
How to extract a data-rich service from a monolith
When breaking monoliths into smaller services, the hardest part is actually breaking up the data that lives in the database of the monolith. To extract a data-rich service, it is useful to follow a series of steps which retain a single write-copy of the data at all times. The steps begin by making a logical separation in the existing monolith: splitting service behavior into a separate module, then separating data into a separate table. These elements can be separately moved into a new autonomous service.
30 August 2018

Praful Todkar is a Principal Consultant with Thoughtworks who specializes in building large scale, distributed, business software systems. When building software, he loves doing two things – delivering business value as quickly as possible and building simple, elegant solutions to complex problems. It is even better when he can combine the two.
Contents
- Service extraction guiding principles
- Service extraction steps
- Step 1. Identify logic and data related to the new service
- Step 2. Create a logical separation for the logic of the new service in the monolith
- Step 3. Create new table/s to support the logic of the new service in the monolith
- Step 4. Build new service pointing to tables in monolithic database
- Step 5. Point clients to the new service
- Step 6. Create the database for the new service
- Step 7. Sync data from the monolith to the new database
- Step 8. Point new service to the new database
- Step 9. Delete logic and schema from the monolith related to the new service
- Summary
There is a major shift in the industry away from monoliths towards smaller services. A key reason why organizations are investing in this shift is because smaller services built around business capabilities increase developer productivity. Teams that can own these smaller service/s can be “masters of their own destiny” which means they can evolve their service/s independently of other services in the system.
When breaking monoliths into smaller services, the hardest part is actually breaking up the data that lives in the database of the monolith. It is relatively easy to chop up the logic in the monolith into smaller pieces while still connecting to the same database. In this case, the database is essentially an IntegrationDatabase which gives the semblance of a distributed system that can evolve independently but in fact is a single tightly coupled system at the database level. For services to be truly independent and thus teams to be “master of their own destiny”, they also need to have an independent database – the schema and the corresponding data for the service.
In this article, I will be talking about a pattern, which is a series of steps, for extracting a data-rich service from a monolith while causing minimum disruption to the service consumers.
Service extraction guiding principles
Before we get too deep into the actual pattern, I would like to talk about two guiding principles that are critical to service extraction. These help enable a smooth and safe transition from a world where you have a monolith to multiple smaller services.
Have a single write copy for the data throughout the transition
We will have a single write copy for the data for the service being extracted during the transition. Having multiple copies of data that clients can write to introduces the possibility of having write conflicts. A write conflict happens when the same piece of data is being written to by multiple clients at the same time. Logic for handling a write conflict is complex – it could mean picking a scheme such as ‘last write wins’ which could produce undesired results from a client’s perspective. It could also mean informing the client for whom the write failed and have them take corrective action. Writing such logic is fraught with complications and is something that is best avoided.
The service extraction pattern described in here will ensure that a single write copy exists at any given point in time for the service being extracted to avoid the complexities that come with managing write conflicts.
Respect “atomic step of architecture evolution” principle
My colleague Zhamak Dehghani coined the term ‘atomic step of architecture evolution’ which is a series of steps taken atomically (all-or-none) in an architecture migration journey. At the end of the series of steps the architecture yields the promised rewards. If the steps aren’t executed in entirety (left midway) the architecture is in a worse off state than the state in which you started. For example, if you decide to extract a service and you only end up pulling the logic but not the data you are still coupled at the database tier which introduces development and runtime coupling. This introduces significant complexity and arguably makes development and debugging issues way harder than if it were to be a single monolith.
In the following service extraction pattern, it is recommended that you complete all the steps listed out for a given service. One of the biggest hurdles in the service extraction pattern is actually not technical but getting organizational alignment to have all the existing clients of the monolith to move to the new service. This will be further explained in step 5.
Service extraction steps
Now, let us dive into the actual service extraction pattern. To make it easy to follow the steps, we will take an example to understand how the service extraction works.
Lets say we have a monolithic Catalog system which provides our eCommerce platform with product information. Over time the Catalog system has grown into a monolith which means along with the core product information such as product name, category name and associated logic, it has also gobbled up product pricing logic and data. There are no clear boundaries between the core product part of the system and the pricing part of the system.
Moreover, the rate of change (rate at which changes are introduced in the system) in the pricing part of the system is much higher than the core product. The data access patterns are also different for the two parts of the system. Pricing for a product changes a lot more dynamically than the core product attributes. Thus, it makes a lot of sense to pull out the pricing part of the system out of the monolith into a separate service that can be evolved independently.
What makes pulling out pricing compelling as opposed to the core product is that pricing is a “leaf” dependency in the catalog monolith. The core product functionality is also a dependency for other functionality in the monolith such as product inventory, product marketing, et al which are not shown here for simplicity. If you were to pull out the core product out as a service it would mean severing too many “connections” in the monolith at the same time which can make the migration process quite risky. To start with, you want to pull apart a valuable business capability that is a leaf dependency in the monolith dependency graph such as the pricing functionality.
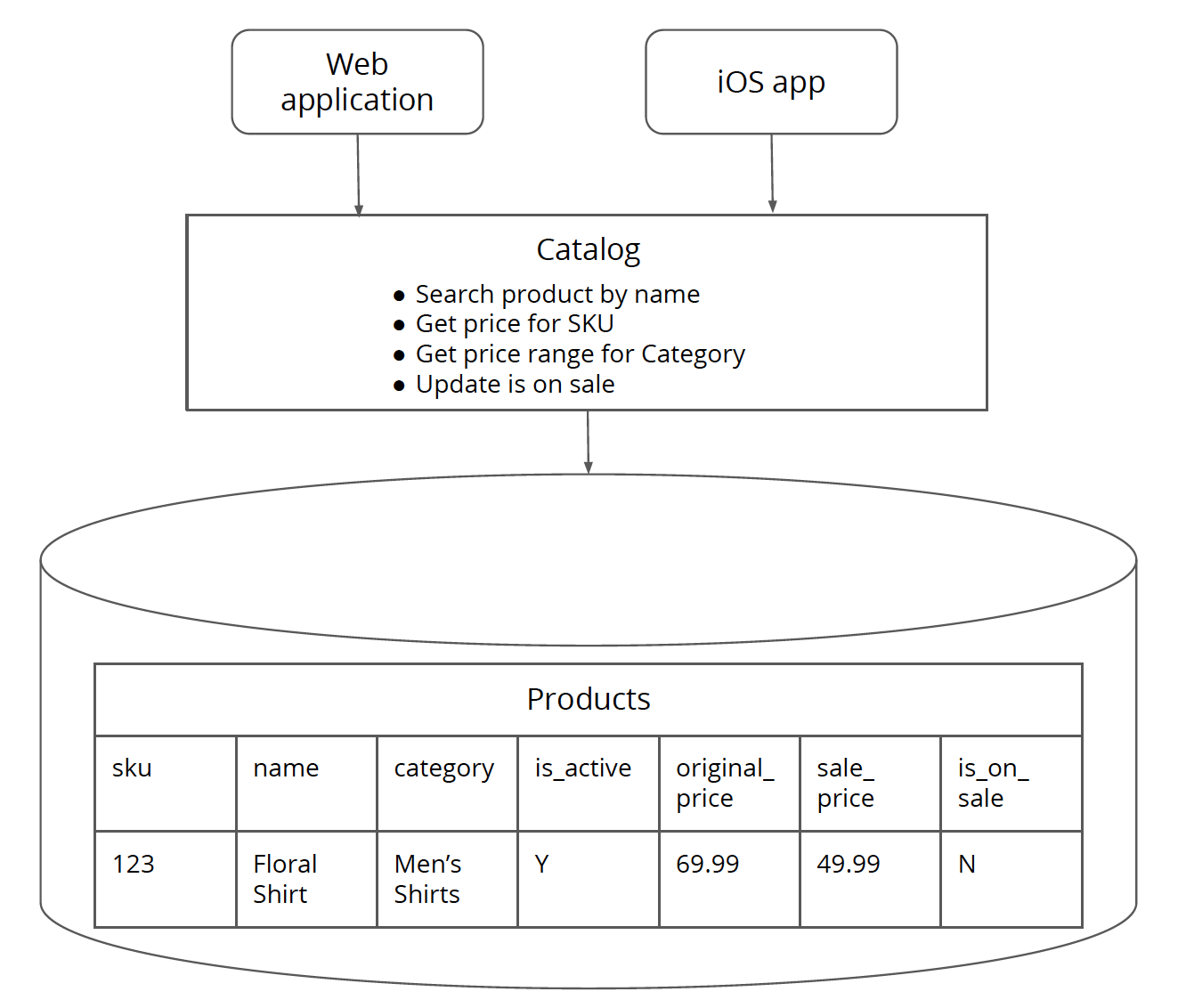
Figure 1: Catalog monolith consists of the application logic and database for core product as well as product pricing. The Catalog monolith has two clients – the web application and iOS app.
