The Dependency Inversion Principle (DIP) has been around since the early '90s, even so it seems easy to
forget in the middle of solving a problem. After a few definitions, I'll present a number of
applications of the DIP I've personally used on real projects so you'll have some examples from which to
form your own conclusions.
Brett is a generalist striving to get the basics right. He's always on the lookout for new
interpretations of simple ideas. He currently works for Thoughtworks as a Principal consultant and
lately has been helping a team with an agile transition while assisting in PM, PO, QA, and BA roles as
well as working with the C level in the organization, but is recently switching back to a plain old
tech. lead.
My original introduction to the
Dependency Inversion Principle
came from Robert (Uncle Bob) Martin around 1994. It, along with most of the
SOLID principles, is
simple to state but deep in its application. What follows are some recent applications I've used on real
projects; everything I discuss is in production from June 2012 and as of mid 2013 is still in
production. Some of these go further back in time, but keep coming back, which is a reminder to me that
the basics remain important.
Synopsis of the DIP
There are many ways to express the dependency inversion principle:
Abstractions should not depend on details
Code should depend on things that are at the same or higher level of abstraction
High level policy should not depend on low level details
Capture low-level dependencies in domain-relevant abstractions
The common thread throughout all of these is about the view from one part of your system to anther;
strive to have dependencies move towards higher-level (closer to your domain) abstractions.
Why care about dependencies?
A dependency is a risk. For example, if my system requires a Java Runtime Environment (JRE)
to be installed and one is not installed, my system will not work. My system also probably requires
some kind of Operating System. If users access the system via the web, it requires the user to have
a browser. Some of these dependencies you control or limit, others you can ignore. For example,
In the case of the JRE requirement, you could make sure the deployment environment has
an appropriate version of the JRE installed. Alternatively, if the environment is fixed, you
might adjust the code to match the JRE. You could control the environment using a tool like
Puppet to build up an environment from a simpler, known starting image. In any case, while
the consequence is severe, it's well understood with several options to mitigate it. (My
personal preference leans towards the
CD
end of the spectrum.)
When your system uses the String class, you probably do not invert that dependency. You
could, for example if you think of String as a primitive (strictly not, but close enough),
then manipulating a number of Strings starts to resemble
Primitive Obsession. If you
introduce a type around the Strings, and add methods that make sense to your use of the
those Strings, rather than simply exposing String methods, that starts to look like a kind
of Dependency Inversion, so long as the resulting type is closer to your domain than a
String.
In the case of browsers, if you want a modern experience it will be hard to support all
browsers. You can try to allow all browsers and versions, limit support to relatively modern
browsers or introduce feature degradation. This kind of dependency is complex and probably
requires a multi-faceted approach to solve.
Dependencies represent risk. Handling that risk has some cost. Through experience, trial and error,
or the collective wisdom of a team, you choose to explicitly mitigate that risk, or not.
In structured analysis and design, we start with a high-level problem
and break it up into smaller parts. For any of those smaller parts that are still “too big”, we
continue breaking them up. The high-level concept / requirement / problem is broken up into
smaller and smaller parts. The high-level design is described in terms of these smaller and
smaller parts and therefore it directly depends on the smaller, and more detailed, parts. This
is also known as top-down design. Consider this problem description (somewhat idealized and
cleansed, but otherwise something found in the wild):
Report Energy Savings
Gather Data
Open Connection
Execute Sql
Translate ResultSet
Calculate Baseline
Determine Baseline Group
Project Time-sequence Data
Calculate Across Date Range
Product Report
Determine Non-Baseline group
Project Time-sequence Data
Calculate Across Data range
Calculate Delta from Baseline
Format Results
The business requirement of reporting on energy savings depends on gathering data, which depends on
executing Sql. Notice that the dependencies follow how the problem is decomposed. The more detailed
something is, the more likely it will change. We have a high-level idea depending on something that
is likely to change. Additionally, the steps are extremely sensitive to changes at the higher
levels, which is a problem since requirements tend to change. We want to invert dependencies
relative to that kind of decomposition.
