
Building Boba AI
Some lessons and patterns learnt in building an LLM-powered generative application
We are building an experimental AI co-pilot for product strategy and generative ideation called “Boba”. Along the way, we’ve learned some useful lessons on how to build these kinds of applications, which we’ve formulated in terms of patterns. These patterns allow an application to help the user interact more effectively with a Large-Language Model (LLM), orchestrating prompts to gain better results, helping the user navigate a path of an intricate conversational flow, and integrating knowledge that the LLM doesn't have available.
29 June 2023

Farooq is a Product Strategy Principal at Thoughtworks in Canada. As a specialized generalist with hands-on experience in product management, strategy and software development, Farooq enjoys working with clients to solve difficult problems that lie at the intersection of design, business, and technology.
Boba is an experimental AI co-pilot for product strategy & generative ideation, designed to augment the creative ideation process. It’s an LLM-powered application that we are building to learn about:
- How to design and build generative experiences beyond chat, powered by LLMs
- How to use AI to augment our product and strategy processes and craft
An AI co-pilot refers to an artificial intelligence-powered assistant designed to help users with various tasks, often providing guidance, support, and automation in different contexts. Examples of its application include navigation systems, digital assistants, and software development environments. We like to think of a co-pilot as an effective partner that a user can collaborate with to perform a specific domain of tasks.
Boba as an AI co-pilot is designed to augment the early stages of strategy ideation and concept generation, which rely heavily on rapid cycles of divergent thinking (also known as generative ideation). We typically implement generative ideation by closely collaborating with our peers, customers and subject matter experts, so that we can formulate and test innovative ideas that address our customers’ jobs, pains and gains. This begs the question, what if AI could also participate in the same process? What if we could generate and evaluate more and better ideas, faster in partnership with AI? Boba starts to enable this by using OpenAI’s LLM to generate ideas and answer questions that can help scale and accelerate the creative thinking process. For the first prototype of Boba, we decided to focus on rudimentary versions of the following capabilities:
1. Research signals and trends: Search the web for articles and news to help you answer qualitative research questions, like:
- How is the hotel industry using generative AI today?
- What are the key challenges facing retailers in 2023 and beyond?
- How are pharma companies using AI to accelerate drug discovery?
- What were the key takeaways from Nike's latest earnings call?
- How do people on Reddit feel about Lululemon's products?”
2. Creative Matrix: The creative matrix is a concepting method for sparking new ideas at the intersections of distinct categories or dimensions. This involves stating a strategic prompt, often as a “How might we” question, and then answering that question for each combination/permutation of ideas at the intersection of each dimension. For example:
- Strategic prompt: “How might we use generative AI to transform wealth management?”
- Dimension 1 - Stages of the value chain: Client acquisition, financial planning, portfolio construction, investment execution, performance monitoring, risk management, reporting and communication
- Dimension 2 - Different personas: For employees, for customers, for partners
3. Scenario building: Scenario building is a process of generating future-oriented stories by researching signals of change in business, culture, and technology. Scenarios are used to socialize learnings in a contextualized narrative, inspire divergent product thinking, conduct resilience/desirability testing, and/or inform strategic planning. For example, you can prompt Boba with the following and get a set of future scenarios based on different time horizons and levels of optimism and realism:
- “Hotel industry uses generative AI to transform the guest experience”
- “Pfizer accelerates drug discovery with the use of generative AI”
- “Show me the future of payments 10 years from now”
4. Strategy ideation: Using the Playing to Win strategy framework, brainstorm “where to play” and “how to win” choices based on a strategic prompt and possible future scenarios. For example you can prompt it with:
- How might Nike use generative AI to transform its business model?
- How might the Globe & Mail increase readership and engagement?
5. Concept generation: Based on a strategic prompt, such as a “how might we” question, generate multiple product or feature concepts, which include value proposition pitches and hypotheses to test.
- How might we make travel more convenient for senior citizens?
- How might we make shopping more social?
6. Storyboarding: Generate visual storyboards based on a simple prompt or detailed narrative based on current or future state scenarios. The key features are:
- Generate illustrated scenes to describe your customer journeys
- Customize the styles and illustrations
- Generate storyboards directly from generated scenarios
Using Boba
Boba is a web application that mediates an interaction between a human user and a Large-Language Model, currently GPT 3.5. A simple web front-end to an LLM just offers the ability for the user to converse with the LLM. This is helpful, but means the user needs to learn how to effectively interact the LLM. Even in the short time that LLMs have seized the public interest, we've learned that there is considerable skill to constructing the prompts to the LLM to get a useful answer, resulting in the notion of a “Prompt Engineer”. A co-pilot application like Boba adds a range of UI elements that structure the conversation. This allows a user to make naive prompts which the application can manipulate, enriching simple requests with elements that will yield a better response from the LLM.
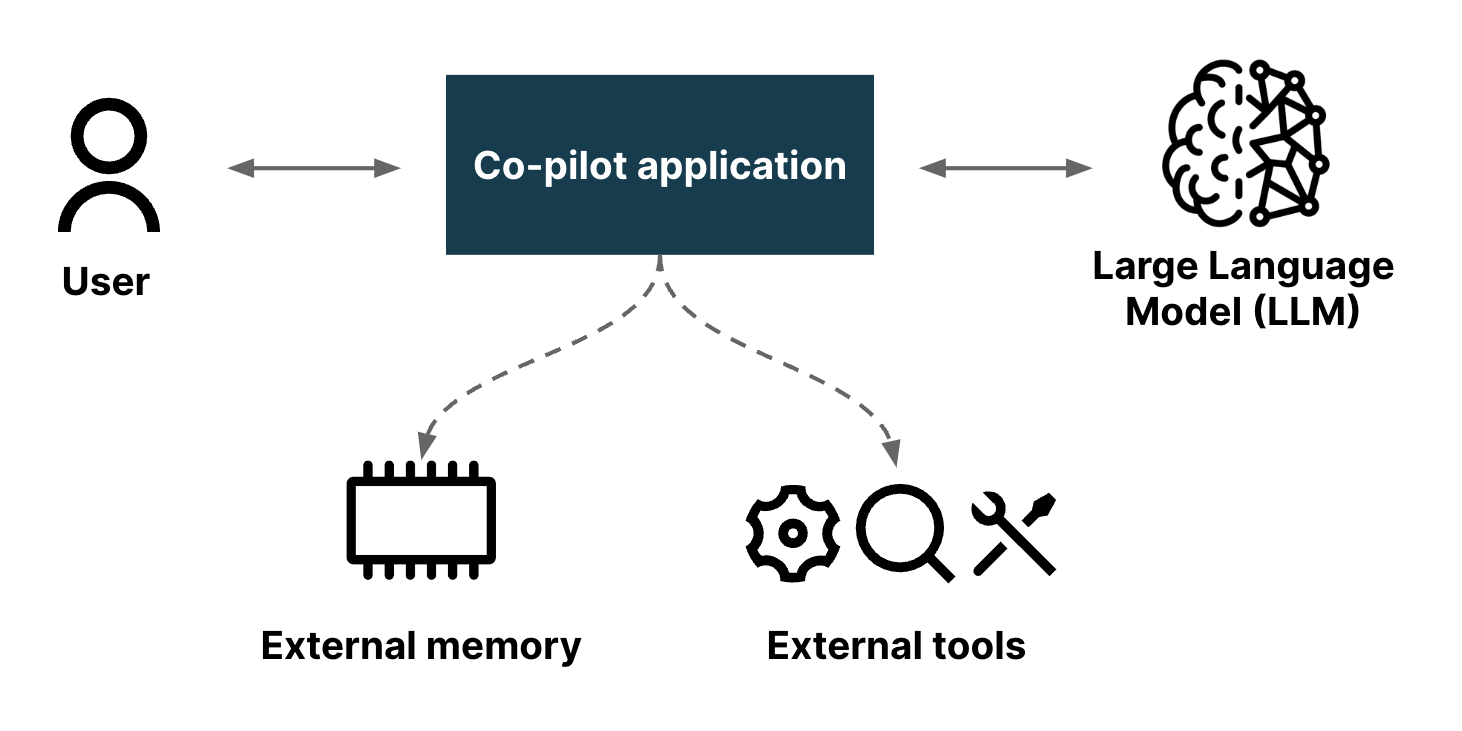
Boba can help with a number of product strategy tasks. We won't describe them all here, just enough to give a sense of what Boba does and to provide context for the patterns later in the article.
