
Data Management Guide
There are many kinds of software out there, the kind I'm primarily engaged is Enterprise Applications. One of the enduring problems we need to tackle in this world is managing data, since such applications are all about using rapid access to large amounts of data to speed workflows, and provide information to the humans involved. Data management includes a whole host of aspects: storing data in data bases or other data storage mechanisms, moving data between applications, and modeling the data so we can understand what it means.
A guide to material on martinfowler.com about data management.

Evolving Data
Over the last few decades, it's become increasingly obvious that data has huge value to the enterprise that holds it. But data is also a complicating factor to the software that manipulates it. We need to change our software regularly to generate more value for our users, but the very data that fuels this value also makes it more difficult to change.
In the early days of agile software development, we were told that we couldn't use evolutionary design techniques for database systems, because database schemas were difficult to change, and thus needed careful up-front design. Fortunately my colleague Pramod Sadalge devised an approach to evolve a database design through small but frequent database migrations. This allows teams to evolve their data the same way that they refactor their code - even if this database is in production.
Evolutionary Database Design
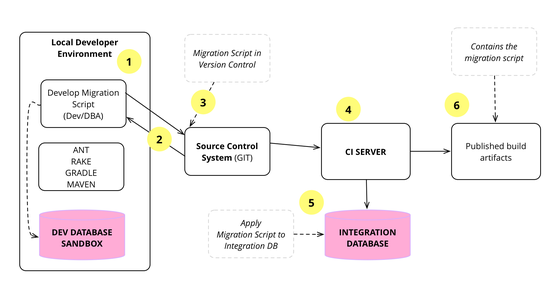
Over the last decade we've developed and refined a number of techniques that allow a database design to evolve as an application develops. This is a very important capability for agile methodologies. The techniques rely on applying continuous integration and automated refactoring to database development, together with a close collaboration between DBAs and application developers. The techniques work in both pre-production and released systems, in green field projects as well as legacy systems.
Refactoring Databases

Many important software systems rely on persistent data, stored in relational databases. To evolve this software, and add new features, it's necessary to change the structure of these databases: changing the data schema, its access code, and migrating any data in the database. Fortunately the basic philosophy of refactoring still applies: make very small, behavior preserving changes - and compose them together to make large changes. This book details these database refactorings, with examples of how to do them.

My colleague Pramod Sadalage has been my authoritive source on data matters for two decades. He developed the evolutionary database techniques that are a core part of our application development approach and co-authored a book on NoSQL databases.
Scoping Data
At the beginning of my career, the dominant theme in data management was a single, unified view of data - integrating all aspects of a enterprise's operations with a single data model. (And often a single database.) While that view is still common, I've moved in a different direction, believing that we have to accept that different parts of an enterprise need different data models: they look at different aspects of the enterprise, and even common elements are often viewed in different ways.
Bounded Context
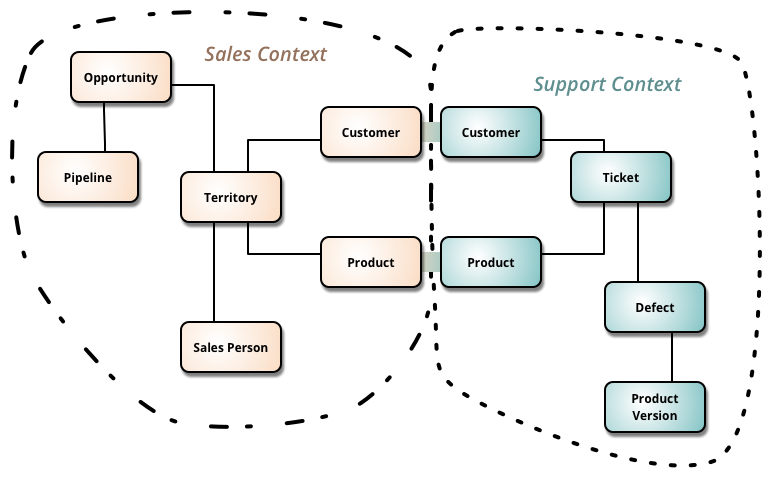
Bounded Context is a central pattern in Domain-Driven Design. It is the focus of DDD's strategic design section which is all about dealing with large models and teams. DDD deals with large models by dividing them into different Bounded Contexts and being explicit about their interrelationships.
