
Research, Review, Rebuild
Intelligent Modernisation with MCP and Strategic Prompting
The Bahmni open-source hospital management system started over nine years ago with a front end using AngularJS and an OpenMRS REST API. We wished to convert this to use a React + TypeScript front end with an HL7 FHIR API. In exploring how to do this modernization we used a structured prompting workflow of Research, Review, and Rebuild - together with Cline, Claude 3.5 Sonnet, Atlassian MCP server, and a filesystem MCP server. Changing a single control would normally take 3–6 days of manual effort, but with these tools was completed in under an hour at a cost of under $2.
27 August 2025

Until recently, I held the belief that Generative Artificial Intelligence (GenAI) in software development was predominantly suited for greenfield projects. However, the introduction of the Model Context Protocol (MCP) marks a significant shift in this paradigm. MCP emerges as a transformative enabler for legacy modernization—especially for large-scale, long-lived, and complex systems.
As part of my exploration into modernizing Bahmni’s codebase, an open-source Hospital Management System and Electronic Medical Record (EMR), I evaluated the use of Model Context Protocol (MCP) to support the migration of legacy display controls. To guide this process, I adopted a workflow that I refer to as “Research, Review, Rebuild”, which provides a structured, disciplined, and iterative approach to code migration. This memo outlines the modernization effort—one that goes beyond a simple tech stack upgrade—by leveraging Generative AI (GenAI) to accelerate delivery while preserving the stability and intent of the existing system. While much of the content focuses on modernizing Bahmni, this is simply because I have hands-on experience with the codebase.
The initial outcomes have been nothing short of remarkable. The streamlined migration effort led to noticeable improvements in code quality, maintainability, and delivery velocity. Based on these early results, I believe this workflow—when augmented with MCP—has the potential to become a game changer for legacy modernization.
Bahmni and Legacy Code Migration
Bahmni is an open-source Hospital Management System & EMR built to support healthcare delivery in low-resource settings providing a rich interface for clinical and administrative users. The Bahmni frontend was originally developed using AngularJS (version 1.x)—an early but powerful framework for building dynamic web applications. However, AngularJS has long been deprecated by the Angular team at Google, with official long-term support having ended in December 2021.
Despite this, Bahmni continues to rely heavily on AngularJS for many of its core workflows. This reliance introduces significant risks, including security vulnerabilities from unpatched dependencies, difficulty in onboarding developers unfamiliar with the outdated framework, limited compatibility with modern tools and libraries, and reduced maintainability as new requirements are built on an aging codebase.
In healthcare systems, the continued use of outdated software can adversely affect clinical workflows and compromise patient data safety. For Bahmni, frontend migration has become a critical priority.
Research, Review, Rebuild
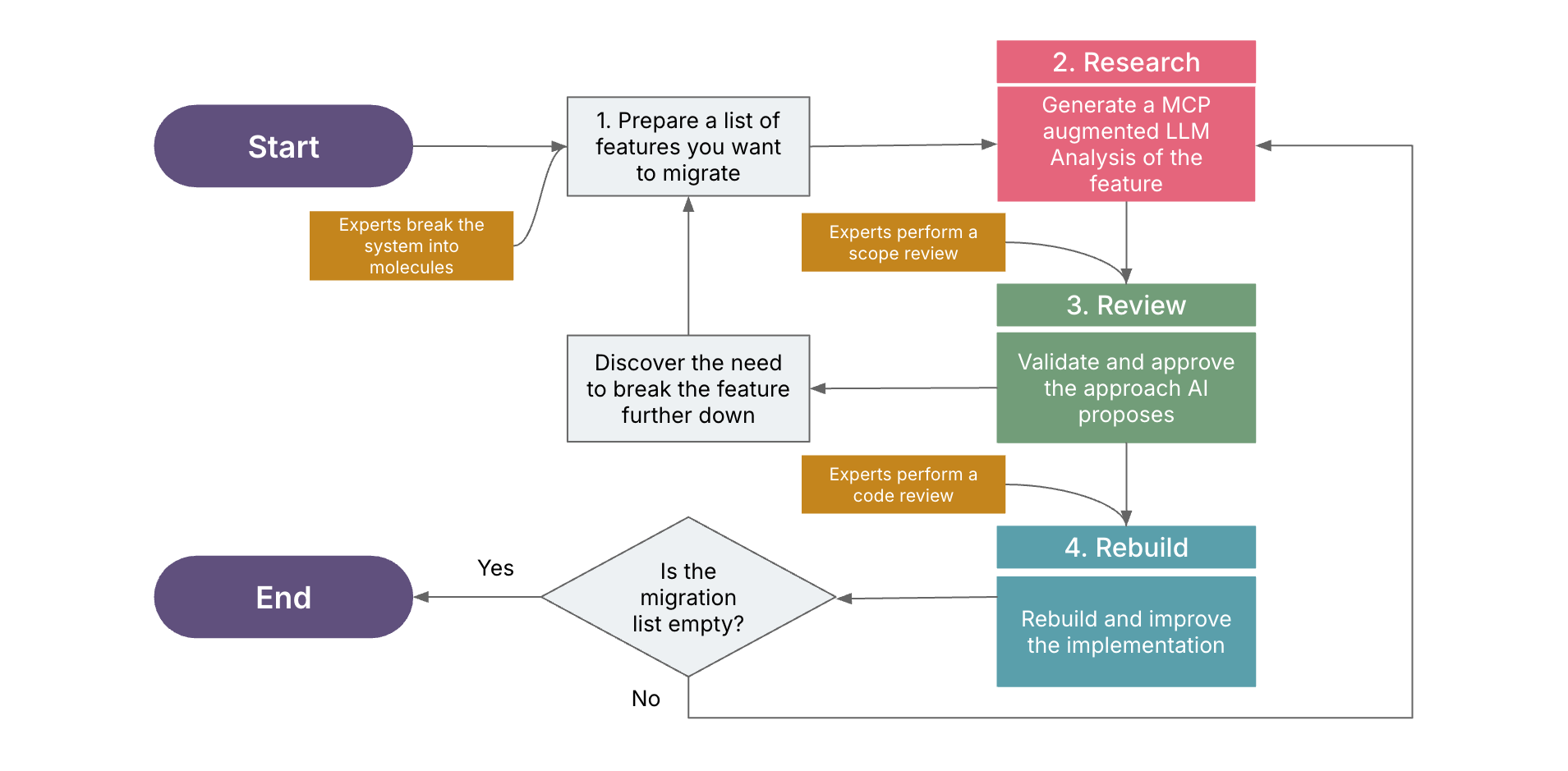
Figure 1: Research, Review, Rebuild Workflow
The workflow I followed is called “Research, Review, Rebuild” — where we do a feature migration research using a couple of MCP servers, validate and approve the approach AI proposes, rebuild the feature and then once all the code generation is done, refactor things that you didn't like.
