
From Black Box to Blueprint
AI in Reverse Engineering
A common enterprise problem: crucial legacy systems become “black boxes”—key to operations but opaque and risky to touch. We worked with a client to use AI-assisted reverse engineering to reconstruct functional specifications from UI elements, binaries, and data lineage to overcome analysis paralysis. We developed a methodical “multi-lens” approach—starting from visible artifacts, enriching incrementally, triangulating logic, and always preserving lineage. Human validation remains central to ensure accuracy and confidence in extracted functionality. This engagement revealed that turning a system from black box to blueprint empowers modernization decisions and accelerates migration efforts.
28 August 2025

Thiyagu Palanisamy, Global Head of Technology for Retail at Thoughtworks, brings 25 years of deep technology expertise; delivering measurable business impacts for retailers. Leading large scale modernizations to help clients reimagine the future of retail has been a firm passion.

Chandru is a technical partner and retail tech specialist at Thoughtworks. He comes with 16 years of ThoughtWorks experience, enjoys infrastructure, platform engineering, and participating in stack overflow.
A remarkably common case in large established enterprises is that there are systems that nobody wants to touch, but everyone depends on. They run payrolls, handle logistics, reconcile inventory, or process customer orders. They’ve been in place and evolving slowly for decades, built on stacks no one teaches anymore, and maintained by a shrinking pool of experts. It’s hard to find a person (or a team) that can confidently say that they know the system well and are ready to provide the functional specs. This situation leads to a really long cycle of analysis, and many programs get long delayed or stopped mid way because of the Analysis Paralysis.
These systems often live inside frozen environments: outdated databases, legacy operating systems, brittle VMs. Documentation is either missing or hopelessly out of sync with reality. The people who wrote the code have long since moved on. Yet the business logic they embody is still critical to daily operations of thousands of users. The result is what we call a black box: a system whose outputs we can observe, but whose inner workings remain opaque. For CXOs and technology leaders, these black boxes create a modernization deadlock
- Too risky to replace without fully understanding them
- Too costly to maintain on life support
- Too critical to ignore
This is where AI-assisted reverse engineering becomes not just a technical curiosity, but a strategic enabler. By reconstructing the functional intent of a system,even if it’s missing the source code, we can turn fear and opacity into clarity. And with clarity comes the confidence to modernize.
The System we Encountered
The system itself was vast in both scale and complexity. Its databases across multiple platforms contained more than 650 tables and 1,200 stored procedures, reflecting decades of evolving business rules. Functionality extended across 24 business domains and was presented through nearly 350 user screens. Behind the scenes, the application tier consisted of 45 compiled DLLs, each with thousands of functions and virtually no surviving documentation. This intricate mesh of data, logic, and user workflows, tightly integrated with multiple enterprise systems and databases, made the application extremely challenging to modernize
Our task was to carry out an experiment to see if we could use AI to create a functional specification of the existing system with sufficient detail to drive the implementation of a replacement system. We completed the experiment phase for an end to end thin slice with reverse and forward engineering. Our confidence level is more than high because we did multiple levels of cross checking and verification. We walked through the reverse engineered functional spec with sys-admin / users to confirm the intended functionality and also verified that the spec we generated is sufficient for forward engineering as well.
The client issued an RFP for this work, with we estimated would take 6 months for a team of peak 20 people. Sadly for us, they decided to work with one of their existing preferred partners, so we won't be able to see how our experiment scales to the full system in practice. We do, however, think we learned enough from the exercise to be worth sharing with our professional colleagues.
Key Challenges
- Missing Source Code: legacy understanding is already complex when you
have source code and an SME (in some form) to put everything together. When the
source code is missing and there are no experts it is an even greater challenge.
What’s left are some compiled binaries. These are not the recent binaries that
are easy to decompile due to rich metadata (like .NET assemblies or JARs), these
are even older binaries: the kind that you might see in old windows XP under
C:\\Windows\\system32. Even when the database is accessible, it does not tell the whole story. Stored procedures and triggers encode decades of accumulated business rules. Schema reflects compromises made based on context unknown. - Outdated Infrastructure: OS and DB reached end of life, long past its LTS. Application has been in a frozen state in the form of VM leading to significant risk to not only business continuity, also significantly increasing security vulnerability, non compliance and risk liability.