When a user navigates to the Boba application, they see an initial screen similar to this
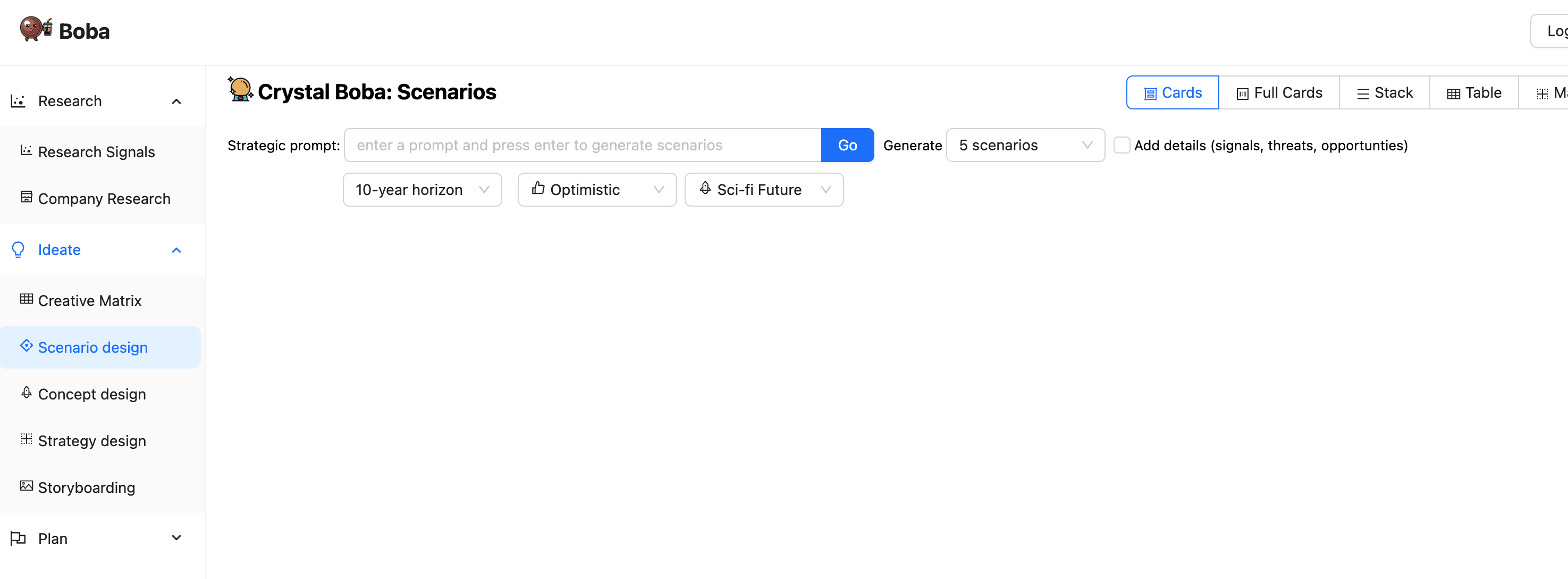
The left panel lists the various product strategy tasks that Boba supports. Clicking on one of these changes the main panel to the UI for that task. For the rest of the screenshots, we'll ignore that task panel on the left.
The above screenshot looks at the scenario design task. This invites the user to enter a prompt, such as “Show me the future of retail”.
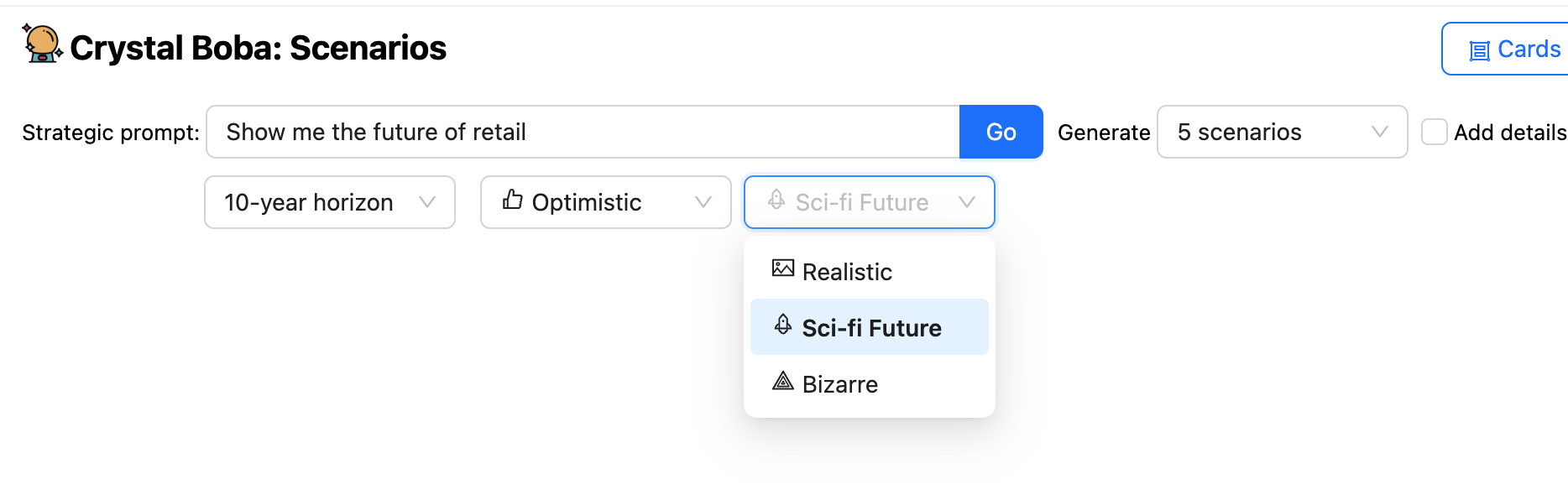
The UI offers a number of drop-downs in addition to the prompt, allowing the user to suggest time-horizons and the nature of the prediction. Boba will then ask the LLM to generate scenarios, using Templated Prompt to enrich the user's prompt with additional elements both from general knowledge of the scenario building task and from the user's selections in the UI.
Boba receives a Structured Response from the LLM and displays the result as set of UI elements for each scenario.
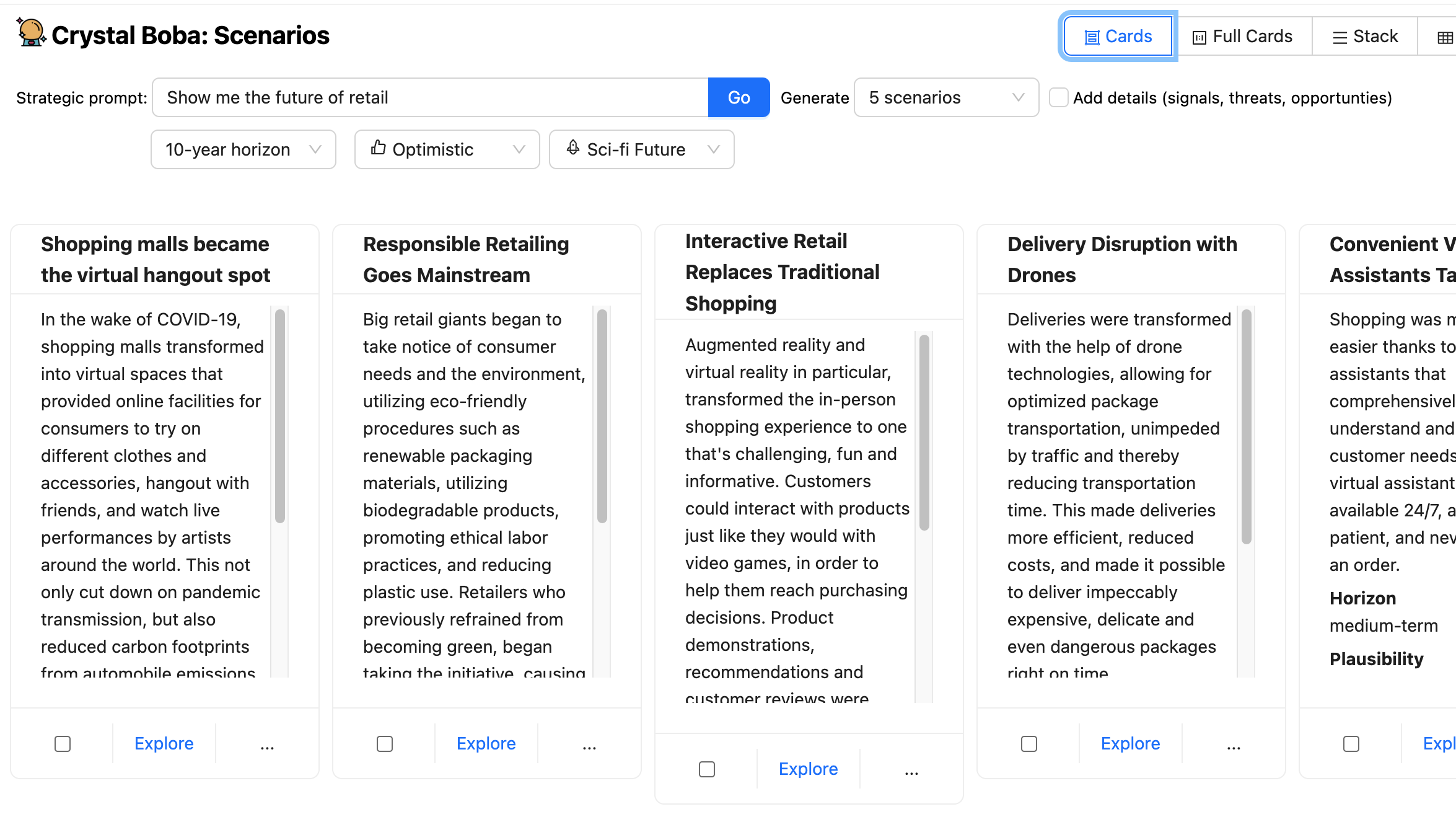
The user can then take one of these scenarios and hit the explore button, bringing up a new panel with a further prompt to have a Contextual Conversation with Boba.