The Workflow
- Prepare a list of features targeted for migration. Select one feature to begin with.
- Use Model Context Protocol (MCP) servers to research the selected feature by generating a contextual analysis of the selected feature through a Large Language Model (LLM).
- Have domain experts review the generated analysis, ensuring it is accurate, aligns with existing project conventions and architectural guidelines. If the feature is not sufficiently isolated for migration, defer it and update the feature list accordingly.
- Proceed with LLM-assisted rebuild of the validated feature to the target system or framework.
- Until the list is empty, go back to #2
Before Getting Started
Before we proceed with the workflow, it is essential to have a high-level understanding of the existing codebase and determine which components should be retained, discarded, or deferred for future consideration.
In the context of Bahmni, Display Controls are modular, configurable widgets that can be embedded across various pages to enhance the system’s flexibility. Their decoupled nature makes them well-suited for targeted modernization efforts. Bahmni currently includes over 30 display controls developed over time. These controls are highly configurable, allowing healthcare providers to tailor the interface to display pertinent data like diagnoses, treatments, lab results, and more. By leveraging display controls, Bahmni facilitates a customizable and streamlined user experience, aligning with the diverse needs of healthcare settings.
All the existing Bahmni display controls are built over OpenMRS REST endpoint, which is tightly coupled with the OpenMRS data model and specific implementation logic. OpenMRS (Open Medical Record System) is an open-source platform designed to serve as a foundational EMR system primarily for low-resource environments providing customizable and scalable ways to manage health data, especially in developing countries. Bahmni is built on top of OpenMRS, relying on OpenMRS for clinical data modeling and patient record management, using its APIs and data structures. When someone uses Bahmni, they are essentially using OpenMRS as part of a larger system.
FHIR (Fast Healthcare Interoperability Resources) is a modern standard for healthcare data exchange, designed to simplify interoperability by using a flexible, modular approach to represent and share clinical, administrative, and financial data across systems. FHIR was introduced by HL7 (Health Level Seven International), a not-for-profit standards development organization that plays a pivotal role in the healthcare industry by developing frameworks and standards for the exchange, integration, sharing, and retrieval of electronic health information. The term “Health Level Seven” refers to the seventh layer of the OSI (Open Systems Interconnection) model—the application layer, responsible for managing data exchange between distributed systems.
Although FHIR was initiated in 2011, it reached a significant milestone in December 2018 with the release of FHIR Release 4 (R4). This release introduced the first normative content, marking FHIR’s evolution into a stable, production-ready standard suitable for widespread adoption.
Bahmni’s development commenced in early 2013, during a time when FHIR was still in its early stages and had not yet achieved normative status. As such, Bahmni relied heavily on the mature and production-proven OpenMRS REST API. Given Bahmni’s dependence on OpenMRS, the availability of FHIR support in Bahmni was inherently tied to OpenMRS’s adoption of FHIR. Until recently, FHIR support in OpenMRS remained limited, experimental, and lacked comprehensive coverage for many essential resource types.
With the recent advancements in FHIR support within OpenMRS, a key priority in the ongoing migration effort is to architect the target system using FHIR R4. Leveraging FHIR endpoints facilitates standardization, enhances interoperability, and simplifies integration with external systems, aligning the system with globally recognized healthcare data exchange standards.
For the purpose of this experiment, we will focus specifically on the Treatments Display Control as a representative candidate for migration.

Figure 2: Legacy Treatments Display Control built using Angular and integrated with OpenMRS REST endpoints
The Treatment Details Control is a specific type of display control in Bahmni that focuses on presenting comprehensive information about a patient's prescriptions or drug orders over a configurable number of visits. This control is instrumental in providing clinicians with a consolidated view of a patient's treatment history, aiding in informed decision-making. It retrieves data via a REST API, processing it into a view model for UI rendering in a tabular format, supporting both current and historical treatments. The control incorporates error handling, empty state management, and performance optimizations to ensure a robust and efficient user experience.
The data for this control is sourced from the
/openmrs/ws/rest/v1/bahmnicore/drugOrders/prescribedAndActive endpoint,
which returns visitDrugOrders. The visitDrugOrders array contains
detailed entries that link drug orders to specific visits, along with
metadata about the provider, drug concept, and dosing instructions. Each
drug order includes prescription details such as drug name, dosage,
frequency, duration, administration route, start and stop dates, and
standard code mappings (e.g., WHOATC, CIEL, SNOMED-CT, RxNORM).