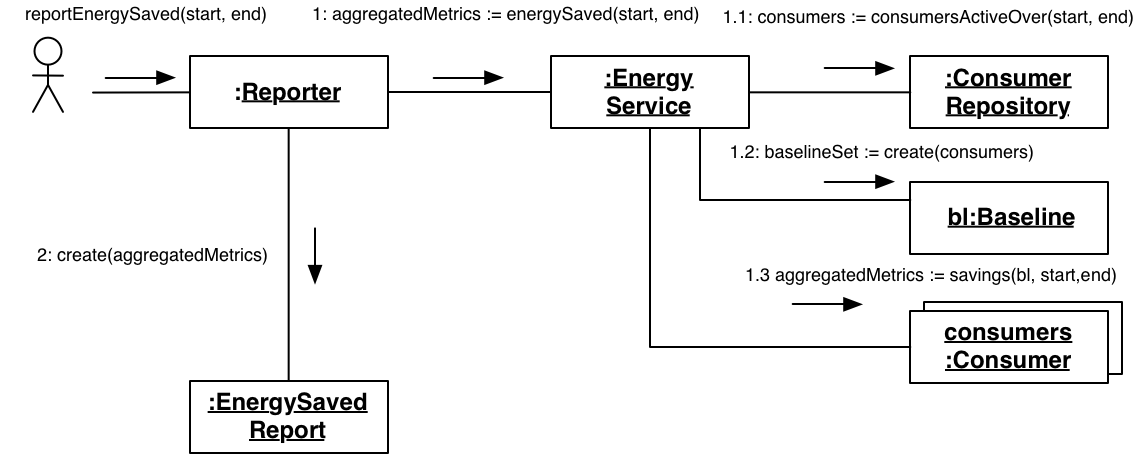
Contrast that to bottom-up composition. You could find the logical concepts that exist in the domain
and combine them to accomplish the high-level goal. For example, we have a number of things using
power, we'll call those Consumers. We don't know much about them, so we'll get to them via a
Consumer Repository. We have
something called a Baseline in our domain, something needs to determine that. Consumers can
calculate their Energy usage and then we can compare the energy used by the Baseline versus all of
the Consumers to determine Energy Savings:
Figure 1: Bottoms Up
While the work we do could initially be the same, in this re-envisioning there's an opportunity, with
a little more work, to introduce different ways to accomplish the details:
Switch out the repository for a different storage mechanism, there's no mention of SQL in
its interface so we can use an in-memory solution, a NoSql solution or a RESTful service.
Instead of constructing a baseline, use an
Abstract factory.
That will provide support for multiple kinds of baseline calculations, which actually
reflects the reality of a particular domain.
As you read this you might notice that there's some notion of the
Open Closed Principle
in all of this. It's certainly related. Initially, break your problem into logical blocks suggested
by your domain. As your system grows, use these blocks or extend them in some way to accommodate
additional scenarios.
What Does That all Mean?
Where the DIP refers to abstractions, I've noticed many people confuse abstraction with:
An interface
An abstract base class
Something given as a constraint (e.g., external system architecture)
Something called a requirement, which is stated as a solution
In fact, any of these can be misleading:
An interface — Have a look at java.sql.Connection, compare your business domain to methods
like
getAutoCommit(),
createStatement()
andgetHoldability(). While these might be reasonable for a database connection,
how do these relate to something a user of your system wants to do? The connection is
tenuous at best.
An abstract base class — An abstract base class has the same problems as an interface. If
the methods make sense to your domain, it might be OK. If the methods make sense to a
software library, maybe not. For example, consider java.util.AbstractList. Imagine a domain
with an ever-increasing ordered listing of historical events. In this hypothetical domain,
it never makes sense to
remove()
an item from the historical record. The List abstraction, because it solves a general
problem and not your problem, offers at least this one feature that does not make sense for
your domain. You can subclass AbstractList (or some other List class), but doing so still
exposes a method (probably several) that does not make sense for your use of that class. As
soon as you give in and allow clients to see unnecessary methods, you probably violate both
the DIP and the
Liskov Substitution
Principle.
A constraint/requirement — When we are given work to do, does that work provide the
motivation and goals or does it talk about how to solve the problem? Does your
requirement talk about having to use message oriented middle-ware for integration, or which
database fields to update to finish the work? Even if you are given a description of the
goals for an
actor, do those goals simply
restate the current as-is process, where you could build a system that obviated the need
for those processed in the first place?
