Before engineers rush into optimizing cost individually
within their own teams, it’s best to assemble a cross-functional
team to perform analysis and lead execution of cost optimization
efforts. Typically, cost efficiency at a startup will fall into
the responsibility of the platform engineering team, since they
will be the first to notice the problem – but it will require
involvement from many areas. We recommend getting a cost
optimization team together, consisting of technologists with
infrastructure skills and those who have context over the
backend and data systems. They will need to coordinate efforts
among impacted teams and create reports, so a technical program
manager will be valuable.
Understand primary cost drivers
It is important to start with identifying the primary cost
drivers. First, the cost optimization team should collect
relevant invoices – these can be from cloud provider(s) and SaaS
providers. It is useful to categorize the costs using analytical
tools, whether a spreadsheet, a BI tool, or Jupyter notebooks.
Analyzing the costs by aggregating across different dimensions
can yield unique insights which can help identify and prioritize
the work to achieve the greatest impact. For example:
Application/system: Some applications/systems may
contribute to more costs than others. Tagging helps associate
costs to different systems and helps identify which teams may be
involved in the work effort.
Compute vs storage vs network: In general: compute costs
tend to be higher than storage costs; network transfer costs can
sometimes be a surprise high-costing item. This can help
identify whether hosting strategies or architecture changes may
be helpful.
Pre-production vs production (environment):
Pre-production environments’ cost should be quite a bit lower
than production’s. However, pre-production environments tend to
have more lax access control, so it is not uncommon that they
cost higher than expected. This could be indicative of too much
data accumulating in non-prod environments, or even a lack of
cleanup for temporary or PoC infrastructure.
Operational vs analytical: While there is no rule of
thumb for how much a company’s operational systems should cost
as compared to its analytical ones, engineering leadership
should have a sense of the size and value of the operational vs
analytical landscape in the company that can be compared with
actual spending to identify an appropriate ratio.
Service / capability provider: Across project management,
product roadmapping, observability, incident management, and
development tools, engineering leaders are often surprised by
the number of tool subscriptions and licenses in use and how
much they cost. This can help identify opportunities for
consolidation, which may also lead to improved negotiating
leverage and lower costs.
The results of the inventory of drivers and costs
associated with them should provide the cost optimization team a
much better idea what type of costs are the highest and how the
company’s architecture is affecting them. This exercise is even
more effective at identifying root causes when historical data
is considered, e.g. costs from the past 3-6 months, to correlate
changes in costs with specific product or technical
decisions.
Identify cost-saving levers for the primary cost drivers
After identifying the costs, the trends and what are driving
them, the next question is - what levers can we employ to reduce
costs? Some of the more common methods are covered below. Naturally,
the list below is far from exhaustive, and the right levers are
often very situation-dependent.
Rightsizing: Rightsizing is the action of changing the
resource configuration of a workload to be closer to its
utilization.
Engineers often perform an estimation to see what resource
configuration they need for a workload. As the workloads evolve
over time, the initial exercise is rarely followed-up to see if
the initial assumptions were correct or still apply, potentially
leaving underutilized resources.
To rightsize VMs or containerized workloads, we compare
utilization of CPU, memory, disk, etc. vs what was provisioned.
At a higher level of abstraction, managed services such as Azure
Synapse and DynamoDB have their own units for provisioned
infrastructure and their own monitoring tools that would
highlight any resource underutilization. Some tools go so far as
to recommend optimal resource configuration for a given
workload.
There are ways to save costs by changing resource
configurations without strictly reducing resource allocation.
Cloud providers have multiple instance types, and usually, more
than one instance type can satisfy any particular resource
requirement, at different price points. In AWS for example, new
versions are generally cheaper, t3.small is ~10% lower than
t2.small. Or for Azure, even though the specs on paper appear
higher, E-series is cheaper than D-series – we helped a client
save 30% off VM cost by swapping to E-series.
As a final tip: while rightsizing particular workloads, the
cost optimization team should keep any pre-purchase commitments
on their radar. Some pre-purchase commitments like Reserved
Instances are tied to specific instance types or families, so
while changing instance types for a particular workload could
save cost for that specific workload, it could lead to part of
the Reserved Instance commitment going unused or wasted.