Here is a sample JSON response from Bahmni’s /bahmnicore/drugOrders/prescribedAndActive REST API endpoint containing detailed information about a patient's drug orders during a specific visit, including metadata like drug name, dosage, frequency, duration, route, and prescribing provider.
{
"visitDrugOrders": [
{
"visit": {
"uuid": "3145cef3-abfa-4287-889d-c61154428429",
"startDateTime": 1750033721000
},
"drugOrder": {
"concept": {
"uuid": "70116AAAAAAAAAAAAAAAAAAAAAAAAAAAAAAA",
"name": "Acetaminophen",
"dataType": "N/A",
"shortName": "Acetaminophen",
"units": null,
"conceptClass": "Drug",
"hiNormal": null,
"lowNormal": null,
"set": false,
"mappings": [
{
"code": "70116",
"name": null,
"source": "CIEL"
},y
/* Response Truncated */
]
},
"instructions": null,
"uuid": "a8a2e7d6-50cf-4e3e-8693-98ff212eee1b",
show rest of json
"orderType": "Drug Order",
"accessionNumber": null,
"orderGroup": null,
"dateCreated": null,
"dateChanged": null,
"dateStopped": null,
"orderNumber": "ORD-1",
"careSetting": "OUTPATIENT",
"action": "NEW",
"commentToFulfiller": null,
"autoExpireDate": 1750206569000,
"urgency": null,
"previousOrderUuid": null,
"drug": {
"name": "Paracetamol 500 mg",
"uuid": "e8265115-66d3-459c-852e-b9963b2e38eb",
"form": "Tablet",
"strength": "500 mg"
},
"drugNonCoded": null,
"dosingInstructionType": "org.openmrs.module.bahmniemrapi.drugorder.dosinginstructions.FlexibleDosingInstructions",
"dosingInstructions": {
"dose": 1.0,
"doseUnits": "Tablet",
"route": "Oral",
"frequency": "Twice a day",
"asNeeded": false,
"administrationInstructions": "{\"instructions\":\"As directed\"}",
"quantity": 4.0,
"quantityUnits": "Tablet",
"numberOfRefills": null
},
"dateActivated": 1750033770000,
"scheduledDate": 1750033770000,
"effectiveStartDate": 1750033770000,
"effectiveStopDate": 1750206569000,
"orderReasonText": null,
"duration": 2,
"durationUnits": "Days",
"voided": false,
"voidReason": null,
"orderReasonConcept": null,
"sortWeight": null,
"conceptUuid": "70116AAAAAAAAAAAAAAAAAAAAAAAAAAAAAAA"
},
"provider": {
"uuid": "d7a67c17-5e07-11ef-8f7c-0242ac120002",
"name": "Super Man",
"encounterRoleUuid": null
},
"orderAttributes": null,
"retired": false,
"encounterUuid": "fe91544a-4b6b-4bb0-88de-2f9669f86a25",
"creatorName": "Super Man",
"orderReasonConcept": null,
"orderReasonText": null,
"dosingInstructionType": "org.openmrs.module.bahmniemrapi.drugorder.dosinginstructions.FlexibleDosingInstructions",
"previousOrderUuid": null,
"concept": {
"uuid": "70116AAAAAAAAAAAAAAAAAAAAAAAAAAAAAAA",
"name": "Acetaminophen",
"dataType": "N/A",
"shortName": "Acetaminophen",
"units": null,
"conceptClass": "Drug",
"hiNormal": null,
"lowNormal": null,
"set": false,
"mappings": [
{
"code": "70116",
"name": null,
"source": "CIEL"
},
/* Response Truncated */
]
},
"sortWeight": null,
"uuid": "a8a2e7d6-50cf-4e3e-8693-98ff212eee1b",
"effectiveStartDate": 1750033770000,
"effectiveStopDate": 1750206569000,
"orderGroup": null,
"autoExpireDate": 1750206569000,
"scheduledDate": 1750033770000,
"dateStopped": null,
"instructions": null,
"dateActivated": 1750033770000,
"commentToFulfiller": null,
"orderNumber": "ORD-1",
"careSetting": "OUTPATIENT",
"orderType": "Drug Order",
"drug": {
"name": "Paracetamol 500 mg",
"uuid": "e8265115-66d3-459c-852e-b9963b2e38eb",
"form": "Tablet",
"strength": "500 mg"
},
"dosingInstructions": {
"dose": 1.0,
"doseUnits": "Tablet",
"route": "Oral",
"frequency": "Twice a day",
"asNeeded": false,
"administrationInstructions": "{\"instructions\":\"As directed\"}",
"quantity": 4.0,
"quantityUnits": "Tablet",
"numberOfRefills": null
},
"durationUnits": "Days",
"drugNonCoded": null,
"action": "NEW",
"duration": 2
}
]
}
The /bahmnicore/drugOrders/prescribedAndActive model differs significantly
from the OpenMRS FHIR
MedicationRequest
model in both structure and representation. While the Bahmni REST model is
tailored for UI rendering with visit-context grouping and includes
OpenMRS-specific constructs like concept, drug, orderNumber, and flexible
dosing instructions, the FHIR MedicationRequest model adheres to international
standards with a normalized, reference-based structure using resources such as
Medication, Encounter, Practitioner, and coded elements in
CodeableConcept and Timing.
Research
The “Research” phase of the approach involves generating an MCP-augmented LLM analysis of the selected Display Control. This phase is centered around understanding the legacy system’s behavior by examining its source code and conducting reverse engineering. Such analysis is essential for informing the forward engineering efforts. While not all identified requirements may be carried forward—particularly in long-lived systems where certain functionalities may have become obsolete—it is critical to have a clear understanding of existing behaviors. This enables teams to make informed decisions about which elements to retain, discard, or redesign in the target system, ensuring that the modernization effort aligns with current business needs and technical goals.
