
How to Move Beyond a Monolithic Data Lake to a Distributed Data Mesh
Many enterprises are investing in their next generation data lake, with the hope of democratizing data at scale to provide business insights and ultimately make automated intelligent decisions. Data platforms based on the data lake architecture have common failure modes that lead to unfulfilled promises at scale. To address these failure modes we need to shift from the centralized paradigm of a lake, or its predecessor data warehouse. We need to shift to a paradigm that draws from modern distributed architecture: considering domains as the first class concern, applying platform thinking to create self-serve data infrastructure, and treating data as a product.
20 May 2019

Zhamak is a principal technology consultant at Thoughtworks with a focus on distributed systems architecture and digital platform strategy at Enterprise. She is a member of Thoughtworks Technology Advisory Board and contributes to the creation of Thoughtworks Technology Radar.
Becoming a data-driven organization remains one of the top strategic goals of many companies I work with. My clients are well aware of the benefits of becoming intelligently empowered: providing the best customer experience based on data and hyper-personalization; reducing operational costs and time through data-driven optimizations; and giving employees super powers with trend analysis and business intelligence. They have been investing heavily in building enablers such as data and intelligence platforms. Despite increasing effort and investment in building such enabling platforms, the organizations find the results middling.

For more on Data Mesh, Zhamak went on to write a full book that covers more details on strategy, implementation, and organizational design.
I agree that organizations face a multi-faceted complexity in transforming to become data-driven; migrating from decades of legacy systems, resistance of legacy culture to rely on data, and ever competing business priorities. However what I would like to share with you is an architectural perspective that underpins the failure of many data platform initiatives. I demonstrate how we can adapt and apply the learnings of the past decade in building distributed architectures at scale, to the domain of data; and I will introduce a new enterprise data architecture that I call data mesh.
My ask before reading on is to momentarily suspend the deep assumptions and biases that the current paradigm of traditional data platform architecture has established; Be open to the possibility of moving beyond the monolithic and centralized data lakes to an intentionally distributed data mesh architecture; Embrace the reality of ever present, ubiquitous and distributed nature of data.
The current enterprise data platform architecture
It is centralized, monolithic and domain agnostic aka data lake.
Almost every client I work with is either planning or building their 3rd generation data and intelligence platform, while admitting the failures of the past generations:
- The first generation: proprietary enterprise data warehouse and business intelligence platforms; solutions with large price tags that have left companies with equally large amounts of technical debt; Technical debt in thousands of unmaintainable ETL jobs, tables and reports that only a small group of specialized people understand, resulting in an under-realized positive impact on the business.
- The second generation: big data ecosystem with a data lake as a silver bullet; complex big data ecosystem and long running batch jobs operated by a central team of hyper-specialized data engineers have created data lake monsters that at best has enabled pockets of R&D analytics; over promised and under realized.
The third and current generation data platforms are more or less similar to the previous generation, with a modern twist towards (a) streaming for real-time data availability with architectures such as Kappa, (b) unifying the batch and stream processing for data transformation with frameworks such as Apache Beam, as well as (c) fully embracing cloud based managed services for storage, data pipeline execution engines and machine learning platforms. It is evident that the third generation data platform is addressing some of the gaps of the previous generations such as real-time data analytics, as well as reducing the cost of managing big data infrastructure. However it suffers from many of the underlying characteristics that led to the failures of the previous generations.
Architectural failure modes
To unpack the underlying limitations that all generations of data platforms carry, let's look at their architecture and their characteristics. In this writeup I use the domain of internet media streaming business such as Spotify, SoundCloud, Apple iTunes, etc. as the example to clarify some of the concepts.
Centralized and monolithic
At 30,000 feet the data platform architecture looks like Figure 1 below; a centralized piece of architecture whose goal is to:
- Ingest data from all corners of the enterprise, ranging from operational and transactional systems and domains that run the business, or external data providers that augment the knowledge of the enterprise. For example in a media streaming business, data platform is responsible for ingesting large variety of data: the 'media players performance', how their 'users interact with the players', 'songs they play', 'artists they follow', as well as 'labels and artists' that the business has onboarded, the 'financial transactions' with the artists, and external market research data such as 'customer demographic' information.
- Cleanse, enrich, and transform the source data into trustworthy data that can address the needs of a diverse set of consumers. In our example, one of the transformations turns the click streams of user interaction to meaningful sessions enriched with details of the user. This attempts to reconstruct the journey and behavior of the user into aggregate views.
- Serve the datasets to a variety of consumers with a diverse set of needs. This ranges from analytical consumption to exploring the data looking for insights, machine learning based decision making, to business intelligence reports that summarize the performance of the business. In our media streaming example, the platform can serve near real-time error and quality information about the media players around the globe through distributed log interfaces such as Kafka or serve the static aggregate views of a particular artist's records being played to drive financial payments calculation to the artists and labels.
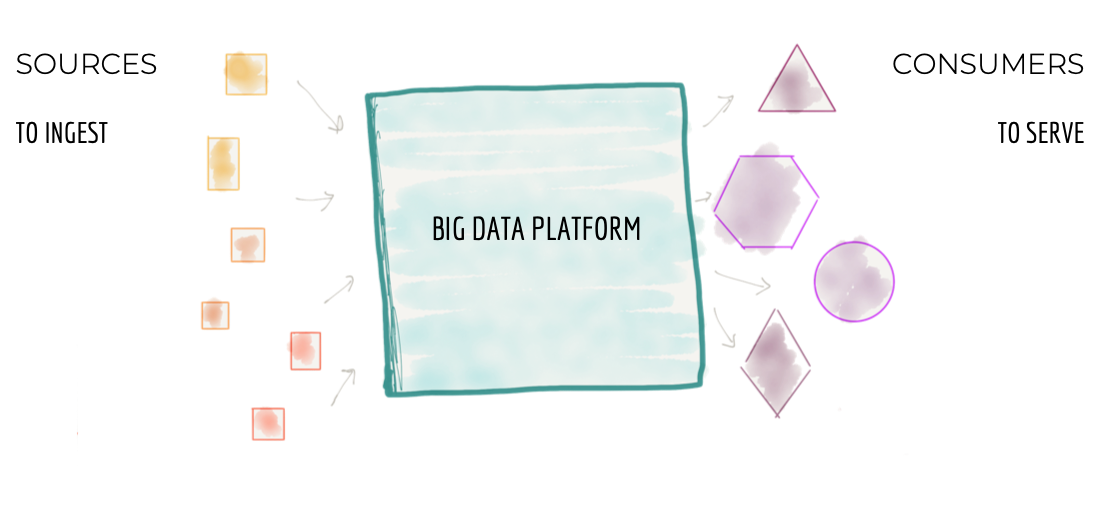
Figure 1: The 30,000 ft view of the monolithic data platform
It's an accepted convention that the monolithic data platform hosts and owns the data that logically belong to different domains, e.g. 'play events', 'sales KPIs', 'artists', 'albums', 'labels', 'audio', 'podcasts', 'music events', etc.; data from a large number of disparate domains.