Initial state of the code
Below is the initial state of the code for the Catalog system. Obviously, the code lacks the real world “messiness” aka complexity of such a system. However, it is sufficiently complex to demonstrate the spirit of a refactoring that involves pulling a data-rich service out of a monolith. We will see how the code below is refactored over the course of the steps.
The code consists of a CatalogService which is representative of
the interface that the monolith provides to its clients. It uses a
productRepository class to fetch and persist state from the database.
Product class is a dumb data class (indicative of an
AnemicDomainModel)
that contains product information.
Dumb data classes are clearly an anti-pattern but they are not the primary focus
of this article so as far as this example is concerned we will make do with it.
Sku, Price and CategoryPriceRange are
“tiny types”.
class CatalogService…
public Sku searchProduct(String searchString) {
return productRepository.searchProduct(searchString);
}
public Price getPriceFor(Sku sku) {
Product product = productRepository.queryProduct(sku);
return calculatePriceFor(product);
}
private Price calculatePriceFor(Product product) {
if(product.isOnSale()) return product.getSalePrice();
return product.getOriginalPrice();
}
public CategoryPriceRange getPriceRangeFor(Category category) {
List<Product> products = productRepository.findProductsFor(category);
Price maxPrice = null;
Price minPrice = null;
for (Product product : products) {
if (product.isActive()) {
Price productPrice = calculatePriceFor(product);
if (maxPrice == null || productPrice.isGreaterThan(maxPrice)) {
maxPrice = productPrice;
}
if (minPrice == null || productPrice.isLesserThan(minPrice)) {
minPrice = productPrice;
}
}
}
return new CategoryPriceRange(category, minPrice, maxPrice);
}
public void updateIsOnSaleFor(Sku sku) {
final Product product = productRepository.queryProduct(sku);
product.setOnSale(true);
productRepository.save(product);
}
Let’s take our first step towards pulling the “Product pricing” service out of the Catalog monolith.
Step 1. Identify logic and data related to the new service
The first step is about identifying the data and logic related to the
product pricing service that lives in the monolith. Our Catalog application
has a Products table which has core product attributes such as name,
SKU, category_name and is_active flag (which indicates if
the product is active or discontinued). Each product belongs to a product category.
A product category
is a grouping of products. For example, “Men’s Shirts” category
has products like “Floral Shirt” and “Tuxedo Shirt”. There is core product
related logic such as searching a product by name in the monolith.
The Products table also has pricing related
fields such as original_price, sale_price and
is_on_sale flag which indicates if the product is on sale
or not.
The monolith has pricing related logic such as calculating the price for a
product and updating the is_on_sale flag. Getting the price range for a category
is interesting as it is primarily product pricing logic but it also has some core product logic.
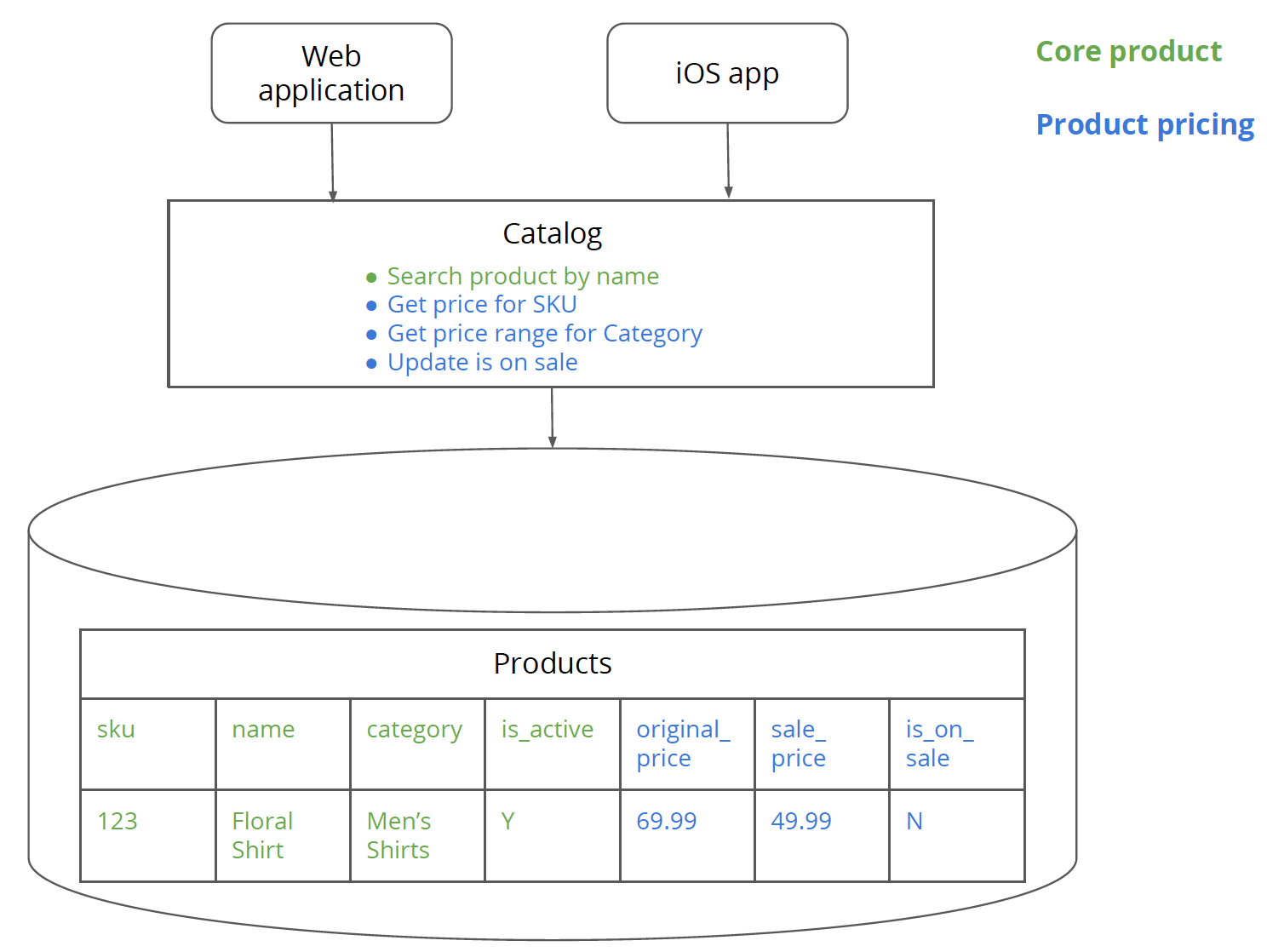
Figure 2: Core product logic and data is highlighted in green whereas product pricing data and logic is in blue.
