
tagged by: continuous delivery
Continuous Delivery Guide
It’s hard enough for software developers to write code that works on their machine. But even when that’s done, there’s a long journey from there to software that’s producing value - since software only produces value when it’s in production. he essence of my philosophy to software delivery is to build software so that it is always in a state where it could be put into production. We call this Continuous Delivery because we are continuously running a deployment pipeline that tests if this software is in a state to be delivered.
Continuous Integration
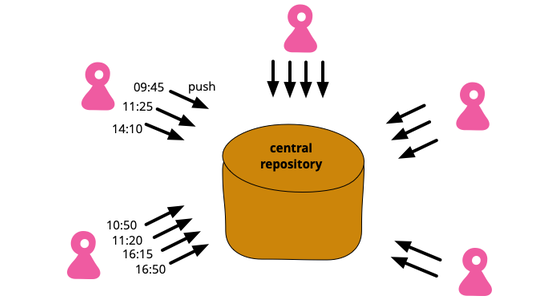
Continuous Integration is a software development practice where each member of a team merges their changes into a codebase together with their colleagues changes at least daily. Each of these integrations is verified by an automated build (including test) to detect integration errors as quickly as possible. Teams find that this approach reduces the risk of delivery delays, reduces the effort of integration, and enables practices that foster a healthy codebase for rapid enhancement with new features.
Patterns for Managing Source Code Branches
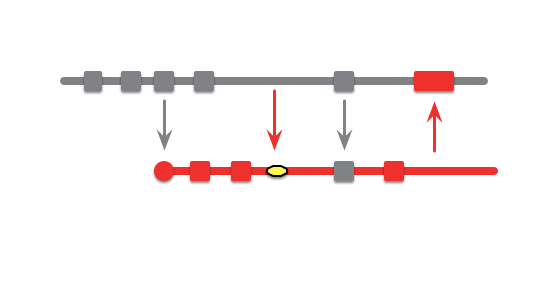
Modern source-control systems provide powerful tools that make it easy to create branches in source code. But eventually these branches have to be merged back together, and many teams spend an inordinate amount of time coping with their tangled thicket of branches. There are several patterns that can allow teams to use branching effectively, concentrating around integrating the work of multiple developers and organizing the path to production releases. The over-arching theme is that branches should be integrated frequently and efforts focused on a healthy mainline that can be deployed into production with minimal effort.
Continuous Delivery
We give a one-hour overview of Continuous Delivery. Topics include the justification of Continuous Delivery, the deployment pipeline, continuous integration, devops, and deployment strategies. The highlight is Jez's personification of a release candidate as a hero in a greek myth.
Continuous Delivery for Machine Learning
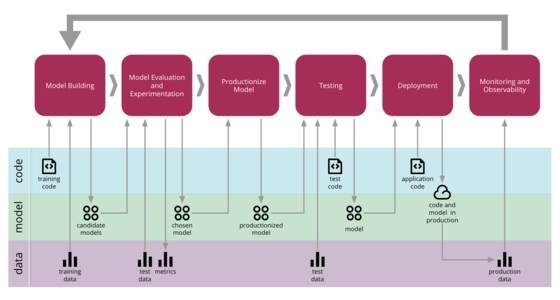
Machine Learning applications are becoming popular in our industry, however the process for developing, deploying, and continuously improving them is more complex compared to more traditional software, such as a web service or a mobile application. They are subject to change in three axis: the code itself, the model, and the data. Their behaviour is often complex and hard to predict, and they are harder to test, harder to explain, and harder to improve. Continuous Delivery for Machine Learning (CD4ML) is the discipline of bringing Continuous Delivery principles and practices to Machine Learning applications.
Compliance in a DevOps Culture
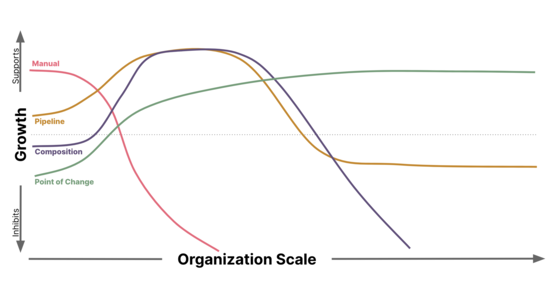
Integrating the necessary Security Controls and Audit capabilities to satisfy Compliance requirements within a DevOps culture can capitalize on CI/CD pipeline automation, but presents unique challenges as an organization scales. Understanding the second order implications and unintended consequences caused by the chosen implementation is key to building an effective, secure, and scalable solution.