At this stage, it is helpful to take a step back and consider how human developers typically approach a migration of this nature. One key insight is that migrating from Angular to React relies heavily on contextual understanding. Developers must draw upon various dimensions of knowledge to ensure a successful and meaningful transition. The critical areas of focus typically include:
- Purpose Evaluation: understanding the functional intent and role of the existing Angular components within the broader application.
- Data Model Analysis: reviewing the underlying data structures and their relationships to assess compatibility with the new architecture.
- Data Flow Mapping: tracing how data moves from backend APIs to the frontend UI to ensure continuity in the user experience.
- FHIR Model Alignment: identifying whether the current data model can be mapped to an HL7 FHIR-compatible structure, where applicable.
- Comparative Analysis: evaluating structural and functional similarities, differences, and potential gaps between the old and target implementations.
- Performance Considerations: taking into account areas for performance enhancement in the new system.
- Feature Relevance: assessing which features should be carried forward, redesigned, or deprecated based on current business needs.
This context-driven analysis is often the most challenging aspect of any legacy migration. Importantly, modernization is not merely about replacing outdated technologies—it is about reimagining the future of the system and the business it supports. It involves the evolution of the application across its entire lifecycle, including its architecture, data structures, and user experience.
The expertise of subject matter experts (SMEs) and domain specialists is crucial to understand existing behavior and to prepare a guide for the migration. And what better way to capture the expected behavior than through well-defined test scenarios against which the migrated code will be evaluated. Understanding what scenarios are to be tested is critical not just in making sure that - everything that used to work still works and the new behavior would work as expected but also because now your LLM has a clearly defined set of goals that it knows is what's expected. By defining these goals explicitly, we can make the LLM's responses as deterministic as possible, avoiding the unpredictability of probabilistic responses and ensuring more reliable outcomes during the migration process.
Based on this understanding, I developed a comprehensive and strategically structured prompt designed to capture all relevant information effectively.
While the prompt covers all expected areas—such as data flow, configuration, key functions, and integration—it also includes several sections that warrant specific mention:
- FHIR Compatibility: this section maps the custom Bahmni data model to HL7 FHIR resources and highlights gaps, thereby supporting future interoperability efforts. Completing this mapping requires a solid understanding of FHIR concepts and resource structures, and can be a time-consuming task. It typically involves several hours of detailed analysis to ensure accurate alignment, compatibility verification, and identification of divergences between the OpenMRS and FHIR medication models, which can now be done in a matter of seconds.
- Testing Guidelines for React + TypeScript Implementation Over OpenMRS FHIR: this section offers structured test scenarios that emphasize data handling, rendering accuracy, and FHIR compliance for the modernized frontend components. It serves as an excellent foundation for the development process, setting out a mandatory set of criteria that the LLM should satisfy while rebuilding the component.
- Customization Options: this outlines available extension points and configuration mechanisms that enhance maintainability and adaptability across diverse implementation scenarios. While some of these options are documented, the LLM-generated analysis often uncovers additional customization paths embedded in the codebase. This helps identify legacy customization approaches more effectively and ensures a more exhaustive understanding of current capabilities.
To gather the necessary data, I utilized two lightweight servers:
- An Atlassian MCP server to extract any available documentation on the display control.
- A filesystem MCP server, where the legacy frontend code and configuration were mounted, to provide source code-level analysis.
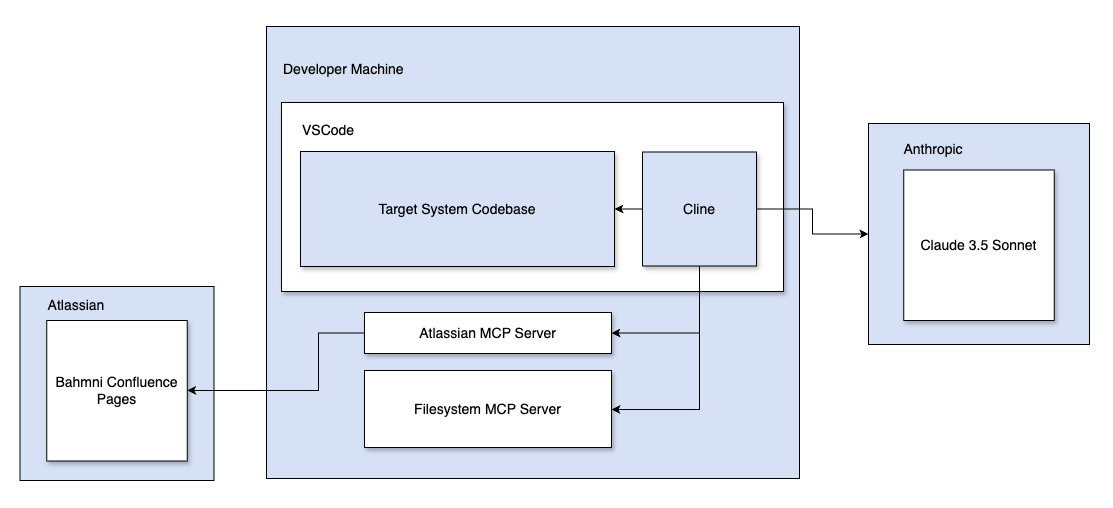
Figure 3: MCP + Cline + Claude Setup Diagram
While optional, this filesystem server allowed me to focus on the target system's code within my IDE, with the legacy reference codebases conveniently accessible through the mounted server.
