Recent Changes
Here is a list of recent updates the site. You can also get this
information as an RSS feed and I announce new
articles on Fediverse (Mastodon),
Bluesky,
LinkedIn, and
X (Twitter)
.
I use this page to list both new articles and additions to existing
articles. Since I often publish articles in installments, many entries on this
page will be new installments to recently published articles, such
announcements are indented and don't show up in the recent changes sections of
my home page.
Fri 31 Jul 2026 09:48 EDT
Rachel Laycock
TL;DR
Why I think software development is starting to feel a little more like conducting an orchestra.

There’s a shift happening in software development that I don’t think we’re talking about clearly enough.
For the last couple of years we’ve framed AI as a productivity tool. How much faster can it write code? How many more features can we ship? How much cheaper can we build software? I think that’s the wrong question, but I understand why.
The first thing AI became good at was writing code, so naturally that’s where we focused. As AI got better at coding, I expected the bottlenecks to move through the software delivery lifecycle: from coding to design and specification, architecture, then verification. And they have. We spent a lot of time at the most recent FOSE event discussing how we ensure good design, quality and resilience while agents increasingly write the code.
That’s a topic for another ramble.
A few months ago, though, I realised I was looking at the wrong bottleneck. I kept assuming it would simply move to the next phase of software delivery.
I was wrong.
AI didn’t change what great software looks like. It changed what’s scarce. Human attention is now the bottleneck.
The next bottleneck isn’t design. It isn’t verification. It’s us. More specifically, it’s our attention. Developers have always protected long periods of uninterrupted focus because that’s where good software gets built. Pair programming. Quiet afternoons. Deep work. We optimized around flow because flow mattered. When we didn’t get that time, very little got done.
But when I watch developers using AI today, I see something different. The best developers I know aren’t spending all day in flow anymore. They’re orchestrating agents.
Great developers are starting to look less like programmers and more like conductors.
I was watching Jacob Collier on YouTube recently because I’m hoping to see him in concert soon. Watching him conduct is fascinating. He’s not trying to play every instrument himself. He’s listening to the whole piece, hearing what doesn’t quite fit, bringing different voices in at the right moment, changing the energy, changing the tempo and shaping the performance as it unfolds. Increasingly, that’s what great software developers look like.
A great conductor is first and foremost a great musician. They could play the instruments themselves. That’s not why they’re standing on the podium. Their value comes from understanding the whole score. The orchestra doesn’t need the conductor because the musicians aren’t talented enough. It needs the conductor because someone has to hold the whole system in their head. Increasingly, I think that’s what great software developers are doing.
The AI agents are the musicians.
The developer is the conductor.
They’re deciding which agent should tackle which problem. They’re providing context. They’re evaluating what comes back. They’re spotting subtle mistakes. They’re deciding what deserves another iteration and what is ready to move on.
I was talking to an engineer recently who told me they regularly have eight AI agents running in parallel. I’ve heard similar numbers from others. Ten. Twelve. Beyond that, they become the bottleneck.
Eight.
That number stuck with me because it sounded remarkably familiar. It sounded like my job.
As CTO, I rarely produce the work myself anymore. Instead, I have lots of streams of work progressing at once. A strategy document comes back for feedback. A client opportunity needs a decision. Someone wants guidance on a technical trade-off. Another team needs context before they can move.
None of it arrives neatly packaged. It comes as conversations, emails, documents, chat messages and half-formed ideas. My job is to decide where my attention belongs, make sense of incomplete information, provide context and help other people make progress.
When I first became CTO, I thought I needed to get better at managing my time. I was wrong.
What I really needed to learn was how to manage my energy. The challenge wasn’t the hours. It was the constant context switching. The endless stream of decisions. The feeling that nothing was ever completely finished.
An executive coach taught me some things I’ve never forgotten.
Protect your attention.
Manage your energy.
Reduce unnecessary decisions.
Create systems that help your brain, not just your calendar.
Lately I’ve been wondering whether developers are about to need exactly the same capabilities. A few weeks ago I shared this thought with our Chief People and Leadership Officer. His response surprised me. “I knew something fundamental was changing,” he said. “I just didn’t know how to help. Now I do.”
That conversation stuck with me because we’ve spent decades helping executives succeed in this kind of environment. We coach them to make decisions with incomplete information, manage cognitive load, prioritize relentlessly and protect their energy. Yet we’re still preparing developers for a world of individual execution. We’re redesigning the tools, but we haven’t started redesigning the job.
I don’t think software developers are becoming managers. I don’t think AI is replacing engineering. I think engineering expertise is simply being applied in a different place, and much more often, because execution has become so much faster.
(I suspect software developers are simply the first knowledge workers to experience it, but I’ll save that thought for another rambling.)
The question I’m most interested in now is this:
How do we redesign engineering careers when human attention becomes the scarce resource?
When I became an executive, learning to manage my own energy was one of the hardest things I’ve ever done. Even today, if I stop paying attention to it, I pay the price.
I have a feeling software development is about to demand those same capabilities from many more people.
And I don’t think we’ve quite realised how profound that change is.
Thu 30 Jul 2026 09:04 EDT
Martin Fowler
Giles Edwards-Alexander does an experiment to see if decomposing a
large function helps reduce token costs, suggesting that is may now be
possible to measure the economic benefit of refactoring
more…
Tue 28 Jul 2026 09:10 EDT
Martin Fowler
Subagents get justified by time saved and parallel execution, but
Rahul Garg explains that's not what matters most. Every
token in the orchestrator's context is competing for its attention, and
the real value of a subagent is what it keeps out of that context.
Subagents should be treated as a tool for protecting the orchestrator's
working memory, offloading reasoning it doesn't need to hold onto. Doing
this well means giving the orchestrator explicit ground rules for when and
how to delegate.
more…
Tue 28 Jul 2026 08:32 EDT
Rachel Laycock
TL;DR
I have ideas. I haven’t been writing them. That’s about to change. I promise… myself.
I’ve been thinking a lot about talent. Actually, I’ve been thinking a lot about thinking. And writing. Or more specifically, not writing. This really hit me earlier this year at the Future of Software conference. I was surrounded by people sharing their latest ideas and I had a slightly uncomfortable realization:
I have my own.
Not just opinions. Actual patterns. Hypotheses. Things I’m seeing across clients, across teams, across the industry that feel new or at least not well articulated yet in a way that a leader can think about and act upon in some way that can influence how they strategise and plan for the future. Because helping clients and other leaders internal and external to thoughtworks do this is actually a big part of what I do and without letting my northern humbleness get in my own way, I’m actually pretty good at it. If I wasn’t I wouldn’t be the global CTO of a future thinking tech org, you know the kind that has Martin Fowler as its Chief Scientist. A title I know he loves… Martin, by the way, is one of the people pushing me to do this, which is weird because on paper I’m his boss but I don’t believe in the traditional idea of a boss anyway. I’m a strong believer in the servant leadership type but I’ll save that for when I write about that.
Anyway the point is for all the ideas I have and discussion I have I don’t do a good job of writing it down. At best I’ll stick it in a presentation deck when I’m forced to communicate with them in some forum or another. I hate decks and love writing so I’m obviously doing something wrong.
So why haven’t I been writing? It’s easy to say I’ve been too busy. I don’t have an easy job. It’s a fun one but not easy. I also have two small children, 5 and 8. In case you are interested, I attempt to give as much time as possible to this busy job. And then I try to have a life. I’m also writing an epic world building sci-fi fantasy book which is a huge passion project I may also share more about so I am definitely busy. But that’s not actually the real reason I haven’t been writing this down and pushing it out publicly. The real reasons…
- I overthink it.
- I move too fast to the next idea.
- I’ve convinced myself it needs to be more polished than it does.
So this is an experiment.
Rachel’s Ramblings is exactly what it sounds like. Fast, imperfect, thinking out loud. Naming ideas early rather than waiting until they’re fully formed. Because the reality is, most of what I do day to day isn’t answering known questions. It’s spotting patterns and asking questions we haven’t quite figured out yet.
My brain works a bit like a knowledge graph. Constant associations, constant pattern matching. That’s useful in conversations, in client work, in strategy.
It’s less useful if it never gets written down.
So this is me fixing that.
I’ll write about:
- what is the future of software
- how software development is changing in the age of AI and what that means for engineers, leaders, and organizations
- how platforms, agents, and people actually work together
- and occasionally, how I manage the reality of doing this job with all the other things I have going on
Some of it will be wrong. Some of it will evolve. That’s the point.
If nothing else, this is a forcing function to turn thinking into something that exists outside my head.
Let’s see where it goes.
Tue 21 Jul 2026 06:13
Martin Fowler
With this post, I’ll wrap up my notes from the second Future of Software Development Retreat. But before I do, I should note that the full Thoughtworks report on the retreat is now available. They have five headline findings:
- Code generation is no longer the bottleneck — verification is.
- ‘Harness engineering’ is emerging as a distinct, ownable discipline.
- Organizations are colliding with a real apprenticeship crisis.
- The executive/engineer expectation gap is a bigger risk than any technical
limitation.
- Legacy modernization is the clearest, most defensible near-term value pool.
❄ ❄
A session convened around the mismatch of views about using LLMs between engineers using it and the C-suite and boards that were calling for it. The concern is that boards are looking at promised productivity gains, and not concerned enough about the risks, particularly about security.
This was illustrated by one tale of a company that used ML-trained software to optimize the replacement of air filters on their field equipment. They were pleased to see that they were able to change the air filters less frequently, saving them $50 million. But the problem was the ML models were trained on equipment used in the desert, while their equipment was used in the arctic. Air filters in the desert deal with dust, but in the arctic the thing to remove is mosquitoes. There’s an important difference here, mosquitoes rot, and enough decaying mosquitoes is a serious fire risk. Fires from such dead mosquitoes around infrequently replaced air filters cost the company $100 billion.
Now such a tale could told of many situations without AI in the mix. Plenty of human situations have gone wrong when solutions are applied in a new context (which is why context is such a key word among pattern-writers). But the tale does remind us to be wary of an AI’s suggestions, and to always think of how to build sensors to provide rapid feedback.
Engineers particularly worry about the risks when citizen developers start vibe coding. In many ways, of course, this isn’t new. I.T. folks often worry about how many important business decisions are based on spreadsheets, that are built with little control, testing, or assessment of data quality. Vibe-coding amplifies these concerns, so companies need a range of controls to guard against security breaches. Some folks have made a point of raising issues at board level, running threat modeling session with board members to introduce them to the risks. Vibe-coded applications need to be put in separate infrastructure, which deterministic controls over data access to tame the lethal trifecta. One company encouraged widespread vibe-coding from citizen developers but recoiled from the problems of the huge shadow IT that emerged - they are now looking to build a platform to help control this work without stifling the useful tools that were produced.
Part of the problem here may be simple experience with LLMs. Many in management find LLMs do a decent job of preparing management reports. Or summarizing management reports prepared by other LLMs. Given this they naturally think LLMs must do a decent job of programming too. My anti-management self has to mention Kelsey Hightower’s observation:
The less busy work you have the less appealing these Al tools are
One possible antidote to this: get the legal department involved. They see LLMs doing a poor job, and appreciate the risks involved.
❄ ❄
Most folks I talk to, both at the retreat and outside, recognize we are in some form of bubble. Technological advances like this almost always come with economic bubbles, and in the future we will all look back at this, and shake our heads saying we knew there was so much froth. But while it’s easy to see that there is a bubble, it’s hard to see how long it will run or what will emerge after the pop. After all the dotcom bubble was clearly recognized as such… in 1995. We can happily point at those companies that failed (Webvan, pets.com) but need to then acknowledge those that survived (Amazon).
Most of those at the retreat were old enough to have lived through the dotcom bubble and crash, but one such grey-hair pointed out an interesting difference. Back then we were excited about what the future would bring, and we saw lots of new things being built. There’s much less of that, this time around. Most people are wary of what the AI bubble is creating. Partly this may stem from the reality that followed the dotcom hope. Social media may be everywhere, but do we think it’s actually improved our lives that much, even if (especially if?) we use so much of it?
We hear so much about the incredibly productive things we can do with agentic programming, but has anyone noticed a flood of wonderful applications built with it? Or have we noticed a significant improvement in common applications from the big AI boosters such as Google or Microsoft?
This may be another factor in the board-vs-engineer divide. Most of what’s driving adoption of AI at the moment is cost-cutting, and it mostly the boards that get excited by cost-cutting. Perhaps the increasing concerns about token costs will temper the eagerness.
❄ ❄
Folks are finding LLMs helpful in operations: with a good event stream from observability tools, an agent finds anomalies much faster. One of the problems with citizen-developer apps, is that they often don’t provide good observability, since the citizen-developers don’t think to ask for it. The agents ability to look at the event stream does pose governance questions, as often such event streams contain a lot of sensitive information.
Reinforcing what I’d heard in Utah, more people agreed that LLMs are valuable for operations folks to help them understand what the code does. Cross matching code and event traces helps them assist humans to find what happened when things go wrong. Agents are particularly handy with repeated incidents, as they can collate lots of information from different cases and present it to the human teams.