- Institutional Knowledge Lost: while thousands of end users are continuously using the system, there is hardly any business knowledge available beyond the occasional support activities. The live system is the best source of knowledge. The only reliable view of functionality is what users see on screen. But the UI captures only the “last mile” of execution. Behind each screen lies a tangled web of logic deeply integrated to multiple other core systems. This is a common challenge, and this system was no exception, having a history of multiple failed attempts to modernize.
Our Goal
The objective is to create a rich, comprehensive functional specification of the legacy system without needing its original code, but with high confidence. This specification then serves as the blueprint for building a modern replacement application from a clean slate.
- Understand overall picture of the system boundary and the integration patterns
- Build detailed understanding of each functional area
- Identify the common and exceptional scenarios
To make sense of a black-box system, we needed a structured way to pull together fragments from different sources. Our principle was simple: don’t try to recover the code — reconstruct the functional intent.
Our Multi Lens Approach
It was a 3 tier architecture - Web Tier (ASP), App Tier (DLL) and Persistence (SQL). This architecture pattern gave us a jump start even without source repo. We extracted ASP files and DB schema, stored procedures from the production system. For App Tier we only have the native binaries. With all this information available, we planned to create a semi-structured description of application behavior in natural language for the business users to validate their understanding and expectations and use the validated functional spec to do accelerated forward engineering. For the semi-structured description, our approach had broadly two parts
- Using AI to connect dots across different data sources
- AI assisted binary Archaeology to uncover the hidden functionality from the native DLL files
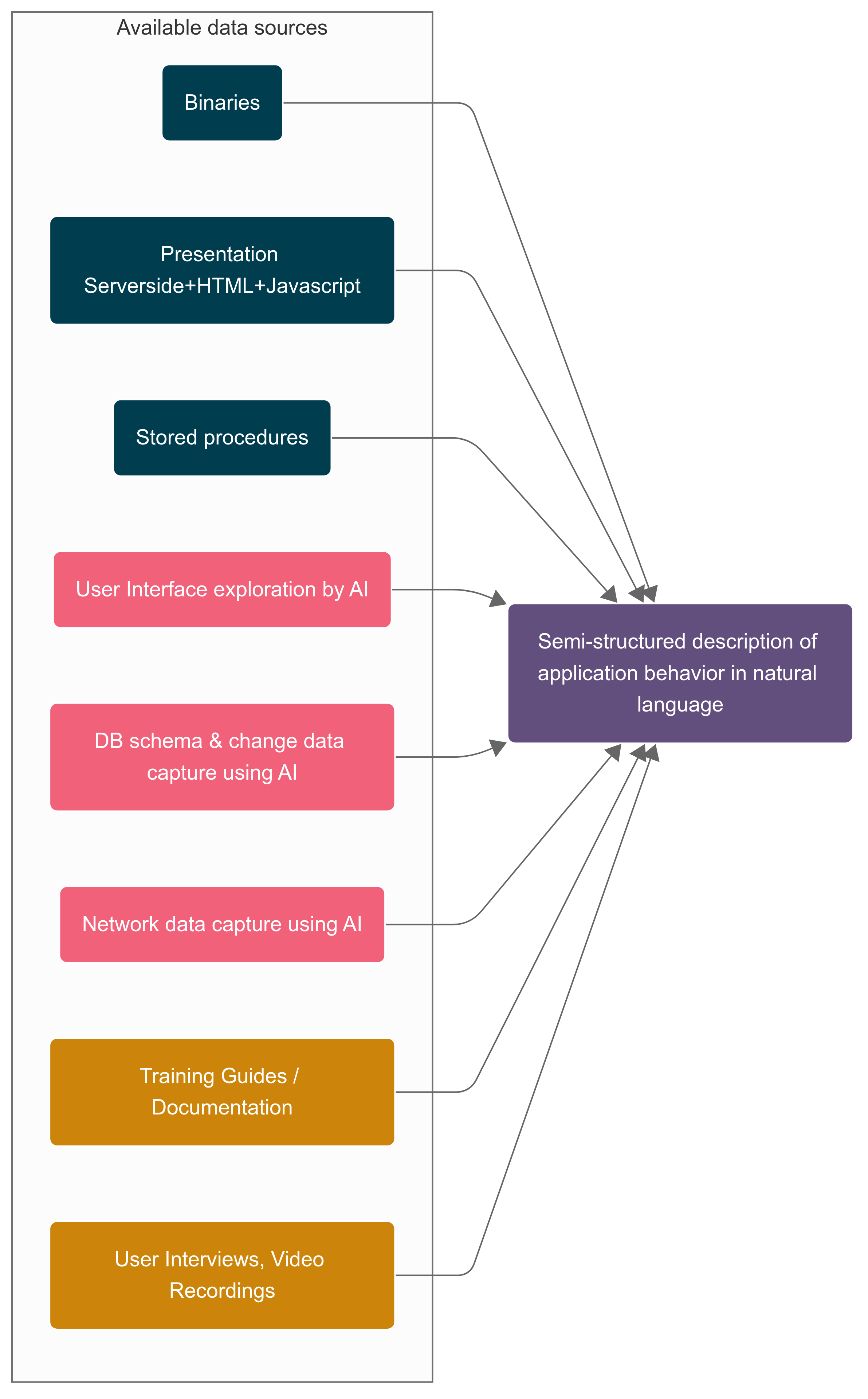
Connect dots across different data sources
UI Layer Reconstruction
Browsing the existing live application and screenshots, we identified the UI elements. Using the ASP and JS content the dynamic behaviour associated with the UI element could be added. This gave us a UI spec like below:
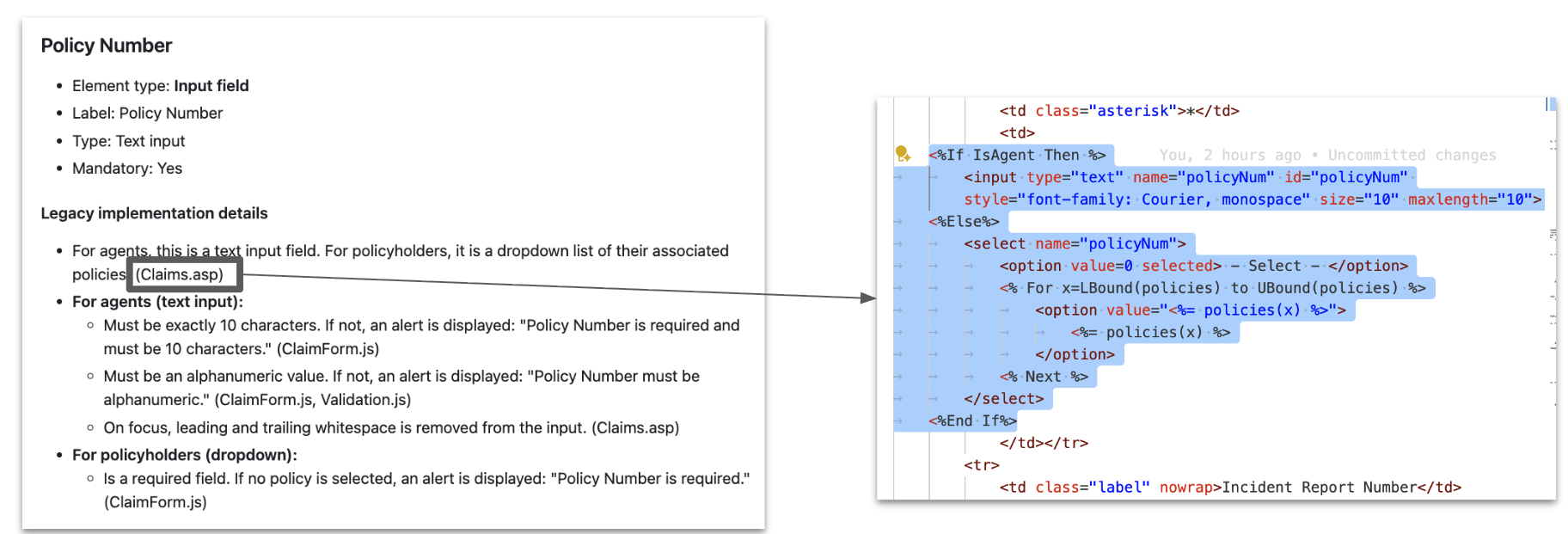
What we looked for: validation rules, navigation paths, hidden fields. One of the key challenges we faced from the early stage was hallucination, every step we added a detailed lineage to ensure that we cross check and confirm. In the above example we had the lineage of where it comes from. Following this pattern, for every key information we added the lineage along with the context. Here the LLM really sped up the summarizing of large numbers of screen definitions and consolidating logic from ASP and JS sources with the already identified UI layouts and field descriptions that would otherwise take weeks to create and consolidate.