Domain-Oriented Observability
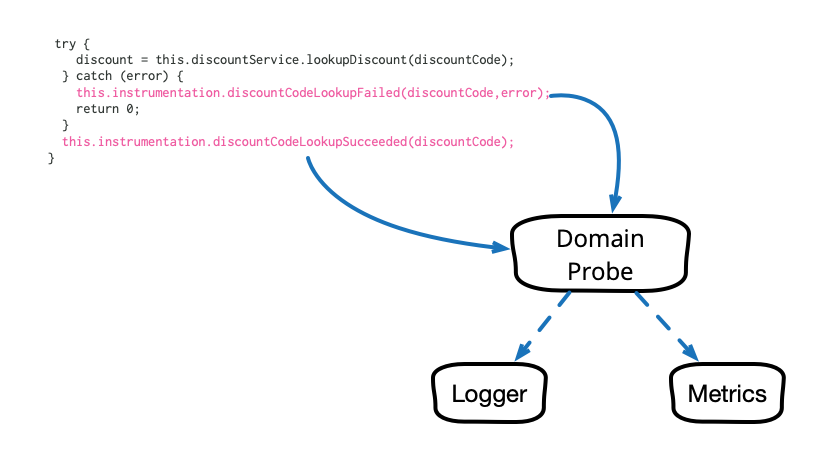
Observability in our software systems has always been valuable and has become even more so in this era of cloud and microservices. However, the observability we add to our systems tends to be rather low level and technical in nature, and too often it seems to require littering our codebase with crufty, verbose calls to various logging, instrumentation, and analytics frameworks. This article describes a pattern that cleans up this mess and allows us to add business-relevant observability in a clean, testable way.
Feature Toggles (aka Feature Flags)
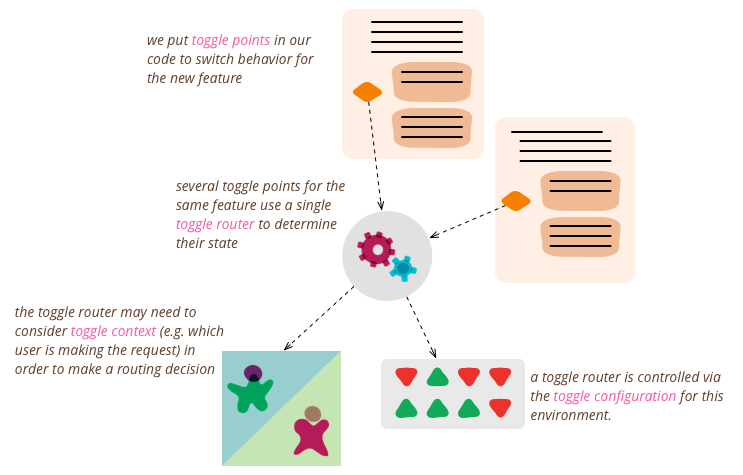
Feature Toggles (often also refered to as Feature Flags) are a powerful technique, allowing teams to modify system behavior without changing code. They fall into various usage categories, and it's important to take that categorization into account when implementing and managing toggles. Toggles introduce complexity. We can keep that complexity in check by using smart toggle implementation practices and appropriate tools to manage our toggle configuration, but we should also aim to constrain the number of toggles in our system.