Ubiquitous Language
Ubiquitous Language is the term Eric Evans uses in Domain Driven Design for the practice of building up a common, rigorous language between developers and users. This language should be based on the Domain Model used in the software - hence the need for it to be rigorous, since software doesn't cope well with ambiguity.
Data Mesh Principles and Logical Architecture
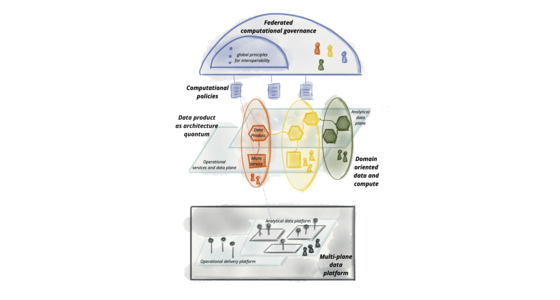
Our aspiration to augment and improve every aspect of business and life with data, demands a paradigm shift in how we manage data at scale. While the technology advances of the past decade have addressed the scale of volume of data and data processing compute, they have failed to address scale in other dimensions: changes in the data landscape, proliferation of sources of data, diversity of data use cases and users, and speed of response to change. Data mesh addresses these dimensions, founded in four principles: domain-oriented decentralized data ownership and architecture, data as a product, self-serve data infrastructure as a platform, and federated computational governance. Each principle drives a new logical view of the technical architecture and organizational structure.
Application Database
I use the term Application Database for a database that is controlled and accessed by a single application, (in contrast to an IntegrationDatabase). Since only a single application accesses the database, the database can be defined specifically to make that one application's needs easy to satisfy. This leads to a more concrete schema that is usually easier to understand and often less complex than that for an IntegrationDatabase.
How to Move Beyond a Monolithic Data Lake to a Distributed Data Mesh
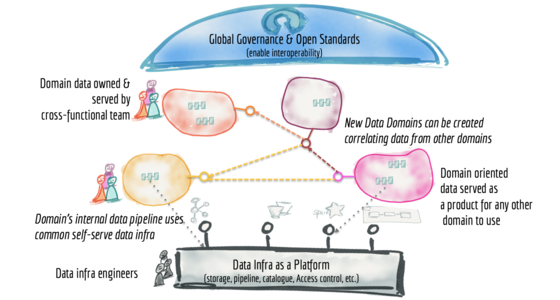
Many enterprises are investing in their next generation data lake, with the hope of democratizing data at scale to provide business insights and ultimately make automated intelligent decisions. Data platforms based on the data lake architecture have common failure modes that lead to unfulfilled promises at scale. To address these failure modes we need to shift from the centralized paradigm of a lake, or its predecessor data warehouse. We need to shift to a paradigm that draws from modern distributed architecture: considering domains as the first class concern, applying platform thinking to create self-serve data infrastructure, and treating data as a product.
Business Capability Centric
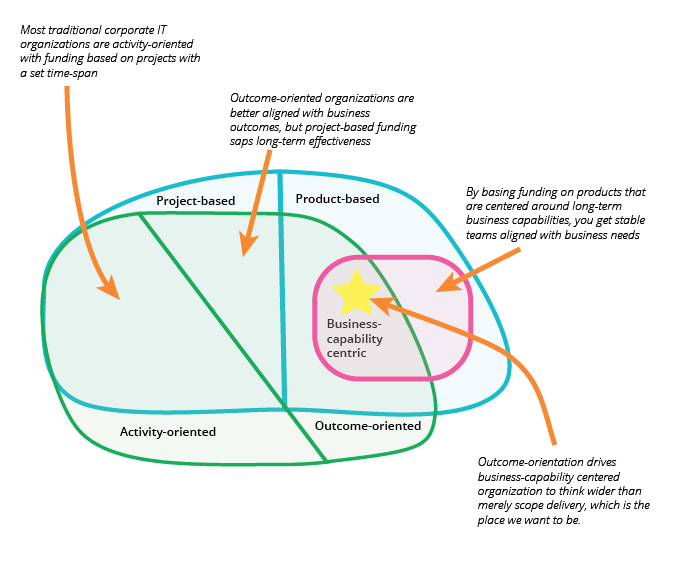
A business-capability centric team is one whose work is aligned long-term to a certain area of the business. The team lives as long as the said business-capability is relevant to the business. This is in contrast to project teams that only last as long as it takes to deliver project scope.
