
Synthetic Monitoring
25 January 2017


Synthetic monitoring (also called semantic monitoring 1) runs a subset of an application's automated tests against the live production system on a regular basis. The results are pushed into the monitoring service, which triggers alerts in case of failures. This technique combines automated testing with monitoring in order to detect failing business requirements in production.
1: Ryan Murray coined the term “semantic monitoring” and it appeared on the Thoughtworks Technology Radar in late 2012. However “synthetic monitoring” seems to be the more widely used term, and usefully builds on the notion of synthetic transactions.
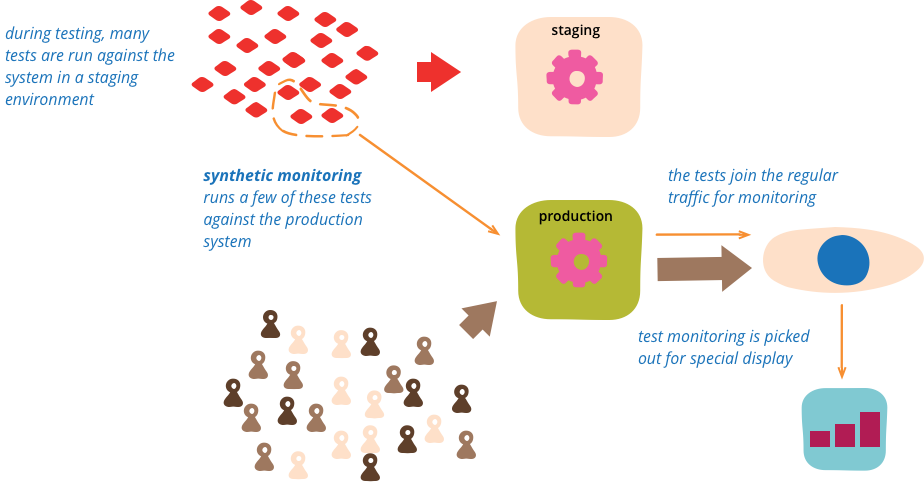
In the age of small independent services and frequent deployments it's very difficult to test pre-production with the exact same combination of versions as they will later exist in production. One way to mitigate this problem is to extend testability from pre-production into production environments - the idea behind QA in production. Doing this shifts the mindset from a focus on Mean-Time-Between-Failures (MTBF) towards a focus on Mean-Time-To-Recovery (MTTR).