These light weight servers each expose specific capabilities through the standardized Model Context Protocol, which is then used by Cline (my client in this case) to access the code base, documentation and configuration. Since the configurations shipped are opinionated and the documents often outdated, I added specific instructions to take the source code as the single source of truth and the rest as a supplementary reference.
Review
The second phase of the approach —is where the human in the loop becomes invaluable.
The AI-generated analysis isn't intended to be accepted at face value, especially for complex codebases. You’ll still need a domain expert and an architect to vet, contextualize, and guide the migration process. AI alone isn't going to migrate an entire project seamlessly; it requires thoughtful decomposition, clear boundaries, and iterative validation.
Not all these requirements will necessarily be incorporated into the target system, for example the ability to print a prescription sheet based on the medications prescribed is deferred for now.
In this case, I augmented the analysis with sample responses from the FHIR endpoint and while discarding aspects of the system that are not relevant to the modernization effort. This includes performance optimizations, test cases that are not directly relevant to the migration, and configuration options such as the number of rows to display and whether to show active or inactive medications. I felt these can be addressed as part of the next iteration.
For instance, consider the unit test scenarios defined for rendering treatment data:
✅ Happy Path
It should correctly render the drugName column.
It should correctly render the status column with the appropriate Tag color.
It should correctly render the priority column with the correct priority Tag.
It should correctly render the provider column.
It should correctly render the startDate column.
It should correctly render the duration column.
It should correctly render the frequency column.
It should correctly render the route column.
It should correctly render the doseQuantity column.
It should correctly render the instruction column.
❌ Sad Path
It should show a “-” if startDate is missing.
It should show a “-” if frequency is missing.
It should show a “-” if route is missing.
It should show a “-” if doseQuantity is missing.
It should show a “-” if instruction is missing.
It should handle cases where the row data is undefined or null.
Replacing missing values with “-” in the sad path scenarios has been removed, as it does not align with the requirements of the target system. Such decisions should be guided by input from the subject matter experts (SMEs) and stakeholders, ensuring that only functionality relevant to the current business context is retained.
The literature gathered on the display control now needs to be coupled with project conventions, practices, and guidelines without which the LLM is open to interpret the above request, on the data that it was trained with. This includes access to functions that can be reused, sample data models and services and reusable atomic components that the LLMs can now rely on. If such practices, style guides and guidelines are not clearly defined, every iteration of the migration risks producing non-conforming code. Over time, this can contribute to a fragmented codebase and an accumulation of technical debt.
The core objective is to define clear, project-specific coding standards and style guides to ensure consistency in the generated code. These standards act as a foundational reference for the LLM, enabling it to produce output that aligns with established conventions. For example, the Google TypeScript Style Guide can be summarized and documented as a TypeScript style guide stored in the target codebase. This file is then read by Cline at the start of each session to ensure that all generated TypeScript code adheres to a consistent and recognized standard.
Rebuild
Rebuilding the feature for a target system with LLM-generated code is the final phase of the workflow. Now with all the required data gathered, we can get started with a simple prompt
At this stage, the LLM generates the initial code and test scenarios, leveraging the information provided. Once this output is produced, it is essential for domain experts and developers to conduct a thorough code review and apply any necessary refactoring to ensure alignment with project standards, functionality requirements, and long-term maintainability.
Refactoring the LLM-generated code is critical to ensuring the code remains clean and maintainable. Without proper refactoring, the result could be a disorganized collection of code fragments rather than a cohesive, efficient system. Given the probabilistic nature of LLMs and the potential discrepancies between the generated code and the original objectives, it is essential to involve domain experts and SMEs at this stage. Their role is to thoroughly review the code, validate that the output aligns with the initial expectations, and assess whether the migration has been successfully executed. This expert involvement is crucial to ensure the quality, accuracy, and overall success of the migration process.
This phase should be approached as a comprehensive code review—similar to reviewing the work of a senior developer who possesses strong language and framework expertise but lacks familiarity with the specific project context. While technical proficiency is essential, building robust systems requires a deeper understanding of domain-specific nuances, architectural decisions, and long-term maintainability. In this context, the human-in-the-loop plays a pivotal role, bringing the contextual awareness and system-level understanding that automated tools or LLMs may lack. It is a crucial process to ensure that the generated code integrates seamlessly with the broader system architecture and aligns with project-specific requirements.
In our case, the intent and context of the rebuild were clearly defined, which minimized the need for post-review refactoring. The requirements gathered during the research phase—combined with clearly articulated project conventions, technology stack, coding standards, and style guides—ensured that the LLM had minimal ambiguity when generating code. As a result, there was little left for the LLM to infer independently.
That said, any unresolved questions regarding the implementation plan can lead to deviations from the expected output. While it is not feasible to anticipate and answer every such question in advance, it is important to acknowledge the inevitability of “unknown unknowns.” This is precisely where a thorough review becomes essential.
In this particular instance, my familiarity with the display control we were rebuilding allowed me to proactively minimize such unknowns. However, this level of context may not always be available. Therefore, I strongly recommend conducting a detailed code review to help uncover these hidden gaps. If recurring issues are identified, the prompt can then be refined to address them preemptively in future iterations.
The allure of LLMs is undeniable; they offer a seemingly effortless solution to complex problems, and developers can often create such a solution quickly and without needing years of deep coding experience. This should not create a bias in the experts, succumbing to the allure of LLMs and eventually take their hands off the wheel.