NoSQL Databases
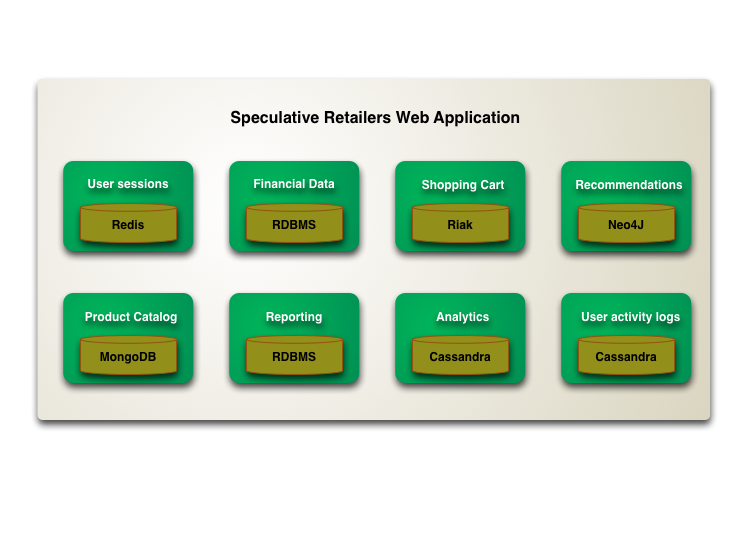
For much of the last few decades, whenever someone mentioned “database”, the immediate assumption was a relational database, usually one sold by the big 3 database vendors. But in the early 2010s we saw a wave of interest in alternative database technologies, that described themselves as “NoSQL”. These databases were a wide-ranging bunch, including Mongo, Neo4j, Cassandra, and Riak. I've never seen these databases as supplanting relational databases as the dominant data storage approach, but do see them playing a significant role in any data architecture.
NoSQL Distilled

As NoSQL databases were new and gathering interest, Pramod Sadalage and I felt the lack of a decent introduction to this technology was making it hard for practitioners to make good decisions about if and how to use them. So we wrote a short (152 page) overview, covering data models, issues with distributed data, thinking about consistency, schema migration, and several examples of different styles of NoSQL database.
Talk: Introduction to NoSQL

Nosql Definition
As soon as we started work on Nosql Distilled we were faced with a tricky conundrum - what are we writing about? What exactly is a NoSQL database? There's no strong definition of the concept out there, no trademarks, no standard group, not even a manifesto.
Schemaless Data Structures

In recent years, there's been an increasing amount of talk about the advantages of schemaless data. Being schemaless is one of the main reasons for interest in NoSQL databases. But there are many subtleties involved in schemalessness, both with respect to databases and in-memory data structures. These subtleties are present both in the meaning of schemaless and in the advantages and disadvantages of using a schemaless approach.
Key Points from NoSQL Distilled
When we designed the book, NoSQL Distilled, we concluded most chapters with some summary key points to act as a refresher for people re-reading the book. We've included these on the website as another way for readers to remind themselves of these key points.