QA in Production
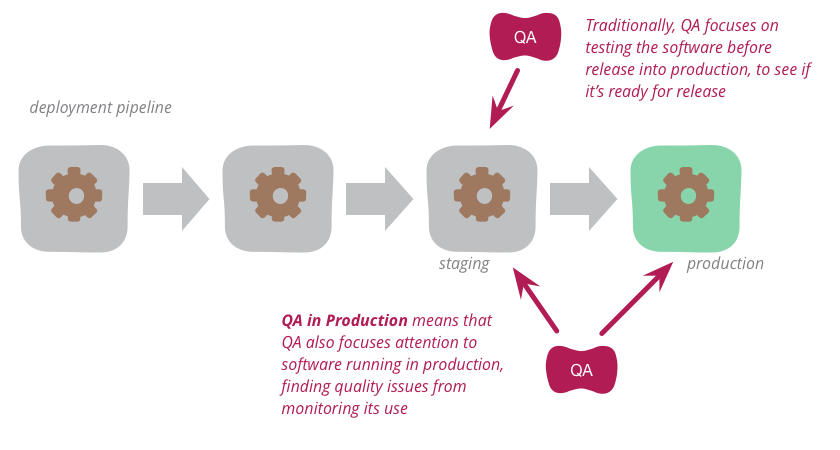
Traditionally, QA focuses on testing the software before release into production to see if it's ready for such release. But increasingly, modern QA organizations are also focusing attention onto the software running in production. By analyzing logs and other monitoring tools, they find quality problems to highlight to the development organization. This approach works particularly well with organizations that use continuous delivery to put new versions of the software into production rapidly and reliably.
InfoQ Interview with Jez and me on Continuous Delivery
An interview with Jez Humble and me at QCon San Francisco in 2010
Eradicating Non-Determinism in Tests
An automated regression suite can play a vital role on a software project, valuable both for reducing defects in production and essential for evolutionary design. In talking with development teams I've often heard about the problem of non-deterministic tests - tests that sometimes pass and sometimes fail. Left uncontrolled, non-deterministic tests can completely destroy the value of an automated regression suite. In this article I outline how to deal with non-deterministic tests. Initially quarantine helps to reduce their damage to other tests, but you still have to fix them soon. Therefore I discuss treatments for the common causes for non-determinism: lack of isolation, asynchronous behavior, remote services, time, and resource leaks.
Mike Mason and I talk about Feature Branching
In this video (12 minutes) Mike Mason and I talk about the perils of Feature Branching and its alternatives.
Using the Rake Build Language
Rake is a build language, similar in purpose to make and ant. Like make and ant it's a Domain Specific Language, unlike those two it's an internal DSL programmed in the Ruby language. In this article I introduce rake and describe some interesting things that came out of my use of rake to build this web site: dependency models, synthesized tasks, custom build routines and debugging the build script.
Agile Handover
One of the most common questions I see about agile projects is how they deal with handover to another team. If you have a development team that leaves and hands over support to a support team, how do they cope when agile projects tend to produce much less documentation than plan-driven processes?
Blue Green Deployment
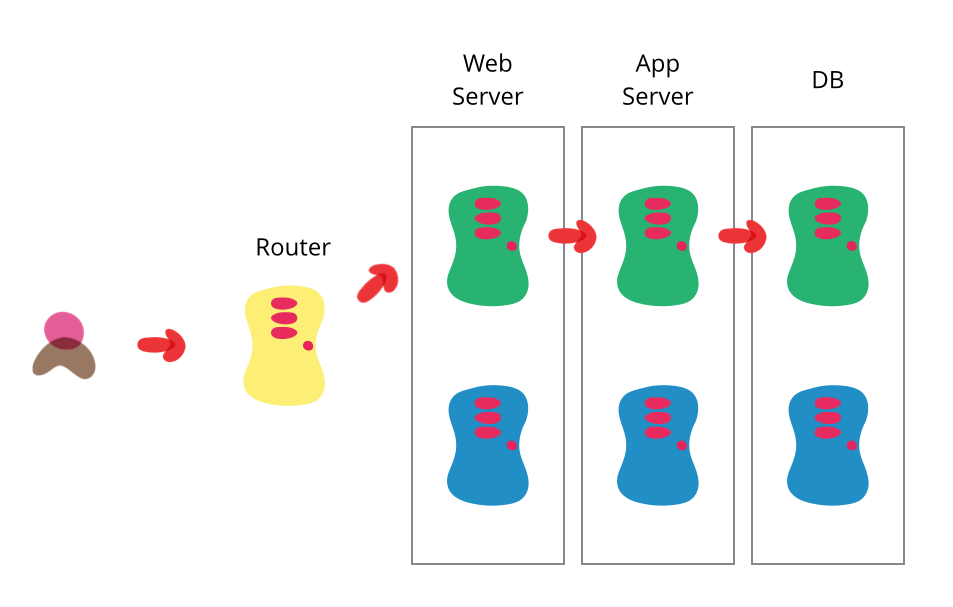
One of the goals that my colleagues and I urge on our clients is that of a completely automated deployment process. Automating your deployment helps reduce the frictions and delays that crop up in between getting the software “done” and getting it to realize its value. Dave Farley and Jez Humble are finishing up a book on this topic - Continuous Delivery. It builds upon many of the ideas that are commonly associated with Continuous Integration, driving more towards this ability to rapidly put software into production and get it doing something. Their section on blue-green deployment caught my eye as one of those techniques that's underused, so I thought I'd give a brief overview of it here.