This is the same code that we saw earlier except that it is now color coded to show the parts of the code that fall into Core product versus Product pricing .
class CatalogService…
public Sku searchProduct(String searchString) { return productRepository.searchProduct(searchString); } public Price getPriceFor(Sku sku) { Product product = productRepository.queryProduct(sku); return calculatePriceFor(product); } private Price calculatePriceFor(Product product) { if(product.isOnSale()) return product.getSalePrice(); return product.getOriginalPrice(); } public CategoryPriceRange getPriceRangeFor(Category category) { List<Product> products = productRepository.findProductsFor(category); Price maxPrice = null; Price minPrice = null; for (Product product : products) { if (product.isActive()) { Price productPrice = calculatePriceFor(product); if (maxPrice == null || productPrice.isGreaterThan(maxPrice)) { maxPrice = productPrice; } if (minPrice == null || productPrice.isLesserThan(minPrice)) { minPrice = productPrice; } } } return new CategoryPriceRange(category, minPrice, maxPrice); } public void updateIsOnSaleFor(Sku sku) { final Product product = productRepository.queryProduct(sku); product.setOnSale(true); productRepository.save(product); }
Step 2. Create a logical separation for the logic of the new service in the monolith
Step 2 and 3 are about creating a logical separation for the logic and data for the product pricing service while still working in the monolith. You essentially isolate the product pricing data and logic from the larger monolith before you actually pull it out into a new service. The advantage of doing this is that, if you get your product pricing service boundary wrong (logic or data) then it is going to be much easier to refactor your code while you are in the same monolith codebase as opposed to pulling it out and refactoring “over the wire”.
As part of Step 2, we will be creating service classes for
wrapping the logic for product pricing and core product called
ProductPricingService and CoreProductService respectively.
These service classes would map one-to-one with our “physical” services –
Product pricing and Core product as you will see in the later steps.
We would also be creating separate repository classes –
ProductPriceRepository and CoreProductRepository.
These will be used to access the product pricing data and core product data
from the Products table respectively.
The key point to keep in mind during this step is that
the ProductPricingService or ProductPriceRepository
should not access the
Products table for core product information.
Instead for any core product
related information, product pricing code should go strictly through
the CoreProductService.
You will see an example of this in the
refactored getPriceRangeFor method below.
No table joins are permitted from tables that belong to the core product part of the system to the tables that belong to product pricing. Similarly, there should be no “hard” constraints in the database between the core product data and the product pricing data such as foreign keys or database triggers. All joins as well as constraints have to be moved up to the logic layer from the database layer. This is unfortunately easier said than done and is one of the hardest things to do but absolutely necessary to break apart the database.
Having said that, core product and product pricing do have a shared identifier – the product SKU to uniquely identify the product across the two parts of the system down to the database level. This “cross system identifier” will be used for cross service communication (as demonstrated in later steps) and hence it is important to select this identifier wisely. It should be one service that owns the cross system identifier. All other services should use the identifier as a reference but not change it. It is immutable from their point of view. The service that is best suited to manage the life cycle of the entity for which the identifier exists, should own the identifier. For example, in our case, core product owns the product lifecycle and hence owns the SKU identifier.
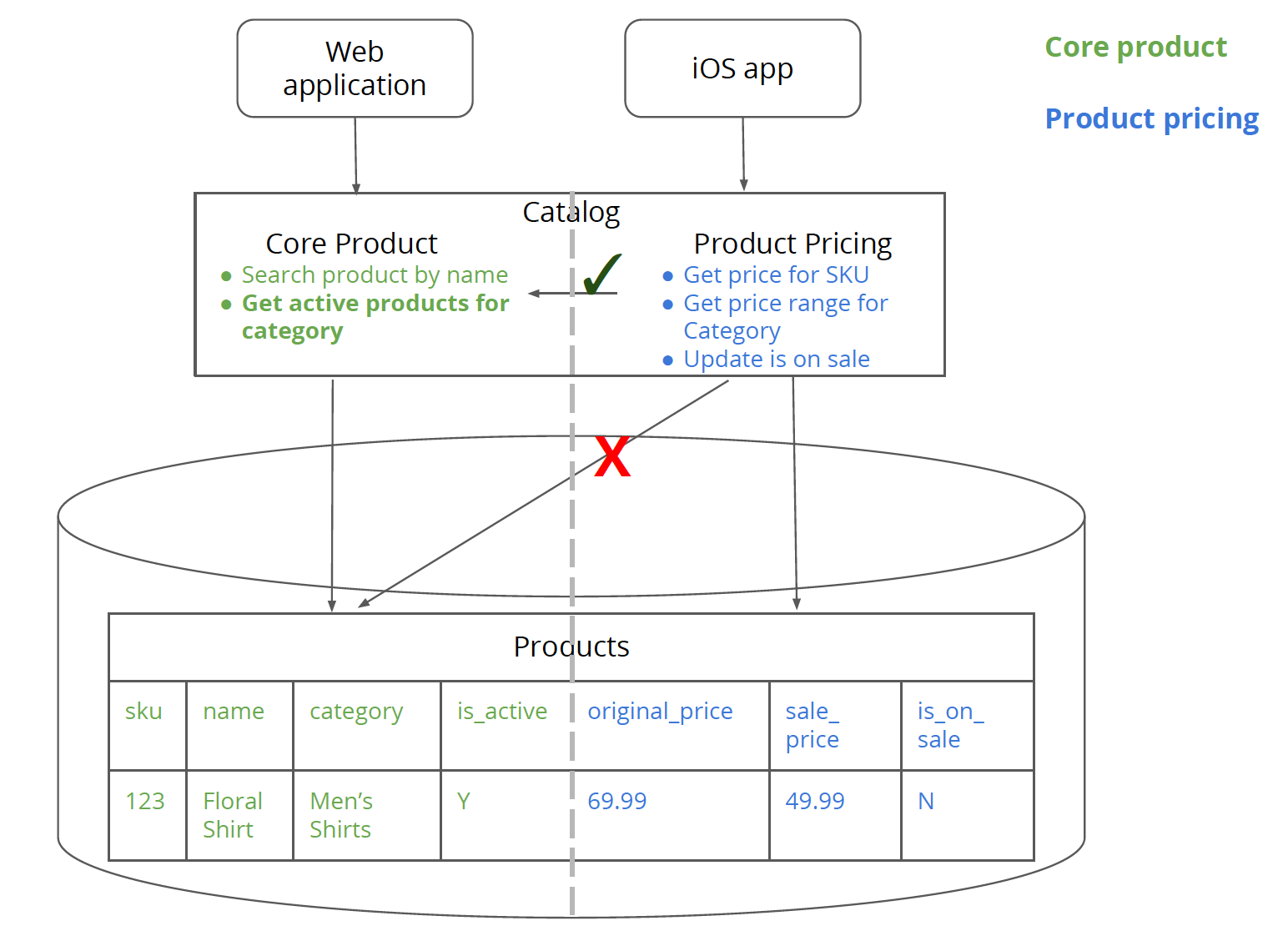
Figure 3: Logical separation between core product logic and product pricing logic while connecting to the same Products table.
Below is the refactored code. You will see the newly created
ProductPricingService
which holds pricing specific logic. We
also have the productPriceRepository to talk to the
pricing specific data in Products table. Instead of the
Product data class, we now have
data classes ProductPrice and CoreProduct
for holding the respective product pricing and core product data.