Aggregate Oriented Database
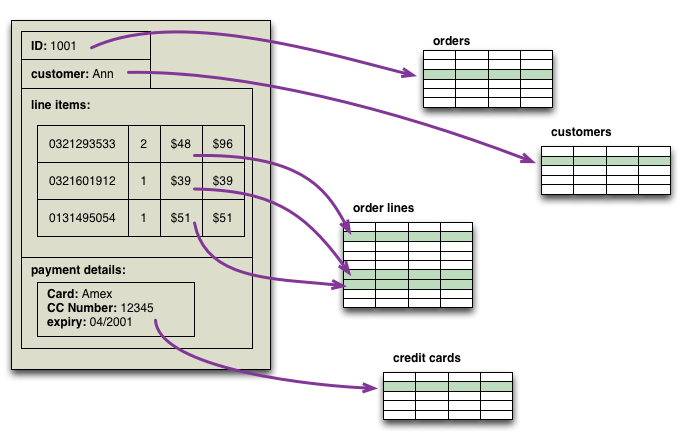
One of the first topics to spring to mind as we worked on Nosql Distilled was that NoSQL databases use different data models than the relational model. Most sources I've looked at mention at least four groups of data model: key-value, document, column-family, and graph. Looking at this list, there's a big similarity between the first three - all have a fundamental unit of storage which is a rich structure of closely related data: for key-value stores it's the value, for document stores it's the document, and for column-family stores it's the column family. In DDD terms, this group of data is an DDD_Aggregate.
The growth of Big (and Messy) Data
There was a time when people saw the future of data management is a single authoritative source of well structure data. But data comes from places, is naturally messy, and comes in greater amounts. This means we need different tools to manage data and a different philosophy to think about it, and we also need to think about the social responsibility we bear as we acquire data.
Thinking about Big Data
“Big Data” has leapt rapidly into one of the most hyped terms in our industry, yet the hype should not blind people to the fact that this is a genuinely important shift about the role of data in the world. The amount, speed, and value of data sources is rapidly increasing. Data management has to change in five broad areas: extraction of data from a wider range of sources, changes to the logistics of data management with new database and integration approaches, the use of agile principles in running analytics projects, an emphasis on techniques for data interpretation to separate signal from noise, and the importance of well-designed visualization to make that signal more comprehensible. Summing up this means we don't need big analytics projects, instead we want the new data thinking to permeate our regular work.
Talk: The Evolving Panorama of Data
Our keynote at QCon London 2012 looks at the role data is playing in our lives (and that it's doing more than just getting bigger). We start by looking at how the world of data is changing: its growing, becoming more distributed and connected. We then move to the industry's response: the rise of NoSQL, the shift to service integration, the appearance of event sourcing, the impact of clouds and new analytics with a greater role for visualization. We take a quick look at how data is being used now, with a particular emphasis from Rebecca on data in the developing world. Finally we consider what does all this mean to our personal responsibilities as software professionals.
Data Lake
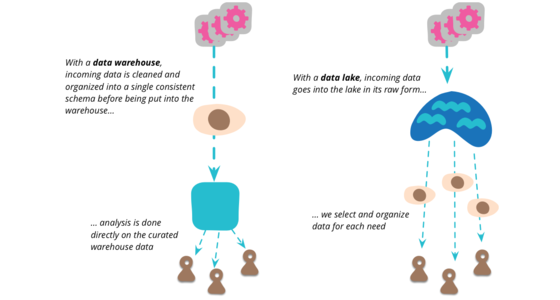
Data Lake is a term that's appeared in this decade to describe an important component of the data analytics pipeline in the world of Big Data. The idea is to have a single store for all of the raw data that anyone in an organization might need to analyze. Commonly people use Hadoop to work on the data in the lake, but the concept is broader than just Hadoop.
Datensparsamkeit
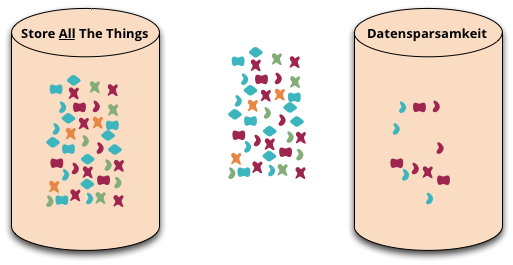
Datensparsamkeit is a German word that's difficult to translate properly into English. It's an attitude to how we capture and store data, saying that we should only handle data that we really need.