Using ephemeral infrastructure: Frequently, compute
resources operate longer than they need to. For example,
interactive data analytics clusters used by data scientists who
work in a particular timezone may be up 24/7, even though they
are not used outside of the data scientists’ working hours.
Similarly, we have seen development environments stay up all
day, every day, whereas the engineers working on them use them
only within their working hours.
Many managed services offer auto-termination or serverless
compute options that ensure you are only paying for the compute
time you actually use – all useful levers to keep in mind. For
other, more infrastructure-level resources such as VMs and
disks, you could automate shutting down or cleaning up of
resources based on your set criteria (e.g. X minutes of idle
time).
Engineering teams may look at moving to FaaS as a way to
further adopt ephemeral computing. This needs to be thought
about carefully, as it is a serious undertaking requiring
significant architecture changes and a mature developer
experience platform. We have seen companies introduce a lot of
unnecessary complexity jumping into FaaS (at the extreme:
lambda
pinball).
Incorporating spot instances: The unit cost of spot
instances can be up to ~70% lower than on-demand instances. The
caveat, of course, is that the cloud provider can claim spot
instances back at short notice, which risks the workloads
running on them getting disrupted. Therefore, cloud providers
generally recommend that spot instances are used for workloads
that more easily recover from disruptions, such as stateless web
services, CI/CD workload, and ad-hoc analytics clusters.
Even for the above workload types, recovering from the
disruption takes time. If a particular workload is
time-sensitive, spot instances may not be the best choice.
Conversely, spot instances could be an easy fit for
pre-production environments, where time-sensitivity is less
stringent.
Leveraging commitment-based pricing: When a startup
reaches scale and has a clear idea of its usage pattern, we
advise teams to incorporate commitment-based pricing into their
contract. On-demand prices are typically higher than prices you
can get with pre-purchase commitments. However, even for
scale-ups, on-demand pricing could still be useful for more
experimental products and services where usage patterns have not
stabilized.
There are multiple types of commitment-based pricing. They
all come at a discount compared to the on-demand price, but have
different characteristics. For cloud infrastructure, Reserved
Instances are generally a usage commitment tied to a specific
instance type or family. Savings Plans is a usage commitment
tied to the usage of specific resource (e.g. compute) units per
hour. Both offer commitment periods ranging from 1 to 3 years.
Most managed services also have their own versions of
commitment-based pricing.
Architectural design: With the popularity of
microservices, companies are creating finer-grained architecture
approaches. It is not uncommon for us to encounter 60 services
at a mid-stage digital native.
However, APIs that aren’t designed with the consumer in mind
send large payloads to the consumer, even though they need a
small subset of that data. In addition, some services, instead
of being able to perform certain tasks independently, form a
distributed monolith, requiring multiple calls to other services
to get its task done. As illustrated in these scenarios,
improper domain boundaries or over-complicated architecture can
show up as high network costs.
Refactoring your architecture or microservices design to
improve the domain boundaries between systems will be a big
project, but will have a large long-term impact in many ways,
beyond reducing cost. For organizations not ready to embark on
such a journey, and instead are looking for a tactical approach
to combat the cost impact of these architectural issues,
strategic caching can be employed to minimize chattiness.
Enforcing data archival and retention policy: The hot
tier in any storage system is the most expensive tier for pure
storage. For less frequently-used data, consider putting them in
cool or cold or archive tier to keep costs down.
It is important to review access patterns first. One of our
teams came across a project that stored a lot of data in the
cold tier, and yet were facing increasing storage costs. The
project team did not realize that the data they put in the cold
tier were frequently accessed, leading to the cost increase.
Consolidating duplicative tools: While enumerating
the cost drivers in terms of service providers, the cost
optimization team may realize the company is paying for multiple
tools within the same category (e.g. observability), or even
wonder if any team is really using a particular tool.
Eliminating unused resources/tools and consolidating duplicative
tools in a category is certainly another cost-saving lever.
Depending on the volume of usage after consolidation, there
may be additional savings to be gained by qualifying for a
better pricing tier, or even taking advantage of increased
negotiation leverage.