Getting agents to auto-remediate moves us to the next level of capabilities and concerns. It’s vital that agents carefully document all their actions when they do fixes. We also need to ensure there is feedback to the development team so they can learn. Agents don’t learn, the best they can do is update the context.
There was a sense that many people over-estimate the capability of agents to deal with incidents. Such people think of incident resolution as a simple, linear process. But it’s rarely that, instead there’s a lot of surprises and adaptation needed. Humans are good with that, but LLMs are not.
One of the perils of agent-developed code is their habit of inserting features that were never asked for. One team spent three days trying to figure out such an unrequested feature, trying to figure out who had requested it and if anyone wanted to keep it.
❄ ❄ ❄ ❄ ❄
A group of law professors carried an interesting experiment to judge how well an LLM can provide short answers to student questions. They created a batch of forty questions in contract law and asked the professors, plus a couple of LLMs, to provide answers. To evaluate the LLM answers they showed professors pairs of answers - one human, one LLM - and asked them which response they would prefer to deliver to a student.
Professors rated LLMs far higher than their peers (average win rate = 75.33%), with models performing similarly to the best instructor. LLM responses were also rarely flagged as harmful (3.53%, vs 12.06% for professors).
This reminds me of the distinction I mentioned in a recent fragment between interactional and contributory expertise.
❄ ❄ ❄ ❄ ❄
A few days ago Unmesh Joshi published an article here about his experiences using DSLs to enable more reliable use of LLMs. Responses to this included a pointer to an article by Spender Nelson that related similar impressions.
DSLs like this hit a lot of sweet spots for LLMs. You can make them extremely token efficient, and enforce hard security boundaries. You can translate high-level LLM intent into a ton of deterministic code, ensuring good behavior and guardrails at the (custom) compiler level.
And Large Language Models are very good at learning and working with DSLs. Maybe this shouldn’t come as a surprise; they are language models after all. A small bit of documentation generally is enough to set them off and running, and reasonable error messages let them course-correct even when they go wrong.
He describes a couple of examples from their use: a query language for data lakes that takes into account security and authorization issues, and a little expression language to make it easier to create safe SQL where clauses.
One of the biggest barriers to using DSLs, particularly external DSLs, is building a parser and tooling. LLMs make this much easier. That said, my sense is that it’s the semantic model that underpins the DSL is what really matters, and the DSL is one projection of that model. LLMs may help us explore other ways to project that model in interesting ways.
❄ ❄ ❄ ❄ ❄
In recent weeks I’ve been noticing the stench of LLM-speak more and more. It’s not just the common tells, it’s a sense of LLM miasma that pervades the prose. I’ve noticed it’s increasingly eliciting a visceral reaction, after a couple of paragraphs I just want to dismiss the entire article out of hand. For some of these, it was necessary for me to hold my nose and wade through the whole text, but it was with an intellectual nausea which obscured the content, even increasing my desire to indulge in such an awful distraction as checking social media.
I wonder - is this just me that’s reacting so negatively to LLM-speak? Or do other people have a reaction that leads them to toss aside any prose that sets off their LLM-alarm?
One indicator that it’s not just me is this post from Jason Koebler that I highlighted a couple of months ago, where he observed how AI was breaking his brain:
People think things that are fake are real, things that are real are fake. Much has been written about “AI psychosis,” the nonspecific, nonscientific diagnosis given to people who have lost themselves to AI. Less has been said about the cognitive load of what other people’s AI use is doing to the rest of us, and the insidious nature of having to navigate an internet and a world where lazy AI has infiltrated everything. Our brains are now performing untold numbers of calculations per day: Is this AI? Do I care if it’s AI? Why does this sound or look or read so weird? Does this person just write like this? Is this a person at all?
A while ago, I was thinking that it was reasonable for folks who aren’t as committed to writing as I am to use an AI to help polish their prose. Now I’m turning to encouraging writers to reject it. That pervasive LLM-voice is just so common now, my sense is that it discredits the writing even before the reader has a chance to try to understand what is being said. I don’t think it’s good enough to ask the LLM to write a first draft and then tweak it. I’m not sure writers can edit the LLM-ness out of prose once it’s in there. I even worry about asking an LLM to suggest improvements,
I think it’s just too easy to accept an LLM’s suggestions, and in the process trigger your readers’ LLM-antibodies.
Of course like most problems, it’s also an opportunity. Those who can get a distinctive human voice will get more visibility and credibility. But the question remains of how we can coach people to let out their true personality into their writing. Academic and corporate writing both tended to stifle engaging prose, LLMs are good amplifiers, and they will amplify this stifling. This is an even greater challenge for those for whom English is their second language (or indeed for many of my colleagues, their third or fourth). It’s too easy for me to neglect to think about a difficulty that I’ve never been able to face.
The most immediate advice I can give something I learned many years ago and shared last year - Say Your Writing.
Once you’ve got a reasonable draft, read it out loud. By doing this you’ll find bits that don’t sound right, and need to fix.
I always suggested this to help people get past sluggish prose, especially if they had spent too much time around academic or corporate writing. But now I think the need to Say Your Writing is even more important, in order to combat the insidious impact of AI. For most people, their speech patterns get closer to their real self, so verbalizing writing is the way to fight those forces that try to smooth away a writer’s individuality.
Thu 16 Jul 2026 09:25 EDT
Martin Fowler
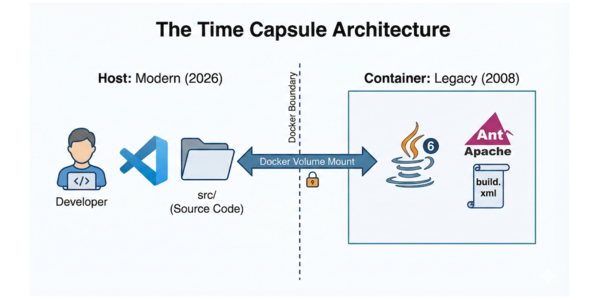
When people think of legacy modernization, most folks aren't imagining
the target environment will be Java 8. But this was the challenge facing
Nik Malykhin when he needed to run a Java 1.5 codebase on
today's hardware. His early use of LLMs gave plausible answers that did
not hold up in the codebase. Progress came when he grounded the process in
evidence, using AI to support analysis, validation in a stable Docker
environment, and gradual refactoring protected by tests. The main takeaway
is practical: AI was most useful when constrained by evidence, clear
roles, and a step-by-step modernization strategy.
more…
Tue 14 Jul 2026 08:51 EDT
Martin Fowler
LLMs generate code incredibly fast, but to ensure they generate
exactly what is intended, they need clear boundaries. Abstractions and
Domain-Specific Languages (DSLs) provide a strong harness that guides LLMs
right from the start. Unmesh Joshi describes how the example
of Tickloom - a domain model and DSL for illustrating distributed system
behavior - shows how we can use an LLM as a partner to iteratively build a
DSL and as a natural language interface to use it. Such a DSL can act as
the key source of truth for software systems in the world of LLMs.
more…
Mon 13 Jul 2026 08:51 EDT
Martin Fowler
Some more of my notes from Thoughtworks Future of Software Development Retreat.
When we had our first retreat in Utah early this year, nobody had heard of Harness Engineering. This time we had a whole session on it.
When comes to the guide side of harnesses, most of the discussion is about context management. While context windows have increased is size as models get more sophisticated, that doesn’t mean that models will properly focus on the right bits. Models typically only focus attention on part of the context, and to get the best behavior, we need to manage that focus. One attendee keeps their context small, limiting the agents.md file to less than 200 lines
On the sensor side, we see more attention on computational sensors. Two patterns from one participant was shifting to languages with greater controls, (eg Rust rather than Python) and “leveling up” validation approaches, using more property-based testing and techniques from formal methods. One commented that while they aren’t smart enough to write specifications in a formal specification language, they are smart enough to read it and check it makes sense for their domain.
Will our attention on harnesses last long enough for our next retreat? Will the models just get so good that harnesses become unnecessary? Those with some mechanical sympathy for LLMs seem to think not - but are they overly coupled to the current state of technology? I find such speculation tends not to lead anywhere useful, I’ve not seen much success in guessing the future in the past, and with technology as radical as this, I don’t see it being any easier. So for the moment, attention to harnesses pays off. We find it reduces token usage, and also allows weaker models to be useful, supporting such things as local hosting of open-weight models.
❄ ❄
Which naturally segues me to a session on self-hosted models. Increasing token costs have made hosting an open-weight model more attractive, particularly due to the decreasing time for open-weight models to catch up with frontier models. Cost isn’t the only factor, however, many folks find a desire to be independent of the frontier model firms to be the the driving force. After all we’ve seen the U.S. government intervene to deny access to models, increasing the desire for greater model sovereignty. Information security is also something to consider, some attendees just can’t give models necessary data for critical work. Even without that, if someone else hosts the model then their model learns rather than your model. And although recent events have increased interest, several participants worked with companies that had been self-hosting for up to a couple of years.
Is this trudging down the same path of self-hosted clouds, which led to lots of folks spending excessive funds on half-arsed private clouds? The answer hinges upon whether it ends up being simpler to host a model than a cloud, perhaps due to a simpler interaction protocol. The hard part of this may be the talent required to efficiently use the GPUs, managing an inference data center currently isn’t a widely available skill. Even self-hosted models are a cost to operate, capital costs in GPUs, ongoing costs in electricity. The physical design of a data center can affect optimal usage. There’s an opportunity here for professional services firms to help companies manage this.
Cost control also involves teaching people to pick the right model for the job. Can we teach engineers, or indeed other users, to pick a less-powerful model? This, of course, could be a job for model itself, acting as a broker, deciding which model is the best choice to tackle certain jobs.
Self-hosting may lead to a greater use of fine-tuning. Currently that’s a niche activity, but over time we could well find that models that are fine-tuned to a particular domain need less reasoning, consume less tokens, and thus are cheaper to operate. We are seeing models trained specifically to support programming.
As with any topic with this degree of uncertainty, the big win isn’t finding the right answer, but coming up with a strategy that will cope with the inevitable and unpredictable changes.
❄ ❄
After an event like this, many people come up to me and ask me to make some grand summing up. I hate this, because I rarely leave these kinds of event with some grand narrative. Even after mulling on it afterwards (in writing the above notes) I still usually don’t have one, and distrust one that forms, as my skepticism includes attempts to make coherent narratives of an event that’s naturally rather jumbled.
However my failings are irrelevant this time, because Kief Morris has put together such a narrative, and it’s a convincing one, even to a narrative-denier like me.
The sessions had different titles and different casts, and on the surface they were about different problems.
But they weren’t. Nearly every one of them was a different facet of the same argument. How much do we let an agent decide, and how do we stay confident in what it does?
He looks at code review, questions whether it matters, but sees that the rigor that many associate with code review shifts to other forms. He describes the disagreements about how much we should trust an agent to identify and fix production incidents. He sees that the contrast between how much leeway teams give to agents depends on the context they are operating
Underneath all of these sessions, the operations debate, the wide-remit team, the dark-factory spectrum, the argument about who’s allowed to steer the model, people were making the same handful of choices over and over about a single thing: the unit of work they were prepared to hand to an agent. How big it is. How much of the job it covers. What you do to get it ready to hand over. How you check what comes back. What you put around the agent to keep it inside the lines. Different rooms set those differently, but they were setting the same controls.
❄ ❄
Sam Ruby convened a session called “Bring me a Rock”. The name evokes a particular kind of management dysfunction. The manager tells his underlings to bring him a rock, and then starts rejecting the results without explaining why (“no not that one”, “no not that one”) until eventually one rock matches the unstated expectation.
It names a manager who substitutes serial rejection for the work of saying what they want, and makes you pay for their unfinished thinking one rock at a time.
Sam had already written why he thought with LLMs, this changed from a slur to a defensible way to work. When its a bunch of tireless machines with endless patience, that return new rocks in minutes rather than days, then an approach like this (using the brainstorming register becomes a defensible way to work.
Sam described the discussion:
The room pulled it somewhere narrower than I’d framed, and the narrower place was the more interesting one: not how to explore by elimination but who should even be allowed to. Product managers, increasingly people managers, are reaching for these models directly, and seasoned engineers get measurably better results from them than untrained people do — so the worry followed. If expertise is what separates a good outcome from slop, should non-engineers be steering the model at all?
It’s a fair question, and I think it’s the wrong one, because it mistakes the act. When a manager reaches for an LLM instead of routing the work to the team that reports to them, they didn’t pick up a tool — they made a hire. And you don’t ask permission to manage your own team; a manager who decides a piece of work is better given to a new participant than to the existing one is doing the most ordinary thing a manager does. Framed that way, the permission question dissolves into an older, better-understood one — the one Drucker named in 1959: when the worker knows more about the specifics than the manager does, you manage by objective, not by method. The non-engineer steering an agent is exactly that manager, out-known by the thing they’re directing, and the slop the room feared is the old danger of managing by method when you should be managing by objective. The question isn’t may they hire? It’s do they know how to manage by objective? — which you can teach, hire for, and hold people to without anyone first becoming an engineer.
