
Reporting Database
2 April 2014

Most EnterpriseApplications store persistent data with a database. This database supports operational updates of the application's state, and also various reports used for decision support and analysis. The operational needs and the reporting needs are, however, often quite different - with different requirements from a schema and different data access patterns. When this happens it's often a wise idea to separate the reporting needs into a reporting database, which takes a copy of the essential operational data but represents it in a different schema.
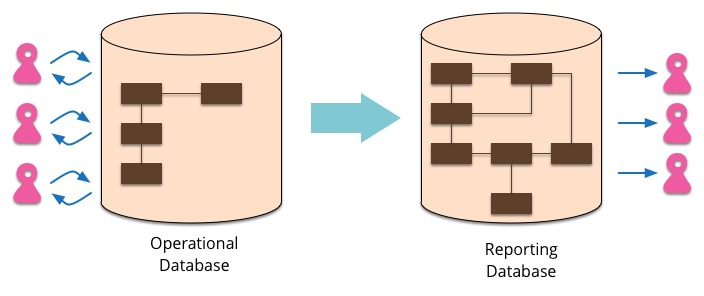
Such a reporting database is a completely different database to the operational database. It may be a completely different database product, using PolyglotPersistence. It should be designed around the reporting needs.
A reporting database has a number of advantages:
- The structure of the reporting database can be specifically designed to make it easier to write reports.
- You don't need to normalize a reporting database, because it's read-only. Feel free to duplicate data as much as needed to make queries and reporting easier.
- The development team can refactor the operational database without needing to change the reporting database.
- Queries run against the reporting database don't add to the load on the operational database.
- You can store derived data in the database, making it easier to write reports that use the derived data without having to introduce a separate set of derivation logic.
- You may have multiple reporting databases for different reporting needs.
The downside to a reporting database is that its data has to be kept up to date. The easiest case is when you do something like use an overnight run to populate the reporting database. This often works quite well since many reporting needs work perfectly well with yesterday's data. If you need more timely data you can use a messaging system so that any changes to the operational database are forwarded to the reporting database. This is more complicated, but the data can be kept fresher. Often most reports can use slightly stale data and you can produce special case reports for things that really need to have this second's data 1.
1: These days the desire seems to be for near-real time analytics. I'm skeptical of the value of this. Often when analyzing data trends you don't need to react right away, and your thinking improves when you give it time for a proper mulling. Reacting too quickly leads to a form of information panic, where you react badly to data that's changing too rapidly to get a proper picture of what's going on.
A variation on this is to use views. This encapsulates the operational data and allows you to denormalize. In order to separate the operational load from the reporting load you need to replicate the views to other nodes for reading. The main limitation is less flexibility to derive data than what you get from an in-memory programming environment.
A reporting database fits well when you have a lot of domain logic in a domain model or other in-memory code. The domain logic can be used to process updates to the operational data, but also to calculate derived data which to enrich the reporting database.
Notes
1: These days the desire seems to be for near-real time analytics. I'm skeptical of the value of this. Often when analyzing data trends you don't need to react right away, and your thinking improves when you give it time for a proper mulling. Reacting too quickly leads to a form of information panic, where you react badly to data that's changing too rapidly to get a proper picture of what's going on.
Revisions
2004-04-02: original publication
2014-04-02: general update
2018-03-27: tweaked views paragraph to point out the ability to replicate view data (thanks to Matthias Hjalmarsson for the prod to do this).