The getPriceFor and calculatePriceFor
functions are fairly straightforward
to convert over to point at the new productPriceRepository class.
class ProductPricingService…
public Price getPriceFor(Sku sku) {
ProductPrice productPrice = productPriceRepository.getPriceFor(sku);
return calculatePriceFor(productPrice);
}
private Price calculatePriceFor(ProductPrice productPrice) {
if(productPrice.isOnSale()) return productPrice.getSalePrice();
return productPrice.getOriginalPrice();
}
Getting the price range for a category logic is more involved since it
needs to know which products belong to the category which lives in the
core product part of the application. getPriceRangeFor method makes a
call to the getActiveProductsFor method in coreProductService to
get the list of active products for a given category. Thing to note here is that
given is_active is an attribute of the core product, we have
moved the isActive check over into the coreProductService.
class ProductPricingService…
public CategoryPriceRange getPriceRangeFor(Category category) {
List<CoreProduct> products = coreProductService.getActiveProductsFor(category);
List<ProductPrice> productPrices = productPriceRepository.getProductPricesFor(mapCoreProductToSku(products));
Price maxPrice = null;
Price minPrice = null;
for (ProductPrice productPrice : productPrices) {
Price currentProductPrice = calculatePriceFor(productPrice);
if (maxPrice == null || currentProductPrice.isGreaterThan(maxPrice)) {
maxPrice = currentProductPrice;
}
if (minPrice == null || currentProductPrice.isLesserThan(minPrice)) {
minPrice = currentProductPrice;
}
}
return new CategoryPriceRange(category, minPrice, maxPrice);
}
private List<Sku> mapCoreProductToSku(List<CoreProduct> coreProducts) {
return coreProducts.stream().map(p -> p.getSku()).collect(Collectors.toList());
}
Here is what the new getActiveProductsFor method for getting active
products for a given category looks like.
class CoreProductService…
public List<CoreProduct> getActiveProductsFor(Category category) {
List<CoreProduct> productsForCategory = coreProductRepository.getProductsFor(category);
return filterActiveProducts(productsForCategory);
}
private List<CoreProduct> filterActiveProducts(List<CoreProduct> products) {
return products.stream().filter(p -> p.isActive()).collect(Collectors.toList());
}
In this case, we have kept the isActive check in the service class
but this can be easily moved down into the database query. In fact,
such a type of refactoring of splitting functionality into multiple services
often makes it easy to spot opportunities to move logic into the database query and thus make the
code more performant.
The updateIsOnSale logic is also fairly straight forward and would have
to be refactored as below.
class ProductPricingService…
public void updateIsOnSaleFor(Sku sku) {
final ProductPrice productPrice = productPriceRepository.getPriceFor(sku);
productPrice.setOnSale(true);
productPriceRepository.save(productPrice);
}
The searchProduct method points to
the newly created coreProductRepository for searching the product.
class CoreProductService…
public Sku searchProduct(String searchString) {
return coreProductRepository.searchProduct(searchString);
}
The CatalogService (top level interface to the monolith)
will be refactored to delegate the service method calls
to the appropriate service – CoreProductService or
ProductPricingService. This is important, so that we do not break
existing contracts with the clients of the monolith.
The searchProduct method gets delegated to coreProductService.
class CatalogService…
public Sku searchProduct(String searchString) {
return coreProductService.searchProduct(searchString);
}
The pricing related methods get delegated to productPricingService.
class CatalogService…
public Price getPriceFor(Sku sku) {
return productPricingService.getPriceFor(sku);
}
public CategoryPriceRange getPriceRangeFor(Category category) {
return productPricingService.getPriceRangeFor(category);
}
public void updateIsOnSaleFor(Sku sku) {
productPricingService.updateIsOnSaleFor(sku);
}
Step 3. Create new table/s to support the logic of the new service in the monolith
As part of this step, you
would split the pricing related data into a new table – ProductPrices.
At the end of this step, the product pricing logic should access
the ProductPrices table and not the
Products table directly. For any information that it needs from the
Products table related to core product information, it should go
through the core product logic layer. This step should result in code changes
only in the productPricingRepository class and not in any of
the other classes, especially the service classes.
It is important to note that this step involves data migration from
the Products table to the ProductPrices table.
Make sure you design the columns in the new table to look exactly
the same as the product pricing related columns in the Products table.
This will keep the repository code simple and make the data migration simple.
If you notice bugs after you have pointed the productPricingRepository
to the new table, you can point the
productPricingRepository code back to the Products table.
You can choose to delete the product pricing related fields from
the Products table once this step has been successfully completed.
Essentially what we are doing here is a database migration which involves splitting a table into two tables and moving data from the original table into the newly created table. My colleague Pramod Sadalage wrote a whole book on Refactoring Databases which you should check out if you are curious to know more about this topic. As a quick reference, you can refer to the Evolutionary Database Design article by Pramod and Martin Fowler.
At the end of this step, you should be able to get indications of
the possible impact the new service would have on the overall system in terms of
functional as well cross-functional requirements especially performance. You
should be able to see the performance impact of “in memory data joins” in the logic layer.
In our case
getPriceRangeFor makes an in memory data join between core product and product
pricing information. In memory data joins in the logic layer will always
be more expensive than making those joins at the database layer but that is cost of having
decoupled data systems. If the performance hurts at this stage, it is going to get worse
when the data goes back and forth across the physical services over the wire. If the
performance requirements (or any other requirements for that matter) are not being met,
then it is likely you will have to rethink the service boundary.
At least, the clients (Web application and iOS app) are largely transparent to this change
since we have not changed any of the client interactions yet. This allows for
quick and cheap experimentation with service boundaries which is a beauty of this step.
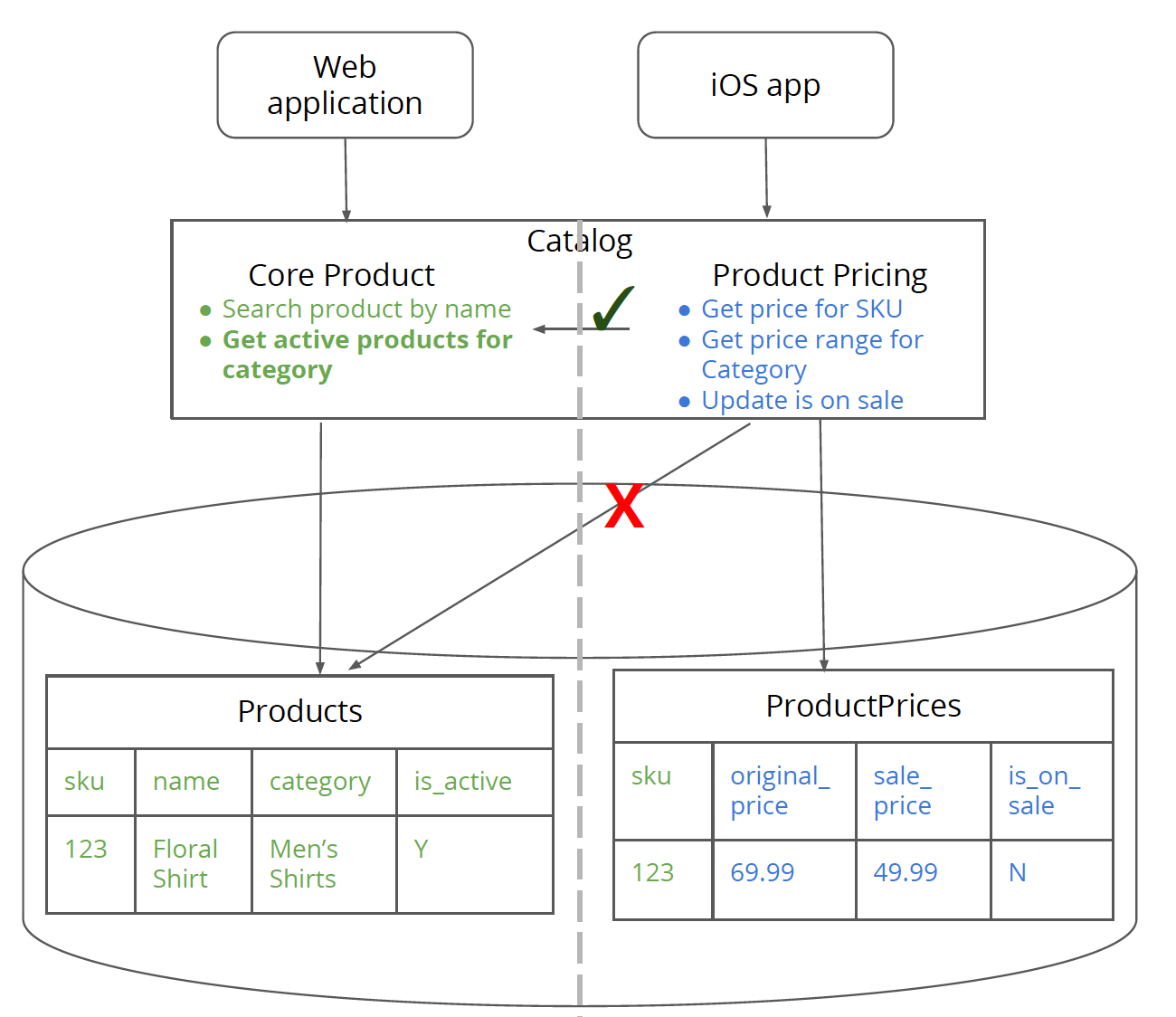
Figure 4: Logical separation between core product logic and data and product pricing logic and data.