Outcome
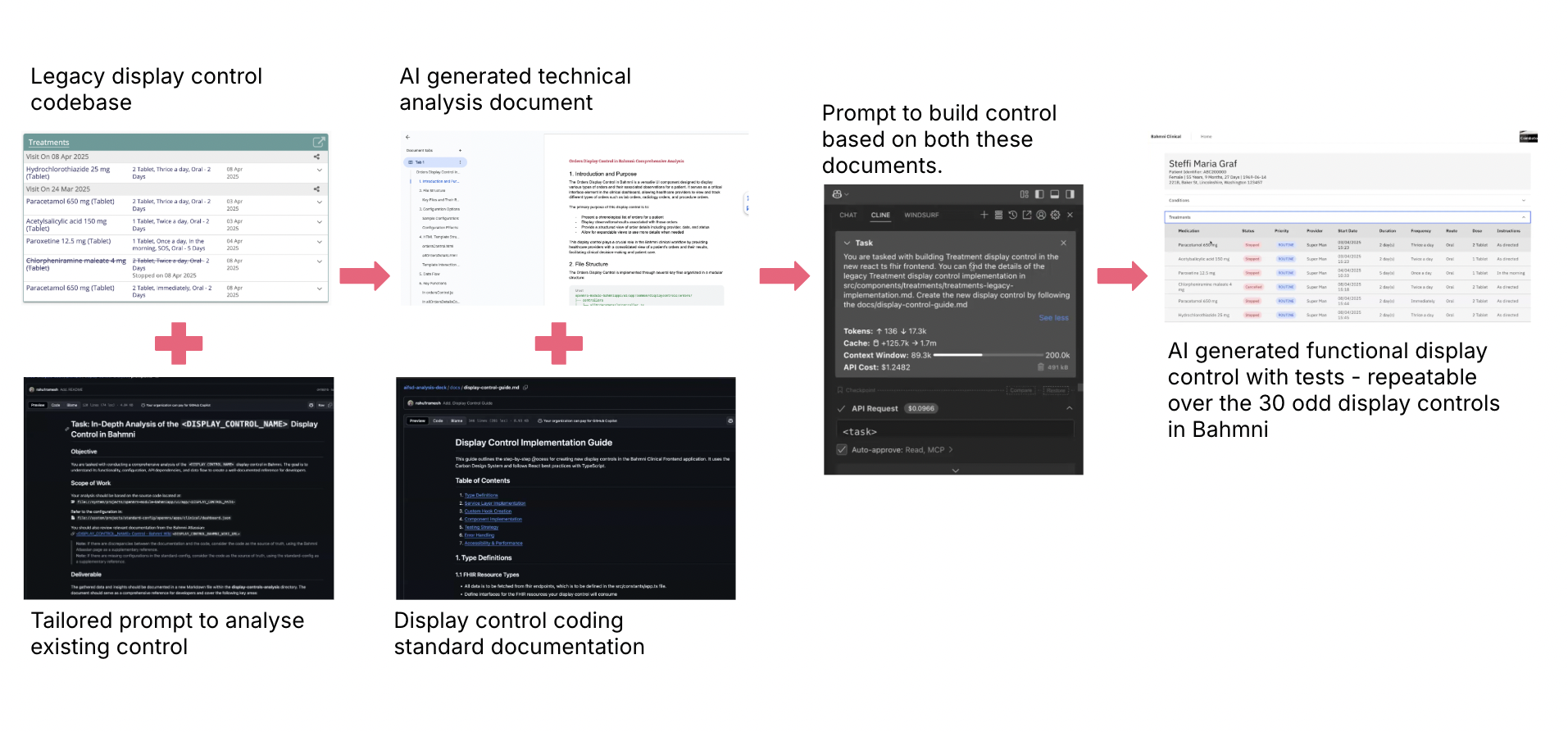
Figure 4: A high level overview of the process; taking a feature from the legacy codebase and using LLM-assisted analysis to rebuild it within the target system
In my case the code generation process took about 10 minutes to complete. The analysis and implementation, including both unit and integration tests with approximately 95% coverage, were completed using Claude 3.5 Sonnet (20241022). The total cost for this effort was about $2.
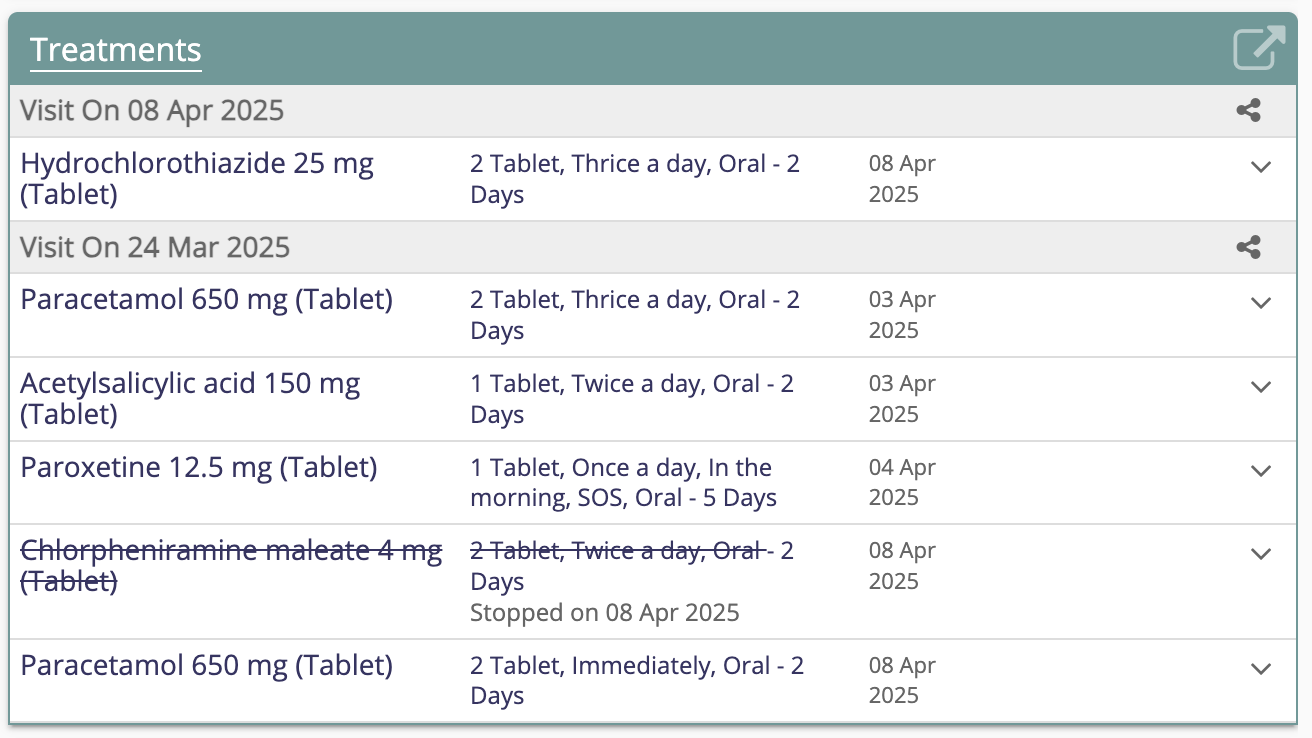
Figure 5: Legacy Treatments Display Control built using Angular and integrated with OpenMRS REST endpoints
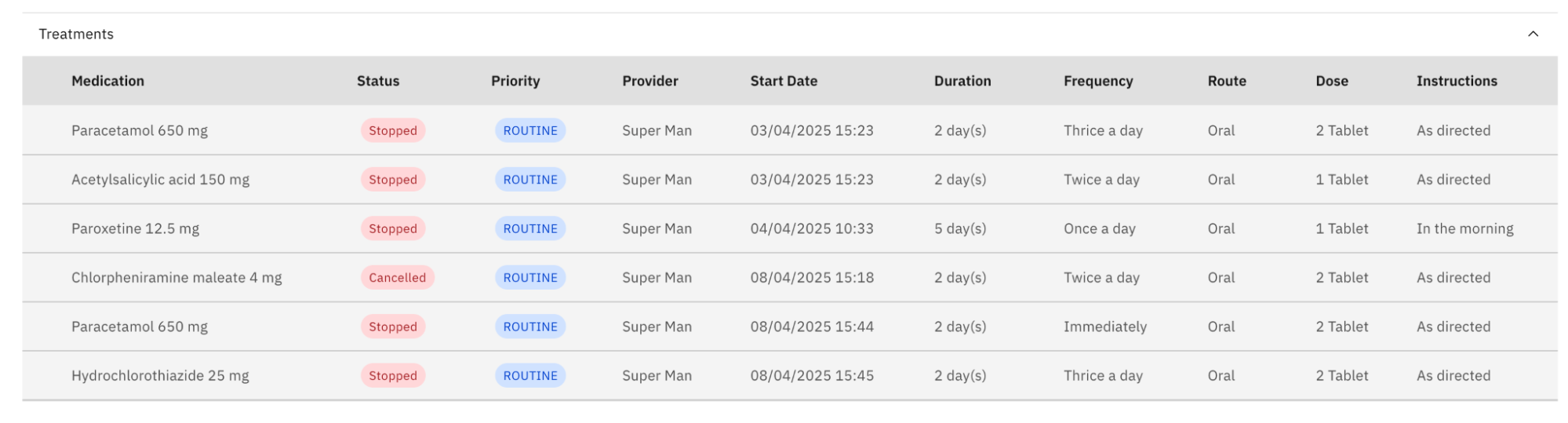
Figure 6: Modernized Treatments Display Control rebuilt using React and TypeScript, leveraging FHIR endpoints
Without AI support, both the technical analysis and implementation would have likely taken a developer a minimum of two to three days. In my case, developing a reusable, general-purpose prompt—grounded in the shared architectural principles behind the approximately 30 display controls in Bahmni—took about five focused iterations over four hours, at a slightly higher inference cost of around $10 across those cycles. This effort was essential to ensure the generated prompt was modular and broadly applicable, given that each display control in Bahmni is essentially a configurable, embeddable widget designed to enhance system flexibility across different clinical dashboards.