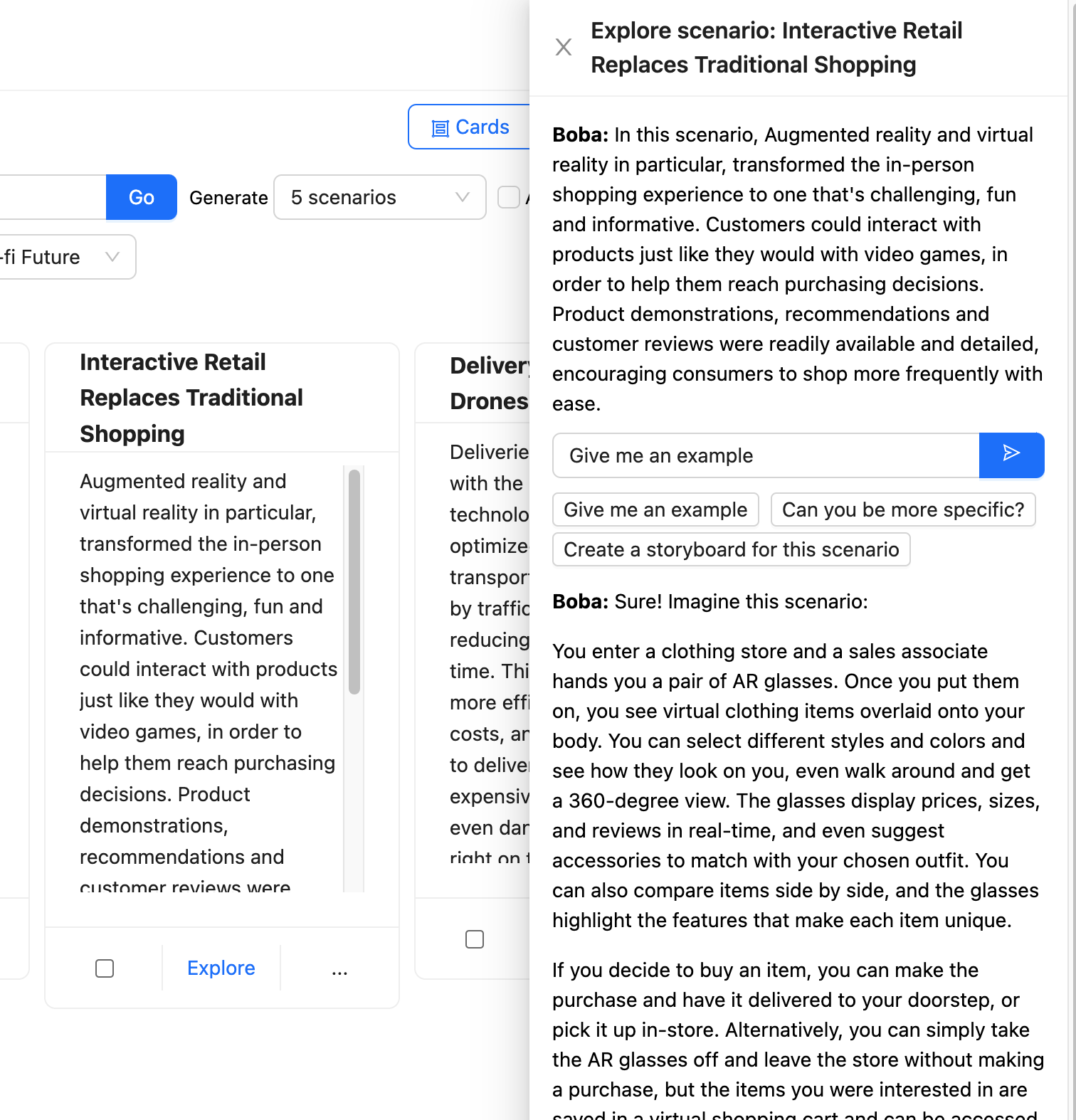
Boba takes this prompt and enriches it to focus on the context of the selected scenario before sending it to the LLM.
Boba uses Select and Carry Context to hold onto the various parts of the user's interaction with the LLM, allowing the user to explore in multiple directions without having to worry about supplying the right context for each interaction.
One of the difficulties with using an LLM is that it's trained only on data up to some point in the past, making them ineffective for working with up-to-date information. Boba has a feature called research signals that uses Embedded External Knowledge to combine the LLM with regular search facilities. It takes the prompted research query, such as “How is the hotel industry using generative AI today?”, sends an enriched version of that query to a search engine, retrieves the suggested articles, sends each article to the LLM to summarize.
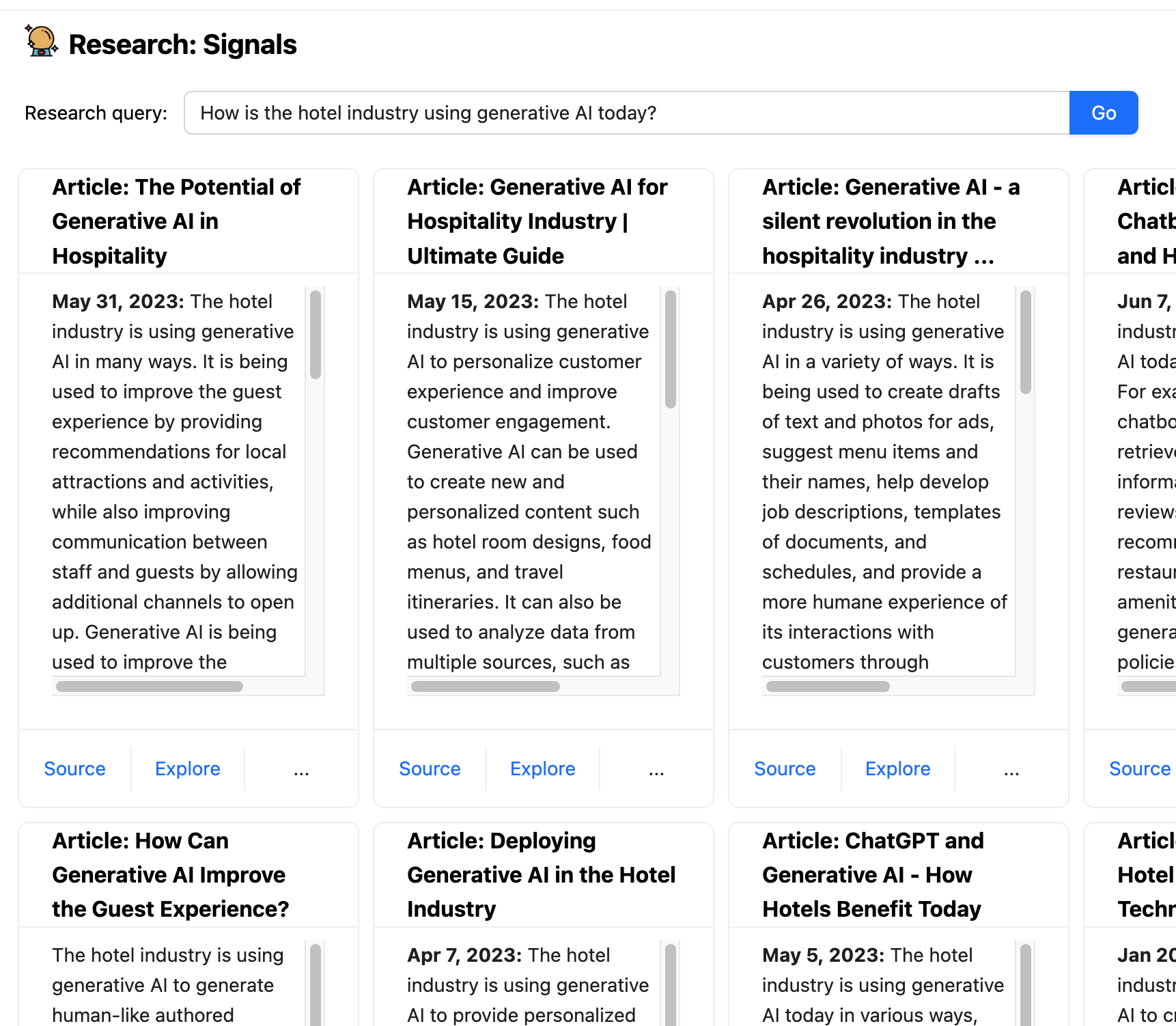
This is an example of how a co-pilot application can handle interactions that involve activities that an LLM alone isn't suitable for. Not just does this provide up-to-date information, we can also ensure we provide source links to the user, and those links won't be hallucinations (as long as the search engine isn't partaking of the wrong mushrooms).
Some patterns for building generative co-pilot applications
In building Boba, we learnt a lot about different patterns and approaches to mediating a conversation between a user and an LLM, specifically Open AI’s GPT3.5/4. This list of patterns is not exhaustive and is limited to the lessons we've learnt so far while building Boba.
Templated Prompt
Use a text template to enrich a prompt with context and structure
The first and simplest pattern is using a string templates for the prompts, also known as chaining. We use Langchain, a library that provides a standard interface for chains and end-to-end chains for common applications out of the box. If you’ve used a Javascript templating engine, such as Nunjucks, EJS or Handlebars before, Langchain provides just that, but is designed specifically for common prompt engineering workflows, including features for function input variables, few-shot prompt templates, prompt validation, and more sophisticated composable chains of prompts.