MTTR > MTBF, for most types of F
-- John Allspaw
A technique for this is synthetic monitoring, which we used at a client who is a digital marketplace for cars with millions of classifieds across a dozen countries. They have close to a hundred services in production, each deployed multiple times a day. Tests are run in a ContinuousDelivery pipeline before the service is deployed to production. The dependencies for the integration tests do not use TestDoubles, instead the tests run against components in production.
Here is an example of these tests that's well suited for synthetic monitoring. It impersonates a user adding a classified to her list of favourites. The steps she takes are as follows:
| Go to the homepage, log in and remove all favourites, if any. At this point the favourites counter is zero. | 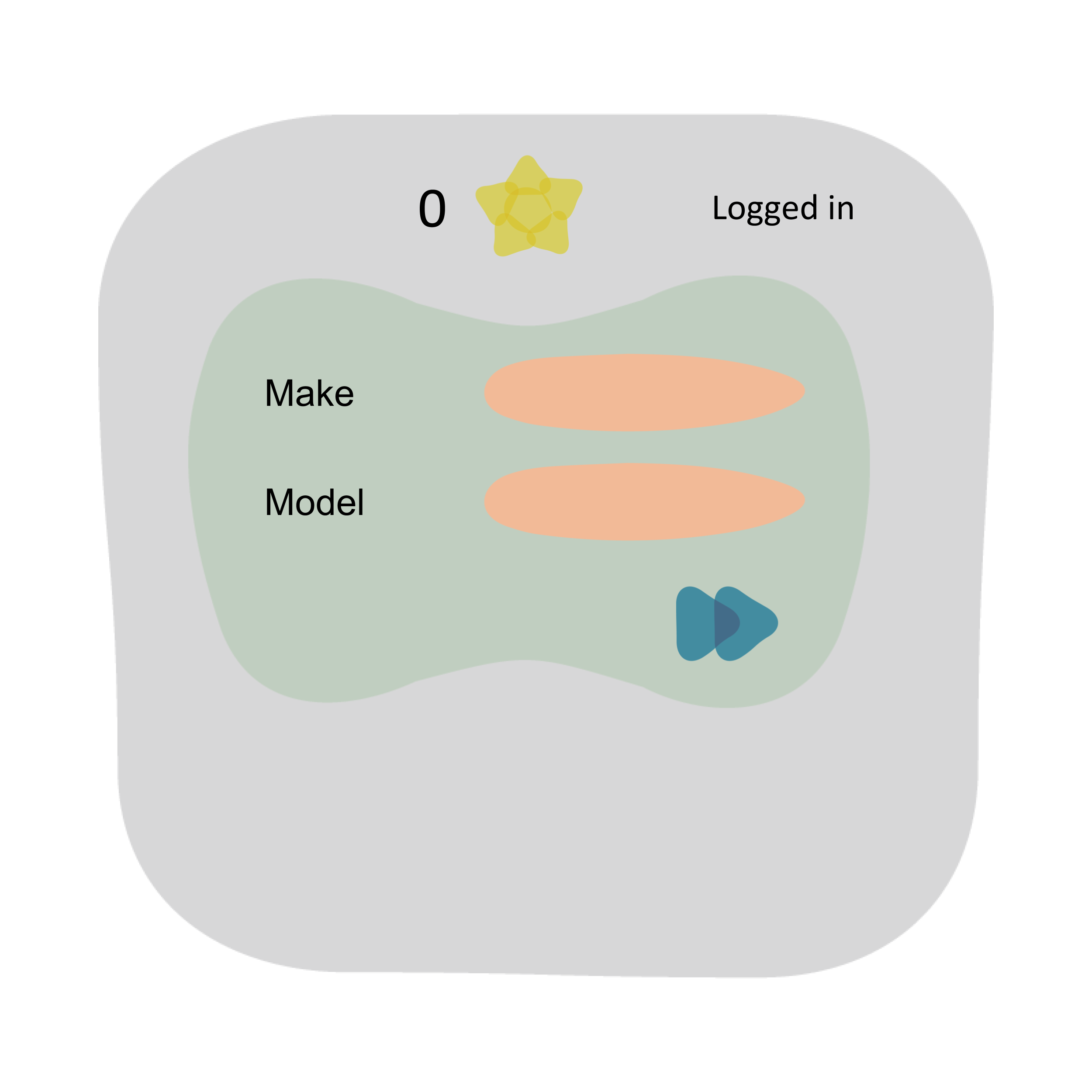 |
| Select some filtering criteria and execute search. | 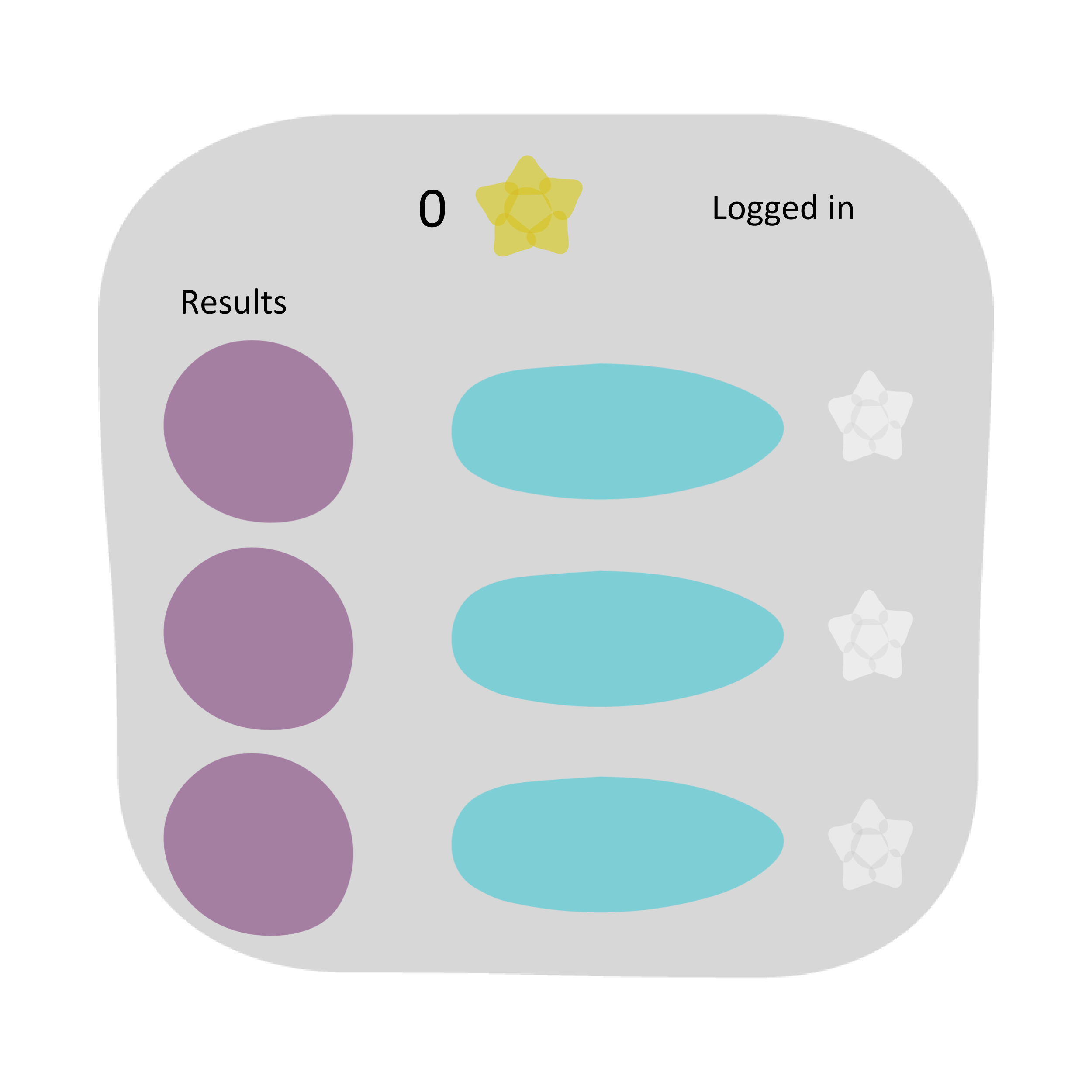 |
| Add two entries from the results to the favourites by clicking the star. The stars change from grey to yellow. | 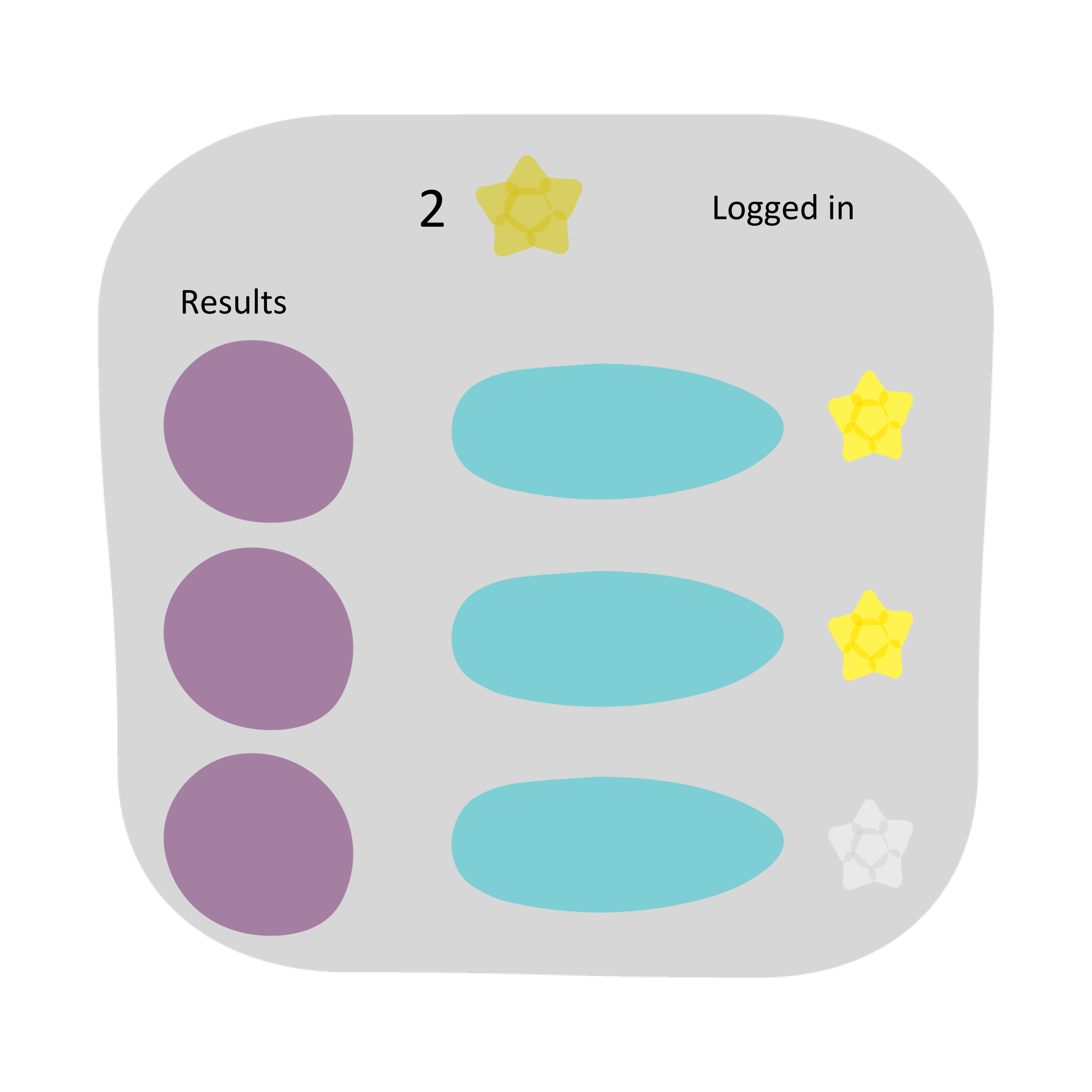 |
| Go to the homepage. At this point the favourites counter should be two. |  |
