
tagged by: version control
Patterns for Managing Source Code Branches
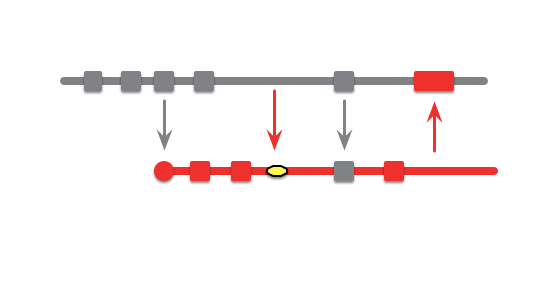
Modern source-control systems provide powerful tools that make it easy to create branches in source code. But eventually these branches have to be merged back together, and many teams spend an inordinate amount of time coping with their tangled thicket of branches. There are several patterns that can allow teams to use branching effectively, concentrating around integrating the work of multiple developers and organizing the path to production releases. The over-arching theme is that branches should be integrated frequently and efforts focused on a healthy mainline that can be deployed into production with minimal effort.
Ship / Show / Ask
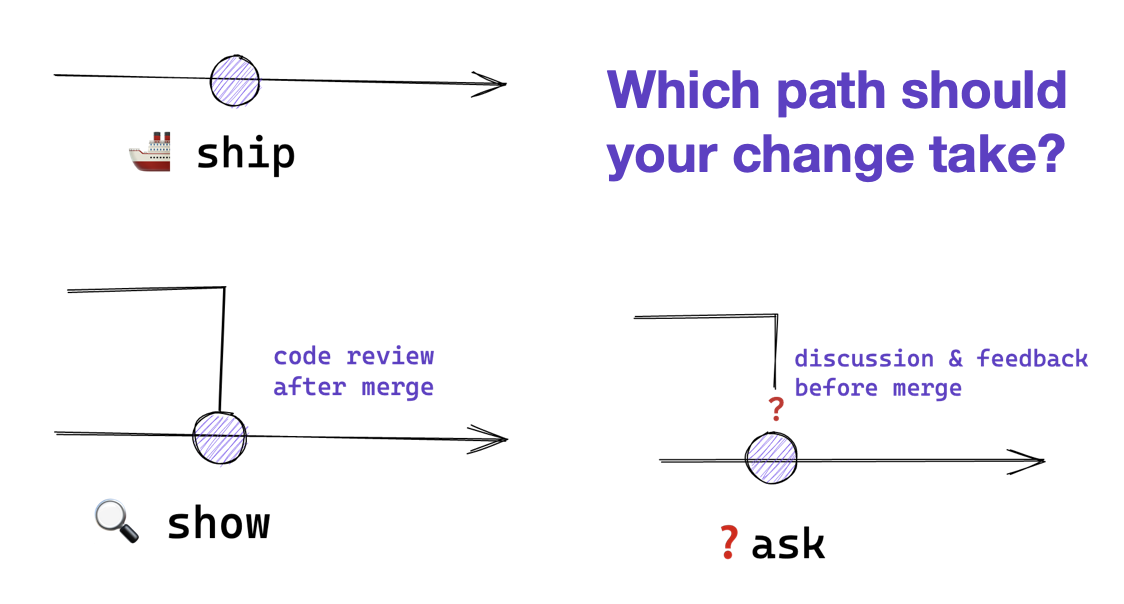
Ship/Show/Ask is a branching strategy that combines the features of Pull Requests with the ability to keep shipping changes. Changes are categorized as either Ship (merge into mainline without review), Show (open a pull request for review, but merge into mainline immediately), or Ask (open a pull request for discussion before merging).
Branch By Abstraction
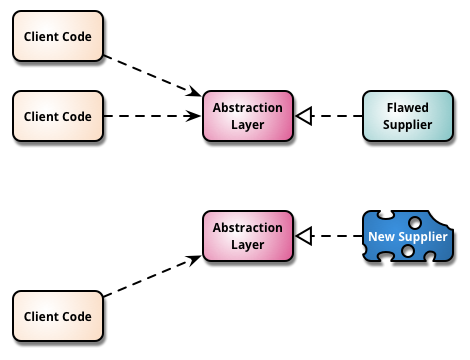
“Branch by Abstraction” is a technique for making a large-scale change to a software system in gradual way that allows you to release the system regularly while the change is still in-progress.
Continuous Delivery
Continuous Delivery is a software development discipline where you build software in such a way that the software can be released to production at any time.