Machine Justification
I remember in my teens being told of the wonderful things Artificial Intelligence (AI) would do in the next few years. Now several decades later, some of these seem to be happening. The most recent triumph was of computers teaching each other to play Go by playing against each other, rapidly becoming more proficient than any human, with strategies human experts could barely comprehend. It's natural to wonder what will happen over the next few years, will computers soon have greater intelligence than humanity? (Given some recent election results, that may not be too hard a bar to cross.)
But as I hear of these, I recall Pablo Picasso's comment about computers many decades ago: “Computers are useless. They can only give you answers”. The kind of reasoning that techniques such as Machine Learning can result in are truly impressive in their results, and will be useful to us as users and developers of software. But answers, while useful, aren't always the whole picture. I learned this in my early days of school - just providing the answer to a math problem would only get me a couple of marks, to get the full score I had to show how I got it. The reasoning that got to the answer was more valuable than the result itself. That's one of the limitations of the self-taught Go AIs. While they can win, they cannot explain their strategies.
Applications and Data
Data needs to be stored and managed - but above all we need to make use of it to drive our systems that help people make better decisions.
Polyglot Persistence
In 2006, my colleague Neal Ford coined the term Polyglot Programming, to express the idea that applications should be written in a mix of languages to take advantage of the fact that different languages are suitable for tackling different problems. Complex applications combine different types of problems, so picking the right language for the job may be more productive than trying to fit all aspects into a single language.
Over the last few years there's been an explosion of interest in new languages, particularly functional languages, and I'm often tempted to spend some time delving into Clojure, Scala, Erlang, or the like. But my time is limited and I'm giving a higher priority to another, more significant shift, that of the DatabaseThaw. The first drips have been coming through from clients and other contacts and the prospects are enticing. I'm confident to say that if you starting a new strategic enterprise application you should no longer be assuming that your persistence should be relational. The relational option might be the right one - but you should seriously look at other alternatives.
Reporting Database
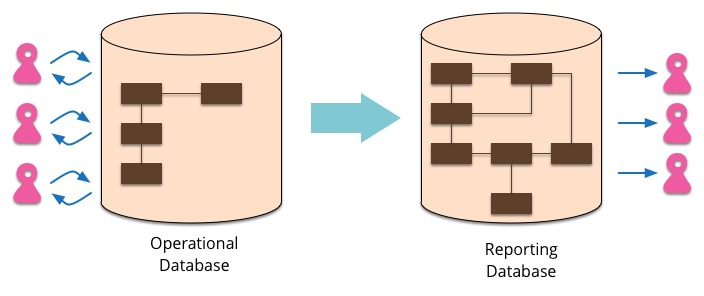
Most EnterpriseApplications store persistent data with a database. This database supports operational updates of the application's state, and also various reports used for decision support and analysis. The operational needs and the reporting needs are, however, often quite different - with different requirements from a schema and different data access patterns. When this happens it's often a wise idea to separate the reporting needs into a reporting database, which takes a copy of the essential operational data but represents it in a different schema.
Type Instance Homonym
“'War and Peace' is a wonderful book.
“Let me see... pity this book has such a tattered cover”
Two sentences, each uses the word 'book'. We glance over combinations like this every day without remarking that the word 'book' means something completely different in each of those sentences.
Orm Hate
While I was at the QCon conference in London a couple of months ago, it seemed that every talk included some snarky remarks about Object/Relational mapping (ORM) tools. I guess I should read the conference emails sent to speakers more carefully, doubtless there was something in there telling us all to heap scorn upon ORMs at least once every 45 minutes. But as you can tell, I want to push back a bit against this ORM hate - because I think a lot of it is unwarranted.
Memory Image
When people start an enterprise application, one of the earliest questions is “how do we talk to the database”. These days they may ask a slightly different question “what kind of database should we use - relational or one of these NOSQL databases?”. But there's another question to consider: “should we use a database at all?”
User Defined Field
A common feature in software systems is to allow users to define their own fields in data structures. Consider an address book - there's a host of things that you might want to add. With new social networks popping up every day, users might want to add a new field for a Bunglr id to their contacts.