
tagged by: data mesh
Data Mesh Principles and Logical Architecture
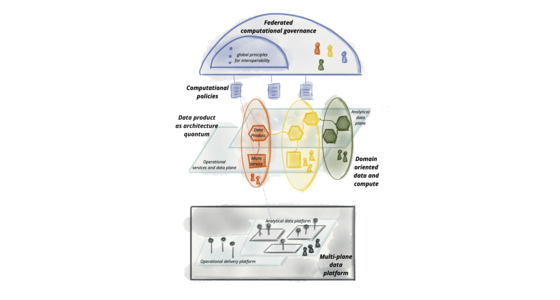
Our aspiration to augment and improve every aspect of business and life with data, demands a paradigm shift in how we manage data at scale. While the technology advances of the past decade have addressed the scale of volume of data and data processing compute, they have failed to address scale in other dimensions: changes in the data landscape, proliferation of sources of data, diversity of data use cases and users, and speed of response to change. Data mesh addresses these dimensions, founded in four principles: domain-oriented decentralized data ownership and architecture, data as a product, self-serve data infrastructure as a platform, and federated computational governance. Each principle drives a new logical view of the technical architecture and organizational structure.
How to Move Beyond a Monolithic Data Lake to a Distributed Data Mesh
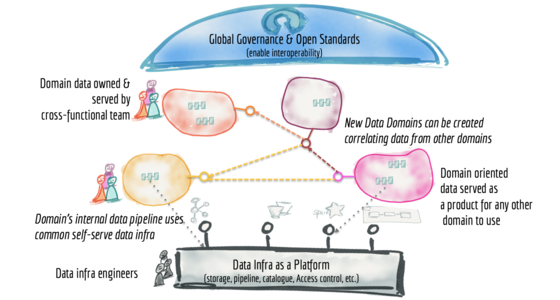
Many enterprises are investing in their next generation data lake, with the hope of democratizing data at scale to provide business insights and ultimately make automated intelligent decisions. Data platforms based on the data lake architecture have common failure modes that lead to unfulfilled promises at scale. To address these failure modes we need to shift from the centralized paradigm of a lake, or its predecessor data warehouse. We need to shift to a paradigm that draws from modern distributed architecture: considering domains as the first class concern, applying platform thinking to create self-serve data infrastructure, and treating data as a product.
Designing data products

Working backwards from the end goal is a core principle of software development, and we’ve found it to be highly effective in modelling data products. In this article we'll explore a step-by-step, methodical approach to identifying data products that avoids overdesign while providing just enough clarity for teams to begin implementation. Starting with a use case, we work backward to define data products and establish their boundaries. By overlaying additional use cases, we generalise the data products to prevent overfitting. Finally, we assign domain ownership and define service level objectives to guide the architecture and implementation.
Governing data products using fitness functions
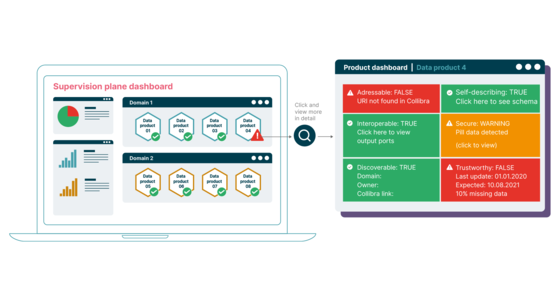
Decentralized data management requires automation to scale governance effectively. Fitness functions are a powerful automated governance technique we've applied to data products within the context of a Data Mesh. Since data products serve as the foundational building blocks (architectural quanta) of a data mesh, ensuring robust governance around them significantly increases the chances of a successful data mesh transformation. In this article, we’ll explore how to implement this technique. We'll start by designing simple tests to assess key architectural characteristics of a data product, and then we'll explore how to automate their execution by leveraging metadata about the data products.
Data Mesh Accelerate Workshop

To accelerate means to move faster, to gain speed. Effectively working with data is key for any organization that wants to thrive in the modern world, and Data Mesh is showing organizations how to realise value from their data, at scale. The Data Mesh Accelerate workshop helps teams and organisations accelerate their Data Mesh transformation, by understanding their current state and exploring what the next steps will look like.