
Editing Publishing Separation
24 April 2012

In my conversations with Thoughtworks project teams over the last year or so, a regular theme has been the growing impact of content management systems (CMS). They aren't usually seen as helpful, indeed there is a clear sign that they are becoming a worryingly invasive tool - used for more than their core purpose in such a manner that they hinder overall development.
Amongst the other irritations, a common failing is that they keep one copy of each article1. This single copy is edited as part of creating the content and published to readers (usually on some kind of state-change flag).
1: I'm using “article” here to mean any item of content that the CMS manages.
The idea of keeping a single copy of some piece of data is a common one. It's the underlying principle behind the relational concept of normalization, and enterprise architects often try to ensure that critical data has a single authoritative copy.
Yet for a CMS there's a clear downside - the data access patterns for editing and publication are very different. Editing involves small number of people frequently accessing the article, doing both reads and updates. Publishing involves many more people (we hope) accessing the article, but all doing reads. There are some edits done to fix problems in published articles, but these are far fewer than the reads and are from a well-controlled group of people.
With two such different access paths, a few CMSs keep separate copies of the articles, controlled by relatively independent modules. The editing module is geared around the frequent updates, it provides support for editing, tracking changes and monitoring the workflow of the editing process. When an article is published it's copied over the publishing module.
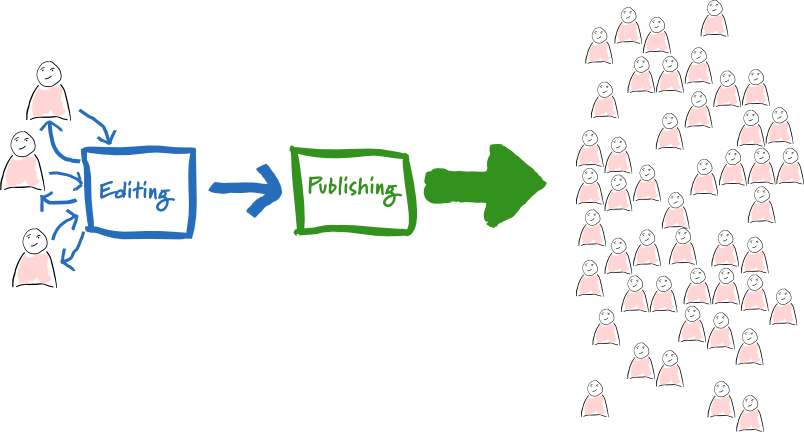
The publishing module treats the article as largely read-only, updated rarely and only by the editing module. Consequently the publishing module is designed around serving that article to a large number of readers. At the least this involves a different configuration of the data storage. The publishing module can be freely replicated across many nodes in a cluster, while it's usually better for the editing module to be centralized on a single node. There's also an argument for different data storage technology, allowing each module to use something appropriate to its access patterns.
The articles can also be stored in different formats. Often articles are edited in one form but published in another, such as editing in markdown and publishing in html. In this case the editing module should store the markdown form while the publishing module stores html. The publishing module can also do some page composition work on the stored copy. So if you have a static header, this can be added to the stored article's html when the article is published, saving the effort of recomposing it for every read.2
2: This does mean that any change to the header would require all the published articles to be rebuilt. Usually this would not be an issue compared to composing the page for each read.
Separating these modules can also help with the editing workflow. Often people want to preview changes before publishing to the world, this is easy to do with the separation because you can publish to a private publishing module in a staging area. This can nicely finesse otherwise awkward logic to figure out what to publish from single storage.
User-generated content does add something of a wrinkle to this approach. A wiki, which is entirely user-generated, is going to have a larger and less-well controlled group of editors than a curated site. Similarly reader comments will come from a wider range of writers. But even with user-generated content you should get many more readers than writers, so it makes sense to separate handling updates from serving published pages.
Teams that use the rare systems that support editing-publishing separation find it works very well and most teams who use tools that don't have this style think it would improve things. If you're evaluating a CMS, or building one for your own needs, you should certainly consider editing-publishing separation as a key feature to look for.
Further Reading
My colleague Sunit Parekh describes an example of building a two-stack CMS that used this principle for a global manufacturer's product catalog.
Notes
1: I'm using “article” here to mean any item of content that the CMS manages.
2: This does mean that any change to the header would require all the published articles to be rebuilt. Usually this would not be an issue compared to composing the page for each read.