You’re doing continuous delivery when:
- Your software is deployable throughout its lifecycle
- Your team prioritizes keeping the software deployable over working on new features
- Anybody can get fast, automated feedback on the production readiness of their systems any time somebody makes a change to them
- You can perform push-button deployments of any version of the software to any environment on demand
Diff Debugging
Regression bugs are newly appeared bugs in features of the software that have been around for a while. When hunting them, it usually valuable to figure out which change in the software caused them to appear. Looking at that change can give invaluable clues about where the bug is and how to squash it. There isn't a well-known term for this form of investigation, but I call it Diff Debugging.
Feature Branch
A feature branch is a source code branching pattern where a developer opens a branch when she starts working on a new feature. She does all the work on the feature on this branch and integrates the changes with the rest of the team when the feature is done.
Keystone Interface
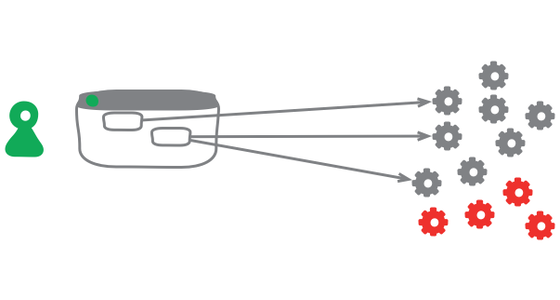
Software development teams find life can be much easier if they integrate their work as often as they can. They also find it valuable to release frequently into production. But teams don't want to expose half-developed features to their users. A useful technique to deal with this tension is to build all the back-end code, integrate, but don't build the user-interface. The feature can be integrated and tested, but the UI is held back until the end until, like a keystone, it's added to complete the feature, revealing it to the users.
Mercurial Squash Commit
I've recently had a bit of a fiddle squashing some commits with Mercurial, so thought it was worth a post in case anyone else is looking to do this. I don't know whether this is the best procedure, but it seemed to work pretty well for me.
More Version Control
As someone who uses version control all the time, I think it's something that can grow into more areas of computer use. Other than software developers, few computer users use version control. Yet as software developers know, version control is a great mechanism for collaborative work, allowing multiple people to work together on a single software system. What would be the benefits of version control being more widely used?
Pending Head
I'm a big fan of Continuous Integration, it's an relatively simple practice that can make a huge difference to most development teams. However like most practices it has its flaws^H^H^H^H^H opportunities for improvement. Paul Duvall, author of the soon-to-be-standard book on the subject, pointed out one of these recently. If the commit build breaks, the whole team is affected and potentially slowed until it's fixed.
Pervasive Versioning
Recently Apple announced the Time Machine, which is the ability to go back in time and see all the alterations to your files, including finding deleted files. For some of us intense geeks, this is not a new feature. Like others, I put my entire working directory under version control, originally CVS now Subversion, and have thus had the ability to easily look at all the changes to everything I work on. It's such a useful feature that I've wondered before about what it would be like to have MoreVersionControl, and perhaps Time Machine is a step in that direction.
Reproducible Build
One of the prevailing assumptions that fans of Continuous Integration have is that builds should be reproducible. By this we mean that at any point you should be able to take some older version of the system that you are working on and build it from source in exactly the same way as you did then.
Semantic Conflict
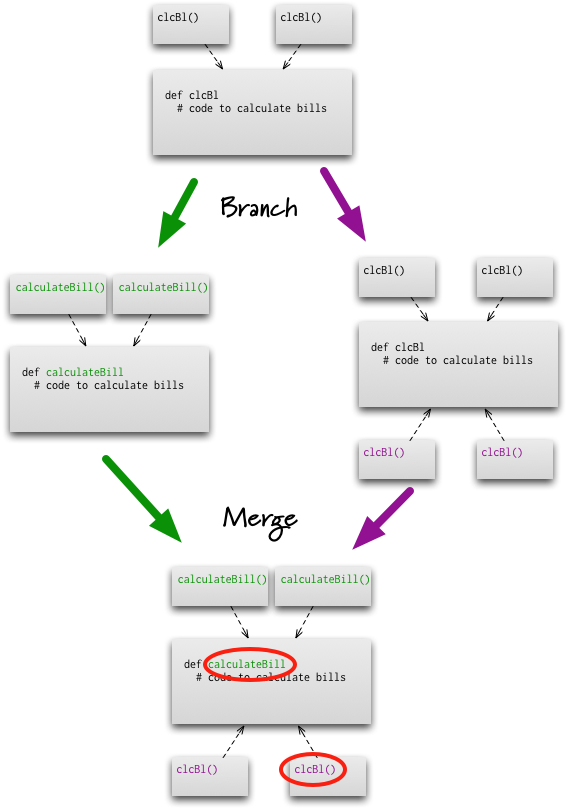
Those who hear my colleagues and I talk about FeatureBranch know that we're not big fans of that pattern. An important part of our objection is the observation that branching is easy, but merging is hard. One argument we hear from time to time is that modern VersionControlTools make merging sufficiently easy that feature branching is worthwhile.