Dependency Injection is about how one object knows about another, dependent
object. For example, in Monopoly a player rolls a pair of dice. Imagine a software
player that needs to send the
roll()
message to a software pair of dice. How does the player object get a reference to the
dice object? Imagine the game tells the player to
takeATurn(:Dice)
and gives the payer the dice. The game
telling a player to take a turn and passing the dice is an example of method level
dependency injection. Imagine a system where the Player class expresses a need for Dice
instead and it gets auto-wired by some kind of so-called IoC container like Spring. A
recent example of this is in the system I'm working as of Q1, 2013. It involves the use
of Spring profiles. We have 4 named profiles: demo, test, qa, prod. The default profile
is demo, which brings the system up configured with 10 simulated devices and certain
test points enabled. The test profile brings the system up with no simulated devices and
the test points enabled. Both qa and prod bring the system up such that the system
connects to real devices over a cellular network and test points are not loaded, meaning
if a production component attempts to use the test point, the system will fail to start.
One more example comes from an application that involved mixing Java and C++. If the
system is started via a JVM, then it is configured to simulate the C++ layer. If it
is instead started via C++, which then starts the JVM, then the system is configured
to hit the C++ layer. These are all kinds of dependency injection.
Inversion of Control
Inversion of control is about who initiates messages. Does your code call
into a framework, or does it plug something into a framework, and then the framework
calls back? This is also referred to as
Hollywood's Law;
don't call me, I'll call you. For example, when you create a ButtonListener for Swing,
you provide an implementation of an interface. When the button is pressed, Swing notices
that and calls back into the code you provided. Imagine the Monopoly system created with
a number of players. The game orchestrates interaction between players. When it's time
to have a player take a turn, the game might ask the player if it has any pre-movement
actions such as selling houses or hotels, then the game will move the player based on
the roll of the dice (in the real world, a physical player rolls dice and moves his or
her token, but that's an artifact of the board game not being a computer - that is, it's
a phenomenological description of what's going on rather than an ontological
description). Notice that the game knows when a player can make decisions and prompts
the player accordingly, rather than the player making the decision. As a final example,
a Spring Message bean or a JEE Message Bean is an implementation of an interface
registered with the container. When a message arrives on a Queue, the container calls
into the bean to process the message, the container will even remove the message or not
based on the response of the bean.
Dependency Inversion Principle
Dependence Inversion is about the shape of the object upon which the code
depends. How does DIP relate to IoC and DI? Consider what happens if you use DI to
inject a low-abstraction dependency? For example, I could use DI to inject a JDBC
connection into a Monopoly game so it could use a SQL statement to read the Monopoly
board from DB2. While this is an example of DI, it is an example of injecting a
(probably) problematic dependency as it exists at an abstraction level significantly
lower than the domain of my problem. In the case of Monopoly, it was created several
decades before SQL databases existed, so to couple it to a SQL database introduces an
unnecessary, incidental dependency. A better thing to inject into Monopoly is a Board
Repository. The interface of such a repository is appropriate to the domain of Monopoly
rather than described in terms of a SQL connection. As IoC is about who initiates a
calling sequence, a poorly designed callback interface might force low-level details
(framework) details into code you write to plug into a framework. If that's the case,
try to keep most of the business stuff out of the callback method and in a POJO instead.
DI is about how one object acquires a dependency. When a dependency is provided externally, then
the system is using DI. IoC is about who initiates the call. If your code initiates a call, it is
not IoC, if the container/system/library calls back into code that you provided it, is it IoC.
DIP, on the other hand, is about the level of the abstraction in the messages sent from your code
to the thing it is calling. To be sure, using DI or IoC with DIP tends to be more expressive,
powerful and domain-aligned, but they are about different dimensions, or forces, in an overall
problem. DI is about wiring, IoC is about direction, and DIP is about shape.
What's coming up?
Armed with a definition of the Dependency Inversion Principle, it's time to move on to examples of
the DIP in the wild. What follows are several examples that all share a common thread; raising the
abstraction level of a dependency to be closer to the domain, as limited by the needs of the
system.
Flexibility is costly
A common thing I've done and I've seen is to make a class “easier” to use by adding more methods than
those required to solve the current problem. It might stem from “just in case” thinking, maybe it's
from a history of practices that lead to hard to change code base, which means putting stuff in
now is perceived as easier than adding it later if we need it. Unfortunately, more methods leads to more
ways in which to write incorrect code, more paths of execution that will need verification, more need
for discipline when using the “easier” interface, etc. The larger the surface area of a class, the more
likely it will be difficult to use that class correctly. In fact, the larger the surface area, the more
likely it becomes easier to use the class incorrectly than it is to use it correctly.
Which hammer should I use?
