
Serverless
20 June 2016

Serverless architectures are internet based systems where the application development does not use the usual server process. Instead they rely solely on a combination of third-party services, client-side logic, and service hosted remote procedure calls (FaaS).
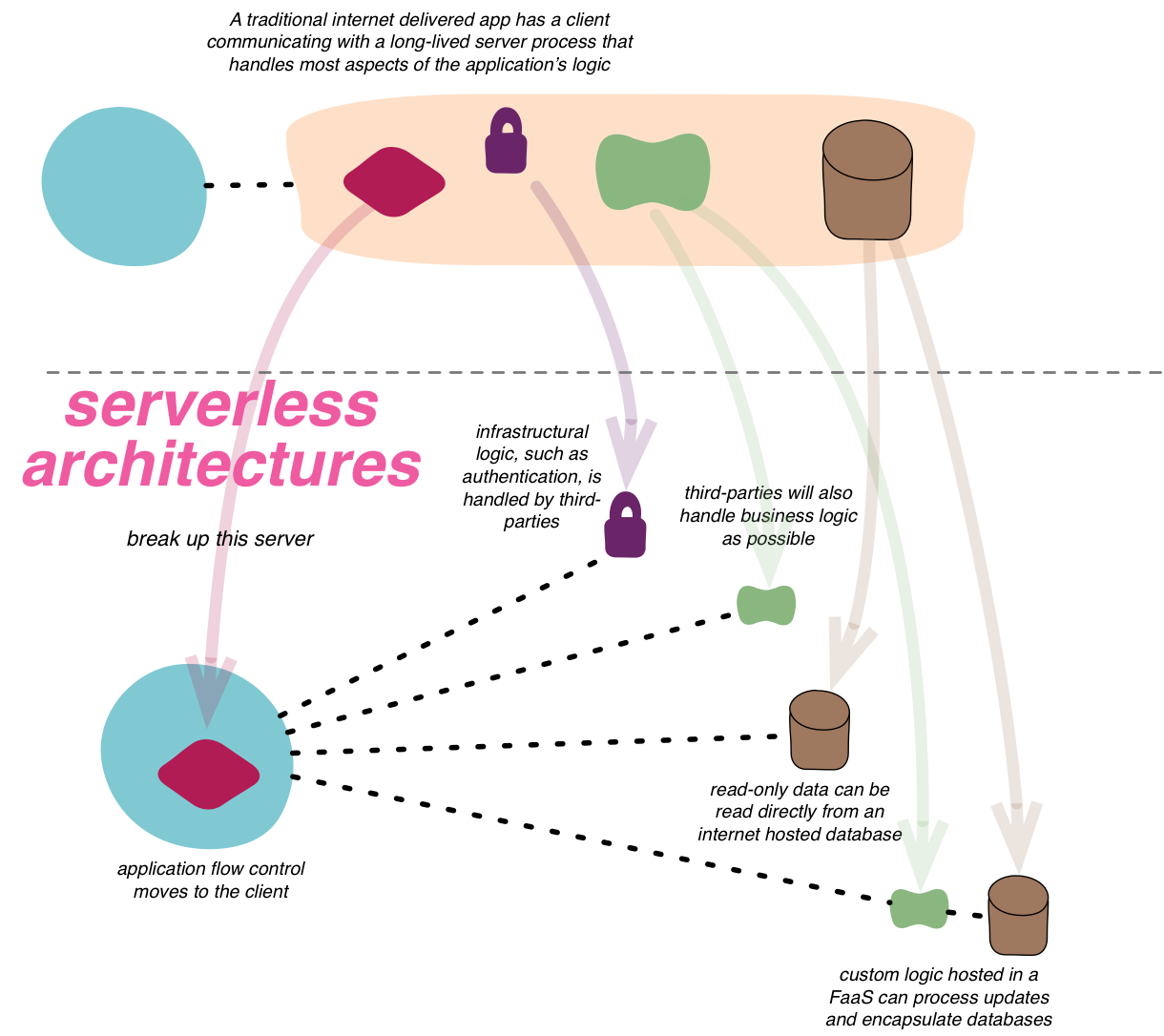
Serverless applications often make extensive use of third party services to accomplish tasks that are traditionally taken care of by servers. These services could be rich ecosystems of services that interoperate, such as Amazon AWS and Azure, or they could be a single service that attempt to provide turnkey set of capabilities such a Parse or Firebase. The abstraction provided by these services could be infrastructural (such as message queues, databases, edge caching…) or higher-level (federated identity, role and capability management, search…).