Step 4. Build new service pointing to tables in monolithic database
In this step, you build a brand new “physical” service for
product pricing with logic from ProductPricingService while still pointing
to the ProductPrices table in the monolith database. Note that at this point,
calling the CoreProductService from ProductPricingService
will be a network call and will incur a performance penalty along with having to deal
with issues concerning remote calls like timeouts which should be handled accordingly.
This might be a good
opportunity to create a “business truthful”
abstraction for the product pricing service so
that you are modeling the service to represent the business intention
rather than the mechanics of the solution. For example, when the business user
is updating the updateIsOnSale flag they are
really creating a “promotion” in the system for a given product.
Below is what updateIsOnSaleFor looks like after the refactoring.
We have also added the ability to
specify the promotion price as part of this change which was not available before.
This might also be a good time to simplify the interface by pushing some of
the service-related complexity
back into the service that might have leaked out into the clients. This would be a
welcome change from a service consumer's point of view.
class ProductPricingService…
public void createPromotion(Promotion promotion) { final ProductPrice productPrice = productPriceRepository.getPriceFor(promotion.getSku()); productPrice.setOnSale(true); productPrice.setSalePrice(promotion.getPrice()); productPriceRepository.save(productPrice); }
However, the limitation around this is that the changes should not require changing the table structure or the data semantics in any way as that will break the existing functionality in the monolith. Once the service has been fully extracted (in Step 9), then you can change the database happily to your heart's content as that would be just as good as making a code change in the logic layer.
You might want to make these changes before you move over the clients because changing a service interface can be an expensive and time consuming process, especially in a large organization as it involves buy in from different service consumers to move to the new interface in a timely fashion. This will be discussed in further detail in the next step. You can safely release this new pricing service to production and test it. There are no clients for this service yet. Also, there is no change to the clients of the monolith – Web application and iOS app, in this step.
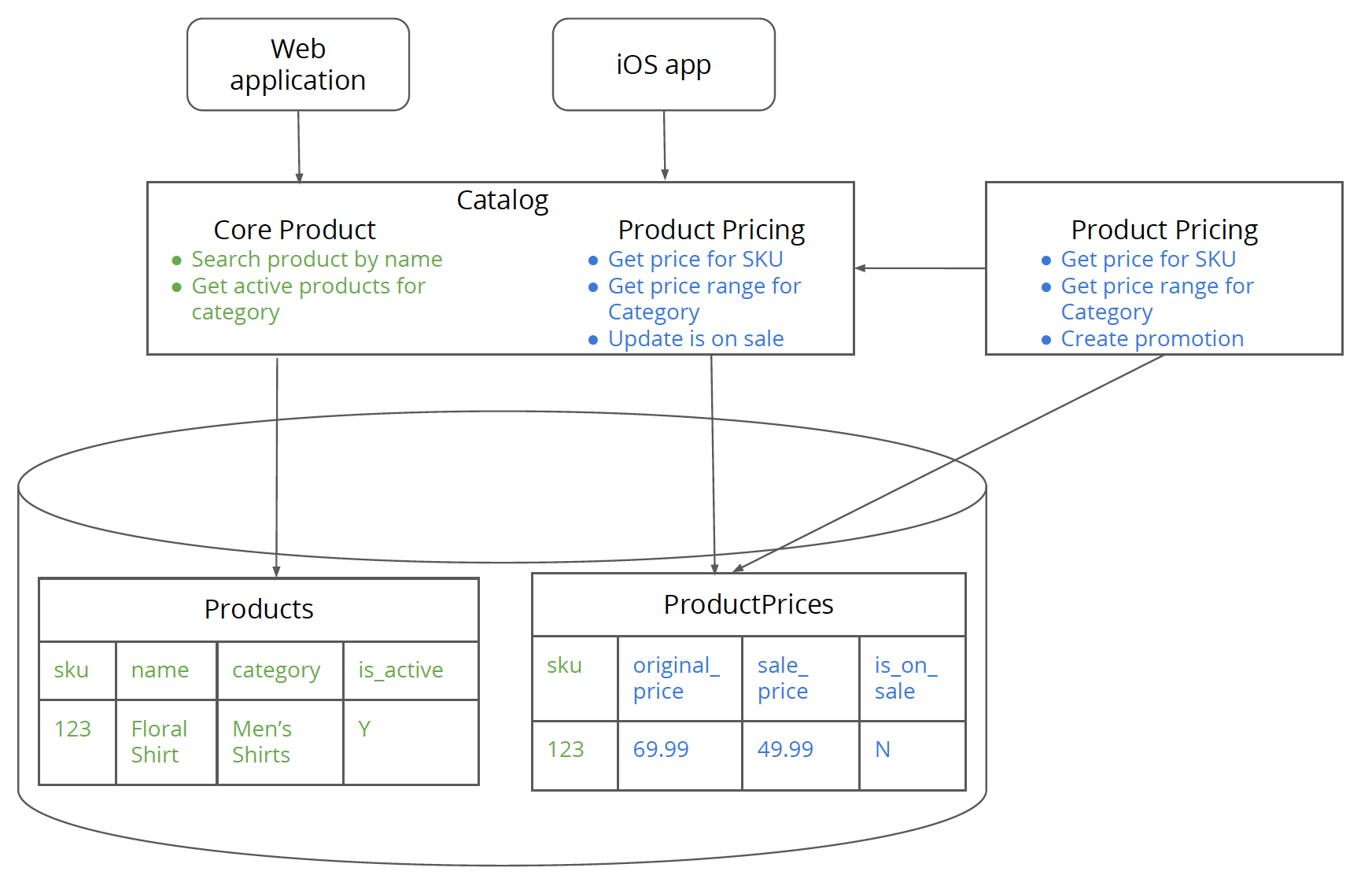
Figure 5: New physical product pricing service that points to the ProductPrices table in the monolith while depending on the monolith for the core product functionality.
Step 5. Point clients to the new service
In this step, the clients of the monolith that are interested in the product pricing functionality need to move over to the new service. The work in this step will depend on two things. First of all it will depend on how much of the interface has changed between the monolith and the new service. Second, and arguably more complex from an organizational standpoint, the bandwidth (capacity) the client teams have to complete this step in a timely fashion.
If this step drags on, it is quite likely that the architecture will be left in a half complete state where some clients point to the new service while some point to the monolith. This arguably leaves the architecture in a worse off state than before you started. This is why the 'atomic step of architecture evolution' principle we discussed earlier is important. Make sure you have the organizational alignment from all clients of the new service functionality to move to the new service in a timely fashion before starting on the migration journey. It is very easy to get distracted by other high priority matters while leaving the architecture in a half baked state.