Consider logging. While logging isn't necessarily the best way to run DevOps, it seems to be a
heavily practiced way to do things. On the last several projects I've worked, logging eventually
became a problem. The problems were varied:
Too much
Not enough
Disagreement on the level at which something should be logged
Disagreement on which logging methods to use
Disagreement on which logging framework to use
Inconsistent use of the Logger class
Incorrect/inconsistent configuration of logging across all of the various open source
logging libraries being used across all of the open source projects used on the project
Multiple logging frameworks used by different open source projects in use
Inconsistent logging messages, making it hard to use the log
Insert your particular experiences here...
While this is not a comprehensive list, I'd be surprised if you've been on moderately sized project
and not had discussions on some of these subjects.
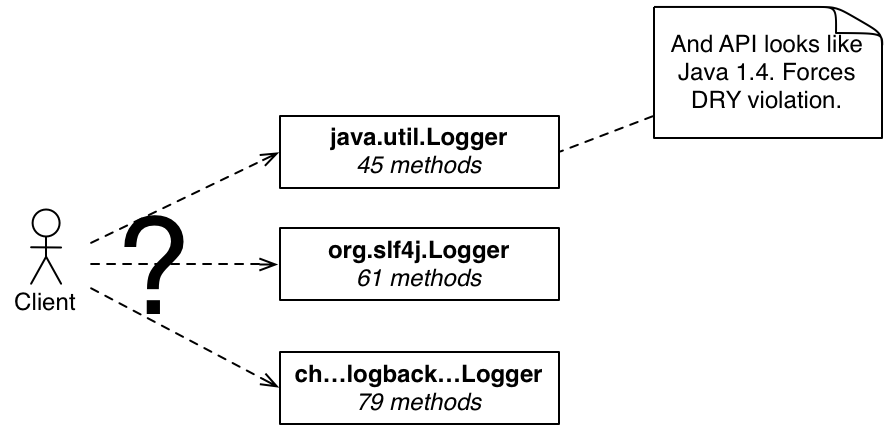
Too Many Methods
Have a look at Figure 2. This includes the Logger
built into the JDK and two other common open-source logging frameworks used by several open source
projects. The key thing to look at is the number of methods in each class.
Figure 2: Complexity of Existing Loggers
Let's consider just the
Logger
class from the JDK. You are a new developer working on a team. Hopefully you're not working alone,
but if you are, you are probably told to “look at the code base” and left to your own devices. When
you have a need to do some logging, which of the
log
methods do you use?
Figure 3: Which Log Method?
Is
log
even the correct method in the first place? You can search the code base for examples, do you take
the first example you find, or do you check to see if there are multiple ways?
This is a trivial example. It seems like nothing. Here's a good rule of thumb I live by
Nothing
+ Nothing + Nothing … eventually equals
something.
While this one thing really isn't a big deal, it won't be the only such thing on a project. Knowing
which method to use increases the burden on each developer just a little bit. It also increases the
difficulty of adding people to an ongoing project or into the team. This kind of detail, one which
seems trivial and unimportant, eventually falls into the bucket of
tribal knowledge.
While there may be advantages to team identity by having a healthy amount of
tribal knowledge,
things that lead to unnecessary inconsistency probably are not worth their cost.
Performance Considerations
Another argument for this, which becomes weaker at time goes on, is maybe a touch less obvious at
first. Consider the following code example:
This use of the logger seems straightforward but it has a problem: it performs String concatenation
regardless of whether the logger ultimately records messages at the INFO level. This leads to both
unnecessary work as well as additional garbage collection. To write this “correctly”, it should look
more like this:
If you use a modern API such as Slf4j, some of this is addressed in that there are methods to take
in a varying number of parameters and perform a check before concatenating. That's great, but then
we are back to having 50+ methods from which to chose. I cannot remember a project with more than
about 3 people where a discussion of consistent logger use hasn't come up, so clearly the number of
methods becomes an unnecessary (incidental) source of complexity.