Sam’s article explores managing an LLM by objective, giving it a goal rather than a task. And Kief’s earlier point about the essence of the discussion still holds: how confident can we be that it’s done the right thing? We can outsource many things, but not the acceptance criteria, at some point there’s a human request and a human judgment on whether that request was properly executed. But the danger lies in important unstated objectives, unstated perhaps because they weren’t even imagined.
It’s easy to state objectives around desired functionality. Give me a an application that will examine my emails and form a todo list for today. But behind that simple statement is a thicket of unstated assumptions. We tend to assume The Genie won’t include any undesired functionality, perhaps deleting emails it thinks are unworthy of our attention. We assume it won’t let an email tell it to send private information to villain@evil.com. We have some hope here - we hear more experiences that suggest that recent models can do an excellent job of finding (and hopefully fixing) security holes. The careful precision of the machine outruns the sloppy if imaginative thinking in squishyware. Perhaps we can assume the genie can take care of some of our unstated objectives. Conformance tests (sensors) are more valuable than specifications (guides), but it’s hard to imagine all the conformance tests that are needed to say what shouldn’t happen.
Furthermore, building software is about exploration, finding out how a workflow can evolve as machines are embedded in the process. For a human to guide that process, we need some understanding of it. My sense is that model building is still important, and while I agree that the genie can take an active role in that construction, I don’t think the human can entirely outsource it. Even if the genie builds the model itself, it needs to teach us that model, because the model helps us imagine and communicate the goals, the objectives that we give to the machine.
❄ ❄ ❄ ❄ ❄
If you follow my feeds (which you probably do if you’re reading this), then you’ll know that Birgitta Böckeler has written a couple of memos on working with local models. She first looked the factors that influence how viable they are for programming, and then related some of her recent experiences evaluating such models.
As a nice, if accidental, complement to these, Sebastian Raschka wrote a detailed guide to his local model environment. Like Birgitta, he’s found the Qwen 3.6 model to be the current sweet spot for local agentic programming.
❄ ❄ ❄ ❄ ❄
Simon Willison shares a useful tip to save money while using the latest Anthropic Fable model
Tell Fable to use other models for smaller tasks, applying its own judgement about which model to use.
❄ ❄ ❄ ❄ ❄
Josh Comeau writes a blog and online courses for developer education, primarily front-end web material. His been successful for most of this decade but has found his online courses have had only ⅓ the sales this year. He attributes this to AI, partly as people worry if it’s worth spending money on a job that may not have a future, but also because AI can provide personalized tutoring.
ideally, it shouldn’t cost any money to learn stuff.
But I sorta worry about how this is supposed to work, going forwards, if there’s no incentive for people to make high-quality free content.
I’ve spoken to a few course creators now, and we’re all seeing the same trend. Revenue down 50%+. Fewer people engaging with our content. People switching to LLMs, which slurp up all of our work and regurgitate it, without consent or compensation.
It feels pretty bleak. 😅
❄ ❄ ❄ ❄ ❄
John Gruber is annoyed that Claude’s desktop app for MacOS in uses Electron.
Electron guarantees that an app feels just as wrong on all platforms.
He has some tasty invective for the folks at Anthropic with ties to the Electron platform.
Finding out that one guy — who is a senior Electron maintainer — has led the teams for the desktop clients for Slack, Notion, and now Claude is like discovering that it was one guy — whose family business was a distillery — who helmed the Titanic, piloted the Hindenburg, and then served as air traffic controller for Amelia Earhart.
The deeper question here is whether there should be a future for cross-platform front-ends in the world of agentic programming. There’s lots of evidence that coding agents do a great job of building the same thing in multiple languages and platform ecosystems. That should mean that the days of least-denominator cross-platform UIs are numbered - and that number is small.
❄ ❄ ❄ ❄ ❄
Dan Davies tries to draw a distinction between interactional and contributory expertise. Contributory expertise is that held by people who are doing the work to advance a field of study, interaction expertise is held by folks that spend time talking to contributory experts, building up a decent store of knowledge themselves, but not steeped in the day-to-day of the work.
it seems to me that there is an important distinction here, which is not any less important because the dividing line might be difficult to establish empirically, or even if that line turns out to be in a different place from where we guessed it was. As well as difficult cases where it’s not clear, I think we could also come up with cases where the distinction between interactional and contributory expertise would suddenly become very clear and important indeed – the ones where someone who was faking it got “found out”.
And so the question that I think is quite important is whether there is a similar kind of distinction between the kind of expertise that it’s possible for a machine to get by industralised consumption and interaction with a much larger corpus of literature than any human being could inhale, and genuine contributory expertise that could apply to entirely new situations outside that literature.
As a human, I’d like to think I’m more of a contributor than an interactor (especially given my increasing introversion), and thus relatively safe from being forced into obsolescence by silicon. But I’m also aware that my career is devoid of any original ideas, my skill is only that of someone who is good at selecting and explaining the ideas of others. (As Brian Foote put it more memorably: “an intellectual jackal with good taste in carrion”.) But there’s skill in being a good jackal too - and we don’t really know yet where the real boundaries of the LLMs will lie.
Wed 08 Jul 2026 07:57 EDT
Martin Fowler
Birgitta Böckeler now reports on her recent experiences
trying local LLMs for coding. She compares them using two standard
tasks, and tries out the most promising model for day-to-day use.
more…
Tue 07 Jul 2026 08:34 EDT
Martin Fowler
Birgitta Böckeler recently spent some time trying out
running local LLMs for some programming tasks. In this memo she outlines the factors that
influence how viable they are for the job.
more…
Mon 06 Jul 2026 08:53 EDT
Martin Fowler
Last week, Thoughtworks ran a second Future of Software Development Retreat, this time in Europe. As with the previous event, I’ll be sharing some fragmentary thoughts on this. There were five parallel streams, so I could, at best, only attend ⅕ of sessions. This isn’t an event that forms conclusions, rather one that allows those exploring to share what they’ve found, and their visions for the future. The bliki post lists all the writing I’ve run into on this, by myself and others. I’ll be updating it as more posts appear.
Giles Edwards-Alexander “noticed a real difference between the retreats”:
Where Deer Valley had hesitancy and a belief that there was something here even if we weren’t yet sure what it was, Engelberg had confidence: the value is here. As I explained to a colleague today, this was not a conference for true believers: the evidence is in.
What does the evidence say? Well, that was less clear. Some patterns and practices are emerging (one attendee had catalogued dozens of agentic engineering pattern libraries) but they are emerging. There is more work to do to truly establish what is effective, and when.
Greg Herlein felt similarly:
Reading the reports of the February event, when a lot of these same folks last got together, the conversation was about what agentic development might look like. Aspirational. More about what was coming.
This time? Everybody in the room was doing it. Shipping it. Not slides - production. The whole debate about whether this changes software engineering is over. People have stopped arguing about whether a while ago. They’re arguing about how, and the how is getting real.
On a more micro level, I noted two other things. Firstly, there was much talk now about harness engineering, when that wasn’t even a term in Utah - an example of how rapidly things are moving. Secondly people are now worrying about the cost of tokens, where before folks were wanting to do almost anything to incentivize people to talk to The Genie.
❄ ❄
A question that continued from Utah was whether architecture and design are still important. There seems to be two landmark hypotheses here, one is that The Genie has such a Galaxy Brain that we no longer need to care about such matters, it will handle as much spaghetti as we can throw at it. The other is, in Laura Tacho’s memorable phrase: “the Venn Diagram of Developer Experience and Agent Experience is a circle”. The point being that The Genie uses the same constructs to understand a code base that humans do, so things like good modularity and naming help it as much as it helps humans. Adam Tornhill’s writing is a good example of this viewpoint.
Tidbits from our session on this:
- to evaluate the value of architecture we need to focus on desirable outcomes. Internal design quality boils down to ease of change. The question is whether the lessons we’ve learned so far will continue for agents.
- a way to measure design quality is to look at token costs. If the same change requires less tokens that indicates a better architecture.
- a good architecture only shows its quality over time, we can’t easily measure it in the short term
- why did 3GL languages continue when things like 4GLs, UML etc not take hold? It’s because these programming languages hit a sweet spot of human comprehension of computation
- we’re at the first time ever where the computers care about code quality
- will future models write machine code directly? If so what will humans review or specify?
- we should beware of speculating about what LLMs may do in the future. Instead we need mechanical sympathy for our LLMs, so we can gain a sense of how they work and how best to use them.
- One workflow:
- take story from backlog
- talk it over with an agent
- once get an agreement, make an ADR for persistent record of spec
- generate a task list
- get agent to complete it
- we need abstractions to communicate with agents (echoing Unmesh Joshi’s thoughts on building conceptual models)
- we often find duplication in LLM generated code, together with mixing of concerns (eg intermingled domain and display logic) - even with a good harness
- get agents to generate explanatory documentation at the end of a session
- overnight quality checks with a report for humans to act on in the morning
- LLMs look at existing code, so if that code has problems, the LLM will amplify them
- we should be wary of drawing too many conclusions comparing LLM code with human code - human code varies enormously from team to team.
❄ ❄
In his account of the retreat, Mathias Verraes goes into the details of his perspective of these issues of software design. He adds another concern: we need good design as a hedge against the risk of dependence on AI. After all, we don’t know how high the costs may rise to. We see governments blocking access to models. We see popular opposition to AI campaigning against data centers and calling for regulation. How much can we rely on AI tools being available to maintain and extend our software in the future?
❄ ❄ ❄ ❄ ❄
Charity Majors has a post on the ethics of working with AI and does an excellent job of articulating how I feel about this topic. She outlines the harms inherent in AI, both in the creation of its models (training on stolen data) and in inference (slop, lack of accountability, skill atrophy). Her conclusion however, like mine, is that there’s no ethical gain from renouncing the use of AI and castigating those who use it. Such purity provides little practical help with a technology that is so powerful and so useful.
The way you show care is by showing up. The way you make the world a better place is by getting down in the muck and building it, using whatever skills and resources you have on hand. The way you drive change is you engage.
Yes, we are all complicit. Yes, we are all compromised. No argument. But what are you going to do with that feeling of conviction? Will you channel your discomfort into solidarity and action, or try to ease your conscience by removing yourself from the system? Which does more to help those being harmed?
Her suggestions on how to engage aren’t striking, but that’s hardly unusual. At the Future of Software Development Retreat I convened a session on this question, and nothing striking turned up there either. That said, I’ve never been much of an activist, so my imagination may be limited.
❄ ❄ ❄ ❄ ❄
Gergely Orosz has run into a case where an article of his was erased from Google search by a clearly fraudulent DMCA claim.
It seems that anyone can file a bogus copyright claim to get an article they don’t like removed from Google’s search index. This happened in this case. I have no information on who filed the copyright claim. Even less so on who claims to be the copyright owner? Because I am the only possible copyright owner!
He was able to find the DMCA complaint, it was made by “Ellie Piee” whose profile listed them as living on Bouvet Island, an uninhabited Norwegian dependent territory near Antarctica. It claimed Gergely’s article copied a New York Post article entitled “Band Leader Hits Winning Chord”. But Gergely’s article is “Inside Pollen’s Collapse: “$200M Raised” but Staff Unpaid”, and the two do not share a single sentence. There’s an obvious motivation for folks connected with Pollen to have done this, and I hope the resulting Streisand effect bites them where it hurts.
❄ ❄ ❄ ❄ ❄
404 media have a bunch of (paywalled) reports on the impact of companies realizing that token costs are getting out of control. They’ve acquired leaked Slack chats, internal dashboards, emails and other material from companies including Citi and Amazon.
Companies are urging staff to use less powerful models, or cutting off frontier models entirely. A dashboard indicates that one company has seen its token bill rise from $5 million in August 2025 to $15 million in May 2026, on track to spend over $120 million in the fiscal year.
404 earlier reported about Accenture taking steps to reduce token usage. The biggest problem wasn’t software engineering using agentic programming, but rather staff “chewing tokens” by using AI to do things like turning PDFs into presentation slides. They saw themselves, and their clients, grappling with exponential increases in token costs. Inevitably, after consulting firms spent time urging their clients to use AI heavily, they are now offering services to control these costs.
Another post says it appears that one way to reduce token costs is to get AI tools to speak like cavemen, using a skill/plugin.
There’s a good summary of all this on 404’s freely available podcast: The AI Tokenpocalypse Is Here.
❄ ❄ ❄ ❄ ❄
I share these thoughts just after the July 4th weekend here in America, indeed the Semiquincentennial. Historian Bret Devereaux celebrated this event with a careful reading of the Declaration of Independence, a document often talked about more than it’s read. Which is a shame since it is hardly very long, and its impact was remarkable, and not just in what is now the United States.
The Declaration of Independence was recognized as a radical, potentially explosive document at the time of its issuance, as we’ll see. And it was explosive: the world of 1775 was one dominated by monarchies with just a tiny handful of traditional republics (which we should not ignore!). It took a long time for the seeds of the declaration to spread, but the world it helped create is one where liberal democracies, while hardly universal (more people have always lived in unfree societies than free ones) represent the most economically and culturally dominant bloc in world affairs – something that had never happened before. The Declaration, in its way, remade not just the Thirteen Colonies, but slowly, surely, as water seeps through the cracks of rocks (or my floorboards, alas), it remade the whole world.