In order to exclude test requests from analytics we add a parameter
(such as excluderequests=true)
to the URL. The parameter is handed over transitively to all downstream services, each
of which suppresses analytics and third party scripts when it is set to true.
We could use the excluderequests
parameter to mark the data as synthetic in the backend
datastores. In our case this isn't relevant since we re-use the same user account and
clean out its state at the beginning of the test. The downside is that we cannot run
this test concurrently. Alternatively, we could create a new user account for each test run.
To make the test users easily identifiable these accounts would have a specific pre or postfix in the email address.
Another option would be to have a custom HTTP header that would be sent in every request to identify it as a test, though
this is more common for APIs.
Our tests run with the Selenium webdriver and are executed with PhantomJS every 5 minutes against the service in production. The test results are fed into the monitoring system and displayed on the team's dashboard. Depending on the importance of the tested feature, failures can also trigger alerts for on-call duties.
A selection of Broad Stack Tests at the top of the Test Pyramid are well suited to use for synthetic monitoring. These would be UI tests, User Journey Tests, User Acceptance tests or End-to-End tests for web applications; or Consumer-Driven Contract tests (CDCs) for APIs. An alternative to running a suite of UI tests — for example in the context of batch processing jobs — would be to feed a synthetic transaction into the system and assert on its desired final state such as a database entry, a message on a queue or a file in a directory.
Further Reading
- Building Microservices: Designing Fine-Grained Systems -- by Sam Newman
- Testing Strategies in a Microservice Architecture -- by Toby Clemson
Acknowledgements
Thanks to Henry Lawson for his feedback.
And a special thanks to Martin Fowler for his support, suggestions and time spent helping us improve this Bliki.
Notes
1: Ryan Murray coined the term “semantic monitoring” and it appeared on the Thoughtworks Technology Radar in late 2012. However “synthetic monitoring” seems to be the more widely used term, and usefully builds on the notion of synthetic transactions.