
tagged by: application integration
Enterprise Integration Using REST
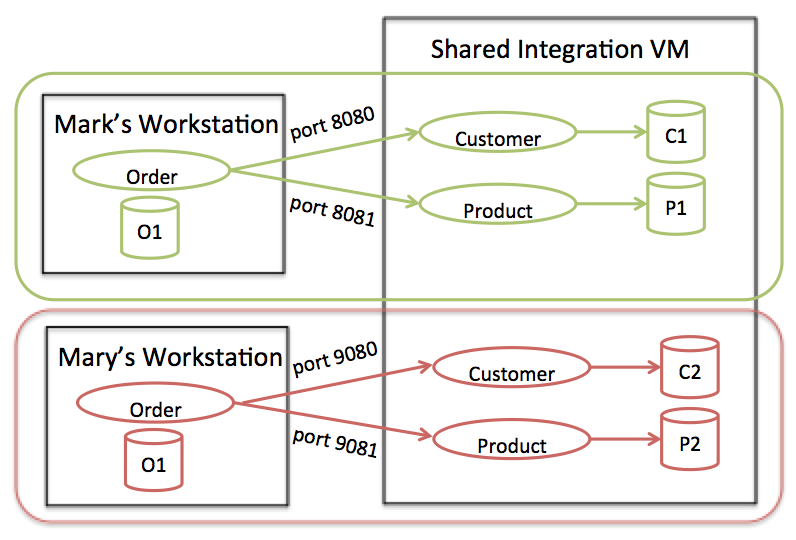
Most internal REST APIs are one-off APIs purpose built for a single integration point. In this article, I'll discuss the constraints and flexibility that you have with nonpublic APIs, and lessons learned from doing large scale RESTful integration across multiple teams.
Richardson Maturity Model
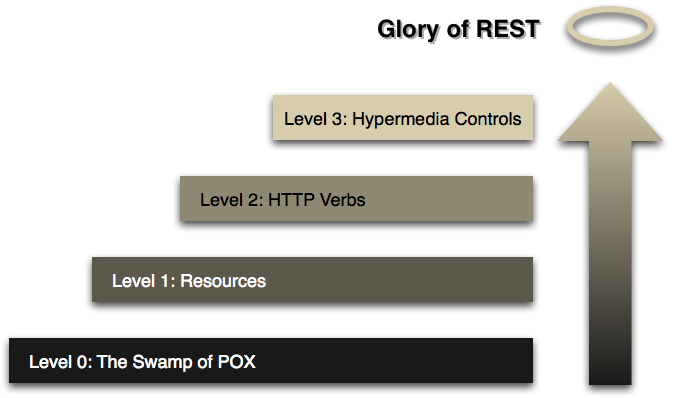
A model (developed by Leonard Richardson) that breaks down the principal elements of a REST approach into three steps. These introduce resources, http verbs, and hypermedia controls.
Function calling using LLMs

While LLMs excel at generating cogent text based on their training data, they may also need to interact with external systems. Function calling allows them to construct such calls. The LLM does not execute these calls directly, instead it creates a data structure that describes the call, passing that to a separate program for execution and further processing. The LLM's prompt includes details about possible function calls and when they should be used.
The strong and weak forces of architecture
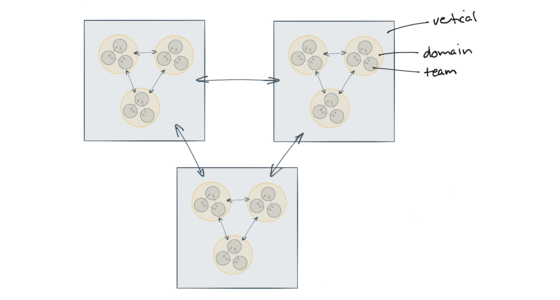
Good technical design decisions are very dependent on context. Teams that regularly work together on common goals are able to communicate regularly and negotiate changes quickly. These teams exhibit a strong force of alignment, and can make technology and design decisions that harness that strong force. As we zoom out in a larger organisation an increasingly weak force exists between teams and divisions that work independently and have less frequent collaboration. Recognising the differences in these strong and weak forces allows us to make better decisions and give better guidance for each level, allowing for more empowered teams that can move faster.
You Can't Buy Integration
Commercial integration tools are a couple decades old now, but there has been little in the way of overarching architectural principles describing when and how to use them. In this article, I argue that “buy” decision mechanics have caused us to exaggerate the value proposition of such tools, often leading to mandates to use a certain integration tool over a general purpose language. I claim that such tools thrive in a world that views integration as primarily about connecting systems, but that digital organizations have reimagined integration to be primarily about putting clean interfaces in front of digital capabilities, emphasizing capabilities over systems. Finally, I list some of the key principles behind a modern view of integration and claim they are best managed with a general purpose language, reorienting the primary value proposition of commercial integration tools towards simplifying tactical implementation concerns.