Devereaux shines a light onto the world of this text, illuminating its historic context, a world that is very different to the one anyone reading this grew up in. It’s assertions of a natural law that there is equality of rights among men and that governments ought to derive their powers from the consent of the governed would seem hardly worth stating now, yet were deeply radical in 1776. I’ve found that reading history like this has helped me understand how the world is, and gives me a broader perspective on the drama of current affairs.
Tue 16 Jun 2026 13:11
Martin Fowler
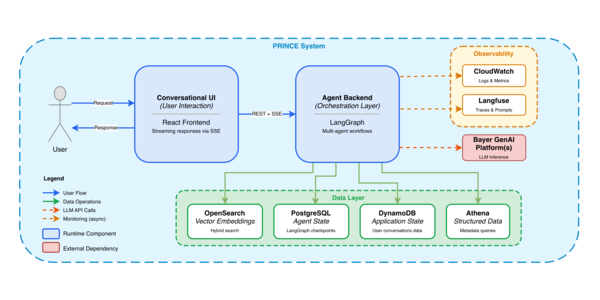
One of the most interesting projects my colleagues have done with LLMs
has been building a system with Bayer to allow pharmaceutical researchers to query
decades of information about studies buried in PDF reports. Sarang
Sanjay Kulkarni describes its evolution from keyword-based search
to an intelligent research assistant capable of answering complex
questions and drafting regulatory documents.
more…
Tue 16 Jun 2026 08:44 EDT
Martin Fowler
“Prag Dave” Thomas (co-author of the outstanding “Pragmatic Programmer”) has loved programming since he was young.
Programming was how I could express myself. I wasn’t an artist. When I sing, dogs howl. When I draw, friends say, “Very nice. What is it?” I didn’t connect particularly well with people, even though I wanted to. And yet, when I wrote my first program, I discovered a medium which let me convert thought into action. All the ideas that were bottled up behind a wall of frustration suddenly had an outlet.
The LLM revolution worried him. Would they remove all that fun stuff? Happily he found it was the opposite. Like Kent Beck and others have told me, programming with LLMs is more fun than ever. His post lists reasons why: removing drudgery, speeding up feedback loops, reviving long abandoned projects, and exploring new technologies.
❄ ❄ ❄ ❄ ❄
I’ve spent a few days at the DDD Europe conference, which was a very enjoyable event. With all the changes to programming due to LLMs, I suspect Domain-Driven Design is going to be one of those things that will continue to be useful, indeed may become even more important. The highlight of the conference was the opening keynote by Eric Evans, who gave a fascinating description of some of his experimentation with LLMs over the last couple of years. Once the video for that talk becomes available, I’ll link to it - hopefully it won’t be too long. I also particularly enjoyed talks from Violetta Pidvolotska, Kiran Prakash, Tom de Wolf, and Chelsea Troy. Gien Verschatse interviewed Eric Evans and me for an hour so so - again I’ll pass that link on when the video gets published.
One snippet that stood out to me was from Chelsea Troy. The main thrust of her talk was managing the context window of LLMs so that it was kept in a healthy state. Much of what she said was familiar, but one thing I hadn’t thought about was her thoughts about the different registers of conversations with LLMs. These registers are different styles of conversation we can have with The Genie (or indeed other humans). She classified them in four ways:
- Exploring: I want to understand before touching anything
- Brainstorming: Generate options, I’ll evaluate them separately
- Deciding: I need a recommendation with a rationale, not a list
- Implementing: The decision is made, help me build it
Her point is that whenever I have a session with an LLM, I need to be conscious about which register I’m using. And should I change register, I should start a new conversation with a fresh context.
❄ ❄ ❄ ❄ ❄
Charity Majors raises an alarm about the crevasse forming between AI enthusiasts and AI skeptics.
The enthusiasts are not wrong. We are starting to see real, non-imaginary, discontinuous leaps in capabilities from teams that lean in hard to working with AI. And this does not feel like a normal technology cycle where you can wait for the dust to settle; teams that sit this out while competitors are hustling could be out of business before the dust settles. That’s a real, existential threat.
The skeptics are also not wrong. When you ship code faster than engineers can read it, in domains where nobody has full context, you are making withdrawals from a trust account that took years to build. Reliability degrades, institutional knowledge evaporates. You end up with systems nobody understands, products burbling into incoherence, and on-call rotations that grind people up and spit them out. That is ALSO a real existential threat.
The heart of the problem is that there is no common feedback connecting these two groups. She posts some concrete ways forward. Enthusiasts tend to talk most publicly, and focus on the wins, but they need to tell the whole story, highlighting the costs too. We all need to look at working with AI as an engineering problem. Don’t just assume that we can or can’t ship code to production without review: instead ask what would make it possible to reduce review effort. She asserts that engineering discipline is becoming more important, echoing others who’ve observed that AI is an amplifier of our current practices. She wants us to avoid getting into arguments with maximalist stances and speculation, but stick to the reality we observe. Authority comes from engagement:
The engineers who shape how AI gets used will be the ones with credibility: they understand the opportunity, the stakes, and the tradeoffs, and they own enough of the consequences to have standing when they push back. Earning that position takes work, but it is work worth doing.
❄ ❄ ❄ ❄ ❄
Simon Willison noticed that Anthropic and Open AI have increased their enterprise pricing:
Why these sudden aggressive moves on pricing? Both Anthropic and OpenAI are planning to IPO, but I suspect there’s a more important factor here: I think they’ve finally found product-market fit, with the coding/general-purpose agent products embodied by Claude Code/Cowork and Codex.
His view is that since the November Inflection there’s increasing evidence that LLMs are making a big difference to programming, and this is translating to a viable business model for these companies. He suspects there’s another inflection point that happened in April:
I think April 2026 is a new inflection point where the revenue implications of this have started to land, to the benefit of the frontier AI labs and with material impacts on the budgets of large companies.
❄ ❄ ❄ ❄ ❄
Mike Masnick looks back at the internet’s failed promise of decentralization.
The early-internet conventional wisdom was that the network would kill the middleman. Yet the promised era of “disintermediation” never quite happened. What actually happened was that the middlemen changed character.
The pre-internet middlemen—record labels, book publishers, movie studios, magazine editors—were gatekeepers. Their entire job was rejecting 99% of what came through the door so that a curated few could reach an audience. The internet middlemen who replaced them did the opposite. Their approach depended on letting nearly everything through. They became enablers rather than gatekeepers, and an entire generation of cultural production—music, video, writing, podcasts—flowed through them in volumes the old gatekeepers couldn’t have imagined.
But the new middlemen still needed a business model.
That business model came from realizing that when content is bountiful, the new scarce resource is attention. The enablers built advertising machines to sell attention, and focused attention with algorithmic curation. Seeking to increase profits, the enablers rode down the road of enshittification:
The companies that embraced centralized control over the user experience did so initially because they were, in fact, making things better for their users. Information overload was a real issue. Having a better system for managing it was a good thing. It’s why so many people flocked to these centralized social media platforms and became so enraptured by their algorithms.
The problem of centralized systems is that they create an irresistible temptation to control and exploit. Users who found value early on feel stuck: they can leave, but doing so means abandoning their community. That lack of easy exit creates lock-in, and lock-in enables enshittification.
Masnick’s view is that we have to fight this process of digital despotism, realizing that decentralization, despite it’s ergonomic problems, is worth striving for as it’s the key to cognitive liberty. The key to achieving this is the user’s control over their data with the ability to easily move from one service to another. Ease of exit promotes competition, and competition is what pushes back against the ills of despotic centralization.
Truly decentralized tools push power to the ends. Users control their data and choose which intermediaries operate on it—and that arrangement is a poison pill to both enshittification and despotification. Any move in those directions only pushes users across the deliberately low barrier to exit, taking their content, data, and community with them.
The lessons of the past are important to guide our AI-enabled future. We need to create an environment that encourages decentralization and competition.
Tue 02 Jun 2026 11:21 EDT
Martin Fowler
Greg Wilson has noticed that lots of folks are using dodgy metrics to figure out if AI tools are worth their costs.
Would you measure lines of code generated, or tickets closed? Or would you send out a survey asking whether developers feel more productive? Each of those approaches is flawed in a different way;
He lists lots of common metrics, and why they are flawed. Sadly he doesn’t give any suggestions on what would be better. In my view, since we cannot measure productivity, any metrics are weak evidence at the best of times.
I do somewhat use one of his flawed measures: “Asking Developers If They Feel More Productive”. While I acknowledge the problems he gives with this measure, I find that in an environment where decent measures are hard to find, even such a dim light is the best we have. In this situation these kinds of qualitative metrics may not be conclusive, but they are useful.
❄ ❄ ❄ ❄ ❄
Benedict Evans observes that extensive automation didn’t mean the demise of professions in the past.
we spent a century automating accounting: we built calculating machines, punch cards, mainframes, data processing, databases, PCs, spreadsheets, ERPs, cloud… in fact, we built half of the tech industry around automating this. Yet the number of accountants kept going up.
He goes into the myriad of problems that exist when we’re trying to forecast the impact of a technology on jobs. There’s the much-talked-about Jevons paradox - once something becomes cheaper, people do it more, which can increase demand. Often this leads to the nature of jobs changing, even if it’s called the same thing.
Accountants today aren’t doing exactly the same work that they did in 1970 or 1980 ‘but more’ - they’re still called ‘accountants’ but the job is different. New technology often starts out being used for ‘the old thing but more’, but it rarely ends up like that.
Technologies often affect whole businesses - consider the impact of the internet on news publishing. Did anyone observing the rise of smart phones in the early 2000s realize that a consequence of this would change the economics of taxis due to the rise of ride-sharing apps? The conclusion is that it is, at the very least, almost impossible to forecast the impact of AI on our work.
❄ ❄ ❄ ❄ ❄
Stephen O’Grady looks at how closed and open models have performed on benchmarks over time.
Closed models are setting the pace of innovation, and constantly breaking new ground from a capabilities standpoint. Open models are chasing them, and the cycle times seem to be getting shorter. There are no clear capability moats, and what is frontier today is table stakes tomorrow.
It tooks 13-18 months for open models to catch up to GPT-4 on these benchmarks, but only 2-7 months to catch up to GPT-4o.
There’s a bunch of caveats to this analysis, that he lists, but it’s a worthwhile survey of how various kinds of models perform against the various measures we are trying to assess them with.
❄ ❄ ❄ ❄ ❄
One of the starkest examples of sloppy AI use is hallucinated citations - a give-away of both usage of LLMs and carelessness driving them. GPTZero is a company that makes tools to detect AI writing. I’ve no insight as to whether their tool is effective or not, but they do publish investigations of AI usage, and have published several articles highlighting hallucinated citations. One post focuses on Ernst & Young Canada’s report on cyber threats to loyalty systems and found that more than half its references were hallucinations. The post uses a lot of extremely annoying animations in how it presents its information (breaking Safari’s reader mode in the process). But the harm that these kind of AI generated reports can do goes further than just some misled humans:
Publishing a report online is essentially a form of data injection into the pool of knowledge that is the internet. When the report includes fake information (either vibed citations or false claims) it can “poison the well” by misleading future researchers, especially if the report is published by a well-known consulting firm and hosted on a high-traffic website.
❄ ❄ ❄ ❄ ❄
As LLMs get more capable in programming, we are rightly worried that people will use them attack software systems. But these models can also be used for defense, allowing teams to find bugs before attackers do. Some folks from Mozilla posted an article on how they’ve used AI model to identify and fix an unprecedented number of latent security bugs in Firefox.
Just a few months ago, AI-generated security bug reports to open source projects were mostly known for being unwanted slop. Dealing with reports that look plausibly correct but are wrong imposes an asymmetric cost on project maintainers: it’s cheap and easy to prompt an LLM to find a “problem” in code, but slow and expensive to respond to it.
It is difficult to overstate how much this dynamic changed for us over a few short months. This was due to a combination of two main factors. First, the models got a lot more capable. Second, we dramatically improved our techniques for harnessing these models — steering them, scaling them, and stacking them to generate large amounts of signal and filter out the noise.
During 2025, there were 17-31 security bugs fixed each month. In April 2026, they fixed 423.
❄ ❄ ❄ ❄ ❄
Pavel Voronin riffs on Unmesh Joshi’s post on What is Code. He observes that cruft in a codebase (technical debt) has always added friction to software development. But the consequences of this cruft are compounded when LLMs are using existing code as context for future work.
In a degraded codebase, the model does not see “technical debt” as debt. It sees examples. It sees precedent. It sees a style to continue.
LLMs multiply what’s currently happening. I hear reports that good code might take the place of much of what’s put in markdown, because LLMs will imitate what’s already in the code base. But bad code multiplies too. Inevitably he introduces another variation of rampant debt metaphors:
Cognitive debt accumulates when a team uses abstractions it no longer understands. Generative debt accumulates when a codebase contains confused concepts that models are likely to continue.
Cognitive debt is about what the team no longer understands. Generative debt is about what the model is now likely to reproduce.