Now the good news is that not all service clients have to migrate at the exact same time or need to coordinate their migration with each other. However, migrating all the clients is important before moving to the next step. If it does not already exist, you can introduce some monitoring at the service level for pricing related methods to identify the “migration laggards” – service consumers that have not migrated over to the new service.
In theory, you could work on some of the next steps before the clients have migrated, especially the next one which involves creating pricing database but for the sake of simplicity, I recommend moving sequentially as much as possible.
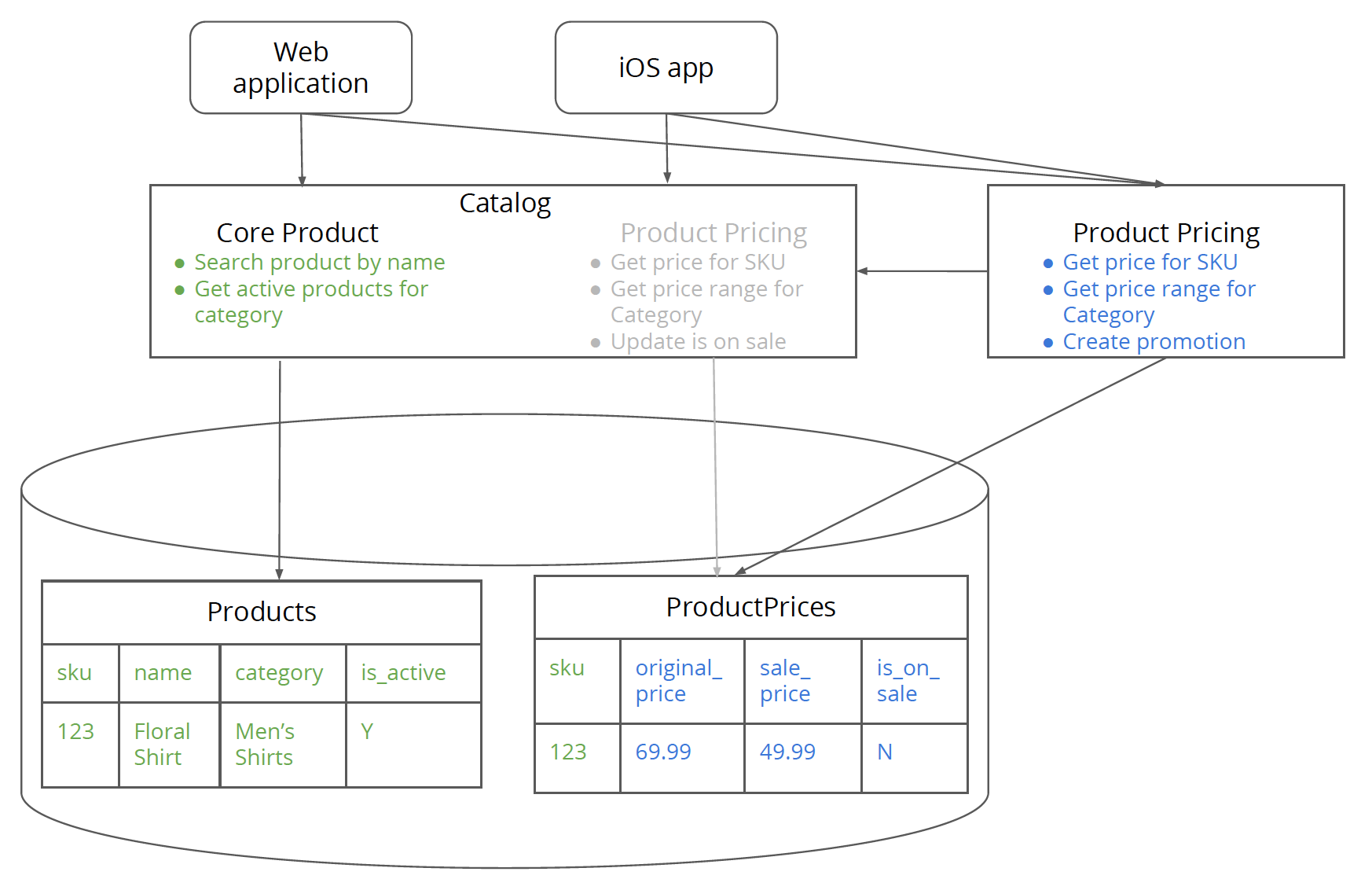
Figure 6: The clients of the monolith that are interested in pricing functionality have been migrated to the new product pricing service.
Step 6. Create the database for the new service
This step is relatively easy where you build a pricing database mirroring the table structure in the monolith. It might be tempting to build a brand new schema for pricing while you are in process of building a brand new service. But having a brand new schema, makes the data migration in later steps harder. It also means the new pricing service would have to support two different schemas – one from the monolith, the other from the new database. I would recommend keeping things simple – first extract the pricing service (finishing all the steps mentioned here) and then refactoring the internals of the pricing service. Once the pricing database has been isolated, changing it should be just as same as changing any code in the service as none of clients would be accessing the pricing database directly.
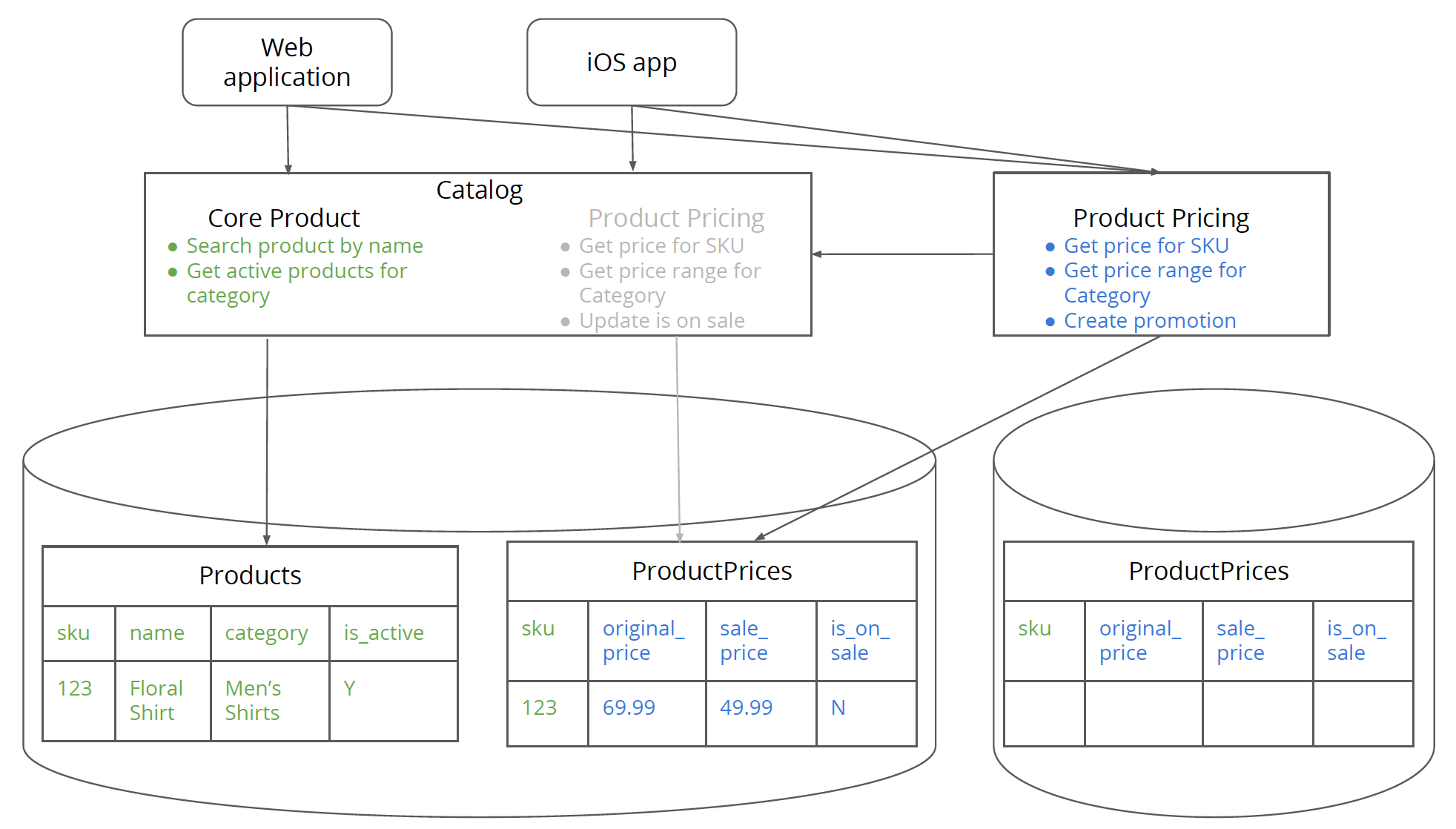
Figure 7: New standalone pricing database has been created.