Semantic Diff
Most version control systems rely on using and understanding the changes between versions of artifacts - often referred to as diffs from the command that can produce them in Unix. Good diff (and merge) algorithms are around for text and binary files. The trouble with these diffs is that they are rather dumb. All they do is look at the two artifact versions and generate a simple way of getting from one to another.
Subversion
Subversion is the an open-source version control system - in essence a successor to CVS. It fixes the biggest issues with CVS, introducing such things as atomic commits and support for file and directory renaming. I've been using it for a couple of years and have found it very solid.
Vcs Survey
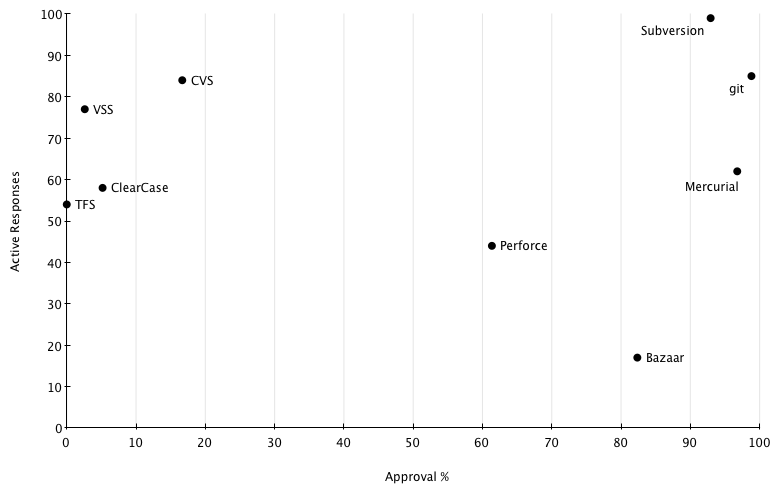
When I discussed VersionControlTools I said that it was an unscientific agglomeration of opinion. As I was doing it I realized that I could add some spurious but mesmerizing numbers to my analysis by doing a survey. Google's spreadsheet makes the mechanics of conducting a survey really simple, so I couldn't resist.
Version Control Tools
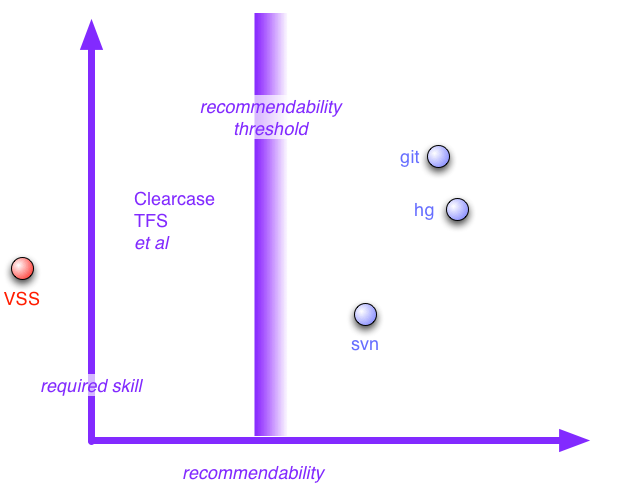
If you spend time talking to software developers about tools, one of the biggest topics I hear about are version control tools. Once you've got to the point of using version control tools, and any competent developers does, then they become a big part of your life. Version tools are not just important for maintaining a history of a project, they are also the foundation for a team to collaborate. So it's no surprise that I hear frequent complaints about poor version control tools. In our recent Thoughtworks technology radar, we called out two items as version control tools that enterprises should be assessing for use: Subversion and Distributed Version Control Systems (DVCS). Here I want to expand on that, summarizing many discussions we've had internally about version control tools.