Branch By Abstraction
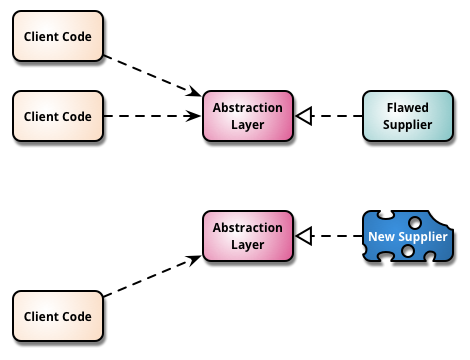
“Branch by Abstraction” is a technique for making a large-scale change to a software system in gradual way that allows you to release the system regularly while the change is still in-progress.
Buildix
I've talked many times about the virtues of Continuous Integration. To get such an environment working you need a continuous integration server, and a source code control system. To make a project run smoothly you could also do with an issue tracker for bug tracking and the like, and a wiki to help capture all sorts of project knowledge.
Canary Release
Canary release is a technique to reduce the risk of introducing a new software version in production by slowly rolling out the change to a small subset of users before rolling it out to the entire infrastructure and making it available to everybody.
Catastrophic Failover
One of the oft advertised features of modern application servers is that they provide failover in a cluster. Clustering improves the reliability of your application, if one of your servers goes down, you have some more up to server your customers. Failover can add even more reliability, if a server goes down in the middle of a interaction the cluster can move that interaction to another server.
However this can be a problem.
Circuit Breaker
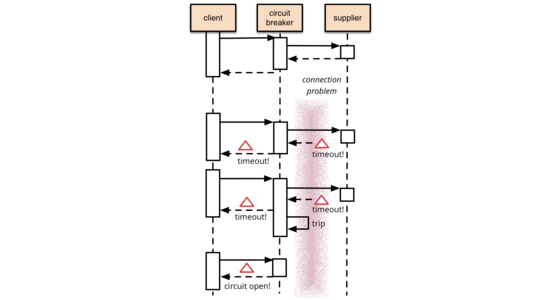
It's common for software systems to make remote calls to software running in different processes, probably on different machines across a network. One of the big differences between in-memory calls and remote calls is that remote calls can fail, or hang without a response until some timeout limit is reached. What's worse if you have many callers on a unresponsive supplier, then you can run out of critical resources leading to cascading failures across multiple systems. In his excellent book Release It, Michael Nygard popularized the Circuit Breaker pattern to prevent this kind of catastrophic cascade.
The basic idea behind the circuit breaker is very simple. You wrap a protected function call in a circuit breaker object, which monitors for failures. Once the failures reach a certain threshold, the circuit breaker trips, and all further calls to the circuit breaker return with an error, without the protected call being made at all. Usually you'll also want some kind of monitor alert if the circuit breaker trips.
Configuration Synchronization
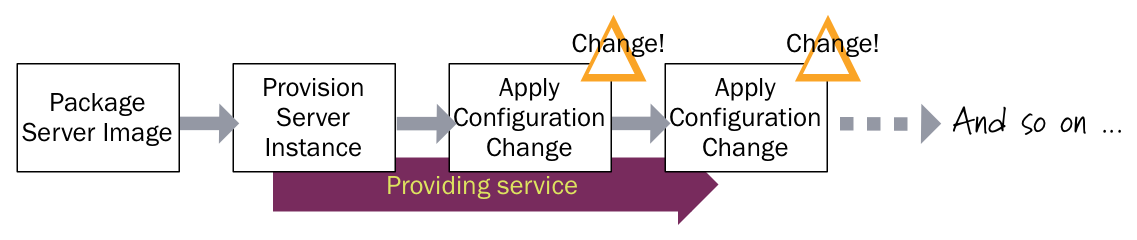
Automated configuration tools (such as CFEngine, Puppet, or Chef) allow you to avoid SnowflakeServers by providing recipes to describe the configuration of elements of a server. Configuration synchronization continually applies these specifications, either on a regular schedule or when it changes, to server instances throughout their lifetime. If someone makes a change to a server outside the tool, it will be reverted to the centrally specified configuration the next time the server is synchronized. If some configuration change is needed, it's made in the configuration specification (recipes, manifests, or whatever the particular configuration tool calls it), and is then applied to all relevant servers across the infrastructure.