While over the last decade we have successfully applied domain driven design and bounded context to our operational systems, we have largely disregarded the domain concepts in a data platform. We have moved away from domain oriented data ownership to a centralized domain agnostic data ownership. We pride ourselves on creating the biggest monolith of them all, the big data platform.
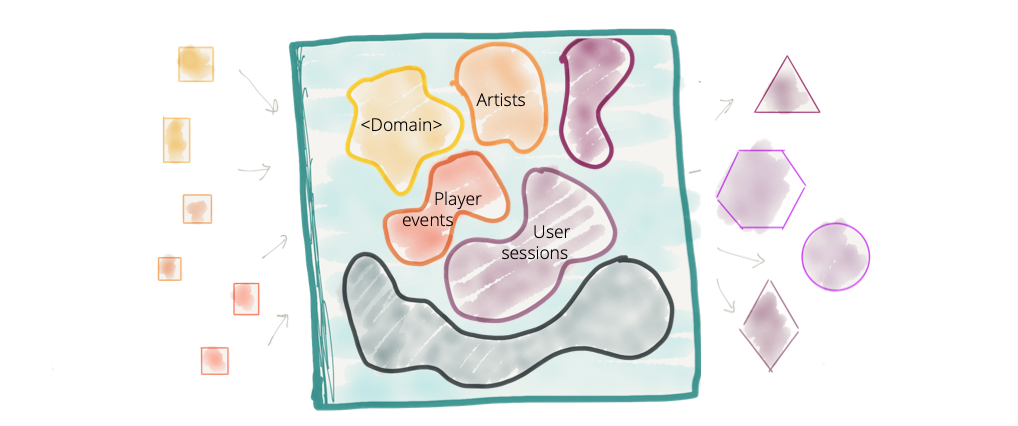
Figure 2: Centralized data platform with no clear data domain boundaries and ownership of domain oriented data
While this centralized model can work for organizations that have a simpler domain with smaller number of diverse consumption cases, it fails for enterprises with rich domains, a large number of sources and a diverse set of consumers.
There are two pressure points on the architecture and the organizational structure of a centralized data platform that often lead to its failure:
- Ubiquitous data and source proliferation: As more data becomes ubiquitously available, the ability to consume it all and harmonize it in one place under the control of one platform diminishes. Imagine just in the domain of 'customer information', there are an increasing number of sources inside and outside of the boundaries of the organization that provide information about the existing and potential customers. The assumption that we need to ingest and store the data in one place to get value from a diverse set of sources is going to constrain our ability to respond to proliferation of data sources. I recognize the need for data users such as data scientists and analysts to process a diverse set of datasets with low overhead, as well as the need to separate the operational systems data usage from the data that is consumed for analytical purposes. But I propose that the existing centralized solution is not the optimal answer for large enterprises with rich domains and continuously added new sources.
- Organizations' innovation agenda and consumer proliferation: Organizations' need for rapid experimentation introduces a larger number of use cases for consumption of the data from the platform. This implies an ever growing number of transformations on the data - aggregates, projections and slices that can satisfy the test and learn cycle of innovation. The long response time to satisfy the data consumer needs has historically been a point of organizational friction and remains to be so in the modern data platform architecture.
While I don't want to give my solution away just yet, I need to clarify that I'm not advocating for a fragmented, siloed domain-oriented data often hidden in the bowels of operational systems; siloed domain data that is hard to discover, make sense of and consume. I am not advocating for multiple fragmented data warehouses that are the results of years of accumulated tech debt. This is a concern that leaders in the industry have voiced. But I argue that the response to these accidental silos of unreachable data is not creating a centralized data platform, with a centralized team who owns and curates the data from all domains. It does not organizationally scale as we have learned and demonstrated above.
Coupled pipeline decomposition
The second failure mode of a traditional data platform architecture is related to how we decompose the architecture. At 10,000 feet zooming into the centralized data platform, what we find is an architectural decomposition around the mechanical functions of ingestion, cleansing, aggregation, serving, etc. Architects and technical leaders in organizations decompose an architecture in response to the growth of the platform. As described in the previous section, the need for on-boarding new sources, or responding to new consumers requires the platform to grow. Architects need to find a way to scale the system by breaking it down to its architectural quanta. An architectural quantum, as described in Building Evolutionary Architectures, is an independently deployable component with high functional cohesion, which includes all the structural elements required for the system to function properly. The motivation behind breaking a system down into its architectural quantum is to create independent teams who can each build and operate an architectural quantum. Parallelize work across these teams to reach higher operational scalability and velocity.
Given the influence of previous generations of data platforms' architecture, architects decompose the data platform to a pipeline of data processing stages. A pipeline that at a very high level implements a functional cohesion around the technical implementation of processing data; i.e. capabilities of ingestion, preparation, aggregation, serving, etc.