Discovery with Change Data Capture (CDC)
We planned to use Change Data Capture (CDC) to trace how UI actions mapped to database activity, retrieving change logs from MCP servers to track the workflows. Environment constraints meant CDC could only be enabled partially, limiting the breadth of captured data.
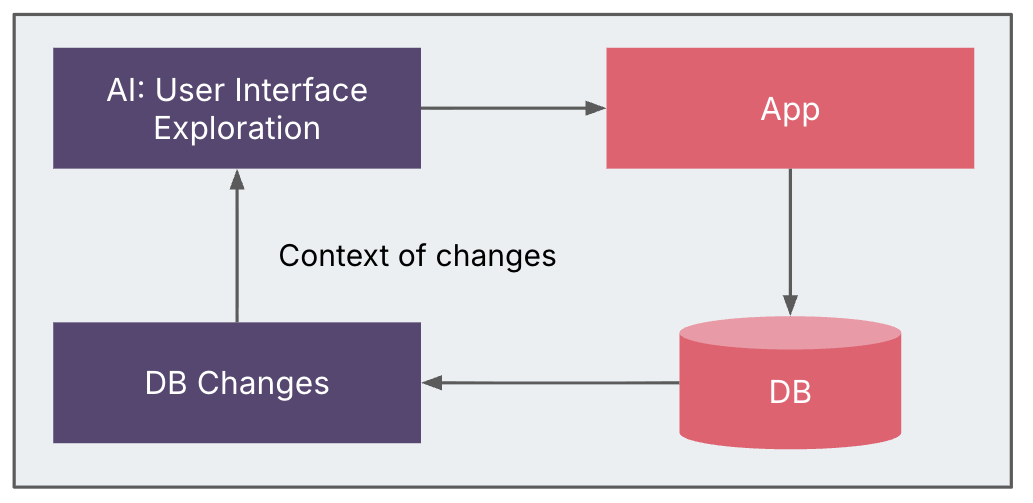
Other potential sources—such as front-end/back-end network traffic, filesystem changes, additional persistence layers, or even debugging breakpoints—remain viable options for finer-grained discovery. Even with partial CDC, the insights proved valuable in linking UI behavior to underlying data changes and enriching the system blueprint.
Server Logic Inferance
We then added more context by supplying typelibs that were extracted from the native binaries, and stored procedures, and schema extracted from the database. At this point with information about layout, presentation logic, and DB changes, the server logic can be inferred, which stored procedures are likely called, and which tables are involved for most methods and interfaces defined in the native binaries. This process leads to an Inferred Server Logic Spec. LLM helped in proposing likely relationships between App tier code and procedures / tables, which we then validated through observed data flows.

AI assisted Binary Archaeology
The most opaque layer was the compiled binaries (DLLs, executables). Here, we treated binaries as artifacts to be decoded rather than rebuilt. What we looked for: call trees, recurring assembly patterns, candidate entry points. AI assisted in bulk summarizing disassembled code into human-readable hypotheses, flagging probable function roles — always validated by human experts.