Continuous Delivery
Continuous Delivery is a software development discipline where you build software in such a way that the software can be released to production at any time.
You’re doing continuous delivery when:
- Your software is deployable throughout its lifecycle
- Your team prioritizes keeping the software deployable over working on new features
- Anybody can get fast, automated feedback on the production readiness of their systems any time somebody makes a change to them
- You can perform push-button deployments of any version of the software to any environment on demand
Continuous Integration Certification
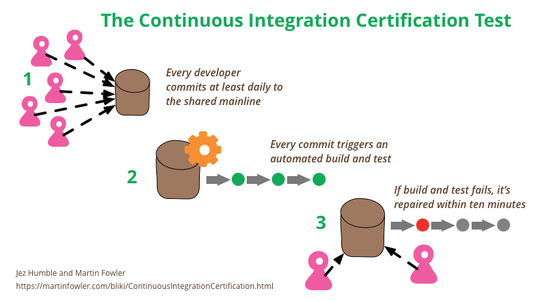
Continuous Integration is a popular technique in software development. At conferences many developers talk about how they use it, and Continuous Integration tools are common in most development organizations. But we all know that any decent technique needs a certification program — and fortunately one does exist. Developed by one of the foremost experts in continuous delivery and devops, it’s known for being remarkably rapid to administer, yet very insightful for its results. Although it’s quite mature, it isn’t as well known as it should be, so as a fan of the technique I think it’s important for me to share this certification program with my readers. Are you ready to be certified for Continuous Integration? And how will you deal with the shocking truth that taking the test will reveal?
Cycle Time

Cycle Time is a measure of how long it takes to get a new feature in a software system from idea to running in production. In Agile circles, we try to minimize cycle time. We do this by defining and implementing very small features and minimizing delays in the development process. Although the rough notion of cycle time, and the importance of reducing it, is common, there is a lot of variations on how cycle time is measured.
Dark Launching
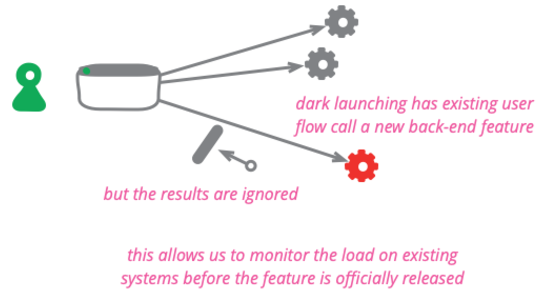
Dark launching a feature means taking a new or changed back-end behavior and calling it from existing users without the users being able to tell it's being called. It's done to assess the additional load and performance impacts upon the system before making a public announcement of the new capability.
Database And Build Time
Here's an interesting contrast I recently picked up. Two enterprise application projects of a similar size (~100 KLOC), similar environments (Java and .NET). One can do a full build and test in an hour, the other takes 2-3 minutes.
Deployment Pipeline
One of the challenges of an automated build and test environment is you want your build to be fast, so that you can get fast feedback, but comprehensive tests take a long time to run. A deployment pipeline is a way to deal with this by breaking up your build into stages. Each stage provides increasing confidence, usually at the cost of extra time. Early stages can find most problems yielding faster feedback, while later stages provide slower and more through probing. Deployment pipelines are a central part of ContinuousDelivery.
Dev Ops Culture
Agile software development has broken down some of the silos between requirements analysis, testing and development. Deployment, operations and maintenance are other activities which have suffered a similar separation from the rest of the software development process. The DevOps movement is aimed at removing these silos and encouraging collaboration between development and operations.