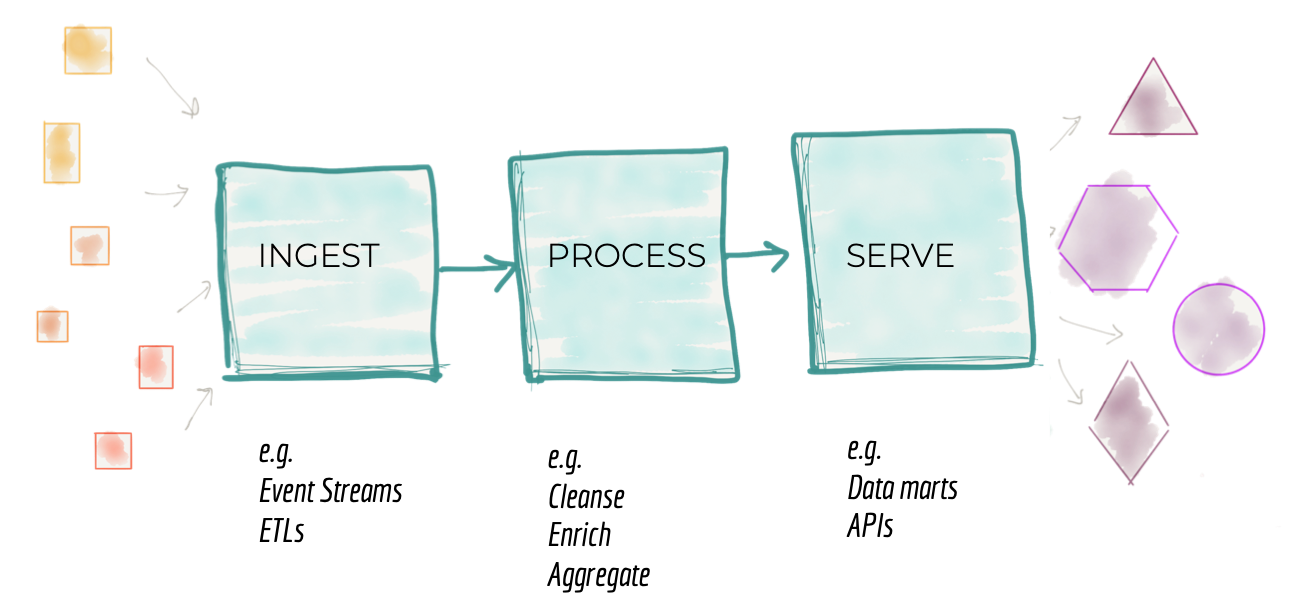
Figure 3: Architectural decomposition of data platform
Though this model provides some level of scale, by assigning teams to different stages of the pipeline, it has an inherent limitation that slows the delivery of features. It has high coupling between the stages of the pipeline to deliver an independent feature or value. It's decomposed orthogonally to the axis of change.
Let's look at our media streaming example. Internet media streaming platforms have a strong domain construct around the type of media that they offer. They often start their services with 'songs' and 'albums', and then extend to 'music events', 'podcasts', 'radio shows', 'movies', etc. Enabling a single new feature, such as visibility to the 'podcasts play rate', requires a change in all components of the pipeline. Teams must introduce new ingestion services, new cleansing and preparation as well as aggregates for viewing podcast play rates. This requires synchronization across implementation of different components and release management across teams. Many data platforms provide generic and configuration-based ingestion services that can cope with extensions such as adding new sources easily or modifying the existing sources to minimize the overhead of introducing new sources. However this does not remove an end to end dependency management of introducing new datasets from the consumer point of view. Though on paper, the pipeline architecture might appear as if we have achieved an architectural quantum of a pipeline stage, in practice the whole pipeline i.e. the monolithic platform, is the smallest unit that must change to cater for a new functionality: unlocking a new dataset and making it available for new or existing consumption. This limits our ability to achieve higher velocity and scale in response to new consumers or sources of the data.
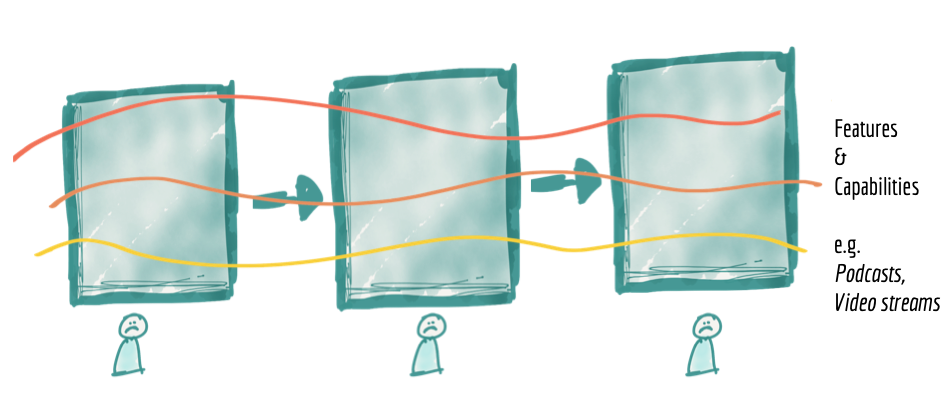
Figure 4: Architecture decomposition is orthogonal to the axis of change when introducing or enhancing features, leading to coupling and slower delivery
Siloed and hyper-specialized ownership
The third failure mode of today's data platforms is related to how we structure the teams who build and own the platform. When we zoom close enough to observe the life of the people who build and operate a data platform, what we find is a group of hyper-specialized data engineers siloed from the operational units of the organization; where the data originates or where it is used and put into actions and decision making. The data platform engineers are not only siloed organizationally but also separated and grouped into a team based on their technical expertise of big data tooling, often absent of business and domain knowledge.
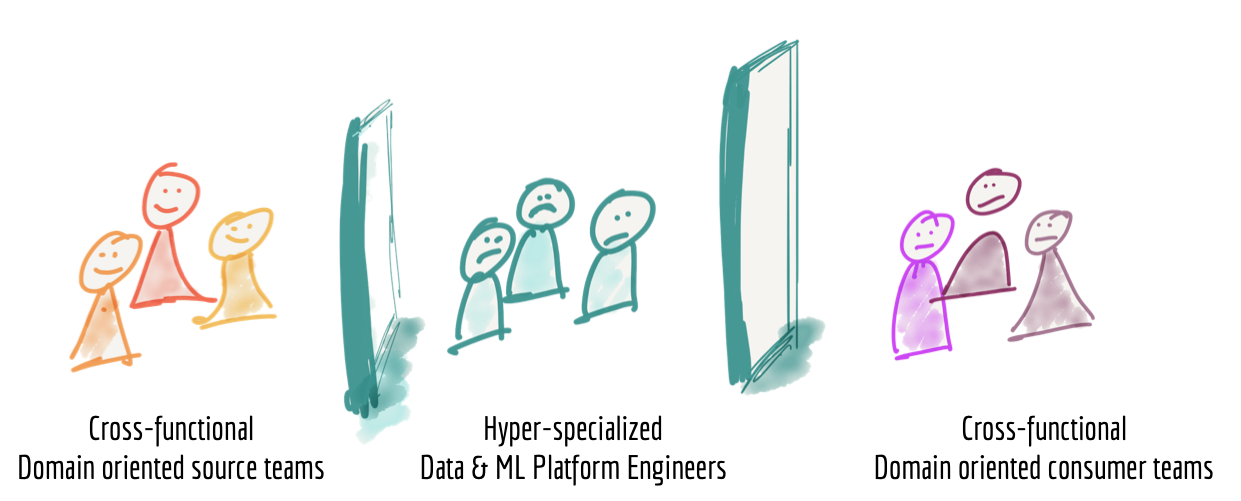
Figure 5: Siloed hyper-specialized data platform team
I personally don't envy the life of a data platform engineer. They need to consume data from teams who have no incentive in providing meaningful, truthful and correct data. They have very little understanding of the source domains that generate the data and lack the domain expertise in their teams. They need to provide data for a diverse set of needs, operational or analytical, without a clear understanding of the application of the data and access to the consuming domain's experts.