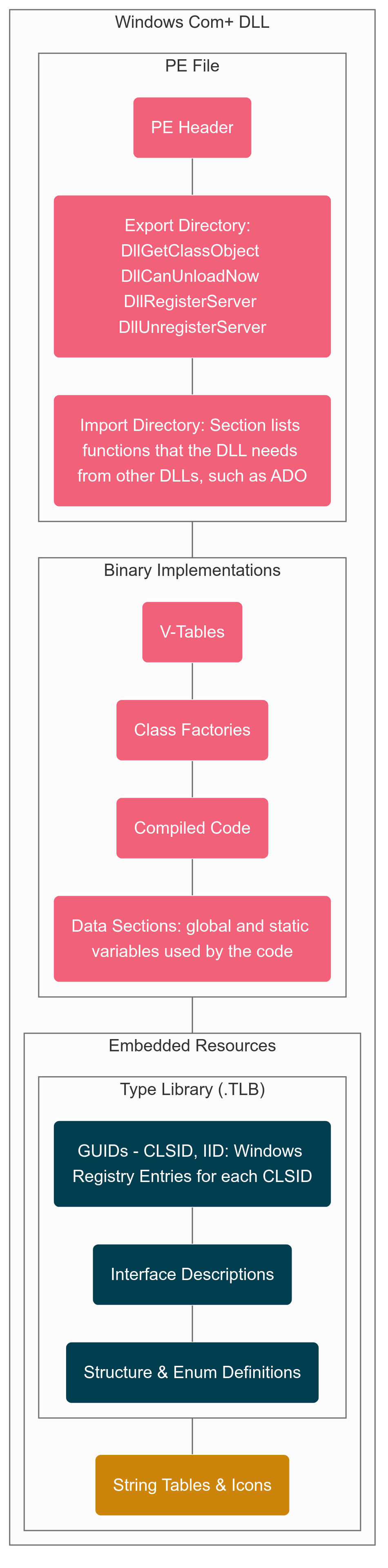
The impact of not having good deployment practices was evident with the Production machine having multiple versions of the same file with file names used to identify different versions and confusing names. Timestamps provided some clues. Locating the binaries was also done using the windows registry. There were also proxies for each binary that passed calls to the actual binary to allow the App tier to run on a different machine than the web tier. The fact that proxy binaries had the same name as target binaries adds to confusion.
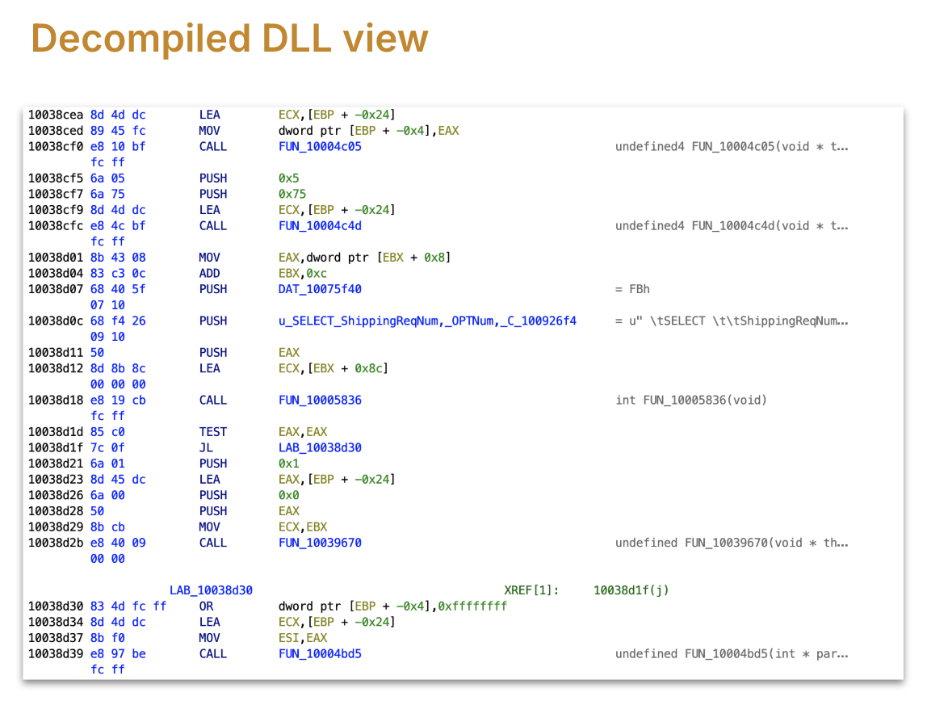
We didn't have to look at binary code of DLL. Tools like Ghidra help to decompile binary to a big set of ASM functions. Some of these tools even have the option to convert ASM into C code but we found that conversions are not always accurate. In our case decompilation to C missed a crucial lead.
Each DLL had 1000s of assembly functions, and we settled on an approach where we identify the relevant functions for a functional area and decode what that subtree of relevant functions does.
Prior Attempts
Before we arrived at this approach, we tried
- brute-force method: Added all assembly functions into a workspace, and used the LLM agent to make it humanly readable pseudocode. Faced multiple challenges with this. Ran out of the 1 million context window as LLM tried to eventually load all functions due to dependencies (references it encountered e.g. function calls, and other functions referencing current one)
- Split the set of functions into multiple batches, a file each with 100s of functions, and then use LLM to analyze each batch in isolation. We faced a lot of hallucination issues, and file size issues while streaming to model. A few functions were converted meaningfully but a lot of other functions didn't make any-sense at all, all sounded like similar capabilities, on cross checking we realised the hallucination effect.
