removing friction from development teams — is vital to the business. This is manifested in a number of ways.
Technical leaders continually measure and re-examine effectiveness. Highly effective organizations have created a framework to make data-driven decisions by tracking the four key metrics and other data points important to their context. This culture starts at the executive level and is communicated to the rest of the organization.
In addition to the metrics, they create an open forum to listen to the individual contributors that work in the environment day to day. Developers will know the problems they face and will have many ideas on how to solve them.
Based on this information, engineering managers can decide on priorities for investments. Large problems may require correspondingly large programs of modernization to address a poor developer experience. But often it is more about empowering teams to make continuous improvement.
A key principle is to embrace the developer experience. It is common to see a program of work of a team focused on this. Developer experience means technical capabilities should be built with the same approaches used for end-user product development, applying the same research, prioritization, outcome-based thinking, and consumer feedback mechanisms.
To motivate developers, highly effective organizations franchise; that means developers should have the ability to improve their day to day lives. They have a policy for teams to make incremental technical improvements and manage technical debt. There should be a healthy data-backed discussion between developers and product management. Highly effective organizations also provide the ability for developers to innovate; when their teams have clear goals and a clear idea of bottlenecks, developers can be creative in solving problems. These organizations also create ways for the best ideas to “bubble to the top”, and then double down, using data to evaluate what is best.
After commitment, measurement and empowerment comes scaling.
At a certain organizational size, there is a need to create efficiency through economies of scale. Organizations do this by applying platform thinking - creating an internal platform specifically focused on improving effectiveness. They invest in engineering teams that build technical capabilities to improve developer effectiveness. They regard other development teams as their consumers, and the services they provide are treated like products. The teams have technical product managers and success metrics related to how they are impacting the consuming teams. For example, a platform capability team focused on observability creates monitoring, logging, alerting, and tracing capabilities so that teams can easily monitor their service health and debug problems in their product.
The need for governance is still a priority. However, this does not need to be seen as a dirty word since its application is very different in highly effective organizations. They move away from centralized processes to a lightweight approach. This is about setting and communicating the guardrails, and then nudging teams in the right direction rather than lengthy approval process approaches. Governance can have a critical role in effectiveness when it is implemented via:
- Clear engineering goals
- Specifying ways that teams and services communicate with each other
- Encouraging useful peer review
- Baking best practices into platform capabilities
- Automating control via architecture fitness functions
Essentially, effective organizations shorten the governance feedback loop. I will be expanding on this in a future article.
Case Study: Etsy
Etsy was one of the pioneers of the DevOps movement. Its leaders have worked to embed developer effectiveness into their culture, with the belief that moving quickly is both a technical and a business strategy. They actively measure their ability to put valuable products into production quickly and safely, and will adjust their technical investments to fix any blockers or slowness.
One of Etsy’s key metrics is lead time, which is measured, monitored, and displayed in real-time throughout their offices. When lead time reaches above a certain key threshold, the release engineering team will work to lower it to a reasonable level. Their CTO, Mike Fisher, talks about Etsy engineers being “fearless” to move forward quickly, having a safety net to try new things.
Deploying software fast is only half of the story. To be truly effective that software has to be valuable to consumers. Etsy does this by taking a data-driven approach, with each feature having measurable KPIs.
Code changes go through a set of checks, so that developers have confidence the change meets Etsy’s SLAs for performance, availability, failure rate, etc. Once the change is in production, Etsy’s experimentation platform is able to capture user behavior metrics. Teams use the metrics to iterate on products, optimizing for the associated KPIs and user satisfaction. If eventually the change is proven not to be valuable, it would be cleaned up, thereby avoiding technical debt.
Etsy has a current initiative that prioritizes the developer experience. It has four key pillars:
4 Pillars of Developer Experience
Help me craft products ensures we have the right abstractions, libraries, and scaffolding for product engineers to do their work.
Help me develop, test, and deploy focuses on product engineers, specifically the development environments themselves (IDEs, linters), unit/integration test patterns/runners, and the deployment tooling and processes.
Help me build with data focuses on data scientists and machine learning engineers, making sure the entire data engineering ecosystem is set up in a way that is intuitive, easy to test, and easy to deploy.
Help me reduce toil focuses on the on-call engineers, to make sure we build production systems with the appropriate levels of automation, have runbooks and documentation that is easily accessible and current, and we track and prioritize reducing toil-y activities.
![]()
This policy represents a true commitment from Etsy’s leadership to their developers. They continually verify their effectiveness by tracking metrics including the 4 key metrics, and conducting monthly surveys with developers to capture net promoter scores (NPS).
Conclusion
The beginning of this article speaks to the importance of developer effectiveness and its impact on developer happiness and productivity. I focused on the outcomes developers aim to achieve and not just the tools and techniques. In pushing this examination further we see a series of feedback loops that developers often use while developing a product.
I also spoke to how inefficiencies in micro-feedback loops compound to affect larger indicators such the four key metrics and product development speed. As well as highlighted the importance of developer experience as a principal and how platform thinking will help maximize efficiency and effectiveness at scale.
In the coming series, a deeper dive into developer effectiveness and the individual feedback loops will be further explained through case studies. These will provide concrete details in how organizations have been able to achieve these numbers and the resulting outcomes. In addition to describing the organizational structures and processes that enable these optimizations at a local and a global level.
The next article will start with the smallest micro-feedback loops.
Acknowledgements
Thanks to Pia Nilsson at Spotify and Keyur Govande at Etsy for collaborating on case studies about their work.
Many thanks to Martin Fowler for his support.
Thanks to the ThoughtWorkers whose amazing work this article references.
Thanks to my colleagues Cassie Shum and Carl Nygard for their feedback and help with research. This article wouldn’t have been possible without Ryan Murray’s ideas about platforms thinking.
Thanks to Mike McCormack and Gareth Morgan for editorial review.
Significant Revisions
26 January 2021: Published organizational effectiveness and Etsy case study
06 January 2021: Published thru Introudcuing micro feedback loops
05 January 2021: Published first installment (thru Spotify case study)