One of the primary responsibilities of a general purpose server based web application is to control the request-response cycle. Controllers on the server side process input, invoke appropriate application behavior and construct dynamic responses, typically using a templating engine. In a serverless application, where application behavior is woven together from third party services, client side control flow and dynamic content generation replaces the server side controllers. Rich JavaScript applications, mobile applications (and increasingly, TV or embedded IoT applications) coordinate the interaction between the various services by making API calls and using client side UI frameworks to generate the dynamic content.
The most substantive part of a server based web application is the work that happens between the controller and the infrastructure; the business logic. A long lived server hosts the code that implements this logic and performs the required processing for as long as the application stays alive. In serverless applications, custom code components have a lifecycle that is much shorter, closer to the timeline of a single HTTP request/response cycle. The code activates when a request arrives, processes the request and becomes dormant as soon as the activity dies down. This code often lives in a managed environment such as Amazon Lambda, Azure Function or Google Cloud Functions, which takes care of the lifecycle management and scaling of the code. (This style of organizing software is sometimes called “Function as a Service” - FaaS.) The short per-request lifecycle offers itself to a per-request pricing model too, which results in significant cost savings for some teams. 1
1: Other automation services such as Zapier and IFTTT seem to foreshadow in spirit, if not in their developer friendliness, the sort of things that can be done with AWS Lambda, Azure Function or Google Cloud Functions.
A new style, a new set of tradeoffs
All design is about tradeoffs. There are some distinct advantages to applications built in this style and certainly some problems too.
The most commonly asserted benefit is cost. In systems with bursty traffic patterns, the cost of having a beefy server run cold the majority of the time in order to accommodate the bursts is both wasteful and expensive. The demand based pricing model of cloud based infrastructure services can offer significant reduction in costs for teams that have to deal with this type of traffic. In addition, in a traditional server based application the scalability of the application and all associated infrastructural components are the responsibility of the development team. This is often harder than using services that scale transparently behind the simple abstraction of an API available over a URL. Thus teams often find that serverless applications can be made to scale more easily.
On the other hand, there are some new costs. The conceptual overhead of splitting a single application into something that woven from a fabric of services is significant and increases with the number and variety of services used. Local development and unit testing is also harder when applications have significant parts implemented and running in external services. Teams often use Broad Stack Tests and semantic monitoring to offset this to some extent.
Lastly, there is a perceived benefit of serverless systems being easier to operate and maintain. Third-party services spend significant resources on security, availability, scaling and performance. These things often require specialized skills and may not be in the wheelhouse of smaller development teams. But this doesn't mean teams can forget about operations. It still falls on development teams to deal with the problems caused by service outage, downtime, decommissioning and slowdowns and to prevent these from having a cascading impact on their own applications.
Further Reading
Mike Roberts is writing a more detailed article on serverless architectures, which includes examples, further details on trade-offs and contrast with similar styles.
Patrick Debois talks more about the reality of operations for serverless architectures in his talk from serverlessconf 2016
Acknowledgments
I would like to thank Martin Fowler for his help with the illustration, editorial advice and guidance with this post. In addition, many thanks to Mike Roberts, Paul Hammant and Ken McCormack for their input and to Chris Turner, Ian Carvell, Patrick Debois and Jay Sandhaus for taking time to discuss their experiences building serverless applications. Jean-Noël Rouvignac alerted me to some typos.