In the media streaming domain, for example, on the source end we have cross-functional 'media player' teams that provide signals around how users interact with a particular feature they provide e.g. 'play song events', 'purchase events', 'play audio quality', etc.; and on the other end sit the consumer cross-functional teams such as 'song recommendation' team, 'sales team' reporting sales KPIs, 'artists payment team' who calculate and pay artists based on play events, and so on. Sadly, in the middle sits the data platform team that through sheer effort provides suitable data for all sources and consumptions.
In reality what we find are disconnected source teams, frustrated consumers fighting for a spot on top of the data platform team backlog and an over stretched data platform team.
We have created an architecture and organization structure that does not scale and does not deliver the promised value of creating a data-driven organization.
The next enterprise data platform architecture
It embraces the ubiquitous data with a distributed Data Mesh.
So what is the answer to the failure modes and characteristics we discussed above? In my opinion a paradigm shift is necessary. A paradigm shift at the intersection of techniques that have been instrumental in building modern distributed architecture at scale; Techniques that the tech industry at large has adopted at an accelerated rate and that have created successful outcomes.
I suggest that the next enterprise data platform architecture is in the convergence of Distributed Domain Driven Architecture, Self-serve Platform Design, and Product Thinking with Data.

Figure 6: Convergence: the paradigm shift for building the next data platforms
Though this might sound like a lot of buzzwords in one sentence, each of these techniques have had a specific and incredibly positive impact in modernizing the technical foundations of operational systems. Lets deep dive into how we can apply each of these disciplines to the world of Data to escape the current paradigm, carried over from years of legacy data warehousing architecture.
Data and distributed domain driven architecture convergence
Domain oriented data decomposition and ownership
Eric Evans's book Domain-Driven Design has deeply influenced modern architectural thinking, and consequently the organizational modeling. It has influenced the microservices architecture by decomposing the systems into distributed services built around business domain capabilities. It has fundamentally changed how the teams form, so that a team can independently and autonomously own a domain capability.
Though we have adopted domain oriented decomposition and ownership when implementing operational capabilities, curiously we have disregarded the notion of business domains when it comes to data. The closest application of DDD in data platform architecture is for source operational systems to emit their business Domain Events and for the monolithic data platform to ingest them. However beyond the point of ingestion the concept of domains and the ownership of the domain data by different teams is lost.
Domain Bounded Context is a wonderfully powerful tool to design the ownership of the datasets. Ben Stopford's Data Dichotomy article unpacks the concept of sharing of domain datasets through streams.
In order to decentralize the monolithic data platform, we need to reverse how we think about data, its locality and ownership. Instead of flowing the data from domains into a centrally owned data lake or platform, domains need to host and serve their domain datasets in an easily consumable way.
In our example, instead of imagining data flowing from media players into some sort of centralized place for a centralized team to receive, why not imagine a player domain owning and serving their datasets for access by any team for any purpose downstream. The physical location where the datasets actually reside and how they flow, is a technical implementation of the 'player domain'. The physical storage could certainly be a centralized infrastructure such as Amazon S3 buckets but player datasets content and ownership remains with the domain generating them. Similarly in our example, the 'recommendations' domain creates datasets in a format that is suitable for its application, such as a graph database, while consuming the player datasets. If there are other domains such as 'new artist discovery domain' which find the 'recommendation domain' graph dataset useful, they can choose to pull and access that.
This implies that we may duplicate data in different domains as we transform them into a shape that is suitable for that particular domain, e.g. a time series play event to related artists graph.
This requires shifting our thinking from a push and ingest, traditionally through ETLs and more recently through event streams, to a serving and pull model across all domains.
The architectural quantum in a domain oriented data platform, is a domain and not the pipeline stage.
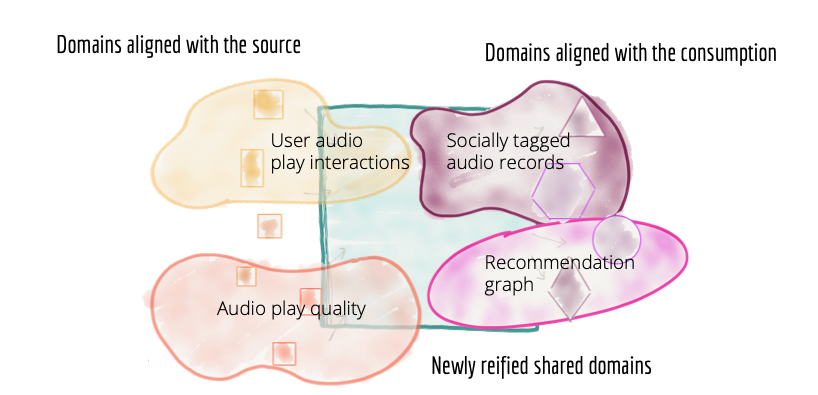
Figure 7: Decomposing the architecture and teams owning the data based on domains - source, consumer, and newly created shared domains
Source oriented domain data
Some domains naturally align with the source, where the data originates. The source domain datasets represent the facts and reality of the business. The source domain datasets capture the data that is mapped very closely to what the operational systems of their origin, systems of reality, generate. In our example facts of the business such as 'how the users are interacting with the services', or 'the process of onboarding labels' lead to creation of domain datasets such as 'user click streams', 'audio play quality stream' and 'onboarded labels'. These facts are best known and generated by the operational systems that sit at the point of origin. For example the media player system knows best about the 'user click streams'.
