
Domain Event
Captures the memory of something interesting which affects the domain


12 December 2005
This is part of the Further Enterprise Application Architecture development writing that I was doing in the mid 2000’s. Sadly too many other things have claimed my attention since, so I haven’t had time to work on them further, nor do I see much time in the foreseeable future. As such this material is very much in draft form and I won’t be doing any corrections or updates until I’m able to find time to work on it again.
I go to Babur's for a meal on Tuesday, and pay by credit card. This might be modeled as an event, whose event type is 'make purchase', whose subject is my credit card, and whose occurred date is Tuesday. If Babur's uses an old manual system and doesn't transmit the transaction until Friday, the noticed date would be Friday.
Things happen. Not all of them are interesting, some may be worth recording but don't provoke a reaction. The most interesting ones cause a reaction. Many systems need to react to interesting events. Often you need to know why a system reacts in the way it did.
By funneling inputs to a system into streams of Domain Event you can keep a record of all the inputs to a system. This helps you organize your processing logic, and also allows you to keep an audit log of the inputs to the system.
How it Works
The essence of a Domain Event is that you use it to capture things that can trigger a change to the state of the application you are developing. These event objects are then processed to cause changes to the system, and stored to provide an Audit Log.
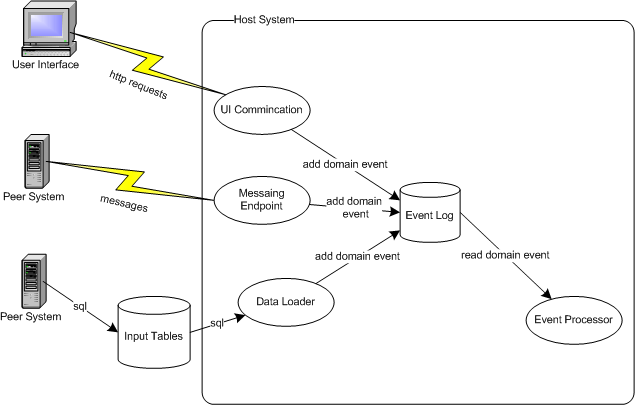
Figure 1: Events funnel inputs into a single source.
Figure 1 helps illustrate the point. Here we have a system with inputs from a user interface, messaging system, and some direct manipulation of database tables. In order to resolve these to Domain Event we have components that interact with each of these input streams and convert the inputs into a stream of Domain Event which are stored in a persistent log. An event processor then reads the events from the log and processes them triggering our application to do whatever it's supposed to do.
{kind=link}
In this stream the first input layer of the system takes no action to the stimulus other than to create and log an event. The second layer can then be ignorant of the actual input source, it just reacts to the event and processes it.
For this example I've shown just the one event log. In practice it often makes sense to separate the logs if the events have different response requirements. A user interface will typically want a much faster response time than many remote messaging systems, so it makes sense to put user interface traffic into a different log and use a separate processor for them.
The diagram implies an asynchronous pipes and filters style of interaction, but this isn't an essential part of the approach. Indeed a common approach, particularly with user interface stimuli, is to have the UI handler invoke the event processor directly in a synchronous interaction.
Each Domain Event captures information from the external stimulus. Since this is logged and we want to use the log as an audit trail, it's important that this source data is immutable. That is once you've created the event object this source data cannot be changed. However there is also another kind of data on the event that records what a system has done with it - I call this the processing data. I characterize the data on a Domain Event as immutable source data that captures what the event is about and mutable processing data that records what the system does in response to it. Source data on a credit card charge would include how much the charge was for, who the vendor was, etc. Processing data might include which statement it appeared on. If your platform has particular support for immutable objects it may be worth splitting the event into two objects to take advantage of this.
Although the source data can never change, it may be that the system needs to handle a change - typically because the original event was incorrect. You can handle this by receiving this change as a separate Retroactive Event. The processor then handles the retroactive event to correct the consequences of the earlier erroneous event. Often this processing can be done at a very generic level.
A third, but only occasional, category of event data is cached data from derivations from other data on the event stream. In these cases the event processor summarizes information from past events while processing the current event and adds that summarized data to the current event to speed up future processing. Like any cache, it's important to signal the fact that this data is free to be removed and recalculated should any adjustments occur.
Different events occur for different reasons, so it's common to use different types of events. The event processor will then use the event type as part of its dispatch mechanism. The type of event can be represented by using subtypes of events, or a separate event type object, or a mixture of both.
It's quite common that different types of event carry different data, so using subtypes of event for the event types fits in well with that. The problem with subtypes is that this leads to a proliferation of types, that is particularly frustrating if much of the data is the same. A hybrid approach uses subtypes to handle different data and event type objects to signal dispatching.
Events are about something happening at a point in time, so it's natural for events to contain time information. When doing this it's important to consider two Time Point that could be stored with the event: the time the event occurred in the world and the time the event was noticed . These Time Points correspond to the notions of actual and record time.
Of course you don't always need both Time Points, but you should always consider whether you need both. The danger is picking one Time Point, and not being clear which Time Point you picked, either at the time or later. So I also suggest you name the Time Point clearly to indicate which one it is.
It's possible you may need multiple record Time Points to record when the event was noticed by various different systems.
When to Use It
Capturing system stimuli through Domain Event is a significant decision. It imposes a distinct architectural style on an application and a programming model that will often seem awkward - at least initially. At this point it's not clear whether this approach actually is any more effort once you've got used to it.
Despite its unusual nature, I see some significant benefits for using this approach.
The Audit Log of events provides a full record that is valuable both for audit and debugging purposes. If the system gets into a strange state you have a full log of the inputs that got it there. By storing the events that were actually processed you decrease the chances of neglecting to write important information to the Audit Log.
Clear event streams make it easier for other system to replace some or all of an application in the future by adding a Message Router to divert events to a new system. Although it isn't fashionable to design a system in a way that facilitates its eventual demise, the sheer frequency of system replacement projects should mean we ought to pay more attention to it.
Domain Event is particularly important as a necessary pattern for Event Sourcing, which organizes a system so that all updates are made through Domain Event.