Step 7. Sync data from the monolith to the new database
In this step, you sync data from the monolith database for the pricing tables to the new pricing database. Syncing the data between the monolith and the new service database is fairly straight forward if the schema in the new database is the same as the pricing tables in the monolith. It is essentially the same as setting up the pricing database as a “read replica” of the monolith database (just for the pricing related tables though). This will ensure that the data in the new pricing database is current.
Now you are ready to hook up the pricing service to the new pricing database in the next step.
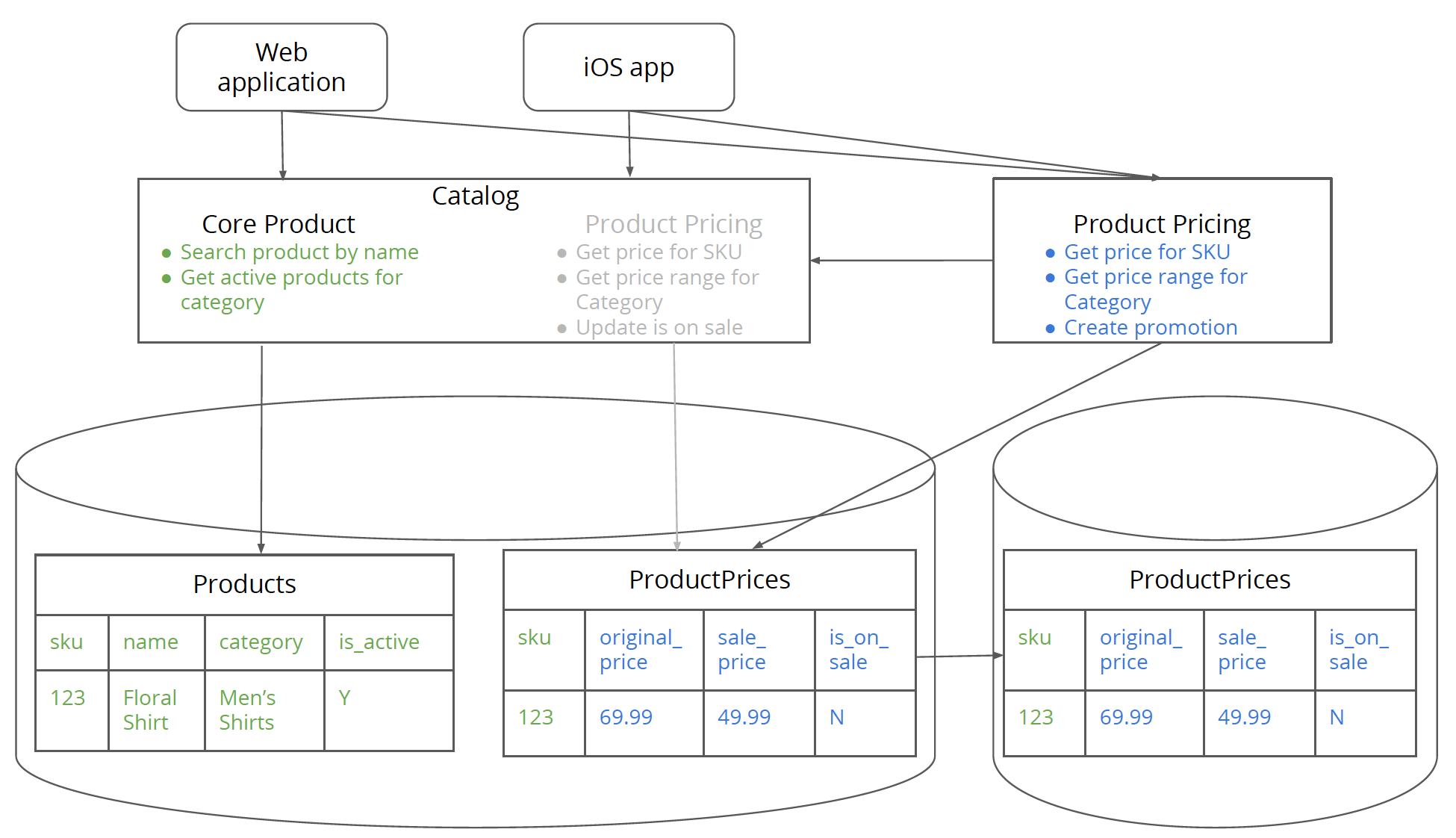
Figure 8: Data synced between the product pricing related tables and the new pricing database tables.
Step 8. Point new service to the new database
Before you start this step, it is absolutely important that all clients of the monolith that are interested in pricing information have moved over to the new service. If not, then you could get into write conflicts which violates the 'have a single write copy for the data' principle we discussed earlier. After all clients have migrated to the new service, you point the pricing service to the new pricing database. You essentially switch the database connection from the monolithic database to the new database.
One of the advantages of this design is that you can easily switch the connection back to the old database if you notice any issues. One of the issues you could have is the code in the new service relies on some tables/fields that do not exist in the new database but only exist in the old database. This could happen because you failed to identify that data in step 1. This could happen with something like “reference” data, for e.g. supported currencies. Once you have successfully resolved these issues, you can move over to the next step.