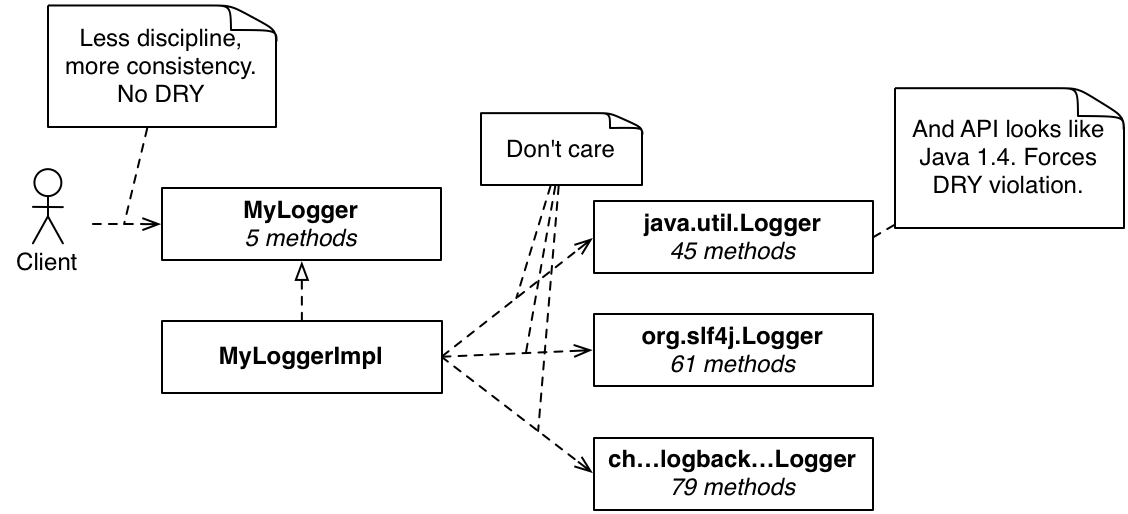
To address this, I'd like something that reduces the need for duplication and complexity. Here is one
thing I've done on a number of projects:
Figure 4: Narrowing the API
Using this new logger is now less likely to cause a problem:
This particular implementation makes use of “modern” Java 1.5 features:
public void info(String message, Object... args) {
if (logger.isInfoEnabled()) {
logger.info(String.format(message, args));
}
}
Martin Fowler calls this a
gateway. I
like that name as it evokes the idea of passing through as well as a separation of one thing from
another. Reducing flexibility leads to something that is a little less burdensome, so we can spend
our time thinking of the next bit of code to write test-first instead.
This solution introduces an additional method invocation, but the cost of a method invocation
compared to removing the chance of doing something incorrectly seems well worth it. On a modern
runtime, this method won't be invoked dynamically, it will be optimized to be called without a
virtual dispatch. Last time I measured method invocations (2008), I could get about 2,000,000,000
per second so this touch of overhead is negligible on a system where we're likely to be using a
logger. As an added bonus, if there is any configuration of logging, it can be managed in one place,
leading to DRYer code.
Conclusion
Flexibility in a logging library can easily lead to inconsistent use, longer code, or code
that does unnecessary work based on the state of logging in the system. From the author of the
framework's perspective, this makes sense. Logging conceptually might exist at an application level,
but the implementation of logging a framework needs to be flexible enough to support multiple JVM
versions, varied uses, and be everything to everybody. A particular system's use of logging can
choose to be more focused and consistent. Logging interfaces typically exists at a lower level of
abstraction than my system's need of a logger.
Solution abstracted, but that's not my problem
Is using a SQL database an essential part of your system? Is the actual requirement that information
entered into your system needs to be durable? How soon? To which users? In fact, these kinds of
questions used to be easier as they were not generally asked.
Background
Last century we worried about
ACID
transactions. Even then, we typically traded ACID, which is pessimistic, with something not quite as
strong such as last one wins or object versioning, which is optimistic. Now, as systems have gotten
bigger and we've moved to the cloud and
NoSql
solutions with eventual consistency, the landscape is even more varied.
How does this relate to Java? I worked on and deployed my first application with JDK 1.0.2. In those
days, if you wanted to work with a database, it looked something like this:
Figure 5: First there was the Database
Java punted on the issue and you had vendor lock-in. Or worse, you wrote your code to handle
“any” database - SQL or Object-Oriented.
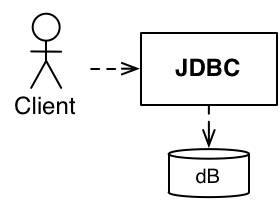
Java 1.1 gave us JDBC. This improved our use of a database so long as we could find a JDBC driver:
Figure 6: JDBC Gave us an interface of sorts
However, while this made it easier to use a database with less vendor lock-in, this abstraction let
things like transactions, prepared statements, and such bleed into your domain. JDBC raised the
level of abstraction, but the level was still too low.