Even with AI-assisted generation, one of the key costs in development remains the time and cognitive load required to analyze, review, and validate the output. Thanks to my prior experience with Bahmni, I was able to review the generated analysis in under 15 minutes, supplementing it with quick parallel research to validate the claims and data mappings. I was pleasantly surprised by the quality of the analysis: the data model mapping was precise, the logic for transformation was sound, and the test case suggestions covered a comprehensive range of scenarios, both typical and edge cases.
Code review, however, emerged as the most significant challenge. Reviewing the generated code line by line across all changes took me approximately 20 minutes. Unlike pairing with a human developer—where iterative discussions occur at a manageable pace—working with an AI system capable of generating entire modules within seconds creates a bottleneck on the human side, especially when attempting line-by-line scrutiny. This isn’t a limitation of the AI itself, but rather a reflection of human review capacity. While AI-assisted code reviewers are often proposed as a solution, they can generally identify syntactic issues, adherence to best practices, and potential anti-patterns—but they struggle to assess intent, which is critical in legacy migration projects. This intent, grounded in domain context and business logic, must still be confirmed by the human in the loop.
For a legacy modernization project involving a migration from AngularJS to React, I would rate this experience an absolute 10/10. This capability opens up the possibility for any individuals with decent technical expertise and strong domain knowledge to migrate any legacy codebase to a modern stack with minimal effort and in significantly less time.