For example, to brainstorm potential future scenarios in Boba, you can enter a strategic prompt, such as “Show me the future of payments” or even a simple prompt like the name of a company. The user interface looks like this:

The prompt template that powers this generation looks something like this:
You are a visionary futurist. Given a strategic prompt, you will create
{num_scenarios} futuristic, hypothetical scenarios that happen
{time_horizon} from now. Each scenario must be a {optimism} version of the
future. Each scenario must be {realism}.
Strategic prompt: {strategic_prompt}
As you can imagine, the LLM’s response will only be as good as the prompt itself, so this is where the need for good prompt engineering comes in. While this article is not intended to be an introduction to prompt engineering, you will notice some techniques at play here, such as starting by telling the LLM to Adopt a Persona, specifically that of a visionary futurist. This was a technique we relied on extensively in various parts of the application to produce more relevant and useful completions.
As part of our test-and-learn prompt engineering workflow, we found that iterating on the prompt directly in ChatGPT offers the shortest path from idea to experimentation and helps build confidence in our prompts quickly. Having said that, we also found that we spent way more time on the user interface (about 80%) than the AI itself (about 20%), specifically in engineering the prompts.
We also kept our prompt templates as simple as possible, devoid of conditional statements. When we needed to drastically adapt the prompt based on the user input, such as when the user clicks “Add details (signals, threats, opportunities)”, we decided to run a different prompt template altogether, in the interest of keeping our prompt templates from becoming too complex and hard to maintain.
Structured Response
Tell the LLM to respond in a structured data format
Almost any application you build with LLMs will most likely need to parse the output of the LLM to create some structured or semi-structured data to further operate on on behalf of the user. For Boba, we wanted to work with JSON as much as possible, so we tried many different variations of getting GPT to return well-formed JSON. We were quite surprised by how well and consistently GPT returns well-formed JSON based on the instructions in our prompts. For example, here’s what the scenario generation response instructions might look like:
You will respond with only a valid JSON array of scenario objects.
Each scenario object will have the following schema:
"title": <string>, //Must be a complete sentence written in the past tense
"summary": <string>, //Scenario description
"plausibility": <string>, //Plausibility of scenario
"horizon": <string>
We were equally surprised by the fact that it could support fairly complex nested JSON schemas, even when we described the response schemas in pseudo-code. Here’s an example of how we might describe a nested response for strategy generation:
You will respond in JSON format containing two keys, "questions" and "strategies", with the respective schemas below:
"questions": [<list of question objects, with each containing the following keys:>]
"question": <string>,
"answer": <string>
"strategies": [<list of strategy objects, with each containing the following keys:>]
"title": <string>,
"summary": <string>,
"problem_diagnosis": <string>,
"winning_aspiration": <string>,
"where_to_play": <string>,
"how_to_win": <string>,
"assumptions": <string>
An interesting side effect of describing the JSON response schema was that we could also nudge the LLM to provide more relevant responses in the output. For example, for the Creative Matrix, we want the LLM to think about many different dimensions (the prompt, the row, the columns, and each idea that responds to the prompt at the intersection of each row and column):
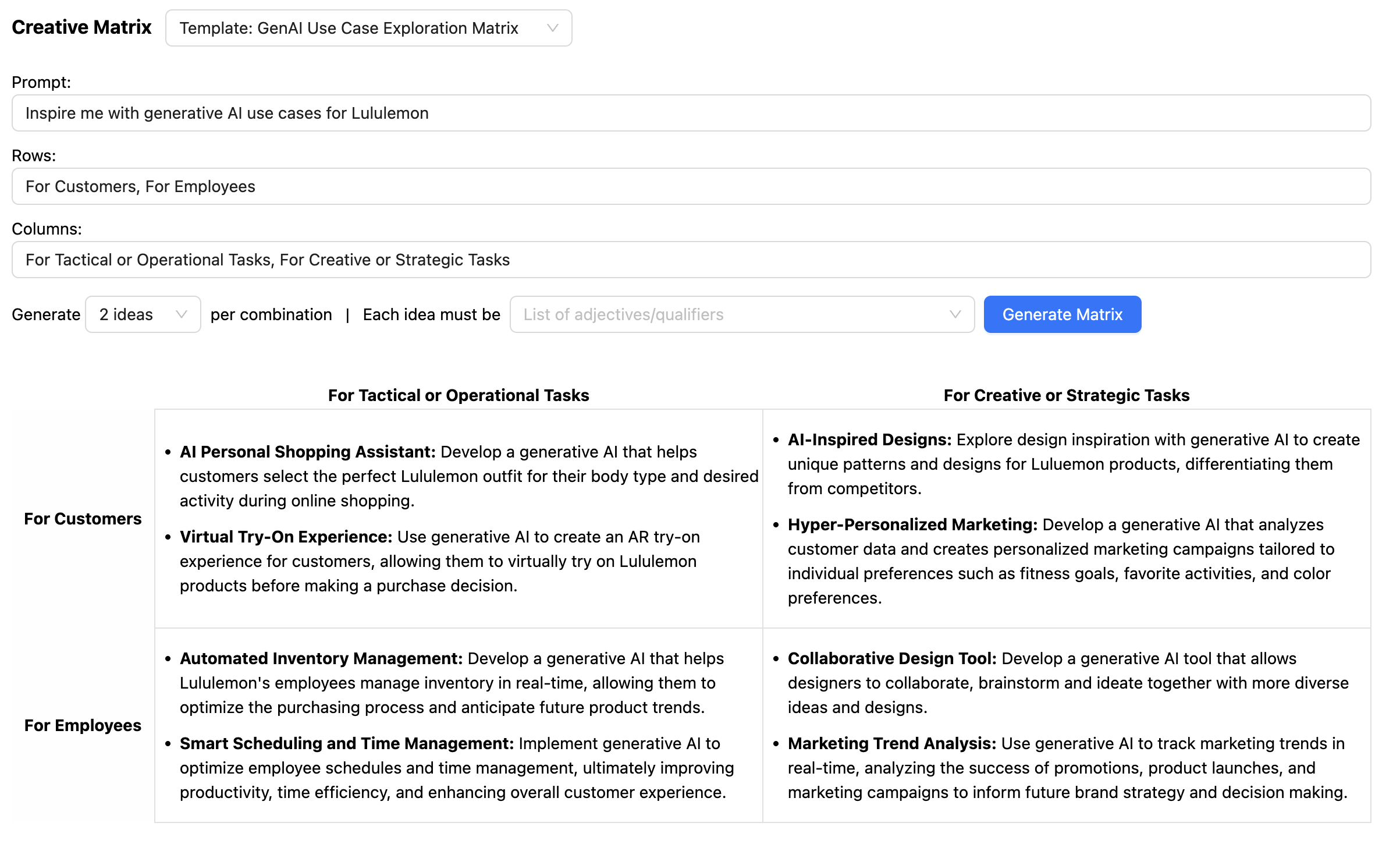
By providing a few-shot prompt that includes a specific example of the output schema, we were able to get the LLM to “think” in the right context for each idea (the context being the prompt, row and column):
You will respond with a valid JSON array, by row by column by idea. For example:
If Rows = "row 0, row 1" and Columns = "column 0, column 1" then you will respond
with the following:
[
{{
"row": "row 0",
"columns": [
{{
"column": "column 0",
"ideas": [
{{
"title": "Idea 0 title for prompt and row 0 and column 0",
"description": "idea 0 for prompt and row 0 and column 0"
}}
]
}},
{{
"column": "column 1",
"ideas": [
{{
"title": "Idea 0 title for prompt and row 0 and column 1",
"description": "idea 0 for prompt and row 0 and column 1"
}}
]
}},
]
}},
{{
"row": "row 1",
"columns": [
{{
"column": "column 0",
"ideas": [
{{
"title": "Idea 0 title for prompt and row 1 and column 0",
"description": "idea 0 for prompt and row 1 and column 0"
}}
]
}},
{{
"column": "column 1",
"ideas": [
{{
"title": "Idea 0 title for prompt and row 1 and column 1",
"description": "idea 0 for prompt and row 1 and column 1"
}}
]
}}
]
}}
]
We could have alternatively described the schema more succinctly and generally, but by being more elaborate and specific in our example, we successfully nudged the quality of the LLM’s response in the direction we wanted. We believe this is because LLMs “think” in tokens, and outputting (ie repeating) the row and column values before outputting the ideas provides more accurate context for the ideas being generated.
At the time of this writing, OpenAI has released a new feature called Function Calling, which provides a different way to achieve the goal of formatting responses. In this approach, a developer can describe callable function signatures and their respective schemas as JSON, and have the LLM return a function call with the respective parameters provided in JSON that conforms to that schema. This is particularly useful in scenarios when you want to invoke external tools, such as performing a web search or calling an API in response to a prompt. Langchain also provides similar functionality, but I imagine they will soon provide native integration between their external tools API and the OpenAI function calling API.