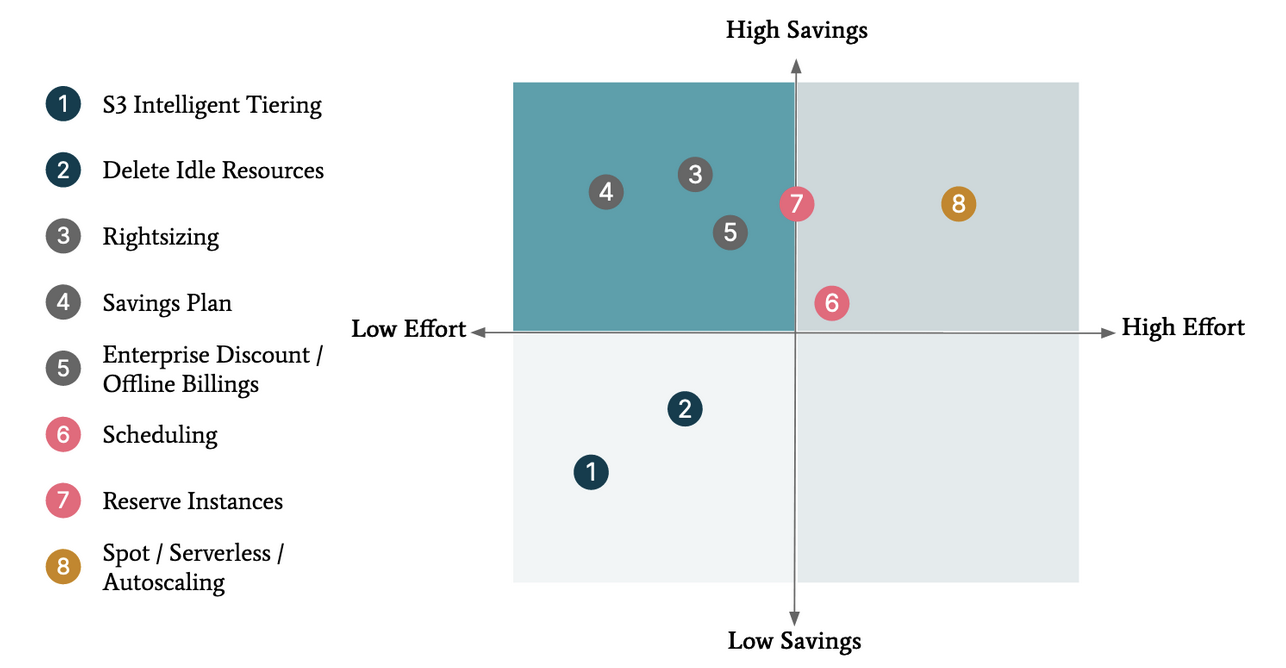
Prioritize by effort and impact
Any potential cost-saving opportunity has two important
characteristics: its potential impact (size of potential
savings), and the level of effort needed to realize them.
If the company needs to save costs quickly, saving 10% out of
a category that costs $50,000 naturally beats saving 10% out of
a category that costs $5,000.
However, different cost-saving opportunities require
different levels of effort to realize them. Some opportunities
require changes in code or architecture which take more effort
than configuration changes such as rightsizing or utilizing
commitment-based pricing. To get a good understanding of the
required effort, the cost optimization team will need to get
input from relevant teams.
At the end of this exercise, the cost optimization team should
have a list of opportunities, with potential cost savings, the effort
to realize them, and the cost of delay (low/high) associated with
the lead time to implementation. For more complex opportunities, a
proper financial analysis needs to be specified as covered later. The
cost optimization team would then review with leaders sponsoring the initiative,
prioritize which to act upon, and make any resource requests required for execution.
The cost optimization team should ideally work with the impacted
product and platform teams for execution, after giving them enough
context on the action needed and reasoning (potential impact and priority).
However, the cost optimization team can help provide capacity or guidance if
needed. As execution progresses, the team should re-prioritize based on
learnings from realized vs projected savings and business priorities.