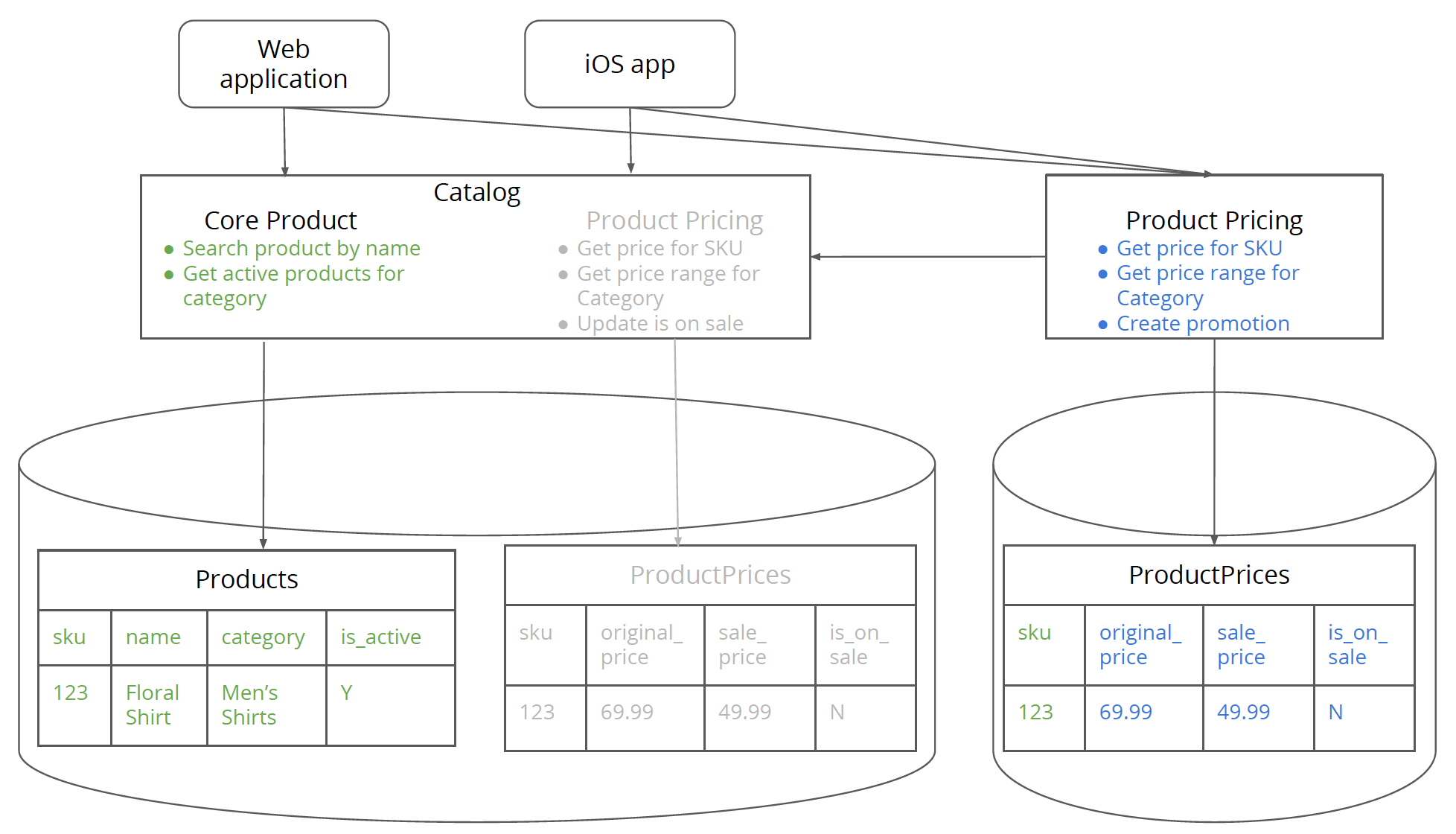
Figure 9: Product pricing service points to the pricing database.
Step 9. Delete logic and schema from the monolith related to the new service
In this step, you delete the pricing related logic and schema from the monolith. Too often teams leave old tables in the database for ever because they are worried “they might need it someday”. Taking a backup of the entire database might help assuage some of those fears.
At this point, all that the CatalogService is doing is delegating
core product method calls
to the CoreProductService, so we can remove the layer of indirection
and have clients call directly the CoreProductService.
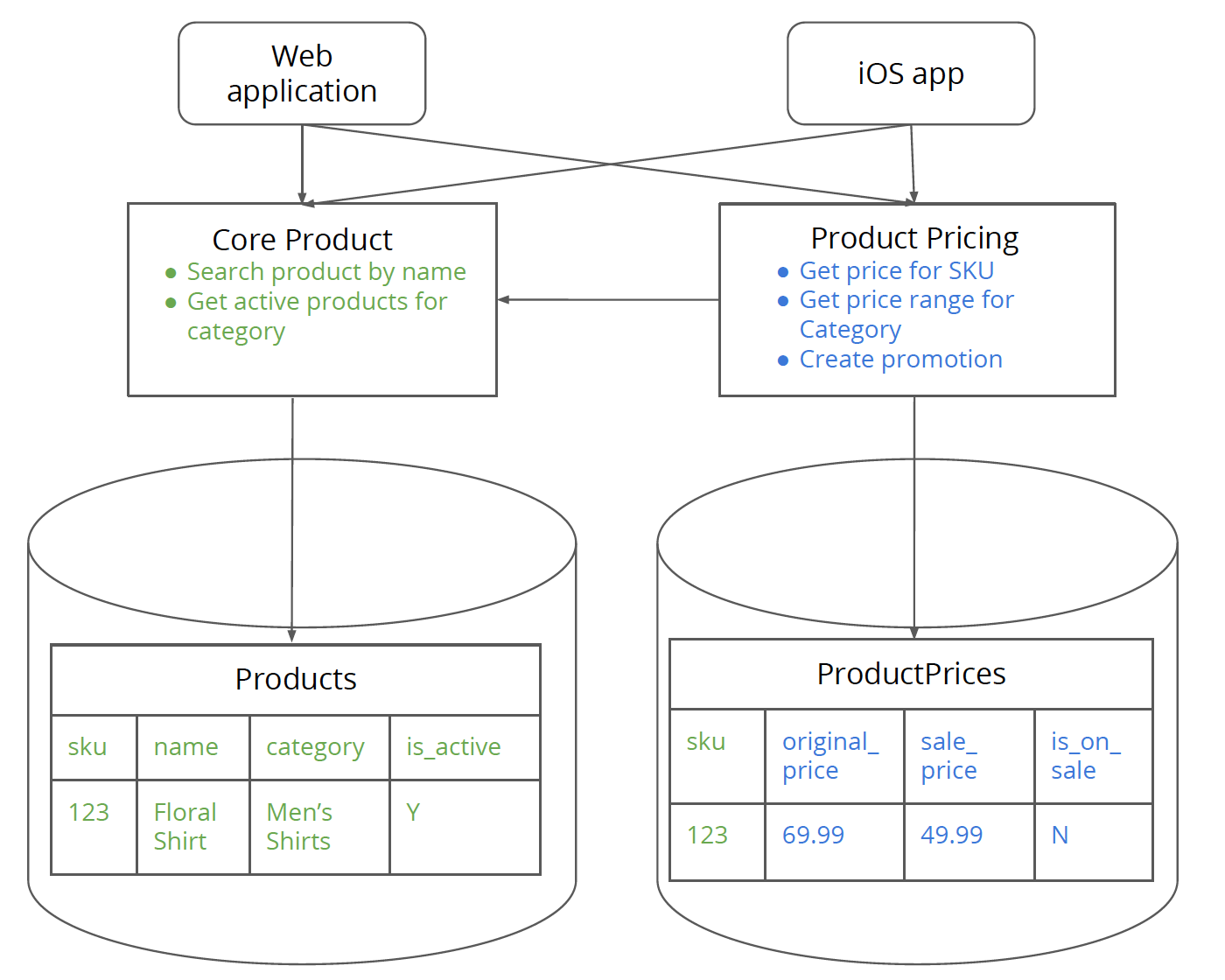
Figure 10: Core product has only core product related logic and data whereas product pricing has pricing related data and logic. They communicate with each other only via the logic layer.
Summary
That's it! We just broke off a data-rich service from the monolith. Woohoo!
When you do this the first time, there will be significant pain and valuable lessons learnt which you can use to inform your next service extraction. On your first service extraction, it is best not to combine the steps, even if it may be tempting to do so. Taking one step at a time, makes the process of breaking up the monolith less daunting, safe and predictable. Once you have achieved a certain level of mastery over this pattern then you can start optimizing the process based on your learnings.
Go break that monolith! Good luck!
Acknowledgements
I would love to thank Martin Fowler for hosting this article and being generous with his time in reviewing this article. His review comments have truly taken this article to the next level. I would also like to thank Jorge Lee for providing critical commentary. I would like to thank my Thoughtworks colleagues Joey Guerra, Matt Newman, Vanessa Towers, Ran Xiao and Kuldeep Singh for their comments on our internal mailing list.
Significant Revisions
30 August 2018: Published the rest of the article
29 August 2018: Published sixth and seventh step
28 August 2018: Published fifth step
27 August 2018: Published fourth step
25 August 2018: Published third step
24 August 2018: Published second step
23 August 2018: Published first step