Real-Time Progress
Stream the response to the UI so users can monitor progress
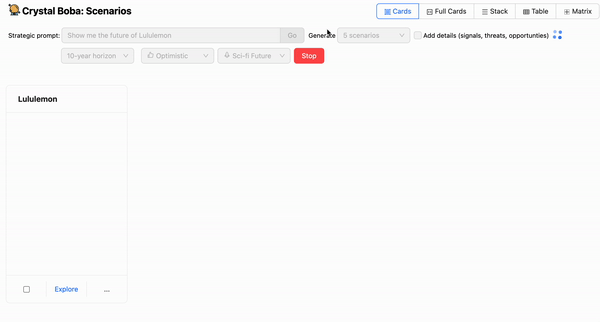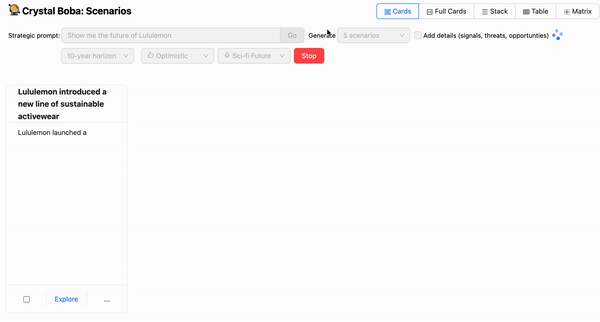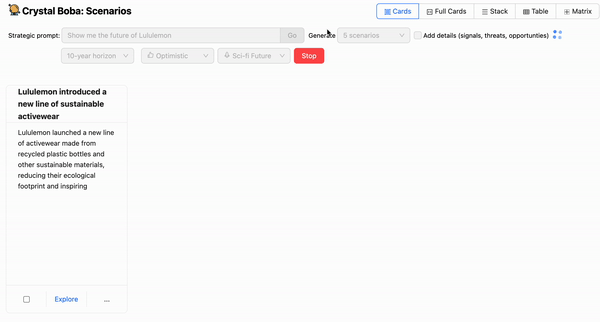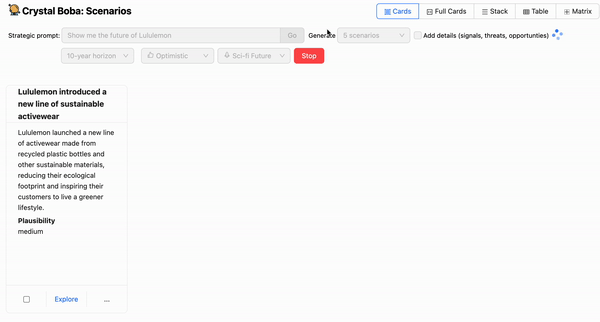
One of the first few things you’ll realize when implementing a graphical user interface on top of an LLM is that waiting for the entire response to complete takes too long. We don’t notice this as much with ChatGPT because it streams the response character by character. This is an important user interaction pattern to keep in mind because, in our experience, a user can only wait on a spinner for so long before losing patience. In our case, we didn’t want the user to wait more than a few seconds before they started seeing a response, even if it was a partial one.
Hence, when implementing a co-pilot experience, we highly recommend showing real-time progress during the execution of prompts that take more than a few seconds to complete. In our case, this meant streaming the generations across the full stack, from the LLM back to the UI in real-time. Fortunately, the Langchain and OpenAI APIs provide the ability to do just that:
const chat = new ChatOpenAI({
temperature: 1,
modelName: 'gpt-3.5-turbo',
streaming: true,
callbackManager: onTokenStream ?
CallbackManager.fromHandlers({
async handleLLMNewToken(token) {
onTokenStream(token)
},
}) : undefined
});
This allowed us to provide the real-time progress needed to create a smoother experience for the user, including the ability to stop a generation mid-completion if the ideas being generated did not match the user’s expectations:
However, doing so adds a lot of additional complexity to your application logic, especially on the view and controller. In the case of Boba, we also had to perform best-effort parsing of JSON and maintain temporal state during the execution of an LLM call. At the time of writing this, some new and promising libraries are coming out that make this easier for web developers. For example, the Vercel AI SDK is a library for building edge-ready AI-powered streaming text and chat UIs.
Select and Carry Context
Capture and add relevant context information to subsequent action
One of the biggest limitations of a chat interface is that a user is limited to a single-threaded context: the conversation chat window. When designing a co-pilot experience, we recommend thinking deeply about how to design UX affordances for performing actions within the context of a selection, similar to our natural inclination to point at something in real life in the context of an action or description.
Select and Carry Context allows the user to narrow or broaden the scope of interaction to perform subsequent tasks - also known as the task context. This is typically done by selecting one or more elements in the user interface and then performing an action on them. In the case of Boba, for example, we use this pattern to allow the user to have a narrower, focused conversation about an idea by selecting it (eg a scenario, strategy or prototype concept), as well as to select and generate variations of a concept. First, the user selects an idea (either explicitly with a checkbox or implicitly by clicking a link):
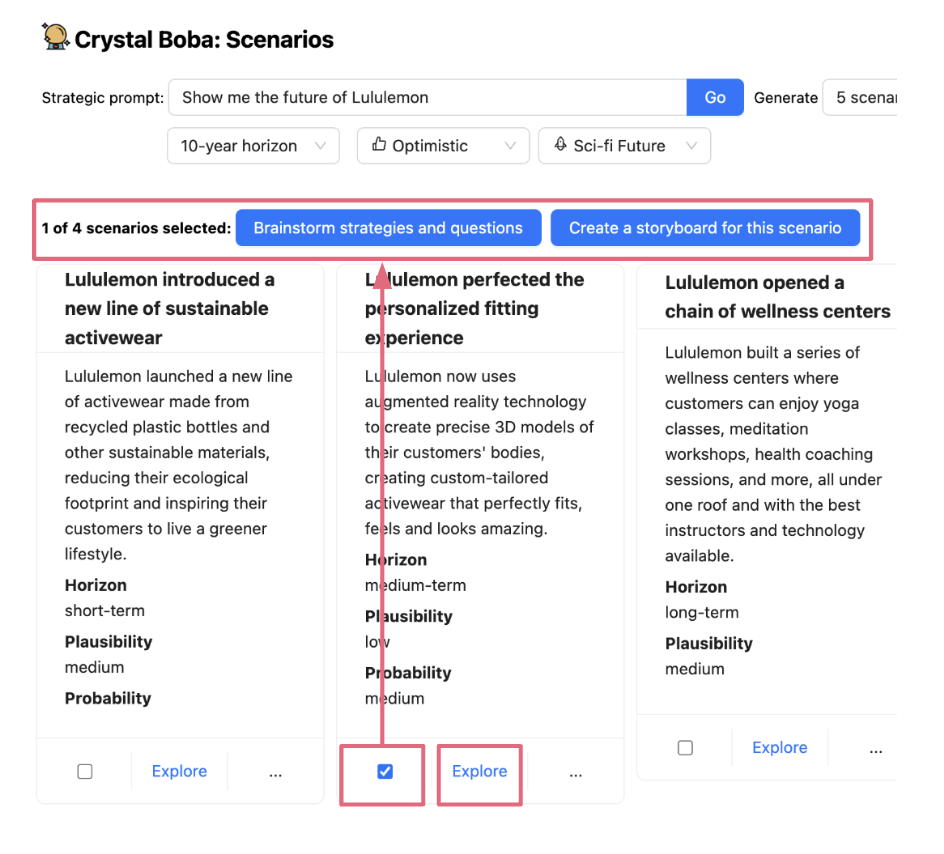
Then, when the user performs an action on the selection, the selected item(s) are carried over as context into the new task, for example as scenario subprompts for strategy generation when the user clicks “Brainstorm strategies and questions for this scenario”, or as context for a natural language conversation when the user clicks Explore:
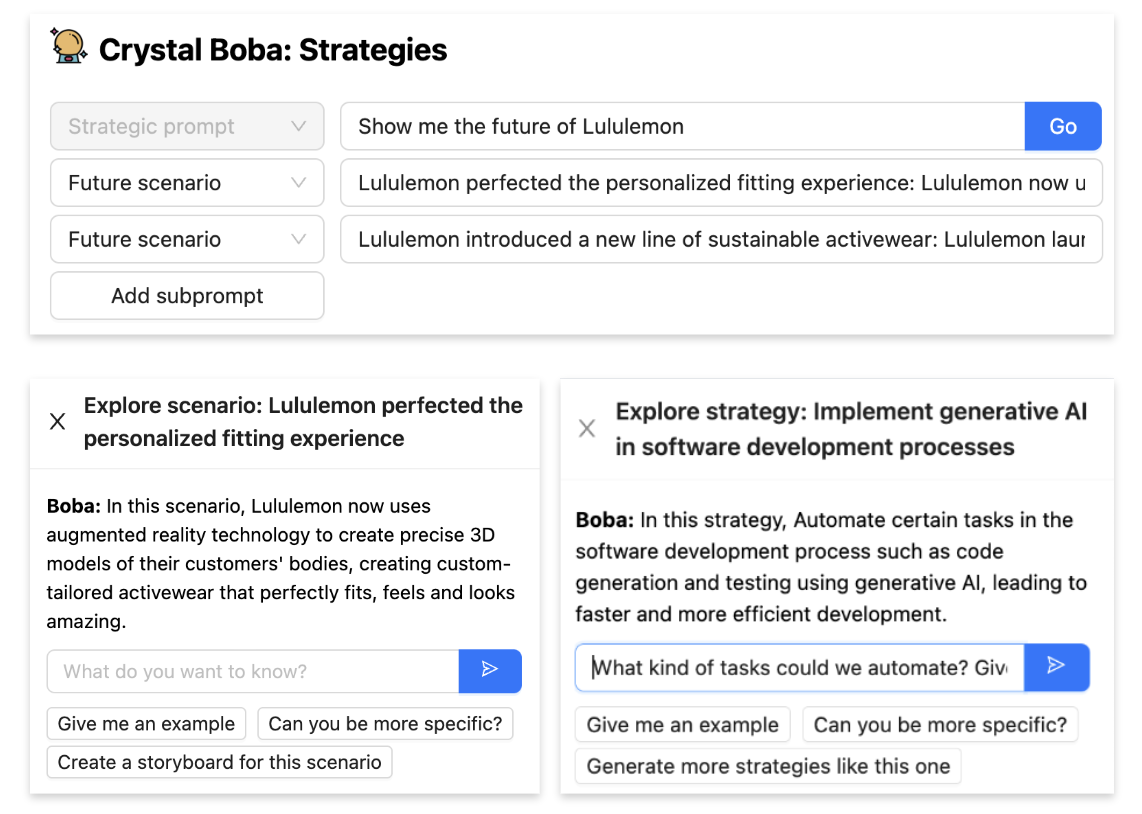
Depending on the nature and length of the context you wish to establish for a segment of conversation/interaction, implementing Select and Carry Context can be anywhere from very easy to very difficult. When the context is brief and can fit into a single LLM context window (the maximum size of a prompt that the LLM supports), we can implement it through prompt engineering alone. For example, in Boba, as shown above, you can click “Explore” on an idea and have a conversation with Boba about that idea. The way we implement this in the backend is to create a multi-message chat conversation:
const chatPrompt = ChatPromptTemplate.fromPromptMessages([
HumanMessagePromptTemplate.fromTemplate(contextPrompt),
HumanMessagePromptTemplate.fromTemplate("{input}"),
]);
const formattedPrompt = await chatPrompt.formatPromptValue({
input: input
})
Another technique of implementing Select and Carry Context is to do so within the prompt by providing the context within tag delimiters, as shown below. In this case, the user has selected multiple scenarios and wants to generate strategies for those scenarios (a technique often used in scenario building and stress testing of ideas). The context we want to carry into the strategy generation is collection of selected scenarios:
Your questions and strategies must be specific to realizing the following
potential future scenarios (if any)
<scenarios>
{scenarios_subprompt}
</scenarios>
However, when your context outgrows an LLM’s context window, or if you need to provide a more sophisticated chain of past interactions, you may have to resort to using external short-term memory, which typically involves using a vector store (in-memory or external). We’ll give an example of how to do something similar in Embedded External Knowledge.