❄ ❄ ❄ ❄ ❄
Jason Koebler, from the very worthwhile 404 media, has written a plaintive essay on how AI-generated slop is driving us crazy. Not just because its filling the web with this slop, but also because how it’s making us humans react to slop and the threat of slop. We review our own writing and notice: it’s not just reading AI slop that hurts us, it’s the risk that we write something that looks like AI slop. If I use phrasing that AI copied from me, does it seem like I’m copying AI? This has led to the appearance of “humanizers” - AI tools that make our writing look less like AI.
Humanizers add typos, randomly replaces words, removes “AI tells,” and sometimes inserts random characters.
It’s another step on the way to the Zombie internet:
I called it the Zombie Internet because the truth is that large parts of the internet are not just bots talking to bots or bots talking to people. It’s people talking to bots, people talking to people, people creating “AI agents” and then instructing them to interact with people. […] It’s my email inbox, in which I used to occasionally get poorly-formatted, poorly written, extremely long emails from delusional people who were positive the CIA had imprisoned them in a virtual torture chamber using undisclosed secret technology but where I now get well-formatted, passably written, extremely long emails from delusional people who are positive they have proven AI sentience and have the AI transcripts to prove it.
❄ ❄ ❄ ❄ ❄
Andy Osmani points out that spawning lots of agents is like launching a bunch of parallel processes that all rely on a single orchestrating thread - yourself.
Python has the Global Interpreter Lock (GIL). You can spawn as many threads as you want but only one executes python bytecode at a time because they must acquire the lock. You are the GIL of your AI agents. They all can run at once. But when any of their work needs genuine understanding of the architecture or resolving merge conflicts, that work has to acquire the lock. There is one lock. You hold it.
This means you must design the workflow with the agents with that GIL in mind. You shouldn’t launch more agents than you can properly review. It’s handy to separate background tasks that can be offloaded to an agent from complex tasks that require applied attention. Don’t use that precious brain for things that the machine can verify itself. [And I’d add - do get the machine to build tools that ease human verification. For example, it’s better to surface test case data in tables rather than buried in assert statements.]
Spawning agents is not the skill. Anyone can run 20.
The real skill is designing the system around the one serial resource that cannot be cloned or parallelized. That resource is your attention.
❄ ❄ ❄ ❄ ❄
Jamie Hurst is a Principal Engineer at booking.com, where he works in developer experience with a focus on AI tooling. He’s written realistically about the gains and losses of using LLMs in this work.
The cost of building has collapsed, but the cost of aligning organisationally has not. If anything, it’s gone up. When three different teams can each produce a working solution to the same problem in the time it used to take to write a proposal, the bottleneck moves from engineering to coordination.
He thinks he’s able to do more as a senior engineer, but is concerned about how sustainable it is, both for him personally and for the organization he works for. He’s able to shape directions for multiple workstreams at once, in a way that he couldn’t three years ago. But one loss is that he doesn’t have enough time for mentoring, which will exact a toll on his employer in the longer term. He also finds he doesn’t have enough time to think.
The productivity gains from AI got captured by output volume rather than output quality. The org’s expectations rose to absorb the speed-up, and the slack that used to exist between tasks, the unstructured time where strategic thinking actually happens, got eaten first because it’s invisible on a dashboard. I’m at a point in my career where thinking is supposed to be most of the job, and most of it now happens on holiday because the working week doesn’t accommodate it.
Wed 27 May 2026 15:40 EDT
Martin Fowler
At the GOTO Conference in Copenhagen in 2025, Kent Beck and I spent some time on stage talking and answering questions from the audience - a format I refer to as “two old geezers on a park bench”. We talk about our experiences with LLM-augmented programming (at that point - October 2025), we show our frustration that things we’ve been saying for thirty years still need to be said, we say how anything like a manifesto reunion needs to be led by a younger generation, and opine on what junior developers should be focusing on in their career.

❄ ❄ ❄ ❄ ❄
Ian Johnson has written a series of posts about restructuring a gnarly codebase
The story follows a real Laravel + React codebase over ~3 months and ~258 commits from a legacy monolith with no tests to a well-structured application with automated quality gates, a React SPA migration in progress, and an AI agent that reliably ships production code with minimal supervision.
The series covers the steps in decent detail, and his approach follows the kinds of steps I’d use. First get everything under the control of decent characterization tests, add static analysis, introduce the right patterns to make things flow easily.
With all of this, is his use of AI, which changed during the exercise:
For the first two months of this project, I used Claude Code with auto-approve turned off. Every file edit, every terminal command, every change… I reviewed it before it executed. […] The results were good. The code was clean. But I was doing most of the thinking and half the typing. The agent was a fancy autocomplete with better suggestions. I wasn’t getting the leverage I’d hoped for.
I read an article about “on-the-loop” versus “in-the-loop” human-AI collaboration. The framing clicked immediately […] I was micromanaging because I didn’t trust the agent to do the right thing. And I didn’t trust the agent because there was nothing forcing it to do the right thing.
His early steps put in tests, static analysis, and the right architectural patterns. With those in place, he could let the agent do more work.
My role shifted from writer to curator. I don’t write most of the code anymore. I Define the patterns […] Review the test specs […] Review the output […] Update the harness […] Make strategic decisions […]
He finishes the series with conclusions about how he’d generalize his experience to other circumstances.
❄ ❄ ❄ ❄ ❄
Back in the land of my birth, there was some notable groans when the National Health Service decided to close nearly all of their Open Source repositories, supposedly to the security threat of LLMs. Closing repos like this isn’t an effective counter to LLM-augmented attackers. I suspect it’s no coincidence to see GDS (Government Data Services), the highly-regarded IT enablers in the UK government publish their position
Moving code from public to private as a substitute for investment in secure-by-design delivery, ownership and remediation is a warning sign because it reduces sharing and scrutiny, can slow coordinated improvement across government and suppliers, and does not remove the underlying weaknesses in a running service.
Terence Eden memorably sums up his view on this:
Within the UK’s Civil Service you occasionally hear the expression “being invited to a meeting without biscuits”. It implies a rather frosty discussion without any of the polite niceties of a normal meeting.
❄ ❄ ❄ ❄ ❄
I’ve seen a few cases where those developers who are most involved in working with LLMs find they are running into a problem with cognitive endurance, Adam Tornhill has joined this group:
One of the big wins with agents is that they let us stay with the higher-level problem for longer. We get less sidetracked by details, dependency cleanup, and similar secondary tasks that used to break concentration.
But there is a cost we are still underestimating. Agentic coding is mentally expensive.
I can usually sustain the pace for a couple of hours. Then I need a break. The pace is simply too intense. And based on conversations with other engineers, I do not think I am alone in that.
He explains that working with The Genie means we are making more decisions in less time, this increase in decision density is hard on the brain.
He responds by keeping agent tasks small, automating everything he can, and accepting that he won’t know every line of code as long as he has good verification mechanisms in place.
Notably, he has not gone in the direction of doing his work with swarms of agents that he coordinates. Instead has one long-running task that he babysits and one focus task
That last point is important given the running-twenty-agents-in-parallel hype. I cannot even think about twenty meaningful things to build, and even less so about the resulting cognitive tax of the likely interruptions. It’s exactly the wrong thing to even consider. At least for humans. (And yes, I understand sub-agents and machine parallelisation. That is not what I’m objecting to. It is the parallelisation of human attention that does not scale).
I liked that he included some thoughts about what folks can do in time outside this intense programming time. Not just “have a coffee” (although he includes that) but also about learning about the domain that the software supports.
❄ ❄ ❄ ❄ ❄
A couple of pithy quotes from social media
Lorin Hochstein
“Metaphor debt” is when all of your metaphors involve the concept of “debt” because you can’t think of any other metaphors anymore.
❄ ❄
Daniel Terhorst-North
If a vegan crossfit fan is using Claude to write Rust, which thing do they tell you first?
❄ ❄ ❄ ❄ ❄
Karl Bode reacts to speakers getting booed when mentioning AI during commencement addresses. He points out that younger folks are increasingly unhappy with the tech oligarchy and their fruits.
The thing is the kids aren’t stupid. They see the field clearly. They see the difference between what’s being sold to them by tech companies, the press, and commencement speakers, and what they have repeatedly seen with their own eyes.
They’ve watched tech oligarchs spend the last decade mired in scandal after scandal, hype cycle after hype cycle, steadily enshittifying everything they touch along the way.
[…]
The percentage of Gen Z that think AI’s benefits don’t counterbalance the risks now sits around fifty percent, up 11 percentage points in just the last year. Eight out of every ten believe that using AI makes the process of actual learning more difficult.
He sees young people saddled with the perception of entering a worsening world -
which leads them to rage against this latest fruit of the tech oligarchy. A rage
that is easy for folks like me
- with a comfortable retirement off-ramp - to properly appreciate. A rage that could have marked political and social consequences.
❄ ❄ ❄ ❄ ❄
Relevant to these concerns are a couple of items in last week’s Economist newspaper. The newspaper argues that historically major technological advances haven’t led to significant unemployment or drops in wages (paywalled article). The closest was the original industrial revolution in 19th Century Britain. There was a stagnation in wages during this period, but there was also a massive increase in population, from 4½ million to 12 million.
It also points out that we’ll probably only understand the full consequences of all this when a recession hits, as this is when most unproductive jobs tend to be flushed out of the system.
A second article (also paywalled) indicates that AI is having some effect on graduate hiring. They did an analysis of surveys of recent graduates, looking to see if employment varied depending on a job’s exposure to AI. The least exposed quintile of subjects saw employment rate fall by 1.5% over the last couple of years, while the most exposed quintile’s drop was 6.6%.
❄ ❄ ❄ ❄ ❄
Lawfare isn’t impressed with the latest efforts by the US Government to regulate AI.
On [last] Wednesday, the White House invited leaders of OpenAI, Google, Anthropic, Meta, and Microsoft to the Oval Office for a signing ceremony the following afternoon. President Trump was to sign an executive order on AI and cybersecurity—the administration’s most formal effort yet to establish a voluntary process for reviewing frontier models before their release. But roughly three hours before the ceremony, when some company executives were already in the air to Washington, the White House called it off.
They see the proposed regulations as mild, and including some valuable measures to harden defenses against cyber threats.
But it’s worth underscoring the implications of postponing (if not outright canceling) this order, which, by its own terms, was about as modest a frontier-AI intervention as the federal government could put on paper: voluntary, focused on the government’s own defenses, and explicitly barred from becoming a licensing regime. The objection isn’t so much about government coercion as about the government having any settled role at all. Voluntary, in other words, isn’t the floor of frontier AI policy in this administration; it’s the ceiling.
This is a questionable position given that the concerns animating this draft order will likely grow in the near future. It is also self-defeating for those who applauded the order’s delay or demise. Far from resolving the risk of government meddling in AI, killing the order just leaves in place what Ball has described as the “opaque and essentially lawless” alternative: government access happening through back channels, on terms set case by case, with no stable rules at all.
One of the problems here is a distinct lack of governmental expertise, either in AI or in software in general. Too much is being decided at the whims of the tech oligarchy, there isn’t any attempt to engage in the broader issues at hand. That’s not entirely a bad thing, trying to regulate something that’s still evolving so fast is usually a fool’s errand - but the problem here is the impact of AI is so big that there’s real danger in being too far behind.
❄ ❄
Which leads me to a rare thing, an endorsement of a candidate for political office. If you are voting in congressional district MA-06 (North Shore of Massachusetts), I’d seriously look at Beth Anders-Beck, who is running for congress in that district. Beth has a long background in software development (including developing the notion of Forest and Desert), so would introduce expertise that Congress desperately needs. I’ve known Beth for decades, and have a high opinion of their intelligence, judgment, and ability to work with others. Congress doesn’t deserve Beth, but it does need her.
Wed 27 May 2026 11:01 EDT
Martin Fowler
Birgitta Böckeler finishes her post on sensors for
coding agents by examining the role of a test suite as a regression
sensor, focusing on the role mutation testing can play.
more…
Wed 27 May 2026 10:03 EDT
Martin Fowler
Vibe coding has significantly accelerated software prototyping but AI
agents frequently recommend insecure configurations, creating security
problems. Gautam Koul, Lucian Moss, Neil Drew-Lopez, and Daberechi
Ruth Edeokoh share their experience while building applications
for Thoughtworks's global marketing. They learned that to combat this we
need to write a security context file to guide the AI, be cautious with AI
permission requests, create a daily security intelligence feed, and
provide builders with a secure-by-default harness and templates.
more…
Thu 21 May 2026 07:49 EDT
Martin Fowler
Vibe coding is building a software application by prompting an LLM, telling it
what to build, trying it out, prompting for changes - but without looking at
any of the code that the LLM generates. This technique can be used by people
without any knowledge of programming. However the resulting software often
shows problems with maintainability, correctness, and security - so is best
used for disposable software written for a limited audience.
The term was coined in February 2025 by Andrej Karpathy, an experienced
programmer, in a post on X:
There's a new kind of coding I call “vibe coding”, where you fully give
in to the vibes, embrace exponentials, and forget that the code even exists.