Diff Debugging
Regression bugs are newly appeared bugs in features of the software that have been around for a while. When hunting them, it usually valuable to figure out which change in the software caused them to appear. Looking at that change can give invaluable clues about where the bug is and how to squash it. There isn't a well-known term for this form of investigation, but I call it Diff Debugging.
Feature Branch
A feature branch is a source code branching pattern where a developer opens a branch when she starts working on a new feature. She does all the work on the feature on this branch and integrates the changes with the rest of the team when the feature is done.
Feature Flag
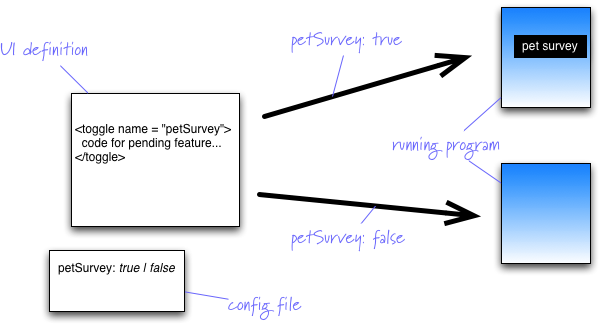
One of the most common arguments in favor of FeatureBranch is that it provides a mechanism for pending features that take longer than a single release cycle. Imagine you are releasing into production every two weeks, but need to build a feature that's going to take three months to complete. How do you use Continuous Integration to keep everyone working on the mainline without revealing a half-implemented feature on your releases? We run into this issue quite a lot and feature flags are a handy tool to deal with it.
Frequency Reduces Difficulty
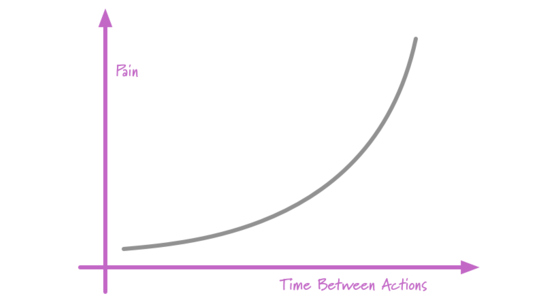
One of my favorite soundbites is: if it hurts, do it more often. It has the happy property of seeming nonsensical on the surface, but yielding some valuable meaning when you dig deeper
Immutable Server
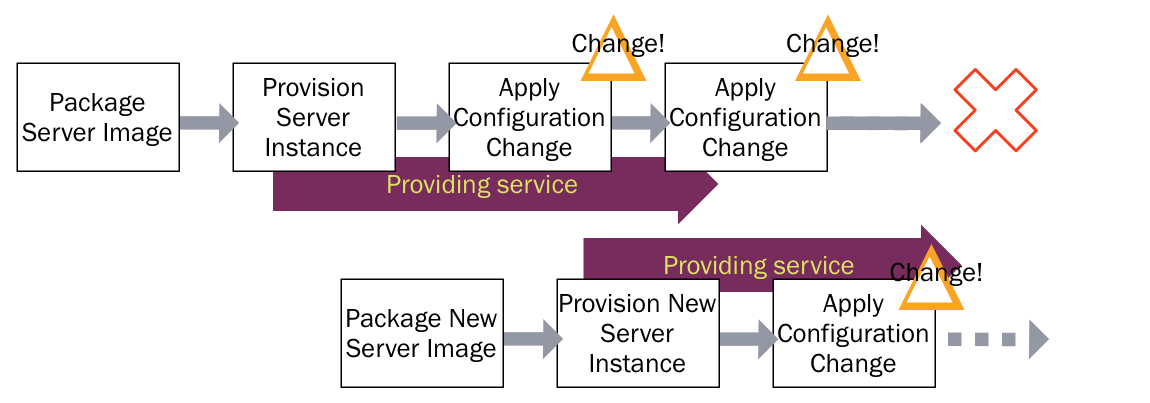
Automated configuration tools (such as CFEngine, Puppet, or Chef) allow you to specify how servers should be configured, and bring new and existing machines into compliance. This helps to avoid the problem of fragile SnowflakeServers. Such tools can create PhoenixServers that can be torn down and rebuilt at will. An Immutable Server is the logical conclusion of this approach, a server that once deployed, is never modified, merely replaced with a new updated instance.