If you want to learn more about the effective use of selection and context in generative applications, we highly recommend a talk given by Linus Lee, of Notion, at the LLMs in Production conference: “Generative Experiences Beyond Chat”.
Contextual Conversation
Allow direct conversation with the LLM within a context.
This is a special case of Select and Carry Context. While we wanted Boba to break out of the chat window interaction model as much as possible, we found that it is still very useful to provide the user a “fallback” channel to converse directly with the LLM. This allows us to provide a conversational experience for interactions we don’t support in the UI, and support cases when having a textual natural language conversation does make the most sense for the user.
In the example below, the user is chatting with Boba about a concept for personalized highlight reels provided by Rogers Sportsnet. The complete context is mentioned as a chat message (“In this concept, Discover a world of sports you love...”), and the user has asked Boba to create a user journey for the concept. The response from the LLM is formatted and rendered as Markdown:
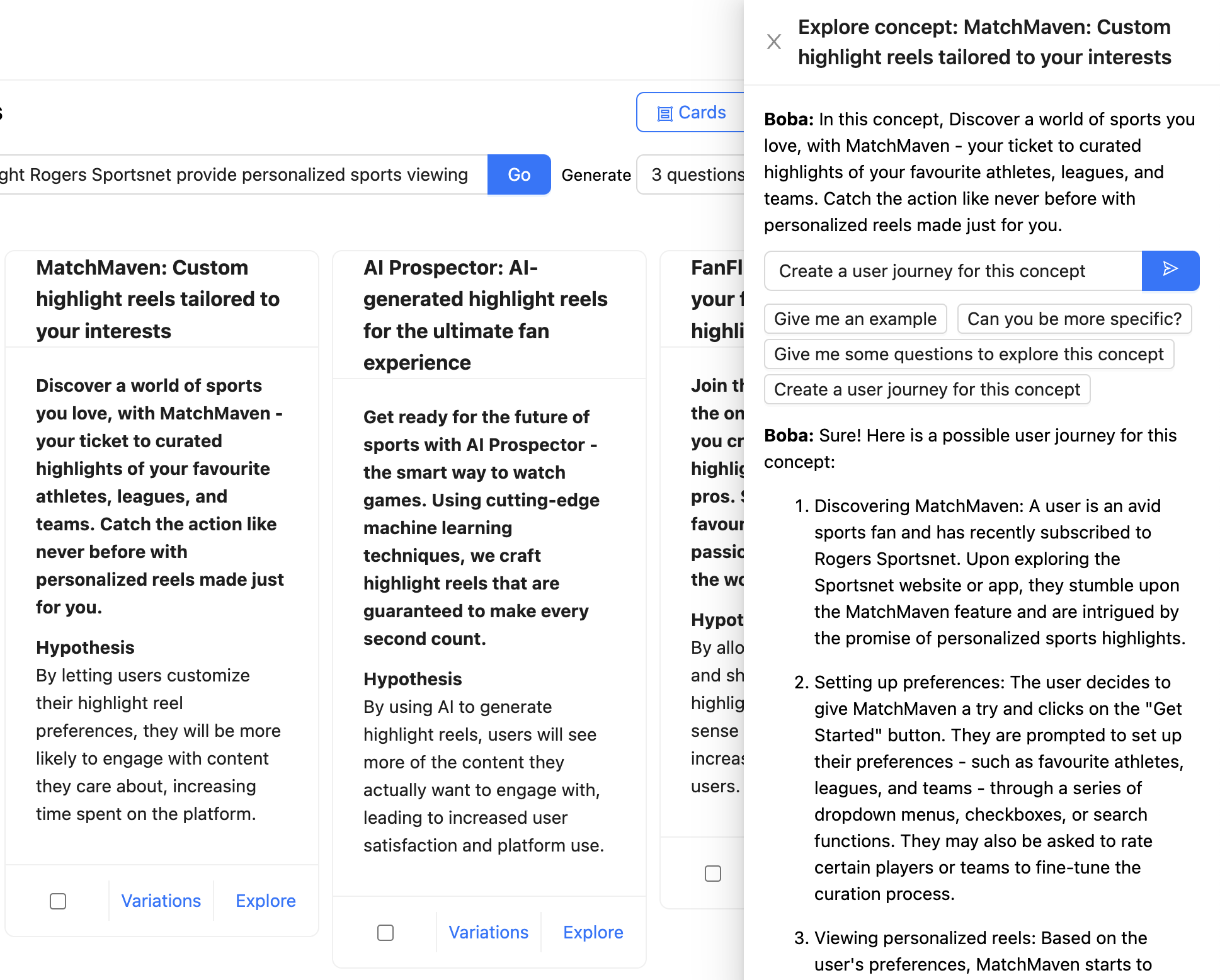
When designing generative co-pilot experiences, we highly recommend supporting contextual conversations with your application. Make sure to offer examples of useful messages the user can send to your application so they know what kind of conversations they can engage in. In the case of Boba, as shown in the screenshot above, those examples are offered as message templates under the input box, such as “Can you be more specific?”
Out-Loud Thinking
Tell LLM to generate intermediate results while answering
While LLMs don’t actually “think”, it’s worth thinking metaphorically about a phrase by Andrei Karpathy of OpenAI: “LLMs ‘think’ in tokens.” What he means by this is that GPTs tend to make more reasoning errors when trying to answer a question right away, versus when you give them more time (i.e. more tokens) to “think”. In building Boba, we found that using Chain of Thought (CoT) prompting, or more specifically, asking for a chain of reasoning before an answer, helped the LLM to reason its way toward higher-quality and more relevant responses.
In some parts of Boba, like strategy and concept generation, we ask the LLM to generate a set of questions that expand on the user’s input prompt before generating the ideas (strategies and concepts in this case).