It's possible because the LLMs (e.g. Cursor Composer w Sonnet) are getting
too good. Also I just talk to Composer with SuperWhisper so I barely even
touch the keyboard. I ask for the dumbest things like “decrease the padding
on the sidebar by half” because I'm too lazy to find it. I “Accept All”
always, I don't read the diffs anymore. When I get error messages I just
copy paste them in with no comment, usually that fixes it. The code grows
beyond my usual comprehension, I'd have to really read through it for a
while. Sometimes the LLMs can't fix a bug so I just work around it or ask
for random changes until it goes away. It's not too bad for throwaway
weekend projects, but still quite amusing. I'm building a project or webapp,
but it's not really coding - I just see stuff, say stuff, run stuff, and
copy paste stuff, and it mostly works.
-- Andrej Karpathy
The key point about vibe coding is “forget that the code even exists”.
This is what gives it much of its usefulness, but also its limitations.
Since the November Inflection many programmers are
getting LLMs to write all their code, commenting that they may never write a
line of code directly again. However they do care about this code, reviewing
it, paying attention to its internal structure. In that case, they aren't
forgetting the code exists, so it's really a different thing that I call
Agentic Programming. Sadly the term “vibe coding” really
caught on, so many people use it to mean agentic programming. However I feel
that despite this rapid Semantic Diffusion, it's worth
trying to keep the concepts of vibe coding and agentic programming separate,
as they are both different to use and different in their consequences.
Because a vibe coder doesn't look at the code, they don't need programming
skills, so it's perfect for someone with no programming knowledge to build
applications for their own use. Experienced programmers may also find it handy
for rapid development of disposable software or prototypes.
Vibe coding
is still new, so we are exploring its limitations, and those limitations
change as the sophistication of models and their harnesses change. These
limitations do introduce considerable risks, particularly if the vibed
software is used widely or has access to sensitive information.
Perhaps the most serious risk is that of security. LLMs are inherently
vulnerable as they provide a large attack surface for predators. Vibe coded
applications can often expose sensitive information or worse, credentials to
attack deeper into an organization's systems. Even non-programmers need to be
aware of the Lethal
Trifecta.
With little attention to the code, vibed software can rapidly produce
many lines of code of a very low quality. Such code makes it difficult, even for an LLM,
to modify and enhance the software in the future. While it's possible that
growing LLM capabilities will allow it to work with even the largest bowls of
spaghetti software, thus far it seems clear that well-structured software
makes life easier for LLMs too.
LLMs are famous for habit of hallucinating incorrect facts and presenting
these with great confidence. This habit also leads them to create software
that behaves incorrectly - and those errors may not be manifest to the user.
Furthermore the non-determinism of LLMs means that it's likely that asking an
LLM to enhance some software could easily lead it to introduce errors, even in
parts of the code that shouldn't change due to the new request. We should thus
treat LLM-generated software with skepticism, it can still be useful, but we
need to be aware of the risks.
On the whole vibe coding software is best used for disposable software
that's only used by its author or a close group of collaborators who
understand and accept the risks involved. Code that is more complex, more
widely-used, and with more consequences to its risks should not be forgotten about.
Wed 20 May 2026 10:27 EDT
Martin Fowler
Birgitta Böckeler adds discussion of three more
sensors for static code analysis, focusing on checking and enforcing
better modularity. Computational sensors for dependency checks were good
at enforcing rules, but the rules were limited. Building a computational
sensor for coupling data proved lackluster. Prompting an inferential
sensor to review modularity was more effective.
more…
Tue 19 May 2026 12:38 EDT
Martin Fowler
In her recent article about harness engineering for coding agent users,
Birgitta Böckeler laid out a mental model for expanding a
coding agent harness: a system of guides and sensors that increase the
probability of good agent outputs and enable self-correction before issues
reach human eyes. Birgitta has now started publishing an article where she
walks though her experiences using sensors to keep a codebase
maintainable. This part looks at static analysis with basic code linting.
more…
Thu 14 May 2026 17:52 EDT
Martin Fowler
Last week I spent a day at The Orchard Retreat, hosted by Mechanical Orchard. that brought together several people working in software development to talk about the profession’s future with the rise of agentic programming. The event was help under the Chatham House Rule, so I can’t attribute the comments and stories I heard. (If anyone recognizes themselves, and would like attribution, let me know.) Here are a few tidbits that caught my notebook.
❄ ❄
One group developed a behavioral clone of GNU Cobol compiler in Rust. The result is 70K lines of Rust and was built in 3 days. This is yet another sign of the ability of LLMs to do a good job of porting existing code to a new platform. Good regression tests are extremely valuable here (and I don’t know how good GNU Cobol’s are). There’s also the possibility of building a test suite if you have access an existing implementation.
❄ ❄
Large spec documents can be complex for a human to review. One attendee shared the idea of getting the LLM to interview a human expert, asking the human questions to verify the correctness of the specification, a form of Interrogatory LLM.
❄ ❄
Not specifically about AI - but I liked how one attendee commented that the first thing they do when consulting with an organization is to read the guidelines for their change-control board. This is the scar tissue of what’s gone wrong in the past. I’ve often said that to understand why a thing is the way it is, you need to understand the history of how it got there. This seems like an excellent way to tap into important parts of that history.
❄ ❄
My colleagues who work with modernizing legacy systems have long been rather sniffy about “Lift and Shift” - porting a legacy system to a new platform while retaining Feature Parity.
We see this pattern as a huge missed opportunity. Often the old systems have bloated over time, with many features unused by users (50% according to a 2014 Standish Group report) and business processes that have evolved over time. Replacing these features is a waste. Instead, try to muster the energy to take a step back and understand what users currently need, and prioritize these needs against business outcomes and metrics.
But this point of view was developed before LLM’s ability to port code appeared. One attendee who does a lot of work in this field said they believed that lifting and shifting to a new platform should now be always the first step in a legacy migration. The cost is no longer as formidable as it used to be, and a better environment makes further evolution much cheaper. Just don’t stop there.
❄ ❄
Several attendees were from the financial industry, and thus were immersed the problems of complex legacy environments coupled with regulatory controls and significant risk should software do something wrong with money. One of their issues is the complexity we run into when a financial product is offered in multiple jurisdictions, each with their own regulations to satisfy. There’s a lot of software complexity in deciding which jurisdiction applies, and picking the right set of rules at the right point of the workflow.
The question here is whether the rapidity of agentic programming means that we can build individual, simpler systems for each jurisdiction. We would then use LLMs to ensure consistency between them, so that as the product rules change, each system reflects that into its own environment.
A large part of software design is about identifying what is the same and what differs between various business contexts. Where things are the same, and need to be the same, we are rightly wary of duplicating code, since this increases the cost of updates the dangers of inconsistency. The interesting question is what role LLMs can play to give us new tools to tackle this.
❄ ❄
As is usually the case in gatherings like this, folks were concerned about junior developers. When we work with The Genie, our value comes from good judgment - how do we teach that? This group did have one common tool - Pair Programming. One of the key benefits of pairing has always been skills transfer, and here an experienced agentic programmer can pass on their judgment for software design and how to use the genie to get there. And the junior will often have a trick or two to share too - that fresh pair of eyes in particularly valuable in the shift to our agentic future.
❄ ❄
Historically, we use computer systems to bring order to chaotic human processes. Is AI reversing that?
❄ ❄
So much software is involved in data transformation. Those records over there need to be consumed by these APIs over here, but there are differences in how the data is structured, often due to being in different Bounded Contexts, so we have to do some conversion. Agents are particularly adept at writing this kind of transformation code, which is often more tedious than we’d like.
❄ ❄
Chaos Engineering has become a valuable technique to improve resiliency, made famous by Netflix’s Chaos Monkey that randomly breaks live services to see how well the ecosystem reacts and recovers. What would a Chaos Monkey for AI look like? Would it deliberately introduce hallucinations into a pipeline to see if sensors were able to catch them?
❄ ❄ ❄ ❄ ❄
Back at my desk
There’s been a bunch of questions about the article on Structured-Prompt-Driven Development (SPDD) that the authors answered in a Q&A section. One in particular caught my eye:
Have you considered having an agent do the prompt/spec review itself — not a human reviewing the Canvas, but an agent that reads the REASONS Canvas alongside the code diff and verifies alignment?
The reply talks about how there is an available command to do this, but there downsides. In particular one reason not to do this automatically is:
Letting humans learn. Review is also where humans learn from the AI’s choices — patterns, trade-offs, options they had not thought of. Cutting humans out speeds things up, but it blocks the long-term skill growth that SPDD is designed to protect. […] Once enough decision rules build up to give us real confidence, we may shift more of the review to the agent step by step — but the part where humans learn from the AI is something we plan to keep.
One of the ways we should judge the value of an AI tool is how much it helps us humans learn more about the world we inhabit and build.
❄ ❄ ❄ ❄ ❄
In some strange way I injured my elbow last week. No idea how, there was no event where I said “oh shit”. It just gradually started hurting and swelling. My life-long strategy to avoid sports injuries had defied me. I applied ice and ibuprofin, the swelling went down, but my range of motion got worse. I’m glad I learned to use a knife and fork in English childhood, so I normally eat with my left hand.
I noticed that that loss of range of motion occurred after I got home, when I started spending all day at the computer again. I might not use my elbow directly, but my right hand does a lot of typing and mousing. My desk set up is pretty ergonomic, with a good keyboard, a wrist rest for the mouse, and arm rests on my chair. But even so, did my computer use make my elbow get worse once I got home? I can’t imagine not using the computer, for me writing has become an unstoppable habit. But maybe I should use this opportunity to explore voice input - after all most people can speak faster than they can type.
I tried this many years ago, when a colleague told me how good voice recognition was once it trained to you. I tried it, and indeed the voice recognition, even in those pre-AI days, was very good. But it didn’t work for me. When I’m writing I rapidly type words into Emacs, but almost immediately I go back to edit them. Write two sentences, edit them, write another, re-edit the paragraph. The back-and-forth between seeing my words and thinking about them is tight - I can’t just dictate my words.
That made me reflect further. I only started using a computer for my writing in my 20s. At school I had to write longhand, and in university to type on typewriter. But those media don’t support the constant rewriting that I do now. Would I even have become a writer had the text editor not been invented?
❄ ❄ ❄ ❄ ❄
James Pritchard thinks that many developers are over-using agents at run-time in their products, when LLMs are better used as functions.
The problem with agents isn’t that they don’t work. It’s that they work unpredictably. You trade a known execution path for “autonomy” that mostly means “I don’t know what it’s going to do.” When an agent-powered feature breaks in production, you’re debugging a conversation transcript, not a stack trace.
Most “agent” use cases are actually workflows, a known sequence of steps where one or two of those steps happen to involve an LLM. You don’t need autonomy for that. You need a function call.
He points out that functions compose predictably, so if you know the workflow, then composing in a program text is better than agents figuring out how to coordinate themselves. It’s faster, and needs less tokens. It’s usually easier to deal with failures, since the scope of the interaction is smaller.
❄ ❄ ❄ ❄ ❄
Pritchard also thinks that people use skills far more than they should. He thinks people accumulate folders of markdown skill files but LLMs use them inconsistently, often missing them when they’re needed, or bloating context when they are not. Many things that should go in skills should be other parts of a harness, preferably computational. Skills should only be used with deliberate, infrequent workflows.
The skills obsession is a symptom of a deeper pattern: people reaching for configuration when they should be reaching for architecture.
“The LLM doesn’t write good tests.” Don’t write a testing skill. Are your existing tests inconsistent? Is the test setup complex? Fix those things and it’ll write good tests without being told how. Point it at a test file you’re proud of. Code is clearer than English.
[…]
The best setup is one where you barely need to configure the LLM at all. A clean codebase with clear patterns, a short project config for the non-obvious stuff, hooks for automation, and maybe one or two skills for specific workflows you run intentionally. That’s it.
❄ ❄ ❄ ❄ ❄
An oft-stated point about the rise of agentic programming is that we have to start dealing with non-determinism in our work. Of course that’s somewhat of a simplification, because some aspects of software development have long had to face non-determinism. A notable example of this is distributed systems, and a notable figure in helping us probe the truly uncomfortable waters of distributed systems is Kyle Kingsbury (Aphyr).
Last month he dropped a long article (the pdf is 32 pages) on how he sees our LLM-enabled future. The title “The Future of Everything is Lies, I Guess” betrays his lack of enthusiasm for this future.
Some readers are undoubtedly upset that I have not devoted more space to the wonders of machine learning—how amazing LLMs are at code generation, how incredible it is that Suno can turn hummed melodies into polished songs. But this is not an article about how fast or convenient it is to drive a car. We all know cars are fast. I am trying to ask what will happen to the shape of cities.
It’s worth the long read, even if it isn’t terribly cheerful. Kingsbury brings up many of worries about AI’s growth from the perspective of someone who is clearly well-informed about their capabilities.
His view is that the best response to all this is that we should stop. He wants to avoid using AIs for his writing, software, or personal life. He thinks those working for the AI companies should quit. And yet he also knows that these tools are useful, and wants to use them.
I’m both a hoper and a doomer when it comes to our AI future. Fundamentally I see any powerful technology as a big bus: we are either on it, or get run over by it. I’m onboard the bus because I don’t think putting up some barriers would stop me being crushed by its wheels. Maybe if I’m on the bus I can join some people to influence the driver a bit. I’m also very reluctant to speculate on the future outcomes of anything, let alone something as powerful as this. Did the early industrialists in the late eighteenth century have any clue what the industrial revolution they unleashed would do? While it created many harms, it also created a massive rise in the living standards of millions of people, at least those whose countries were on the bus. AI may create benefits that I can’t really dream of, although I can glimpse it when it helps a friend stave off Parkinson’s disease.