Does My Bus Look Big in This?
My colleague Jim Webber has built quite a reputation for taking a lightweight and business-oriented approach to integration in the enterprise. He also has a reputation for being a very robust and entertaining speaker. So I was as nervous as I was excited to share the stage with him for a keynote at QCon 2008. He put together a wonderfully funny presentation with some serious tidbits of meat woven through it. We then just dove in and did it - possibly helped by the pre-talk pint. We talk about the history of Enterprise Integration, the growth of systems that think they are strong but are really just fat, the role of agile thinking, the influence of the web (including Jim's unique theory on why it was invented), and how this leads to Guerilla SOA.
Consumer-Driven Contracts: A Service Evolution Pattern
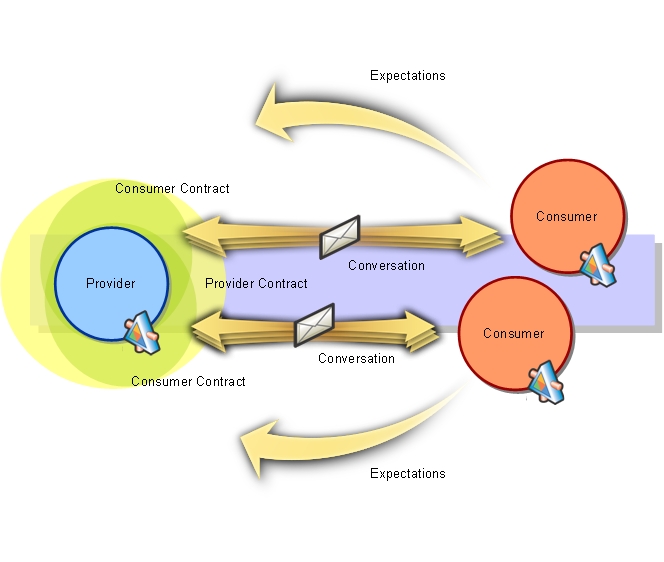
This article discusses some of the challenges in evolving a community of service providers and consumers. It describes some of the coupling issues that arise when service providers change parts of their contract, particularly document schemas, and identifies two well-understood strategies - adding schema extension points and performing “just enough” validation of received messages - for mitigating such issues. Both strategies help protect consumers from changes to a provider contract, but neither of them gives the provider any insight into the ways it is being used and the obligations it must maintain as it evolves. Drawing on the assertion-based language of one of these mitigation strategies - the “just enough” validation strategy - the article then describes the “Consumer-Driven Contract” pattern, which imbues providers with insight into their consumer obligations, and focuses service evolution around the delivery of the key business functionality demanded by consumers.
Schemaless Data Structures

In recent years, there's been an increasing amount of talk about the advantages of schemaless data. Being schemaless is one of the main reasons for interest in NoSQL databases. But there are many subtleties involved in schemalessness, both with respect to databases and in-memory data structures. These subtleties are present both in the meaning of schemaless and in the advantages and disadvantages of using a schemaless approach.
Application Database
I use the term Application Database for a database that is controlled and accessed by a single application, (in contrast to an IntegrationDatabase). Since only a single application accesses the database, the database can be defined specifically to make that one application's needs easy to satisfy. This leads to a more concrete schema that is usually easier to understand and often less complex than that for an IntegrationDatabase.
Bounded Context
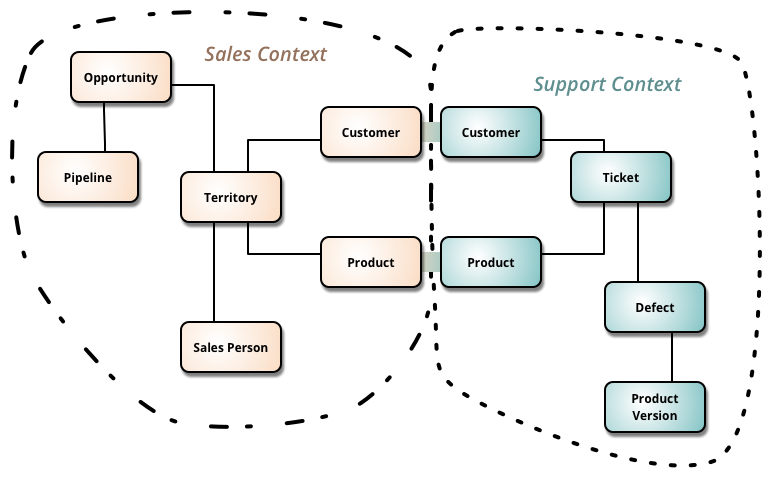
Bounded Context is a central pattern in Domain-Driven Design. It is the focus of DDD's strategic design section which is all about dealing with large models and teams. DDD deals with large models by dividing them into different Bounded Contexts and being explicit about their interrelationships.