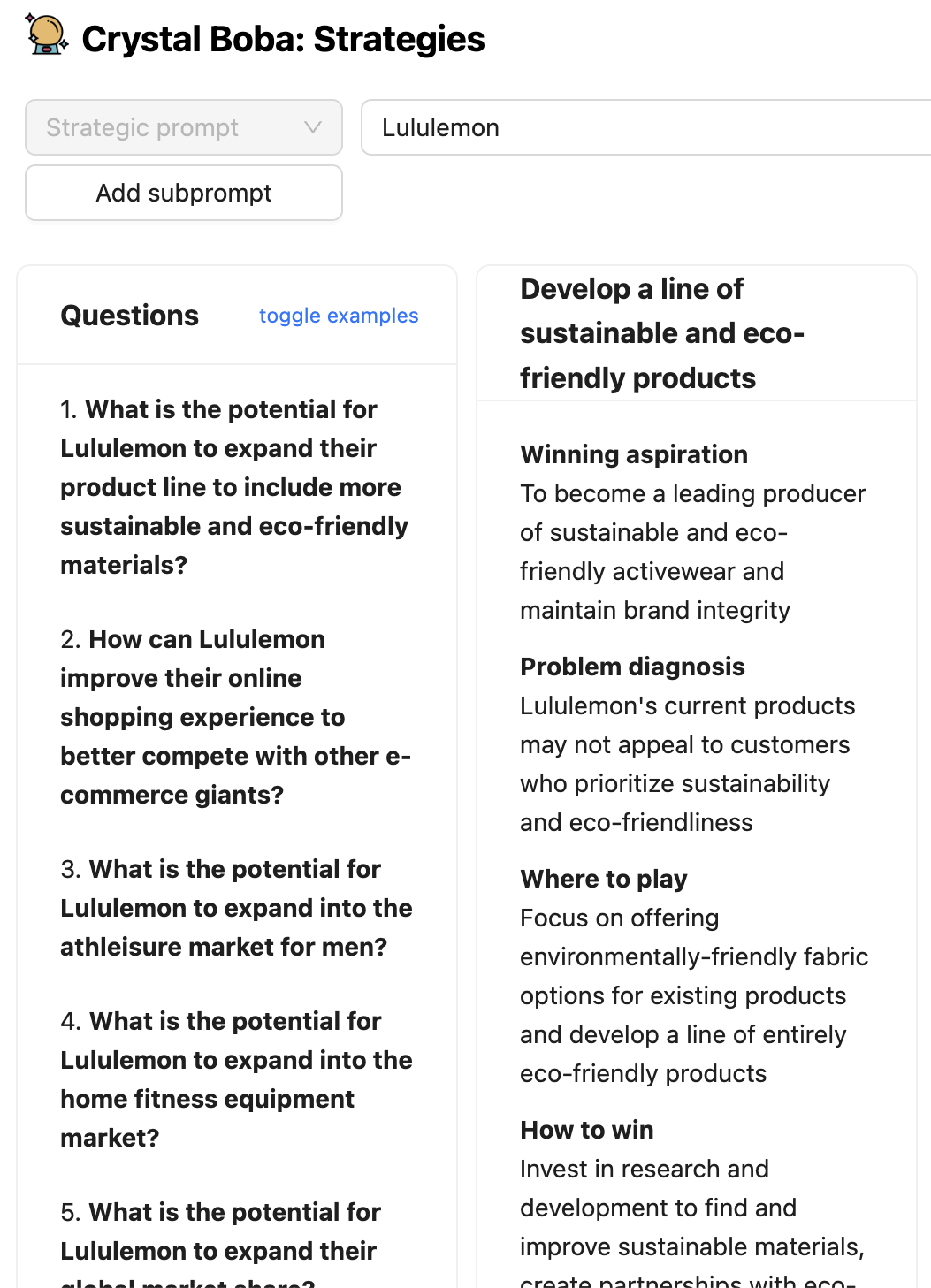
While we display the questions generated by the LLM, an equally effective variant of this pattern is to implement an internal monologue that the user is not exposed to. In this case, we would ask the LLM to think through their response and put that inner monologue into a separate part of the response, that we can parse out and ignore in the results we show to the user. A more elaborate description of this pattern can be found in OpenAI’s GPT Best Practices Guide, in the section Give GPTs time to “think”
As a user experience pattern for generative applications, we found it helpful to share the reasoning process with the user, wherever appropriate, so that the user has additional context to iterate on the next action or prompt. For example, in Boba, knowing the kinds of questions that Boba thought of gives the user more ideas about divergent areas to explore, or not to explore. It also allows the user to ask Boba to exclude certain classes of ideas in the next iteration. If you do go down this path, we recommend creating a UI affordance for hiding a monologue or chain of thought, such as Boba’s feature to toggle examples shown above.
Iterative Response
Provide affordances for the user to have a back-and-forth interaction with the co-pilot
LLMs are bound to either misunderstand the user’s intent or simply generate responses that don’t meet the user’s expectations. Hence, so is your generative application. One of the most powerful capabilities that distinguishes ChatGPT from traditional chatbots is the ability to flexibly iterate on and refine the direction of the conversation, and hence improve the quality and relevance of the responses generated.
Similarly, we believe that the quality of a generative co-pilot experience depends on the ability of a user to have a fluid back-and-forth interaction with the co-pilot. This is what we call the Iterate on Response pattern. This can involve several approaches:
- Correcting the original input provided to the application/LLM
- Refining a part of the co-pilot’s response to the user
- Providing feedback to nudge the application in a different direction
One example of where we’ve implemented Iterative Response in Boba is in Storyboarding. Given a prompt (either brief or elaborate), Boba can generate a visual storyboard, which includes multiple scenes, with each scene having a narrative script and an image generated with Stable Diffusion. For example, below is a partial storyboard describing the experience of a “Hotel of the Future”:
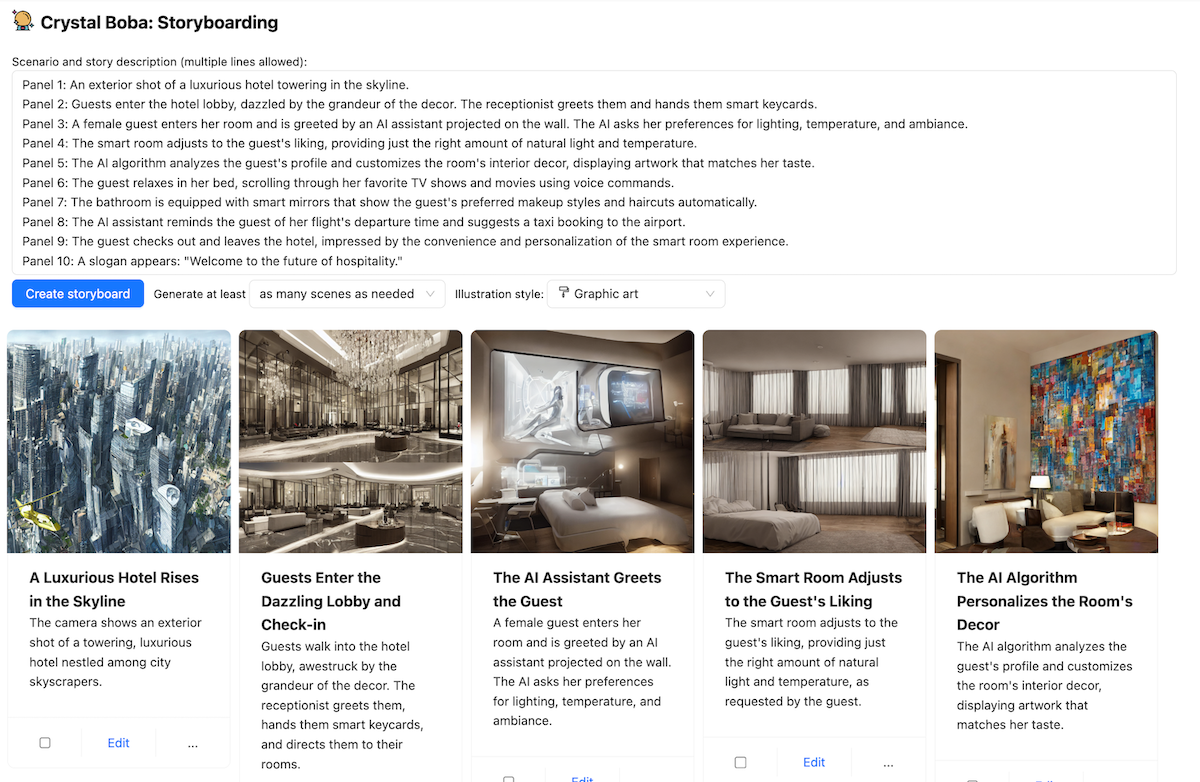
Since Boba uses the LLM to generate the Stable Diffusion prompt, we don’t know how good the images will turn out–so it’s a bit of a hit or miss with this feature. To compensate for this, we decided to provide the user the ability to iterate on the image prompt so that they can refine the image for a given scene. The user would do this by simply clicking on the image, updating the Stable Diffusion prompt, and pressing Done, upon which Boba would generate a new image with the updated prompt, while preserving the rest of the storyboard:
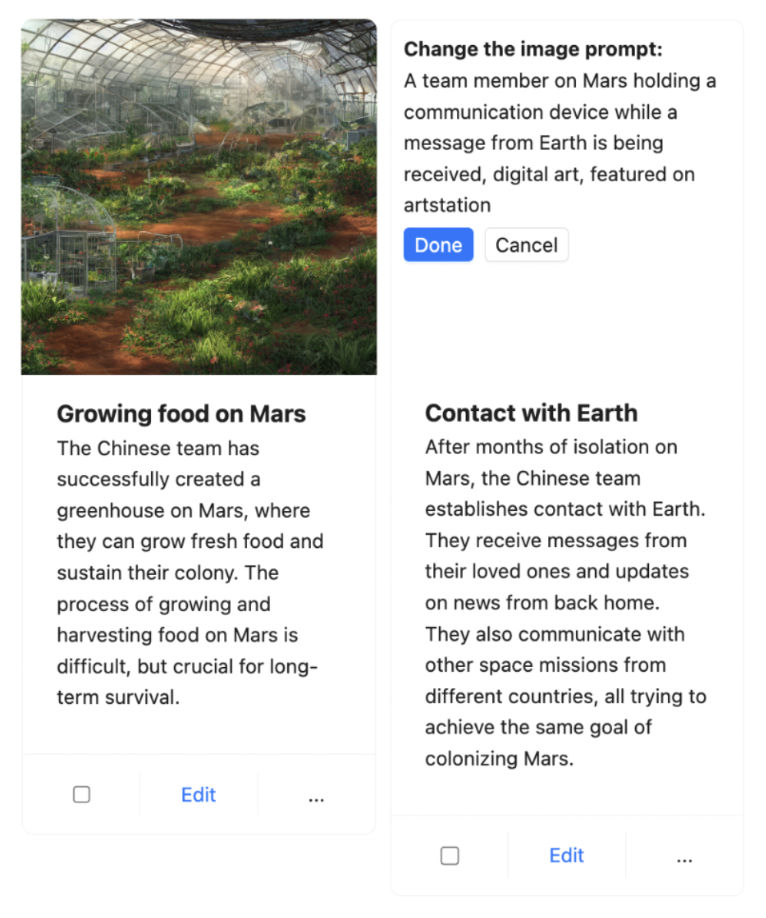
Another example Iterative Response that we are currently working on is a feature for the user to provide feedback to Boba on the quality of ideas generated, which would be a combination of Select and Carry Context and Iterative Response. One approach would be to give a thumbs up or thumbs down on an idea, and letting Boba incorporate that feedback into a new or next set of recommendations. Another approach would be to provide conversational feedback in the form of natural language. Either way, we would like to do this in a style that supports reinforcement learning (the ideas get better as you provide more feedback). A good example of this would be Github Copilot, which demotes code suggestions that have been ignored by the user in its ranking of next best code suggestions.