In a mature and ideal situation, an operational system and its team or organizational unit, are not only responsible for providing business capabilities but also responsible for providing the truths of their business domain as source domain datasets. At enterprise scale there is never a one to one mapping between a domain concept and a source system. There are often many systems that can serve parts of the data that belongs to a domain, some legacy and some easy to change. Hence there might be many source aligned datasets aka reality datasets that ultimately need to be aggregated to a cohesive domain aligned dataset.
The business facts are best presented as business Domain Events, can be stored and served as distributed logs of time-stamped events for any authorized consumer to access.
In addition to timed events, source data domains should also provide easily consumable historical snapshots of the source domain datasets, aggregated over a time interval that closely reflects the interval of change for their domain. For example in an 'onboarded labels' source domain, which shows the labels of the artists that provide music to the streaming business, aggregating the onboarded labels on a monthly basis is a reasonable view to provide in addition to the events generated through the process of onboarding labels.
Note that the source aligned domain datasets must be separated from the internal source systems' datasets. The nature of the domain datasets is very different from the internal data that the operational systems use to do their job. They have a much larger volume, represent immutable timed facts, and change less frequently than their systems. For this reason the actual underlying storage must be suitable for big data, and separate from the existing operational databases. Section Data and self-serve platform design convergence describes how to create big data storage and serving infrastructure.
Source domain datasets are the most foundational datasets and change less often, as the facts of business don't change that frequently. These domain datasets are expected to be permanently captured and made available, so that as the organization evolves its data-driven and intelligence services they can always go back to the business facts, and create new aggregations or projections.
Note that source domain datasets represent closely the raw data at the point of creation, and are not fitted or modeled for a particular consumer.
Distributed pipelines as domain internal implementation
While the datasets’ ownership is delegated from the central platform to the domains, the need for cleansing, preparing, aggregating and serving data remains, so does the usage of data pipeline. In this architecture, a data pipeline is simply an internal complexity and implementation of the data domain and is handled internally within the domain. As a result we will be seeing a distribution of the data pipelines stages into each domain.
For example the source domains need to include the cleansing, deduplicating, enriching of their domain events so that they can be consumed by other domains, without replication of cleansing. Each domain dataset must establish Service Level Objectives for the quality of the data it provides: timeliness, error rates, etc. For example our media player domain providing audio 'play clickstream' can include cleansing and standardizing data pipeline in their domain that provides a stream of de-duped near real-time 'play audio click events' that conform to the organization's standards of encoding events.
Equally, we will see that aggregation stages of a centralized pipeline move into implementation details of consuming domains.
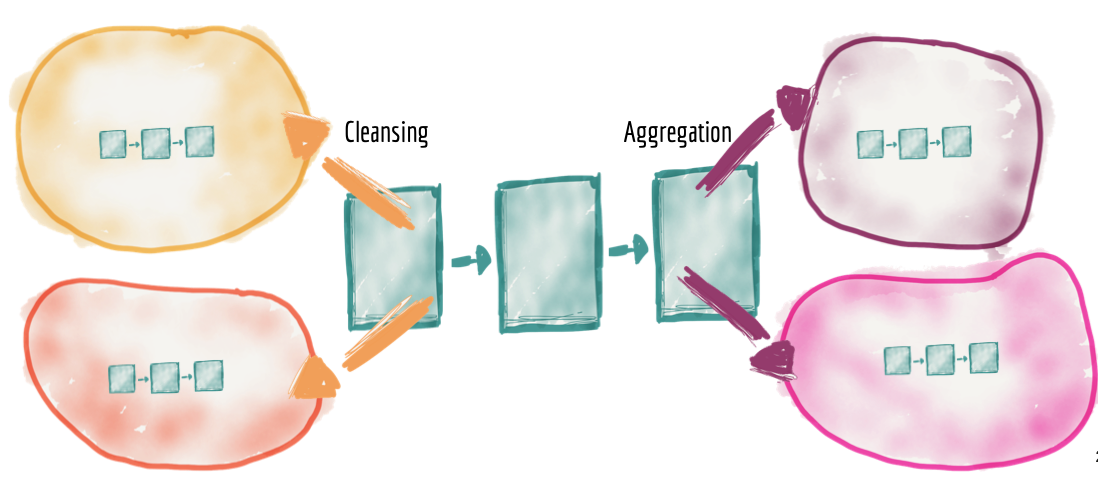
Figure 8: Distribute the pipelines into the domains as a second class concern and the domain's internal implementation detail
One might argue that this model might lead to duplicated effort in each domain to create their own data processing pipeline implementation, technology stack and tooling. I will address this concern shortly as we talk about the Convergence of Data and Platform Thinking with Self-serve shared Data Infrastructure as a Platform.
Data and product thinking convergence
Distribution of the data ownership and data pipeline implementation into the hands of the business domains raise an important concern around accessibility, usability and harmonization of distributed datasets. This is where the learning in applying product thinking and ownership of data assets come in handy.
Domain data as a product
Over the last decade operational domains have built product thinking into the capabilities they provide to the rest of the organization. Domain teams provide these capabilities as APIs to the rest of the developers in the organization, as building blocks of creating higher order value and functionality. The teams strive for creating the best developer experience for their domain APIs; including discoverable and understandable API documentation, API test sandboxes, and closely tracked quality and adoption KPIs.
For a distributed data platform to be successful, domain data teams must apply product thinking with similar rigor to the datasets that they provide; considering their data assets as their products and the rest of the organization's data scientists, ML and data engineers as their customers.
