
Contradictory Observations
3 March 2009

Many computer systems are built to house data and turn it into useful information for humans. When we do this there is a natural desire to make that information consistent. After all what use is there of a computer system that's in two minds about things?
But sometimes computer systems should record contradictory data and help humans deal with that. This issue came foremost to my mind many years ago when working in health care for the UK National Health Service. We were building a conceptual model for health care delivery - essentially a conceptual schema for an electronic health care record.
Looking back on it, there were certainly plenty of things I'd do differently now. But one thing in particular was something very precious and important - the model was very much a collaborative effort between myself, another software developer, two doctors and a nurse. The clinicians understood the model and played a full part in developing it - they were not merely passive reviewers. As a result I think the ideas we developed were particularly valuable in thinking about what a clinical practitioner wants to see in an electronic health care record.
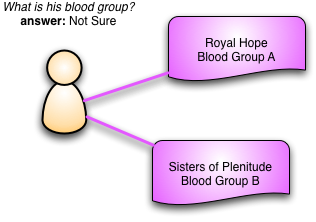
One thing the clinicians were very strong about was this need to capture contradictory information. I might have a note from the Royal Hope Hospital saying my blood type is A and another note from the Sisters of Plenitude saying my blood type is B. This would clearly be nonsense, blood types don't change. But that doesn't mean we cannot record these two bits of data. Without further investigation we don't know which one is correct. Even if we test again and confirm one of them, we can't just throw away the bad one as it may have been the basis for further clinical action. And of course there are lots of cases where the contradiction isn't as clear cut. We may never be able to find out which of two contradictory bits of data was wrong or may find a change over time that is extremely unlikely but not impossible.
The key to handling this issue is to represent my blood type not as an attribute of a person class, but as a fully fledged class in its own right - which we called observation. Each observation applies to a particular patient, but also records such information as when it was made, who made it, and how it was made.
We also saw that observations can be about the absence of things as much as about their presence. So in some circumstances it may not be possible to figure out my blood group, but it is possible to say that it isn't blood group O. This we could represent as an observation of an absence of blood group O. (I have no idea if this example is possible or reasonable, but it can get tricky to think up realistic examples quickly.) Often observing the absence of things is crucial in a diagnostic process.
Using observations changes the way we determine information about a patient. Rather than simply asking for a patient's blood group, we look at all the patient's blood group observations. If they are all the same, then we just use that value. If they differ, we need to delve deeper. In many cases observations do sensibly change over time, so we might look at all the observations of my weight over time to plot how my weight changes.
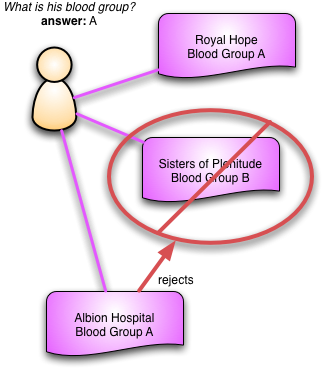
Although we need to keep contradictory observations, we also need to capture if we think one of them was wrong. Some observations, such as a broken leg, will become untrue over time, but the blood group example above is more likely to be a error. In the erroneous case we have the notion of rejecting (or refuting) one observation with another. So we might have a further test in the Albion Hospital that finds I'm Blood Group A, this observation would then reject the Sisters of Plenitude's observation. Rejecting an observation says that we believe it was never true. We never delete the old observation, instead we mark it as rejected and link it to Albion Hospital's observation.
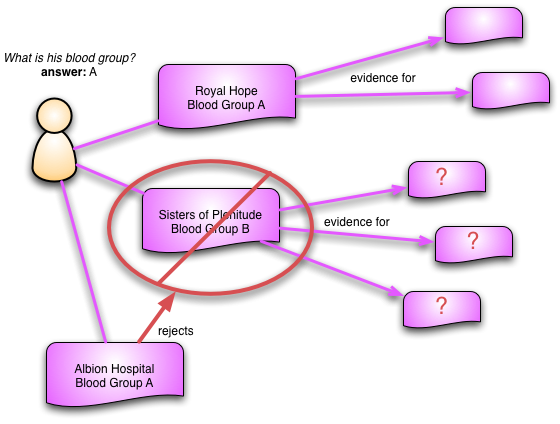
An important property of information is that it's used to guide behavior. A rejected observation may have been used as evidence for further observations or to justify interventions. Keeping these links in the record is essential since once an observation is rejected we can then follow those links to investigate the consequences. If the observation we've just rejected is a crucial part of evidence for another observation, that should be questioned and maybe rejected as well. Observations thus form a web of evidence that we can examine as we learn more about the patient.
Most of the time, of course, we don't use complicated schemes like this. We mostly program in a world that we assume is consistent. But there are times where we have to step away from that comfortable assumption. When that happens then explicit observations are a useful tool
(If you are interested in more of this, see Chapter 3 of Analysis Patterns. I'm sure I'd write it better if I were to do it again now, but the core concepts still seem to hold up pretty well. I'd also like to call out my colleagues on this work: Tom Cairns, Anne Casey, Mark Thursz, and Hazim Timimi)