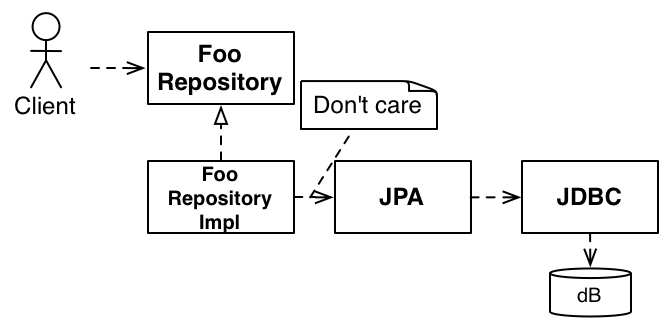
There were a number of improvements to JDBC, then JDO, ORMs, Hibernate and other ORMs and somewhat
recently JPA (I'm ignoring things like Spring Data, Hades, etc. because it doesn't significantly
change the situation). Something to notice is that we still have a bunch of arrows pointing from the
system to the database.
Figure 7: JPA gave us a standard ORM
Like the discussion on Logging interfaces, using any of these interfaces is probably still a
violation of the DIP. Assuming you are not writing a database, your business probably doesn't
need
a database, it probably needs some kind of durable information. The chances that
a general thing like a SQL database (or a NoSql database, or hierarchical, object-based, etc.)
exists at the same level as your business is low unless you are writing something direclty related
to databases.
Hide DB Behind Something Domain-related
Confusing
a
solution with the problem is a common mistake. Luckily, this is a well understood problem and you
might
already know a solution to it. A common one is to use a
Repository:
Figure 8: Give Domain what it wants to see
A repository is a gateway to a conceptual (maybe actual) potentially large collection of durable
objects. The interface should comprise methods that make sense to goals of a user in a domain, not
to a database. If it just so happens that behind the repository sits a database, then the Repository
will deal with mapping from the requests that make sense to the domain into something that makes
sense to the database. Make the implementation of the abstraction do the work once rather than all
consumers of a lower-level abstraction duplicating the effort.
The typical interface might include basic
CRUD
operations (assuming the domain calls for them) but then we'll add methods that make sense for the
needs of the system. That is, as we grow the system by adding new use cases, scenarios, user stories
or backlog items, we'll extend the interface so that it supports the current needs of the system. No
more, no less.
Consider a system that works with travel schedules for trains. There are a number of scheduled
journeys between stations. Over time new stations get built, others are closed for maintenance, and
the schedule of trains between stations changes due to changes in capacity, to match seasonal
demand, or to introduce specials in an attempt to lure new business. Train schedules are planned
well in advance and then added to the system for future activation. The system needs to periodically
find schedules that are no longer relevant, ones that are about to become active, and potential
conflicts such as overlapping schedules or gaps in schedules.
Figure 9: Operations that match what my
domain needs
Does this mean for a given system we will only have one Repository for a given domain concept? Maybe.
Maybe we'll have multiple based on considerations like the use of
Bounded
Contexts, or we might split a single Repository interface based on the
Interface Segregation
Principle. The important consideration from the DIP perspective is that the interface exists
at an appropriate abstraction level for the
current needs of the system.
What drives the current needs of the system? The use cases, user stories, scenarios, backlog items.
That is, who are your actors, and what do they need to do?
Conclusion
When we use JDBC, we use a bunch of interfaces. An interface is an abstraction. However, while using
some kind of abstraction often helps writing decent code, it's not sufficient. The abstraction
should be at a level that is appropriate for your domain. A general solution like JDBC doesn't try
to solve your problem, it tries to solve a general problem. This is similar to the Logging example
where there were too many methods. The features of JDBC address the full scale of all things you
might need to deal with when using a database. Typical domains don't care about all of those
problems, so a particular domain's consumption can be simplified to conform to its needs.
Don't take what is given
Up to this point, the examples have been about the level of the abstraction layer used to solve
some part of the system. This next example is no different, but in practice it seems to be
viewed differently. What happens when what you are given a solution hidden as a requirement?
Solution Provided
We'll start this next part with something that was given to a team I was on:
Figure 10: Given
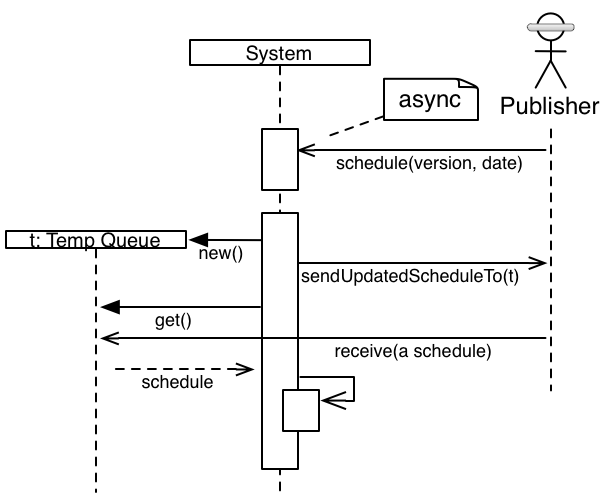
Here's a bit more detail:
Some external system broadcasts the fact that a schedule has been updated using an
asynchronous publish/subscribe queue.