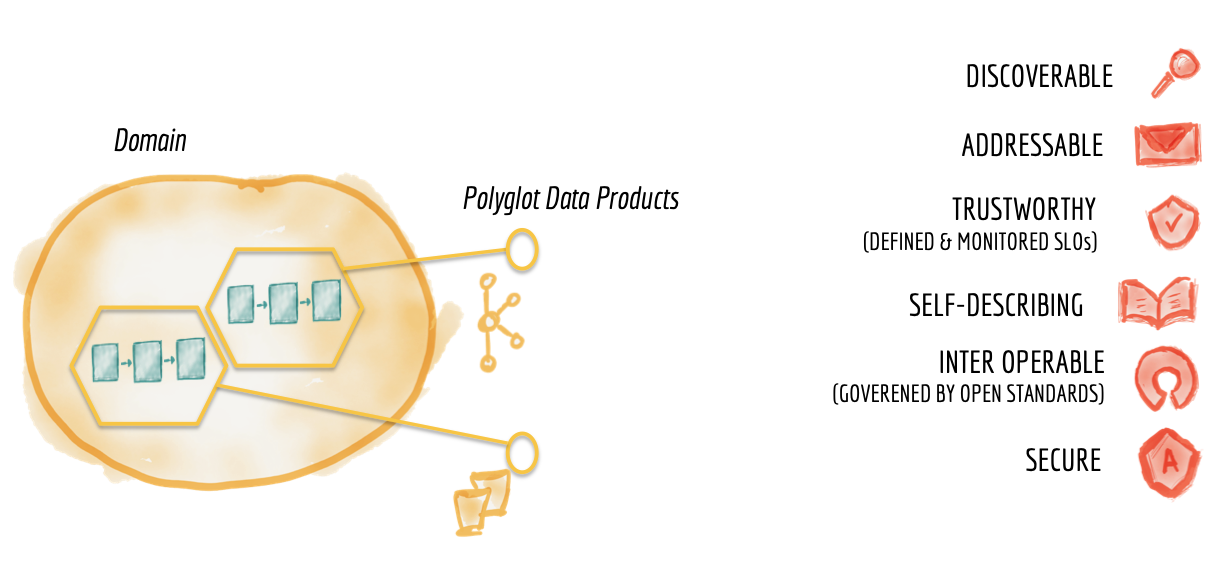
Figure 9: Characteristics of domain datasets as product
Consider our example, internet media streaming business. One of its critical domains is the 'play events', what songs have been played by whom, when and where. This key domain has different consumers in the organization; for example near real-time consumers that are interested in the experience of the user and possibly errors so that in case of a degraded customer experience or an incoming customer support call can respond quickly to recover the error. There are also a few consumers that would prefer the historical snapshots of the daily, or monthly song play event aggregates.
In this case our 'played songs' domain provides two different datasets as its products to the rest of the organization; real-time play events exposed on event streams, and aggregated play events exposed as serialized files on an object store.
An important quality of any technical product, in this case domain data products, is to delight their consumers; in this case data engineers, ML engineers or data scientists. To provide the best user experience for consumers, the domain data products need to have the following basic qualities:
Discoverable
A data product must be easily discoverable. A common implementation is to have a registry, a data catalogue, of all available data products with their meta information such as their owners, source of origin, lineage, sample datasets, etc. This centralized discoverability service allows data consumers, engineers and scientists in an organization, to find a dataset of their interest easily. Each domain data product must register itself with this centralized data catalogue for easy discoverability.
Note the perspective shift here is from a single platform extracting and owning the data for its use, to each domain providing its data as a product in a discoverable fashion.
Addressable
A data product, once discovered, should have a unique address following a global convention that helps its users to programmatically access it. Organizations may adopt different naming conventions for their data, depending on the underlying storage and format of the data. Considering the ease of use as an objective, in a decentralized architecture, it is necessary for common conventions to be developed. Different domains might store and serve their datasets in different formats, events might be stored and accessed through streams such as Kafka topics, columnar datasets might use CSV files, or AWS S3 buckets of serialized Parquet files. A standard for addressability of datasets in a polyglot environment removes friction when finding and accessing information.
Trustworthy and truthful
No one will use a product that they can't trust. In the traditional data platforms it's acceptable to extract and onboard data that has errors, does not reflect the truth of the business and simply can't be trusted. This is where the majority of the efforts of centralized data pipelines are concentrated, cleansing data after ingestion.
A fundamental shift requires the owners of the data products to provide an acceptable Service Level Objective around the truthfulness of the data, and how closely it reflects the reality of the events that have occurred or the high probability of the truthfulness of the insights that have been generated. Applying data cleansing and automated data integrity testing at the point of creation of the data product are some of the techniques to be utilized to provide an acceptable level of quality. Providing data provenance and data lineage as the metadata associated with each data product helps consumers gain further confidence in the data product and its suitability for their particular needs.
The target value or range of a data integrity (quality) indicator vary between domain data products. For example, 'play event' domain may provide two different data products, one near-real-time with lower level of accuracy, including missing or duplicate events, and one with longer delay and higher level of events accuracy. Each data product defines and assures the target level of its integrity and truthfulness as a set of SLOs.
Self-describing semantics and syntax
Quality products require no consumer hand holding to be used: they can be independently discovered, understood and consumed. Building datasets as products with minimum friction for the data engineers and data scientists to use requires well described semantics and syntax of the data, ideally accompanied with sample datasets as exemplars. Data schemas are a starting point to provide self-serve data assets.
Inter-operable and governed by global standards
One of the main concerns in a distributed domain data architecture, is the ability to correlate data across domains and stitch them together in wonderful, insightful ways; join, filter, aggregate, etc. The key for an effective correlation of data across domains is following certain standards and harmonization rules. Such standardizations should belong to a global governance, to enable interoperability between polyglot domain datasets. Common concerns of such standardization efforts are field type formatting, identifying polysemes across different domains, datasets address conventions, common metadata fields, event formats such as CloudEvents, etc.
For example in the media streaming business, an 'artist' might appear in different domains and have different attributes and identifiers in each domain. The 'play eventstream' domain may recognize the artist differently to 'artists payment' domain that takes care of invoices and payments. However to be able to correlate the data about an artist across different domain data products we need to agree on how we identify an artist as a polyseme. One approach is to consider 'artist' with a federated entity and a unique global federated entity identifier for the 'artist', similarly to how federated identities are managed.
Interoperability and standardization of communications, governed globally, is one of the foundational pillars for building distributed systems.
Secure and governed by a global access control
Accessing product datasets securely is a must, whether the architecture is centralized or not. In the world of decentralized domain oriented data products, the access control is applied at a finer granularity, for each domain data product. Similarly to operational domains the access control policies can be defined centrally but applied at the time of access to each individual dataset product. Using the Enterprise Identity Management system (SSO) and Role Based Access Control policy definition is a convenient way to implement product datasets access control.
Section Data and self-service platform design convergence describes the shared infrastructure that enables the above capabilities for each data product easily and automatically.
Domain data cross-functional teams
Domains that provide data as products need to be augmented with new skill sets: (a) the data product owner and (b) data engineers.
A data product owner makes decisions around the vision and the roadmap for the data products, concerns herself with the satisfaction of her consumers and continuously measures and improves the quality and richness of the data her domain owns and produces. She is responsible for the lifecycle of the domain datasets, when to change, revise and retire data and schemas. She strikes a balance between the competing needs of the domain data consumers.