- The next attempt was to convert the functions one at a time, to ensure LLM is provided with a fresh narrow window of context to limit hallucination. We faced multiple challenges (API usage limit, rate limits) - We couldn't verify what LLM translation of business logic was right or wrong. Then we couldn't connect the dots between these functions. Interesting note, we even found some C++ STDLIB functions like std::vector::insert in this approach. We found a lot were actually unwind functions purely used to call destructors when exception happens (stack unwinding) destructors, catch block functions. Clearly we needed to focus on business logic and ignore the compiled library functions, also mixed into the binary
After these attempts we decided to change our approach to slice the DLL based on functional area/workflow rather than consider the complete assembly code.
Finding the relevant function
The first challenge in the functional area / workflow approach is to find a link or entry point among the 1000s of functions.
One of the available options was to carefully look at the constants and strings in the DLL. We used the historical context: late 1990s or early 2000 common architectural pattern followed in that period was to insert data into the DB: was to either “select for insert” or “insert/update handled by stored procedure” or via ADO (which is an ORM). Interestingly we found all the patterns in different parts of the system.
Our functionality was about inserting or updating the DB at the end of the process but we couldn't find any insert or update queries in the strings, no stored procedure to perform the operation either. For the functionality we were looking for, it happened to actually use a SELECT through SQL and then updated via ADO (activex data object microsoft library).
We got our break based on the table name mentioned in the strings/constants, and this led to finding the function which is using that SQL statement. Initial look at that function didn't reveal much, it could be in the same functional area but part of a different workflow.
Building the relevant subtree