At some point later, our system needs to pick up that notification and decide to act on it
or not. For example, it might already have the particular schedule as schedules might be
sent multiple times. In this particular example, the system cares about the schedule, so it
will ask for it.
The system creates a temporary queue, which is where the system will ask the publisher to
send the full schedule. It sends an asynchronous message to the original publisher (actually
it sends it to another queue, which is handled in the same process space).
The system waits on the temporary queue for the schedule to be delivered. It doesn't
block forever, it actually wakes up every so often just in case the system decides it is
shutting down in the middle of this overall process. It also gives up after some
property-driven number of minutes.
Eventually (happy path), the schedule arrives and the system receives the schedule. It does
some processing and then the system persists the schedule.
How did we tackle that?
At the time the team was working on this, we had shared pairing stations, and an open environment.
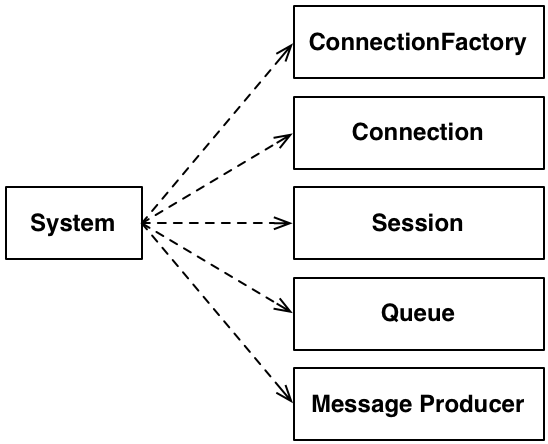
I heard the pair working on the problem and asked if they were depending directly on JMX
or if they were following the DIP (paraphrased, but true story). They had gone head first into
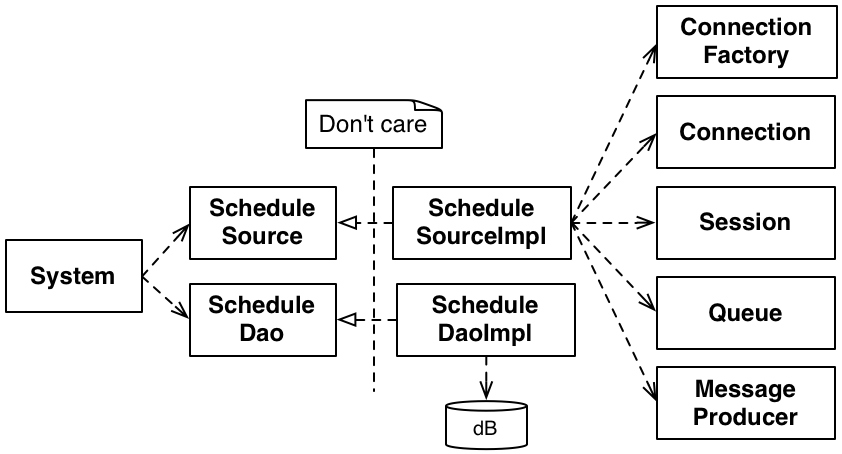
solving the problem, taking all of the givens as essential and this is what they were doing:
Figure 11: A direct use of a bunch of
interfaces
This is an easy, typical, and familiar response. There are so many details, it can be hard to
see what's really there. In this problem, is an asynchronous interaction essential or incidental?
In this particular case, the entire mechanism was a design decision imposed on us. While we had to
conform to it (it is a reasonable approach), we did not have to make its design an indelible part of
our design. I'd suggest that in most cases it is as well; a slightly weaker guideline is to assume
it is incidental unless shown to be otherwise.
Is there ever a case where something like asynchronicity is essential? Yes. Imagine a work flow where
a work item has one or more hand-offs. That is, when I'm done with it, then you take it over. I do
my work and then finish. While the last step for which I am responsible has completed, the overall
workflow for a given item has not. Conceptually, the interface I'd design for this kind of flow is
not going to look the same as one where all the work is done in one sitting by one person. However,
the driving force behind the design should be heavily influenced by the domain.