Data product owners must define success criteria and business-aligned Key Performance Indicators (KPIs) for their data products. For example, the lead time for consumers of a data product to discover and use the data product successfully, is a measurable success criteria.
In order to build and operate the internal data pipelines of the domains, teams must include data engineers. A wonderful side effect of such cross-functional team is cross pollination of different skills. My current industry observation is that some data engineers, while competent in using the tools of their trade, lack software engineering standard practices, such as continuous delivery and automated testing, when it comes to building data assets. Similarly software engineers who are building operational systems often have no experience utilizing data engineering tool sets. Removing the skillset silos will lead to creation of a larger and deeper pool of data engineering skill sets available to the organization. We have observed the same cross-skill pollination with the DevOps movement, and the birth of new types of engineers such as SREs.
Data must be treated as a foundational piece of any software ecosystem, hence software engineers and software generalists must add the experience and knowledge of data product development to their tool belt. Similarly infrastructure engineers need to add knowledge and experience of managing a data infrastructure. Organizations must provide career development pathways from a generalist to a data engineer. The lack of data engineering skills has led to the local optimization of forming centralized data engineering teams as described in section Siloed and hyper-specialized ownership.

Figure 10: Cross functional domain data teams with explicit data product ownership
Data and self-serve platform design convergence
One of the main concerns of distributing the ownership of data to the domains is the duplicated effort and skills required to operate the data pipelines‘ technology stack and infrastructure in each domain. Luckily, building common infrastructure as a platform is a well understood and solved problem; though admittedly the tooling and techniques are not as mature in the data ecosystem.
Harvesting and extracting domain agnostic infrastructure capabilities into a data infrastructure platform solves the need for duplicating the effort of setting up data pipeline engines, storage, and streaming infrastructure. A data infrastructure team can own and provide the necessary technology that the domains need to capture, process, store and serve their data products.
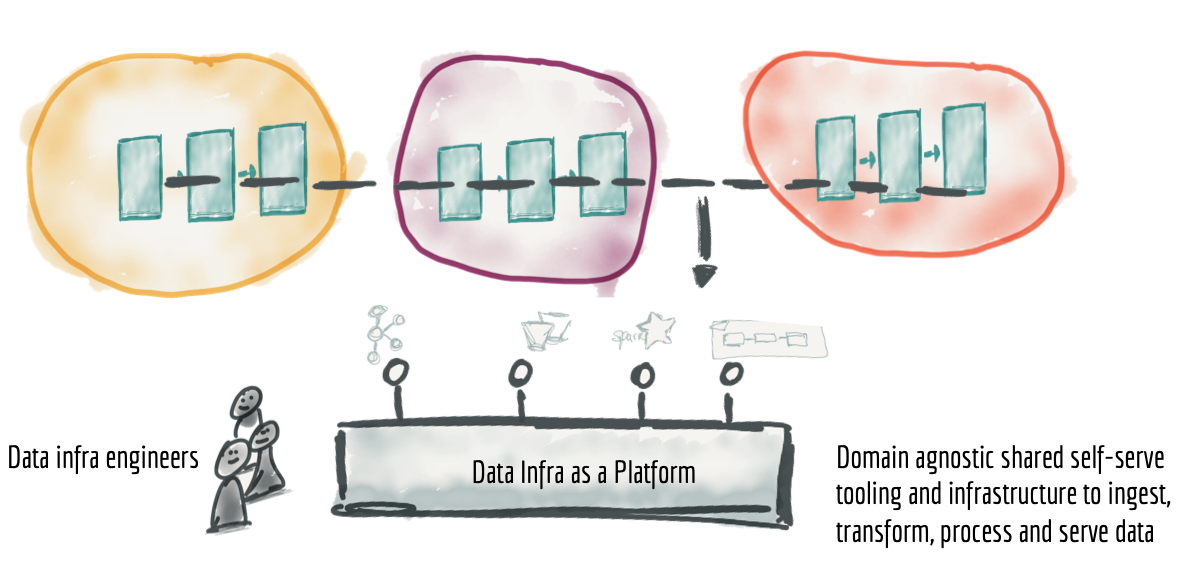
Figure 11: Extracting and harvesting domain agnostic data pipeline infrastructure and tooling into a separate data infrastructure as a platform
The key to building the data infrastructure as a platform is (a) to not include any domain specific concepts or business logic, keeping it domain agnostic, and (b) make sure the platform hides all the underlying complexity and provides the data infrastructure components in a self-service manner. There is a long list of capabilities that a self-serve data infrastructure as a platform provides to its users, a domain's data engineers. Here are a few of them:
- Scalable polyglot big data storage
- Encryption for data at rest and in motion
- Data product versioning
- Data product schema
- Data product de-identification
- Unified data access control and logging
- Data pipeline implementation and orchestration
- Data product discovery, catalog registration and publishing
- Data governance and standardization
- Data product lineage
- Data product monitoring/alerting/log
- Data product quality metrics (collection and sharing)
- In memory data caching
- Federated identity management
- Compute and data locality
A success criteria for self-serve data infrastructure is lowering the 'lead time to create a new data product' on the infrastructure. This leads to automation, required for implementing the capabilities of a 'data product' as covered in section Domain data as a product. For example, automating data ingestion through configurations and scripts, data product creation scripts to put scaffolding in place, auto-registering a data product with the catalog, etc.
Using cloud infrastructure as a substrate reduces the operational costs and effort required to provide on-demand access to the data infrastructure, however it doesn't completely remove the higher abstractions that need to be put in place in the context of the business. Regardless of the cloud provider there is a rich and ever growing set of data infrastructure services that are available to the data infra team.
The paradigm shift towards a data mesh
It's been a long read. Let's bring it all together. We looked at some of the underlying characteristics of the current data platforms: centralized, monolithic, with highly coupled pipeline architecture, operated by silos of hyper-specialized data engineers. We introduced the building blocks of a ubiquitous data mesh as a platform; distributed data products oriented around domains and owned by independent cross-functional teams who have embedded data engineers and data product owners, using common data infrastructure as a platform to host, prep and serve their data assets.
The data mesh platform is an intentionally designed distributed data architecture, under centralized governance and standardization for interoperability, enabled by a shared and harmonized self-serve data infrastructure. I hope it is clear that it is far from a landscape of fragmented silos of inaccessible data.