Those hopes are there, but Kingsbury’s article shines a light on the darker elements of the here-and-now, asking serious questions of responsibility
a part of my work as a moderator of a Mastodon instance is to respond to user reports, and occasionally those reports are for CSAM, and I am legally obligated to review and submit that content to the NCMEC. I do not want to see these images, and I really wish I could unsee them. On dark mornings, when I sit down at my computer and find a moderation report for AI-generated images of sexual assault, I sometimes wish that the engineers working at OpenAI etc. had to see these images too. Perhaps it would make them reflect on the technology they are ushering into the world, and how “alignment” is working out in practice.
Thu 14 May 2026 11:04 EDT
Martin Fowler
When we need an LLM to perform a complex task, we often need to feed it a
lot of context. Coming up with a design for a new feature requires
descriptions of how we want the feature to appear to the user, guidelines on
how it should be implemented, information on external systems to consult, and
so on. All this can be several pages of markdown. The obvious way to do
this is for a human to write this context, but an alternative is to use an LLM to write
this context after interviewing a human.
The way I can do this is to prompt the LLM to interrogate me. It should ask me
all the questions it needs to create this appropriate context. I can feed much
of the information it needs, and tell it other sources it needs to consult if
it can't figure those out itself. Once it's done, it can then create the
context report for another session (perhaps with another model) to carry out
the next step.
I first saw a decent description of this approach in Harper
Reed's blog. A striking element of his approach is insisting that the LLM
ask only one question at a time. (When I tried it, I found it needed to be
frequently reminded of this.)
Another way to use an interrogatory LLM is to give it a document, such as a
software specification, that captures knowledge about a domain - and then ask
the LLM to interview a human expert to determine if the document is accurate.
This is an alternative to getting the human expert to read the document to
review it. People often find reviewing hard, so a conversation with an LLM
might be more fruitful, particularly if the document isn't well-written.
Naturally we can use both of these, using one interrogatory LLM to build a
document, then using other interrogatory LLMs to review it with other experts.
The above is getting an LLM to create or assess context for a particular
use of an LLM. But the technique is more broadly applicable. I've become a
natural writer, someone who finds the process of writing an essential part of
thinking. To really understand something, I need to write about it. But
different people are different. Many folks find writing hard, often
very hard. This can be a real problem when we need to get information
out of someone's head into a form that other humans can consume. Maybe such
people would find it easier to ask an LLM to interview them than to write a
document themselves. Certainly the result will have that tang of AI-writing
that folks like me shudder at - but that's better than not having the
information itself, either due to rushed writing or no writing at all.
Tue 12 May 2026 09:30 EDT
Martin Fowler
Increasingly humans delegate writing code to agents. Will there even be
source code in the future? To wrestle with this question, we have to
understand what code is. Unmesh Joshi sees code as having
two distinct but intertwined purposes: instructions to a machine and a
conceptual model of the problem domain. He explores why it's vital
to build a vocabulary to talk to the machine, how programming languages
are thinking tools, and how this affects our future as we work with LLMs.
more…
Tue 05 May 2026 12:23 EDT
Martin Fowler
Over the last couple of months Rahul Garg published a series of posts here on how to reduce the friction in AI-assisted programming. To make it easier to put these ideas into practice he’s now built an open-source framework to operationalize these patterns.
AI coding assistants jump straight to code, silently make design decisions, forget constraints mid-conversation, and produce output nobody reviewed against real engineering standards. Lattice fixes this with composable skills in three tiers – atoms, molecules, refiners – that embed battle-tested engineering disciplines (Clean Architecture, DDD, design-first methodology, secure coding, and more), plus a living context layer (the .lattice/ folder) that accumulates your project’s standards, decisions, and review insights. The system gets smarter with use – after a few feature cycles, atoms aren’t applying generic rules, they’re applying your rules, informed by your history.
It can be installed as a Claude Code plugin or downloaded for use with any AI tool.
❄ ❄ ❄ ❄ ❄
This is also a good point to note that the article by my colleagues Wei Zhang and Jessie Jie Xia on Structured-Prompt-Driven Development (SPDD) has generated an enormous amount of traffic, and quite a few questions. They have thus added a Q&A section to the article that answers a dozen of them.
❄ ❄ ❄ ❄ ❄
Jessica Kerr (Jessitron) posted a merry tidbit of building a tool to work with conversation logs. She observes the double feedback loop involved.
There are (at least) two feedback loops running here. One is the development loop, with Claude doing what I ask and then me checking whether that is indeed what I want.[…] Then there’s a meta-level feedback loop, the “is this working?” check when I feel resistance. Frustration, tedium, annoyance–these feelings are a signal to me that maybe this work could be easier.
The double loop here is both changing the thing we are building but also changing the thing we are using to build the thing we are building.
As developers using software to build software, we have potential to mold our own work environment. With AI making software change superfast, changing our program to make debugging easier pays off immediately. Also, this is fun!
Indeed it is, and makes me think that agents are allowing us to (re)discover one of the Great Lost Joys of software development - that of molding my development environment to exactly fit the problem and my personal tastes. A while ago I wrote about this under the name Internal Reprogramability. It was a central feature of the Smalltalk and Lisp communities but was mostly lost as we got complex and polished IDEs (although the unix command line gives a hint of its appeal).
❄ ❄ ❄ ❄ ❄
Ashley MacIsaac is a musician from Cape Breton, who plays folk-influenced music (I have a couple of his albums in my collection). Google generated an AI overview that asserted that had been convicted of crimes, including sexual assault and was on the national sex-offender registry. These were completely false, confusing him with another man with the same name. MacIsaac is suing Google for defamation:
“This was not a search engine just scanning through things and giving somebody else’s story […] It was published by them. And to me, that is defamation. The guardrails were not there to prevent Google AI from publishing that content.”
MacIsaac’s point is that Google must take responsibility for what a tool it controls publishes. MacIsaac suffered genuine harm here, not just to his reputation, but he also had a concert canceled and the claims affect his performing.
“I felt that tangible fear from something that was published by a media company,” he said in an interview with The Canadian Press. “I feared for my own safety going on stage because of what I was labelled as. And I don’t know how long this will follow me.”
Too often tech companies try to dodge the consequences of their actions. There are genuine issues about the difficulties of monitoring what’s published at scale, but that’s a responsibility that they should face up to.
❄ ❄ ❄ ❄ ❄
Stephen O’Grady (RedMonk) takes a serious look at how much the big tech companies are spending on AI build-outs. The sums involved are staggering, not just in absolute terms (over $100 Billion), but also compared to the revenues of the companies involved. Firms like Amazon, Alphabet, and Microsoft are spending over 50% of their revenues (not profits). Meta and Oracle hit or pass 75% of revenues.
That level of investment would have been unthinkable a decade ago. Today, the chart suggests it’s table stakes
There is a notable exception: Apple. Here they are clearly Thinking Different, eyeballing the chart they seem closer to 10% of revenues.
❄ ❄ ❄ ❄ ❄
Most folks I talk to about agentic programming are using models in the cloud: Claude, Codex, and the like. Everyone agrees these are the most powerful models, the ones that triggered the November Inflection. But do we need to use the Most Powerful Models, particularly when we have to ship data to them, and pay handsomely for the privilege? Willem van den Ende considers an alternative, that local models are Good Enough.
Assumptions
- We are all figuring this out.
- Quality of a harness (coding agent + “skills” + extensions) can matter as least as much as the model
- Running open models and an open coding agent + custom extensions takes time, but pays off in understanding and a stable base where engineering effort compounds
- Open, local, models have (for me) crossed the point where they are good enough for daily work with a coding agent.
The post describes in detail his setup for local model work. It includes sandboxing with Nono, which is something to consider even if using a Cloud model - such powerful tools need a Zero Trust Architecture.
❄ ❄ ❄ ❄ ❄
In case you haven’t noticed, those last two fragments resonate. Apple isn’t playing the cloud AI model game, they are saving a huge amount of money, and if local models end up being the future, they’ll be looking rather wise. Van den Ende’s post led me to a podcast by Nate B Jones that argues that Apple is replaying a fifty-year old strategy here. All those years ago anyone who used a computer bought time on a mainframe, the Apple II put far less capable compute into the home and small office. From there came spreadsheets, desktop publishing, and the modern home computer - things that weren’t possible using mainframes.
He sees the rise of John Ternus as CEO isn’t merely a switch to a known insider successor - but a bet that the future of AI is sophisticated hardware in the home, office, and pocket. If Open Source models are Good Enough, then why spend money sending tokens - containing your sensitive data - to the AI megacorps?
❄ ❄ ❄ ❄ ❄
Talking of five decades in the past, it was in 1974 that Fred Brooks opened one of the most influential books in our profession with these paragraphs:
No scene from prehistory is quite so vivid as that of the mortal struggles of great beasts in the tar pits. In the mind’s eye one sees dinosaurs, mammoths, and sabertoothed tigers struggling against the grip of the tar. The fiercer the struggle, the more entangling the tar, and no beast is so strong or so skillful but that he ultimately sinks.
Large-system programming has over the past decade been such a tar pit, and many great and powerful beasts have thrashed violently in it. Most have emerged with running systems — few have met goals, schedules, and budgets. Large and small, massive or wiry, team after team has become entangled in the tar. No one thing seems to cause the difficulty — any particular paw can be pulled away. But the accumulation of simultaneous and interacting factors brings slower and slower motion. Everyone seems to have been surprised by the stickiness of the problem, and it is hard to discern the nature of it. But we must try to understand it if we are to solve it.
With the title of his recent post Kent Beck summons up that imagery as the Genie Tarpit. After explaining why skilled software development is about building both features and futures, he observes that these AI tools aren’t doing a good job of producing software with the kind of internal quality that is needed for a good future.
Here’s what I’ve observed — genies naturally live down & to the left of muddling. The “plausible deniability” task orientation of the genie leaves it claiming success even though the code doesn’t work at all. And complexity piles on complexity until even the genie can’t pretend to make progress any more.
It’s still an open question whether, or to what extent, internal quality matters in the age of agentic programming. One view is, as Laura Tacho puts it, “The Venn Diagram of Developer Experience and Agent Experience is a circle”. Well organized elements, with good naming, help The Genie understand code, so are important if we can continue to go beyond small disposable systems. The other view is that such internal quality doesn’t matter, that the galaxy brain of LLMs will make sense of the biggest bowls of spaghetti. Maybe not now, but after a couple more inflections.
That’s the fundamental question. Can The Genie evade the tar pit, or will it struggle fruitlessly against the tar’s sticky grip?
Tue 05 May 2026 12:18 EDT
Martin Fowler
In the early 1960s, Fred Brooks managed the development of IBM's System/360
computer systems. After it was done he penned his thoughts in the book The
Mythical Man-Month which became one of the most influential books on software
development after its publication in 1975. Reading it in 2026, we'll find some
of it outdated, but it also retains many lessons that are still relevant today.
The book contains Brooks's law: “Adding manpower to a late software project
makes it later.” The issue here is communication, as the number of people
grows, the number of communication paths between those people grows
exponentially. Unless these paths are skillfully designed, then work quickly
falls apart.
Perhaps my most enduring lesson from this book is the importance of
conceptual integrity
I will contend that conceptual integrity is the most important
consideration in system design. It is better to have a system omit certain
anomalous features and improvements, but to reflect one set of design ideas,
than to have one that contains many good but independent and uncoordinated
ideas.
He argues that conceptual integrity comes from both simplicity and
straightforwardness - the latter being how easily we can compose elements.
This point of view has been a strong influence upon my career, the pursuit
of conceptual integrity underpins much of my work.
The anniversary edition of this book is the one to get, because it also
includes his even-more influential 1986 essay “No Silver Bullet”.
Wed 29 Apr 2026 09:23 EDT
Martin Fowler
Chris Parsons has updated his guide on using AI to code. This is his third update, what I like about it is that he gives a lot of concrete information about how he uses AI, with sufficient detail that we can learn from him. His advice also resonates with the better advice I’ve seen out there, so the article makes a good overview of the state of using AI for software development.
I wrote the previous version of this post in March 2025, updated it once in August, and it has been linked from almost everything I have written about AI engineering since. The fundamentals from that post still hold: keep changes small, build guardrails, document ruthlessly, and make sure every change gets verified before it ships. One thing has had to move with the volume. “Verified” used to mean “read by you”. With modern agent throughput, it has to mean “checked by tests, by type checkers, by automated gates, or by you where your judgement matters”. The check still happens; it just does not always happen in your head.
Like Simon Willison, he makes a clear distinction between vibe coding, where you don’t look at or care about the code, and agentic engineering. He recommends either Claude Code or Codex CLI. He considers the inner harness provided by his preferred tools to be a key part of their advantage.