I believe that with a bottom-up approach, breaking the problem down into atomic components, and clearly defining best practices and guidelines, AI-generated code could greatly accelerate delivery timelines—even for complex brownfield projects as we saw for Bahmni.
The initial analysis and the subsequent review by experts results in a crisp enough document that lets us use the limited space in the context window in an efficient way so we can fit more information into one single prompt. Effectively, this allows the LLM to analyze code in a way that is not limited by how the code is organized in the first place by developers. This also results in reducing the overall cost of using LLMs, as a brute force approach would mean that you spend 10 times as much even for a much simpler project.
While modernizing the legacy codebase is the main product of this proposed approach, it is not the only valuable one. The documentation generated about the system is valuable when provided not just to the end users / implementers in complementing or filling gaps in existing systems documentation and also would stand in as a knowledge base about the system for forward engineering teams pairing with LLMs to enhance or enrich system capabilities.
Why the Review Phase Matters
A key enabler of this successful migration was a well-structured plan
and detailed scope review phase prior to implementation. This early
investment paid dividends during the code generation phase. Without a
clear understanding of the data flow, configuration structure, and
display logic, the AI would have struggled to produce coherent and
maintainable outputs. If you have worked with AI before, you may have
noticed that it is consistently eager to generate output. In an earlier
attempt, I proceeded without sufficient caution and skipped the review
step—only to discover that the generated code included a useMemo hook
for an operation that was computationally trivial. One of the success
criteria in the generated analysis was that the code should be
performant, and this appeared to be the AI’s way of fulfilling that
requirement.
Interestingly, the AI even added unit tests to validate the performance of that specific operation. However, none of this was explicitly required. It arose solely due to a poorly defined intent. AI incorporated these changes without hesitation, despite not fully understanding the underlying requirements or seeking clarification. Reviewing both the generated analysis and the corresponding code ensures that unintended additions are identified early and that deviations from the original expectations are minimized.
Review also plays a key role in avoiding unnecessary back-and-forth with the AI during the rebuild phase. For instance, while refining the prompt for the “Display Control Implementation Guide”, I initially didn’t have the section specifying the unit tests to be included. As a result, the AI generated a test that was largely meaningless—offering a false sense of test coverage with no real connection to the code under test.
Figure 7: AI generated unit test that verifies reality is still real
In an attempt to fix this test, I began prompting extensively—providing examples and detailed instructions on how the unit test should be structured. However, the more I prompted, the further the process deviated from the original objective of rebuilding the display control. The focus shifted entirely to resolving unit test issues, with the AI even beginning to review unrelated tests in the codebase and suggesting fixes for problems it identified there.
Eventually, realizing the increasing divergence from the intended task, I restarted the process with clearly defined instructions from the outset, which proved to be far more effective.
This leads us to a crucial insight: Don't Interrupt AI.
LLMs, at their core, are predictive sequence generators that build narratives token by token. When you interrupt a model mid-stream to course-correct, you break the logical flow it was constructing. Stanford’s “Lost in the Middle” study revealed that models can suffer up to a 20% drop in accuracy when critical information is buried in the middle of long contexts, versus when it’s clearly framed upfront. This underscores why starting with a well-defined prompt and letting the AI complete its task unimpeded often yields better results than constant backtracking or mid-flight corrections.
This idea is also reinforced in “Why Human Intent Matters More as AI Capabilities Grow” by Nick Baumann, which argues that as model capabilities scale, clear human intent—not just brute model strength—becomes the key to unlocking useful output. Rather than micromanaging every response, practitioners benefit most by designing clean, unambiguous setups and letting the AI complete the arc without interruption.
Conclusion
It is important to clarify that this approach is not intended to be a silver bullet capable of executing a large-scale migration without oversight. Rather, its strength lies in its ability to significantly reduce development time—potentially by several weeks—while maintaining quality and control.
The goal isn't to replace human expertise but to amplify it—to accelerate delivery timelines while ensuring that quality and maintainability are preserved, if not improved, during the transition.
It is also important to note that the experience and results discussed thus far are limited to read-only controls. More complex or interactive components may present additional challenges that require further evaluation and refinement of the prompts used.
One of the key insights from exploring GenAI for legacy migration is that while large language models (LLMs) excel at general-purpose tasks and predefined workflows, their true potential in large-scale business transformation is only realized when guided by human expertise. This is well illustrated by Moravec’s Paradox, which observes that tasks perceived as intellectually complex—such as logical reasoning—are relatively easier for AI, whereas tasks requiring human intuition and contextual understanding remain challenging. In the context of legacy modernization, this paradox reinforces the importance of subject matter experts (SMEs) and domain specialists, whose deep experience, contextual understanding, and intuition are indispensable. Their expertise enables more accurate interpretation of requirements, validation of AI-generated outputs, and informed decision-making—ultimately ensuring that the transformation is aligned with the organization’s goals and constraints.
While project-specific complexities may render this approach ambitious, I believe that by adopting this structured workflow, AI-generated code can significantly accelerate delivery timelines—even in the context of complex brownfield projects. The intent is not to replace human expertise, but to augment it—streamlining development while safeguarding, and potentially enhancing, code quality and maintainability. Although the quality and architectural soundness of the legacy system remain critical factors, this methodology offers a strong starting point. It reduces manual overhead, creates forward momentum, and lays the groundwork for cleaner and more maintainable implementations through expert-led, guided refactoring.
I firmly believe following this workflow opens up the possibility for any individuals with decent technical expertise and strong domain knowledge to migrate any legacy codebase to a modern stack with minimal effort and in significantly less time.
Significant Revisions
27 August 2025: published