Incremental Migration
Like any profession, software development has it's share of oft-forgotten activities that are usually ignored but have a habit of biting back at just the wrong moment. One of these is data migration.
Infrastructure As Code
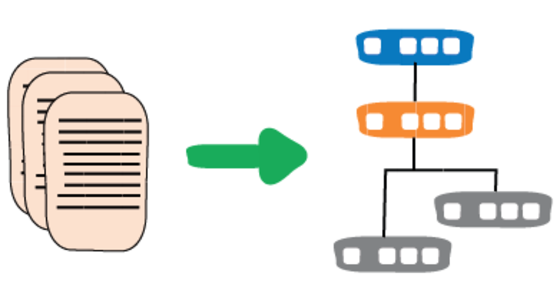
Infrastructure as code is the approach to defining computing and network infrastructure through source code that can then be treated just like any software system. Such code can be kept in source control to allow auditability and ReproducibleBuilds, subject to testing practices, and the full discipline of ContinuousDelivery. It's an approach that's been used over the last decade to deal with growing CloudComputing platforms and will become the dominant way to handle computing infrastructure in the next.
Keystone Interface
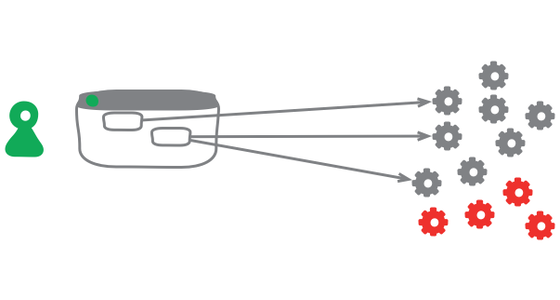
Software development teams find life can be much easier if they integrate their work as often as they can. They also find it valuable to release frequently into production. But teams don't want to expose half-developed features to their users. A useful technique to deal with this tension is to build all the back-end code, integrate, but don't build the user-interface. The feature can be integrated and tested, but the UI is held back until the end until, like a keystone, it's added to complete the feature, revealing it to the users.
Pending Head
I'm a big fan of Continuous Integration, it's an relatively simple practice that can make a huge difference to most development teams. However like most practices it has its flaws^H^H^H^H^H opportunities for improvement. Paul Duvall, author of the soon-to-be-standard book on the subject, pointed out one of these recently. If the commit build breaks, the whole team is affected and potentially slowed until it's fixed.
Phoenix Server
One day I had this fantasy of starting a certification service for operations. The certification assessment would consist of a colleague and I turning up at the corporate data center and setting about critical production servers with a baseball bat, a chainsaw, and a water pistol. The assessment would be based on how long it would take for the operations team to get all the applications up and running again.
Pull Request
Pull Requests are a mechanism popularized by github, used to help facilitate merging of work, particularly in the context of open-source projects. A contributor works on their contribution in a fork (clone) of the central repository. Once their contribution is finished they create a pull request to notify the owner of the central repository that their work is ready to be merged into the mainline. Tooling supports and encourages code review of the contribution before accepting the request. Pull requests have become widely used in software development, but critics are concerned by the addition of integration friction which can prevent continuous integration.
Refinement Code Review
When people think of code reviews, they usually think in terms of an explicit step in a development team's workflow. These days the Pre-Integration Review, carried out on a Pull Request is the most common mechanism for a code review, to the point that many people witlessly consider that not using pull requests removes all opportunities for doing code review. Such a narrow view of code reviews doesn't just ignore a host of explicit mechanisms for review, it more importantly neglects probably the most powerful code review technique - that of perpetual refinement done by the entire team.
Reproducible Build
One of the prevailing assumptions that fans of Continuous Integration have is that builds should be reproducible. By this we mean that at any point you should be able to take some older version of the system that you are working on and build it from source in exactly the same way as you did then.
Self Testing Code

Self-Testing Code is the name I used in Refactoring to refer to the practice of writing comprehensive automated tests in conjunction with the functional software. When done well this allows you to invoke a single command that executes the tests - and you are confident that these tests will illuminate any bugs hiding in your code.
