
Microservices and the First Law of Distributed Objects

13 August 2014
When I wrote Patterns of Enterprise Application Architecture, I coined what I called the First Law of Distributed Object Design: “don't distribute your objects”. In recent months there's been a lot of interest in microservices, which has led a few people to ask whether microservices are in contravention to this law, and if so why I am in favor of them?
It's important to note that in this first law statement, I use the phrase “distributed objects”. This reflects an idea that was rather in vogue in the late 90's early 00's but since has (rightly) fallen out of favor. The idea of distributed objects is that you could design objects and choose to use these same objects either in-process or remote, where remote might mean another process in the same machine, or on a different machine. Clever middleware, such as DCOM or a CORBA implementation, would handle the in-proces/remote distinction so your system could be written and you could break it up into processes independently of how the application was designed.
My objection to the notion of distributed objects was although you can encapsulate many things behind object boundaries, you can't encapsulate the remote/in-process distinction. An in-process function call is fast and always succeeds (in that any exceptions are due to the application, not due to the mere fact of making the call). Remote calls, however, are orders of magnitude slower, and there's always a chance that the call will fail due to a failure in the remote process or the connection.
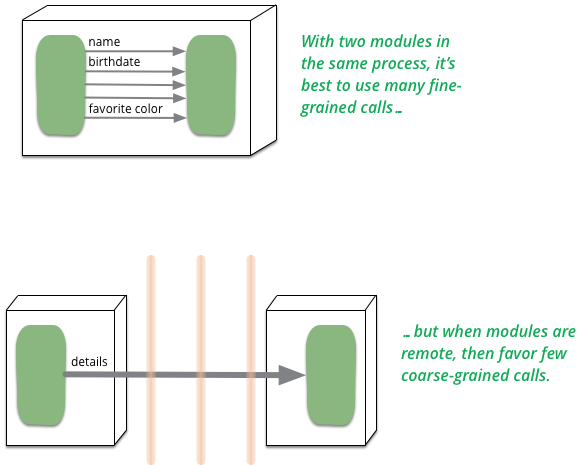
The consequence of this difference is that your guidelines for APIs are different. In process calls can be fine-grained, if you want 100 product prices and availabilities, you can happily make 100 calls to your product price function and another 100 for the availabilities. But if that function is a remote call, you're usually better off to batch all that into a single call that asks for all 100 prices and availabilities in one go. The result is a very different interface to your product object. Consequently you can't take the same class (which is primarily about interface) and use it transparently in an in-process or remote manner.
The microservice-advocates I've talked to are very aware of this distinction, and I've not heard any of them talk about in-process/remote transparency. So they aren't trying to do what distributed objects were trying to do, and thus don't violate the first law. Instead they advocated coarse-grained interactions with documents over HTTP or lightweight messaging.
So in essence, there is no contradiction between my views on distributed objects and advocates of microservices. Despite this essential non-conflict, there is another question that is now begging to be asked. Microservices imply small distributed units that communicate over remote connections much more than a monolith would do. Doesn't that contravene the spirit of the first law even if it satisfies the letter of it?
While I do accept that there are valid reasons to do for a distributed design for many systems, I do think distribution is a complexity booster. A coarser-grained API is more awkward than a fine-grained one. You need to decide what you are going to do about failure of remote calls, and the consequences to consistency and availability. Even if you minimize remote calls through your protocol design, you still have to think more about performance issues around them. When designing a monolith you have to worry about allocation of responsibilities between modules, with a distributed system you have to worry about allocation of responsibilities between modules and distribution factors.
While small microservices are certainly simpler to reason about, I worry that this pushes complexity into the interconnections between services, where it's less explicit and thus harder to figure out when it goes wrong. Refactoring becomes much harder when you have to do it across remote boundaries. Microservice advocates tout the reduction of coupling you get from asynchronous communication, but asynchrony is yet another complexity booster. Cookie-cutter scaling allows you to handle large volumes of traffic without increasing distribution complexity.
Consequently I'm wary of distribution and my default inclination is to prefer a monolithic design. Given that, why have I spent a lot of effort describing microservices and supporting my colleagues who are advocating it? The answer is because I know my gut feelings are not always right. I cannot deny that many teams have taken a microservices approach and have found success with it, whether they be well-known public cases like Netflix and (probably) Amazon, or various teams I've talked to both inside and outside of Thoughtworks. I am by nature an empiricist, one that believes that empirical evidence trumps theory, even if that theory is rather better worked out than my gut feel.
Not that I think the matter is settled yet. In software delivery, success is a very slippery thing to identify. Although organizations like Netflix and Spotify have trumpeted their earlier success with microservices there are also examples like Etsy or Facebook that have had success with much more monolithic architectures. However successful a team may think itself to have been with microservices, the only real comparison would be the counter-factual - would they have fared better with a monolith? The microservices approach has only been around for a relatively short time, so we don't have much evidence from a decade old legacy microservice architecture to compare it to those elderly monoliths that we dislike so much. And there may be factors we haven't identified that mean that in some circumstances monoliths are better while other situations favor the microservices. Given the difficulty in assembling evidence in software development it's more likely than not that there won't be a compelling decision in favor of one or the other even after many years have passed.
Given this uncertainty, the most important thing a writer like myself can do is to communicate as clearly as I can the lessons we think we've learned, even if they are contradictory. Readers will make their own decisions, it is our job as writers to make sure those decisions are well-informed ones, whichever side of the architectural line they fall.
Further Reading
My article with my colleague James Lewis is our attempt to prepare a definition of the microservices architectural style. I coined the first law of distributed objects in my book Patterns of Enterprise Application Architecture, it appears in chapter 7: “Distribution Strategies”. That chapter was also freely published online by Dr Dobb's under the title Errant Architectures.
The Fallacies of Distributed Computing is the classic statement of why one should beware of any notion that distribution can be done transparently (or easily). Waldo et al's Note on Distributed Computing was a excellent statement of the fundamental problems with distributed objects.