ASM code, and our disassembly tool, gave us the function call reference data, using it we walked up the tree, assuming the statement execution is one of the leaf functions, we navigated to the parent which called this to understand its context. At each step we converted ASM into pseudo code to build context.
Earlier when we converted ASM to pseudocode using brute-force we couldn't cross verify if it is true. This time we are better prepared because we know to anticipate what could be the potential things that could happen before a sql execution. And use the context that we gathered from earlier steps.
We mapped out relevant functions using this call tree navigation, sometimes we have to avoid wrong paths. We learned about context poisoning in a hard way, in-advertely we passed what we were looking for into LLM. From that moment LLM started colouring its output targeted towards what we were looking for, leading into wrong paths and eroding trust. We had to recreate a clean room for AI to work in during this stage.
We got a high level outline of what the different functions were, and what they could be doing. For a given work flow, we narrowed down from 4000+ functions to 40+ functions to deal with.
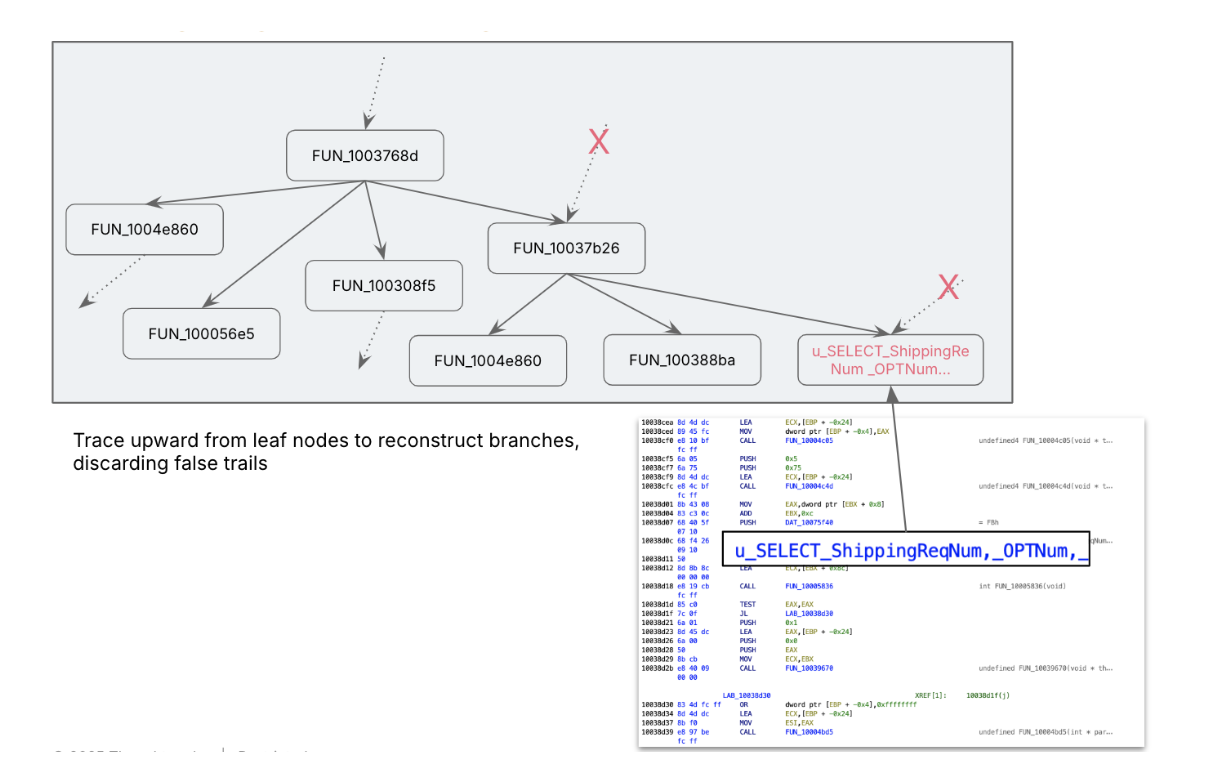
Multi-Pass Enrichment
AI accelerated the assembly archaeology layer by layer, pass by pass: We applied multi pass enrichment. In each pass, we either navigated from leaf node to top of the tree or reverse, in each step we enriched the context of the function either using its parents context or its child context. This helped us to change the technical conversion of pseudocode into a functional specification. We followed simple techniques like asking LLM to give meaningful method names based on known context. After multiple passes we build out the entire functional context.
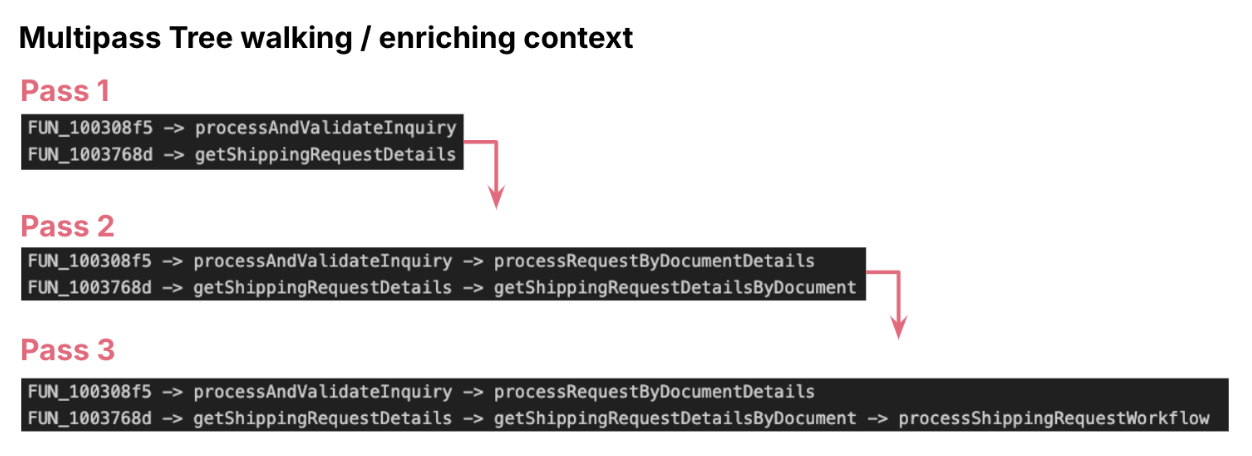
Validating the entry point
The last and critical challenge was to confirm the entry function. Typical to C++, virtual functions made it harder to link entry functions in class definition. While functionality looked complete starting with the root node, we were not sure if there is any other additional operation happening in a parent function or a wrapper. Life would have been easier if we had debugger enabled, a simple break point and review of the call stack would have confirmed it.