Semantic Conflict
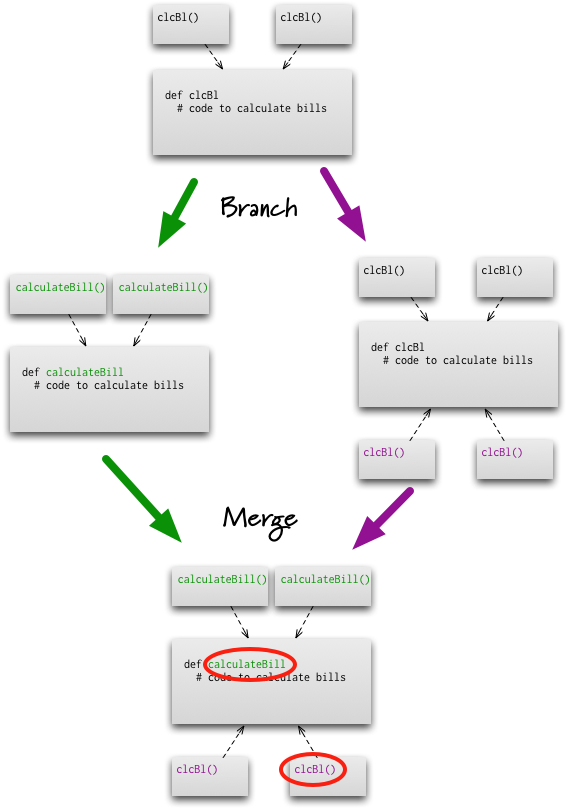
Those who hear my colleagues and I talk about FeatureBranch know that we're not big fans of that pattern. An important part of our objection is the observation that branching is easy, but merging is hard. One argument we hear from time to time is that modern VersionControlTools make merging sufficiently easy that feature branching is worthwhile.
Snowflake Server
It can be finicky business to keep a production server running. You have to ensure the operating system and any other dependent software is properly patched to keep it up to date. Hosted applications need to be upgraded regularly. Configuration changes are regularly needed to tweak the environment so that it runs efficiently and communicates properly with other systems. This requires some mix of command-line invocations, jumping between GUI screens, and editing text files.
The result is a unique snowflake - good for a ski resort, bad for a data center.
State Of Dev Ops Report
The State of DevOps Report is an annual report that uses a statistical analysis of survey data to determine effective practices for software delivery organizations. Its principal authors are Nicole Forsgren, Jez Humble, and Gene Kim.
Synthetic Monitoring
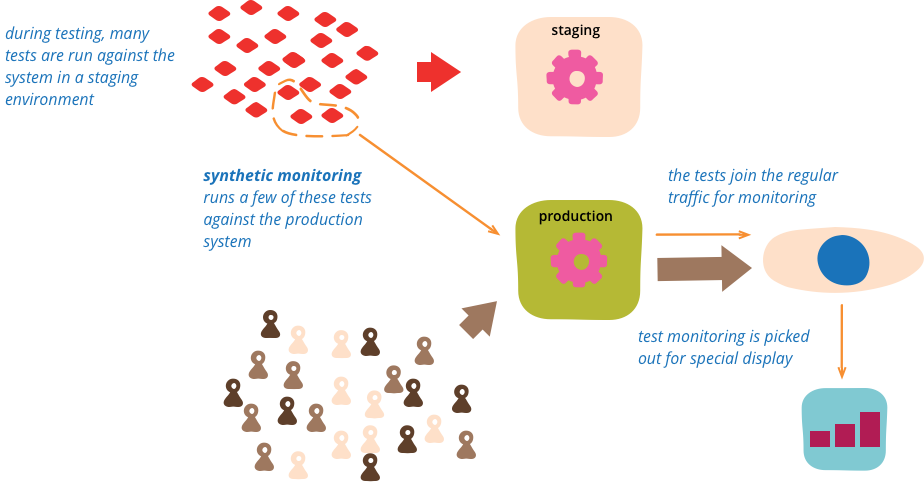
Synthetic monitoring (also called semantic monitoring ) runs a subset of an application's automated tests against the live production system on a regular basis. The results are pushed into the monitoring service, which triggers alerts in case of failures. This technique combines automated testing with monitoring in order to detect failing business requirements in production.
Very Low Defect Project
When people talk about Extreme Programming, they often focus on such things as its adaptive planning style, or its evolutionary approach design. One small but growing trend that particularly interests me is the small but growing number of XP projects that have very low defect rates, by which I mean less than one production bug per month.