We believe that this is one of the most important, albeit generically-framed, patterns to implementing effective generative experiences. The challenging part is incorporating the context of the feedback into subsequent responses, which will often require implementing short-term or long-term memory in your application because of the limited size of context windows.
Embedded External Knowledge
Combine LLM with other information sources to access data beyond the LLM's training set
As alluded to earlier in this article, oftentimes your generative applications will need the LLM to incorporate external tools (such as an API call) or external memory (short-term or long-term). We ran into this scenario when we were implementing the Research feature in Boba, which allows users to answer qualitative research questions based on publicly available information on the web, for example “How is the hotel industry using generative AI today?”:
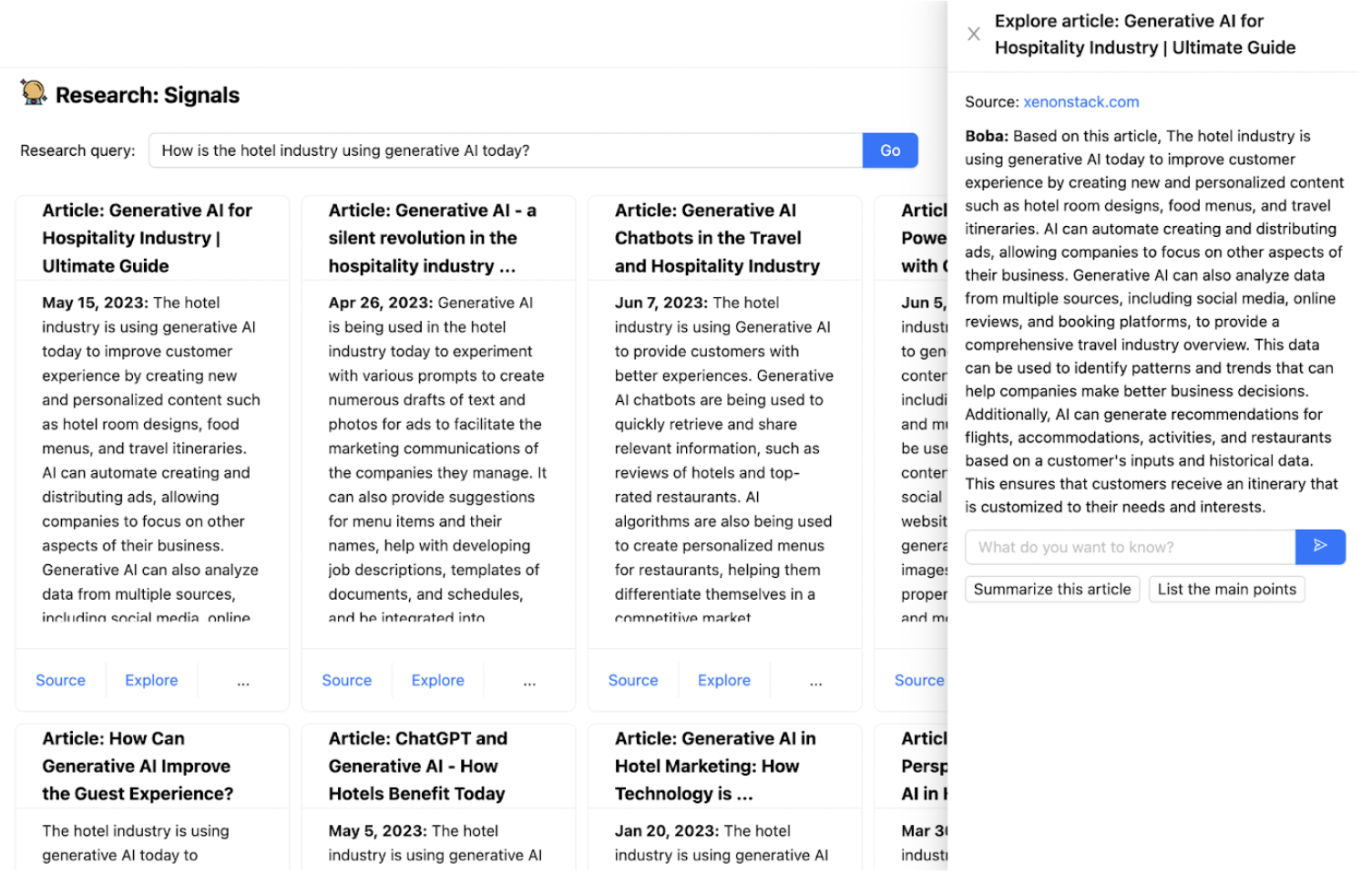
To implement this, we had to “equip” the LLM with Google as an external web search tool and give the LLM the ability to read potentially long articles that may not fit into the context window of a prompt. We also wanted Boba to be able to chat with the user about any relevant articles the user finds, which required implementing a form of short-term memory. Lastly, we wanted to provide the user with proper links and references that were used to answer the user’s research question.
The way we implemented this in Boba is as follows:
- Use a Google SERP API to perform the web search based on the user’s query and get the top 10 articles (search results)
- Read the full content of each article using the Extract API
- Save the content of each article in short-term memory, specifically an in-memory vector store. The embeddings for the vector store are generated using the OpenAI API, and based on chunks of each article (versus embedding the entire article itself).
- Generate an embedding of the user’s search query
- Query the vector store using the embedding of the search query
- Prompt the LLM to answer the user’s original query in natural language, while prefixing the results of the vector store query as context into the LLM prompt.
This may sound like a lot of steps, but this is where using a tool like Langchain can speed up your process. Specifically, Langchain has an end-to-end chain called VectorDBQAChain, and using that to perform the question-answering took only a few lines of code in Boba:
const researchArticle = async (article, prompt) => {
const model = new OpenAI({});
const text = article.text;
const textSplitter = new RecursiveCharacterTextSplitter({ chunkSize: 1000 });
const docs = await textSplitter.createDocuments([text]);
const vectorStore = await HNSWLib.fromDocuments(docs, new OpenAIEmbeddings());
const chain = VectorDBQAChain.fromLLM(model, vectorStore);
const res = await chain.call({
input_documents: docs,
query: prompt + ". Be detailed in your response.",
});
return { research_answer: res.text };
};
The article text contains the entire content of the article, which may not fit within a single prompt. So we perform the steps described above. As you can see, we used an in-memory vector store called HNSWLib (Hierarchical Navigable Small World). HNSW graphs are among the top-performing indexes for vector similarity search. However, for larger scale use cases and/or long-term memory, we recommend using an external vector DB like Pinecone or Weaviate.
We also could have further streamlined our workflow by using Langchain’s external tools API to perform the Google search, but we decided against it because it offloaded too much decision making to Langchain, and we were getting mixed, slow and harder-to-parse results. Another approach to implementing external tools is to use Open AI’s recently released Function Calling API, which we mentioned earlier in this article.
To summarize, we combined two distinct techniques to implement Embedded External Knowledge:
- Use External Tool: Search and read articles using Google SERP and Extract APIs
- Use External Memory: Short-term memory using an in-memory vector store (HNSWLib)
Future plans and patterns
So far, we’ve only scratched the surface with the prototype of Boba and what a generative co-pilot for product strategy and generative ideation could entail. There is yet a lot to learn and share about the art of building LLM-powered generative co-pilot applications, and we hope to do so in the months to come. It’s an exciting time to work on this new class of applications and experiences, and we believe many of the principles, patterns and practices are yet to be discovered!
Significant Revisions
29 June 2023: First published