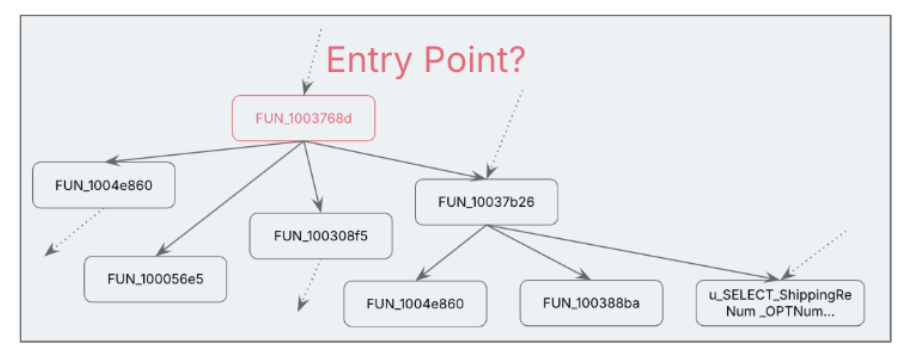
However with triangulation techniques, like:
- Call stack analysis
- Validating argument signatures and the the return signature in the stack
- Cross-checking with UI layer calls (e.g., associating method signature with the “submit” call from Web tier, checking parameter types and usage, and validating against that context)
Building the Spec from Fragments to Functionality
By integrating the reconstructed elements from the previous stages:UI Layer Reconstruction, Discovery with CDC, Server Logic Inference, and Binary analysis of App tier, a complete functional summary of the system is recreated with high confidence. This comprehensive specification forms a traceable and reliable foundation for business review and modernization/forward engineering efforts.
From our work, a set of repeatable practices emerged. These aren’t step-by-step recipes — every system is different — but guiding patterns that shape how to approach the unknown.
- Start Where Visibility is Highest: Begin with what you can see and trust: screens, data schemas, logs. These give a foundation of observable behavior before diving into opaque binaries. This avoids analysis paralysis by anchoring early progress in artifacts users already understand.
- Enrich in Passes: Don’t overload AI or humans with the whole system at once. Break artifacts into manageable chunks, extract partial insights, and progressively build context. This reduces hallucination risk, reduces assumptions, scales better with large legacy estates.
- Triangulate Everything: Never rely on a single artifact. Confirm every hypothesis across at least two independent sources — e.g., a screen flow matched against a stored procedure, then validated in a binary call tree. It creates confidence in conclusions, exposes hidden contradictions.
- Preserve Lineage: Track where every piece of inferred knowledge comes from — UI screen, schema field, binary function. This “audit trail” prevents false assumptions from propagating unnoticed. When questions arise later, you can trace back to original evidence.
- Keep Humans in the Loop: AI can accelerate analysis, but it cannot replace domain understanding. Always pair AI hypotheses with expert validation, especially for business-critical rules. Helps to avoid embedding AI errors directly into future modernization designs.
Conclusion and Key Takeaways
Blackbox reverse engineering, especially when supercharged with AI, offers significant advantages for legacy system modernization:
- Accelerated Understanding: AI speeds up legacy system understanding from months to weeks, transforming complex tasks like converting assembly code into pseudocode and classifying functions into business or utility categories.
- Reduced Fear of Undocumented Systems: organizations no longer need to fear undocumented legacy systems.
- Reliable First Step for Modernization: reverse engineering becomes a reliable and responsible first step toward modernization.
This approach unlocks Clear Functional Specifications even without source code, Better-Informed Decisions for modernization and cloud migration, Insight-Driven Forward Engineering while moving away from guesswork.
The future holds much faster legacy modernization due to the impact of AI tools, drastically reducing steep costs and risky long-term commitments. Modernization is expected to happen in “leaps and bounds”. In the next 2-3 years we could expect more systems to be retired than in the last 20 years. It is recommended to start small, as even a sandboxed reverse engineering effort can uncover surprising insights
In other media
Chandirasekar talked about this work in an episode of the Thoughtworks technology podcast.
The experiment described here originated from a concept first outlined in a Thoughtworks Insights article , where we explored whether generative AI could help reverse-engineer a system solely by observing its behavior.
Acknowledgements
This experiment was shaped with the contributions of Birgitta Boeckeler, Jigar Jani, Sean Luckett, and Vanitha Kumar
Significant Revisions
28 August 2025: put into toolchain