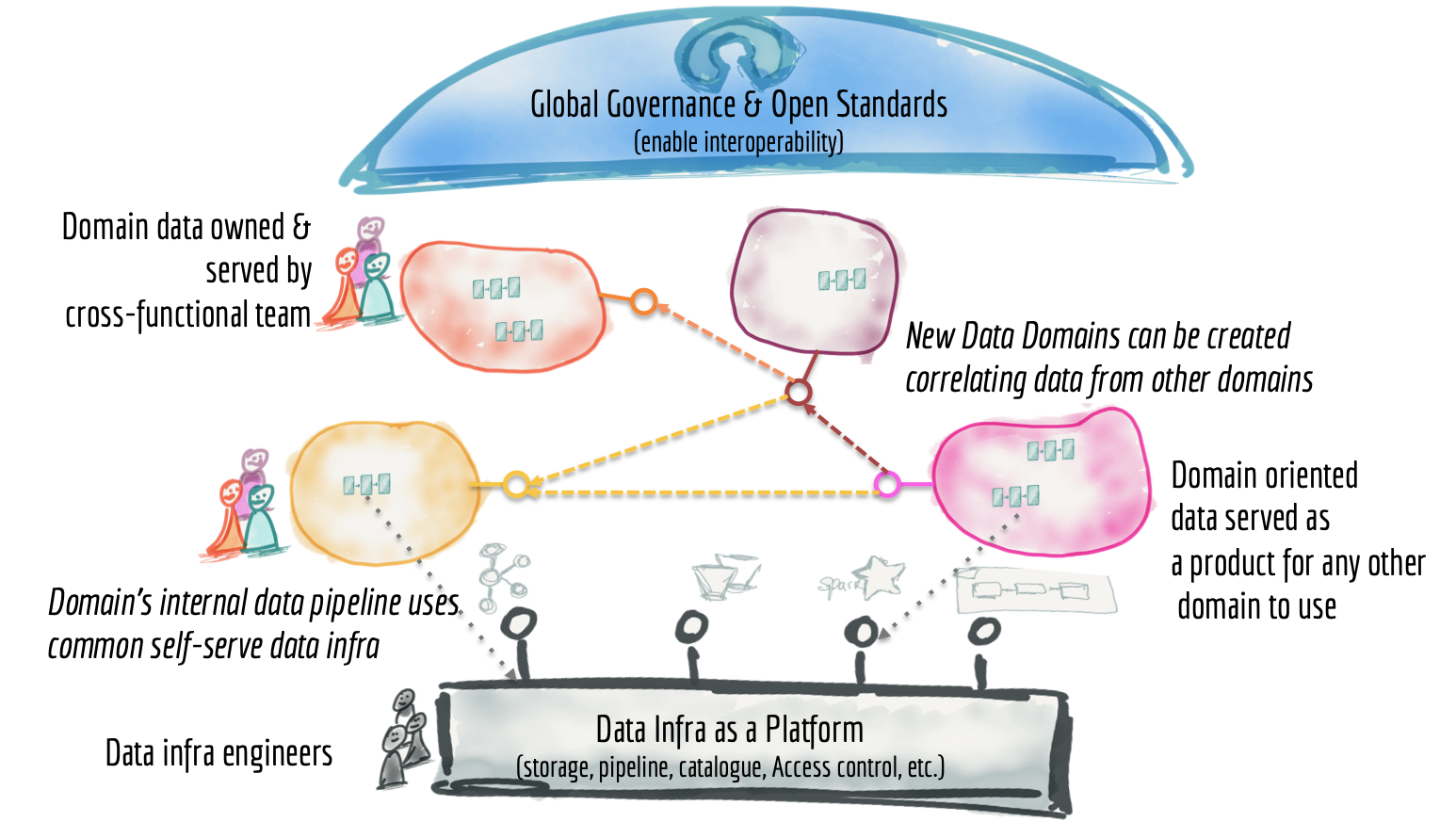
Figure 12: Data mesh architecture from 30,000 foot view
You might ask where does the data lake or data warehouse fit in this architecture? They are simply nodes on the mesh. It's very likely that we won't need a data lake, because the distributed logs and storage that hold the original data are available for exploration from different addressable immutable datasets as products. However, in cases where we do need to make changes to the original format of the data for further exploration, such as labeling, the domain with such need might create its own lake or data hub.
Accordingly, the data lake is no longer the centerpiece of the overall architecture. We will continue to apply some of the principles of data lake, such as making immutable data available for explorations and analytical usage, to the source oriented domain data products. We will continue to use the data lake tooling, however either for internal implementation of data products or as part of the shared data infrastructure.
This, in fact, takes us back to where it all began: James Dixon in 2010 intended a data lake to be used for a single domain, multiple data domains would instead form a 'water garden'.
The main shift is to treat domain data product as a first class concern, and data lake tooling and pipeline as a second class concern - an implementation detail. This inverts the current mental model from a centralized data lake to an ecosystem of data products that play nicely together, a data mesh.
The same principle applies to the data warehouse for business reporting and visualization. It's simply a node on the mesh, and possibly on the consumer oriented edge of the mesh.
I admit that though I see the data mesh practices being applied in pockets at my clients, enterprise scale adoption still has a long way to go. I don't believe technology is the limitation here, all the tooling that we use today can accommodate distribution and ownership by multiple teams. Particularly the shift towards unification of batch and streaming and tools such as Apache Beam or Google Cloud Dataflow, easily allow processing addressable polyglot datasets.
Data catalog platforms such as Google Cloud Data Catalog provide central discoverability, access control and governance of distributed domain datasets. A wide variety of cloud data storage options enables domain data products to choose fit for purpose polyglot storage.
The needs are real and tools are ready. It is up to the engineers and leaders in organizations to realize that the existing paradigm of big data and one true big data platform or data lake, is only going to repeat the failures of the past, just using new cloud based tools.
This paradigm shift requires a new set of governing principles accompanied with a new language:
- serving over ingesting
- discovering and using over extracting and loading
- Publishing events as streams over flowing data around via centralized pipelines
- Ecosystem of data products over centralized data platform
Let's break down the big data monolith into a harmonized, collaborative and distributed ecosystem of data mesh.
Significant Revisions
20 May 2019: Published final installment
16 May 2019: Published installment on product thinking
14 May 2019: Published installment on domain-driven archtecture
13 May 2019: Published installment on current enterprise data platform architecture