He sees verification is the key thing to focus on:
A team that can generate five approaches and verify all five in an afternoon will outpace a team that generates one and waits a week for feedback. The game is not “how fast can we build” any more. It is “how fast can we tell whether this is right”. That shifts where to invest. Build better review surfaces, not better prompts. Make feedback unnecessary where you can by having the agent verify against a realistic environment before it asks a human, and make feedback instant where you cannot.
The key role of the programmer is in training the AI to write software properly, and the most important thing skilled agentic programmers can do is pass that skill onto other developers.
And if you are a senior engineer worried that your job is quietly turning into approving diffs: it is. The way out is to train the AI so the diffs are right the first time, to make yourself the person on the team who shapes the harness, and to make that work the visible thing you are measured on. That role compounds in a way that reviewing never will.
❄ ❄ ❄ ❄ ❄
Early this month Birgitta Böckeler wrote a superb article on Harness Engineering. (That’s not just my opinion, judging by the crazy traffic it’s attracted.) Birgitta has now recorded a video discussion with Chris Ford on Harness Engineering, which is well worth a watch.
In it they focus on discussing the role of computational sensors in the harness, such as static analysis and tests.
LLMs are great for exploratory and fuzzy rules, but once you have something that really is objective, converting it to a formal, unambiguous, deterministic format can give you more assurance
Birgitta did some experiments to explore the benefits of adding sensors, including a deep dive on using static analysis. She found it’s more useful as agents can really address every warning, and don’t slack off like humans do.
❄ ❄ ❄ ❄ ❄
Adam Tornhill considers an age-old question: how long should a function be? This question is still relevent in the age of agentic programming.
AI models do not “understand” code the way humans do. They infer meaning from patterns in tokens and depend heavily on what is explicitly expressed in the code.
Research shows that naming plays a critical role. When meaningful identifiers are replaced with arbitrary names, model performance drops significantly. Current models rely heavily on literal features—names, structure, and local context—rather than inferred semantics.
Like me, he doesn’t think the answer is to think about how many lines should be in a function, instead it’s all about providing better structure. He has a good example of how a well-chosen function defines useful concepts, where a function wraps four lines of code, returning a new concept that enters the vocabulary of the program.
Functions are the first unit of structure in a codebase. They define how logic is grouped, how intent is communicated, and how change is localized. If the function boundaries are wrong, everything built on top of them becomes harder to understand and harder to evolve.
This fits with my writing that the key to function length is the separation between intention and implementation:
If you have to spend effort into looking at a fragment of code to figure out what it’s doing, then you should extract it into a function and name the function after that “what”. That way when you read it again, the purpose of the function leaps right out at you, and most of the time you won’t need to care about how the function fulfills its purpose - which is the body of the function.
❄ ❄ ❄ ❄ ❄
Many folks in my feeds recommended Nilay Patel’s post on Why People Hate AI. He thinks that many people in the software world have “software brain”:
The simplest definition I’ve come up with is that it’s when you see the whole world as a series of databases that can be controlled with the structured language of software code. Like I said, this is a powerful way of seeing things. So much of our lives run through databases, and a bunch of important companies have been built around maintaining those databases and providing access to them.
Zillow is a database of houses. Uber is a database of cars and riders. YouTube is a database of videos. The Verge’s website is a database of stories. You can go on and on and on. Once you start seeing the world as a bunch of databases, it’s a small jump to feeling like you can control everything if you can just control the data.
Software Brain views people into databases, and oddly enough, a lot of people don’t like that. Which is why so many polls reveal the negative feelings folks have about the AI movement.
Even taking the time to consider how much of your life is captured in databases makes people unhappy. No one wants to be surveilled constantly, and especially not in a way that makes tech companies even more powerful. But getting everything in a database so software can see it is a preoccupation of the AI industry. It’s why all the meeting systems have AI note takers in them now.
Patel draws a similarity that I’ve often made - that between programmers and lawyers. Lawyers who draw up contracts are creating a protocol for how the parties in the contract should behave. As Patel puts it:
If the heart of software brain is the idea that thinking in the structured language of code can make things happen in the real world, well, the heart of lawyer brain is that thinking in the structured legal language of statutes and citations can also make things happen. Hell, it can give you power over society.
The difference, of course, is that law is non-deterministic. Litigation is resolving what happens when people have different ideas about how those contracts should execute.
❄ ❄ ❄ ❄ ❄
I was chatting recently with a company who wanted to use AI to make sense of their internal data. The potential was great, but the problem was that the data a mess. People put stuff into fields that didn’t make sense, and there was little consistency about how people classified important entities. As someone commented
the hardest problem with internal data is precise, consistent definitions
You can imagine my astonishment. (i.e. none at all - this has been a constant theme during all my decades with computers.) The difficulty of getting such definitions undermines much of the hopes of Software Brain
This resonates with our relationship with LLMs when programming. Precise and consistent definitions strike me as crucial to effective communication with The Genie. These definitions need to grow in the conversation, and be tended over time. Conceptual modeling will be a key skill for agentic programming and whatever comes next. (At least I hope it will, since it’s a part of programming I really enjoy.)
❄ ❄ ❄ ❄ ❄
Patel’s article refers to Ezra Klein’s post about the new feeling in San Francisco.
You might think that A.I. types in Silicon Valley, flush with cash, are on top of the world right now. I found them notably insecure. They think the A.I. age has arrived and its winners and losers will be determined, in part, by speed of adoption. The argument is simple enough: The advantages of working atop an army of A.I. assistants and coders will compound over time, and to begin that process now is to launch yourself far ahead of your competition later. And so they are racing one another to fully integrate A.I. into their lives and into their companies. But that doesn’t just mean using A.I. It means making themselves legible to the A.I.
That legibility is the heart of Patel’s observation. That’s why I see many colleagues of mine dumping all their email, meeting notes, slide decks and everything else into files that AI can read and work with. This works to the strengths of AI, we know that AI is really good at querying unstructured information. So I can figure out what’s buried in my notes in a way that’s far more effective than hoping I’m typing the right search regex.
I’ve been using Gemini a fair bit for exactly this on the web, finding it easier to write a question to it than to throw search terms at Google. Gemini keeps a record of my past requests, and uses that to help it tune what I’m looking for. As Klein observes:
[The AI] is constantly referring back to other things it knows, or thinks it knows, about me. Sycophancy, in my experience, has given way to an occasionally unsettling attentiveness; a constant drawing of connections between my current concerns and my past queries, like a therapist desperate to prove he’s been paying close attention.
The result is a strange amalgam of feeling seen and feeling caricatured.
Like myself, Klein is a writer, and is faced by the same temptation that I have when I think about AI and writing. Maybe instead of toiling over articles, I should ask an LLM to create an AGENTS.md file that summarizes my writing style, and every few days ask it to compose an article on some subject, read it, tweak it, and then publish my erudite musings. But that’s not at all appealing to me. I want understanding to grow in my brain, not the LLM’s transient session. Writing to explain my thinking to others is how I refine that thinking, “chiseling that idea into something publishable” as Klein puts it. To have an AI write for me is to cripple my own mind.
Tue 28 Apr 2026 09:02 EDT
Martin Fowler
LLM programming assistants have demonstrated considerable value, but
mostly with individual developers. The internal IT organization in
Thoughtworks has been using them for their teams and have developed a
method and workflow called Structured Prompt-Driven Development (SPDD).
Wei Zhang and Jessie Jie Xia describe a simple example of
this workflow with details in github. This workflow treats the prompts as
a first-class artifact, kept with the code in version control, and used to
align development with business needs. They have found that developers
need three key skills to be effective: alignment, abstraction-first, and
iterative review.
more…
Tue 21 Apr 2026 16:34 EDT
Martin Fowler
Last week Thoughtworks released the 34th volume of our Technology Radar. This radar is our biannual survey of our experience of the technology scene, highlighting tools, techniques, platforms, and languages that we’ve used or otherwise caught our eye. This edition contains 118 blips, each briefly describing our impressions of one of these elements.
As we would expect, the radar is dominated by AI-oriented topics. Part of this is revisiting familiar ground with LLM-assisted eyes:
An interesting consequence of AI in software development is that it’s not only forcing us to look to the future; it’s also pushing us to revisit the foundations of our craft. While assembling this edition, we found ourselves returning to many established techniques, from pair programming to zero trust architecture, and from mutation testing to DORA metrics. We also revisited core principles of software craftsmanship, such as clean code, deliberate design, testability and accessibility as a first-class concern. This is not nostalgia, but a necessary counterweight to the speed at which AI tools can generate complexity. We also observed a resurgence of the command line: After years of abstracting it away in the name of usability, agentic tools are bringing developers back to the terminal as a primary interface.
I was especially happy to see my colleague Jim Gumbley added to the writing team, he’s been a regular source of security information for me over the years, including working on this site’s Threat Modeling Guide. Having a strong security presence on the radar team is especially important given the serious security concerns around using LLMs. One of the themes of the radar is securing “permission hungry” agents:
“Permission hungry” describes the bind at the heart of the current agent moment: the agents worth building are the ones that need access to everything. OpenClaw and Claude Cowork supervise real work tasks; Gas Town coordinates agent swarms across entire codebases. These agents require broad access to private data, external communication and real systems — each arguing that the payoff justifies it.
However, like a skier who’s just learned to turn and confidently points themselves at the hardest black run, the safeguards haven’t caught up with that ambition. The appetite for access collides with unsolved problems. Prompt injection means models still can’t reliably distinguish trusted instructions from untrusted input.
Given all of this, many of this radar’s blips are about Harness Engineering, indeed the radar meeting was a major source of ideas for Birgitta’s excellent article on the subject. The radar includes several blips suggesting the guides and sensors necessary for a well-fitting harness. I expect that when the next radar appears in six months time, that list will increase.
❄ ❄ ❄ ❄ ❄
Mike Mason looks what happens when developers aren’t reading the code.
The Python codebase Claude produced was largely working. Unit tests passed, and a few hours of real-world testing showed it was successfully managing a fairly complex piece of my infrastructure. But somewhere around 100KB of total code I noticed something: the main file had grown to about 50KB (2,000 lines) and Claude Code, when it needed to make edits, had started reaching for sed to find and modify code within that file. When I saw that, it was a serious alarm bell.
As well as the experience of “a friend”, he ponders the 500,000 lines of Claude Code after the leak.
Both things are true: there is good architecture in Claude Code, and there is also an incomprehensible mess. That’s actually the point. You don’t get to know which is which without reading the code.
His conclusion is a rough framework. Throw-away analysis scripts are fine to vibe away. Tooling you need to maintain and durable code, needs regular human review - even if it’s just a human asking a model to evaluate the code with some hints as to what good code looks like
The moment you say “I’m getting uncomfortable with how big this is getting, can we do something better?” it does the right thing: sensible decomposition, new classes, sometimes even unit tests for the new thing. It knew, it just didn’t volunteer it.
He does recommend being serious with CLAUDE.md, I don’t know if he’s tried many of the patterns that Rahul Garg has recently posted to break the similar frustration loop that he saw.
❄ ❄ ❄ ❄ ❄
Dan Davies poses an annoying philosophy thought experiment for us to consider how we feel about LLMs indulging in ghost writing.
❄ ❄ ❄ ❄ ❄
DOGE dismantled many useful things during their brief period with the wood chipper. One of these was DirectFile, a government program that supported people filing their taxes online. Don Moynihan has talked to many folks involved in Direct File, has penned a worthwhile essay that isn’t just relevant to DirectFile and other U.S. government technology projects, but indeed any technology initiative in a large organization.
Moynihan highlights:
a paradox of government reform: the simpler a potential change appears, the more likely that it has not been implemented because it features deceptive complexity that others have tried and failed to resolve.
I’ve heard that tale in many a large corporation too
One way government initiatives are different is that, at its best, it’s built on an attitude of public service
Many who worked on Direct File drew a sharp contrast with DOGE and their approach to building tech products. One point of distinction was DOGE’s seeming disinterest in public interest goals and of the public itself: “if you do not think government has a responsibility to serve people, I think it draws into question how good are you going to be at making government work better for people if you just don’t believe in that underlying principle”
The tragedy for U.S. taxpayers like me is that we’ve lost an effective way to go through the annual hassle of taxes. In addition the IRS is much weaker - it’s lost 25% of its staff and its budget is 40% below what it was in 2010. Much though we hate tax collectors, this isn’t a good thing. An efficient tax system is an important part of national security, many historians consider the ability to raise taxes effectively was an important reason why Britain won its century-long struggle with France in the Eighteenth century. A wonky tax system is also a major reason why the French monarchy, so powerful at the start of that century, fell to revolution. Indeed there is considerable evidence that increasing the budget of the IRS would more than pay for itself by increasing revenue.
Sat 11 Apr 2026 09:01 EDT
Martin Fowler
Last night I saw Central Square Theater’s excellent production of Breaking the Code. It’s about Alan Turing, who made a monumental contribution to both my profession and the fate of free democracies. Well worth seeing if you’re in the Boston area this month.
Wed 08 Apr 2026 09:28 EDT
Martin Fowler
Rahul Garg finishes his
series on reducing the friction in AI-Assisted Development. He
proposes a structured feedback practice that harvests learnings from AI
sessions and feeds them back into the team's shared artifacts, turning
individual experience into collective improvement.
more…