Database Styles
When I talk about databases and how they relate to applications, I've found it useful to distinguish between two styles of database: ApplicationDatabase and IntegrationDatabase. The difference between the two lies in whether the database is controlled and encapsulated within a single ApplicationBoundary.
Enterprise Application
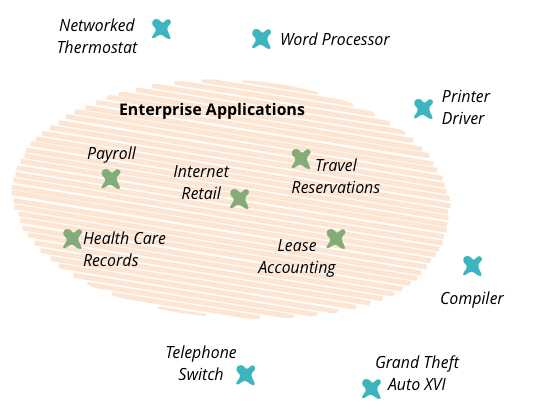
In the early part of this century, I worked on my book Patterns of Enterprise Application Architecture. One of the problems I had when writing the book was how to title it, or rather what to call the kinds of software systems that I was writing about. I've always been conscious that my experience of software development has always been focused on one particular form of software - things like health care records, foreign exchange trading, payroll, and lease accounting. These are very different to embedded software inside printers, games, flight control software, or telephone switches. I needed a name to describe these kinds of systems and settled on the term “enterprise application”.
Enterprise Architecture
Just recently I've picked up a couple of bad reviews on Amazon for P of EAA because there is nothing in the book about enterprise architecture. Of course there's a good reason for that - the book is about enterprise application architecture, that is how to design enterprise applications. Enterprise architecture is a different topic, how to organize multiple applications in an enterprise into a coherent whole.
Evolutionary S O A
Can SOA be done with an agile approach?
Humane Registry
One of the features of the new world of services that SOA-gushers promoted was the notion of registries. Often this was described in terms of automated systems that would allow systems to automatically look up useful services in a registry and bind and consume those services all by themselves.
Well computers may look clever occasionally, but I didn't particularly buy that idea. While there might the be odd edge case for automated service lookup, I reckon twenty-two times out of twenty it'll be a human programmer who is doing the looking up.
Integration Database
An integration database is a database which acts as the data store for multiple applications, and thus integrates data across these applications (in contrast to an ApplicationDatabase).
Multiple Canonical Models
Scratch any large enterprise and you'll usually find some kind of group focused on enterprise-wide conceptual modeling. Most commonly this will be a data management group, occasionally they may be involved in defining enterprise-wide services. They are enterprise-wide because rather than focusing on the efforts of a single application they concentrate on integrating multiple applications.
Provide Service Stub
An important thought for anyone building services for a service oriented architecture. When you build your service, also build a service stub that your clients can use to test against. Such a stub should provide canned responses to a fixed set of requests, simulate error conditions, and be runnable on a client's machine. You'll need to ensure that the stub mimics the true systems behavior properly. By providing a stub for your clients, you make it much easier for your clients to use your service; which of course means that your service is more likely to be used.
Service Custodian
Let's imagine a pretty world of SOA-happiness where the computing needs of an enterprise are split into many small applications that provide services to each other to allow effective collaboration. One fine morning a consumer service needs some information from a supplier service. The twist is that although the supplier service has the necessary data and processing logic to get this information, it doesn't yet expose that information through a service interface. The supplier has a potential service, but it isn't actually there yet.
Service Oriented Ambiguity
Whenever Thoughtworks rashly lets me out in front of a client, one question I'm bound to be asked is “what do you think of SOA (Service Oriented Architecture)?” It's a question that's pretty much impossible to answer because SOA means so many different things to different people.
Tolerant Reader
One of the benefits of using web services is that it helps you to decouple various parts of a system. People can work on separate code-bases with some degree of separation. Although you get some decoupling, you cannot eliminate the coupling completely because the services still have to communicate to each other through their interfaces. The sad thing is that many teams make this coupling much worse than it should be.