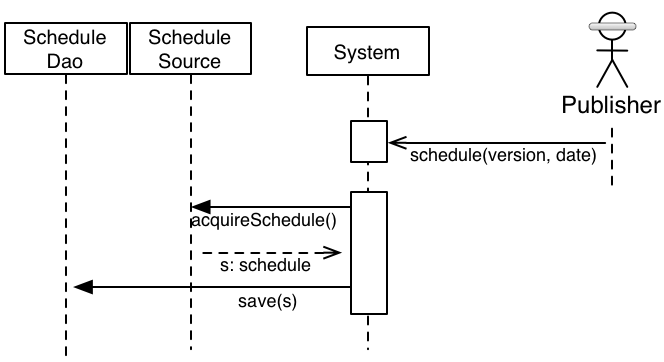
In this particular situation, we had three major things we needed to do: acquire the schedule in its
raw form, translate from XML to a schedule, and then persist it. The second and third steps had
already been written some time ago, so when work on this began, we had handle acquisition. There was
never a case where our system actually needed the original raw representation, so acquisition
resulting in a Schedule was better than ever seeing the XML representation elsewhere in the system.
A quick envisioning of this became:
Figure 12: Asynchronous was given but
incidental
Notice that the dependencies on the various JMS interfaces did not go away. It just went behind one
more level of indirection. Our system-level view was that we had something that could get schedules.
How it did that exactly was left for the particular implementation. In fact, we originally wrote a
simple
fake
during initial exploration using Active MQ. Later, we additionally used
Mockito
to write per-test
stubs.
The resulting high-level interaction was a touch easier to follow:
Figure 13: Now our flow follows our
consumption
All of this became important for a number of reasons:
It took some time to get Tibco access, but we had concrete examples early on
The translation from the raw format to a schedule did require some additional work,
which we could do without waiting
We had to learn some of the inner workings of Spring 3.x, and doing this with ActiveMQ got
us probably 90% of the way there while we were waiting for Tibco access.
We had no control over Tibco, it was in another group's responsibility (and something that
politically was not going to change) - this is a huge sign that the DIP will be your friend.
We were practicing
continuous
Integration, which means we ran tests often, easily 60+ times a day: up to 5 pairs,
multiple check-ins, multiple developer runs before checking in, then on the build box for
each check-in, and the performance tests, etc.
The test queues were shared
The test queues were often unavailable because some other testing had filled their
buffers
The test queues would have consumers that might swallow all messages, meaning our
tests could fail because of something out of our control
How bad was it?
All of these risks made being able to verify the majority of our logic not directly related to
Tibco-specific issues essential. In fact, the logic of working with JMS made the distinction between
Tibco and ActiveMQ strictly a configuration issue rather than a code issue. When we used ActiveMQ,
we pointed to an in-process queue. When we used Tibco, we pointed to one of a number of queues
depending on if we wanted to use QA queues or production queues. While there were some differences
(ActiveMQ was a little more forgiving), we managed to write one path that handled both libraries.
If this sounds heavy-weight, it wasn't. The actual design is straightforward. Thinking about the
design was not days of effort, it was minutes. Implementing the design was a good amount of time,
but most of that was discovery because many of us were rusty with JMS (I'm always rusty with it, I
live and die by Google.)
The real win came months after we had this working both in QA and a replication of production. At
some point, our system stopped working in QA but it still worked in every other environment,
including the replicated production environment. Immediately we guessed that the queue
configurations were different. We asked and were assured that the queue configurations were
the same. Since we had tests, we could work with someone and step through our tests while someone
looked at the queue. We did our due diligence and finally said that while we were not certain it
wasn't us, we were as certain as we could be given that the only identifiable variable related to
the use of one instance of Tibco versus another. After about a week and a half, they found out that
the QA queues were configured differently. While all of this was going on, our team was not stopped
from working on parts of this overall problem.
Conclusion
It is common to be given a solution to implement or for the solution to be constrained by existing
external environmental considerations. While you will write code to address the specifics of those
given constraints, that does not mean those details should diffuse throughout the rest of your
system. Hide the implementation in one place and give it an interface written from the perspective
of the goals of your domain. Sweep the details under the rug.
I've been in a coma, when is it?
Have you ever worked on a system that cared about dates and or time? How did you get access to the
current date? How did you handle the passage of time? Most systems care about time. In Java, there
are a number of ways to get the current date and or time but they all tend to use the time on the
system in which they run.
I've Got Your Schedule Right Here
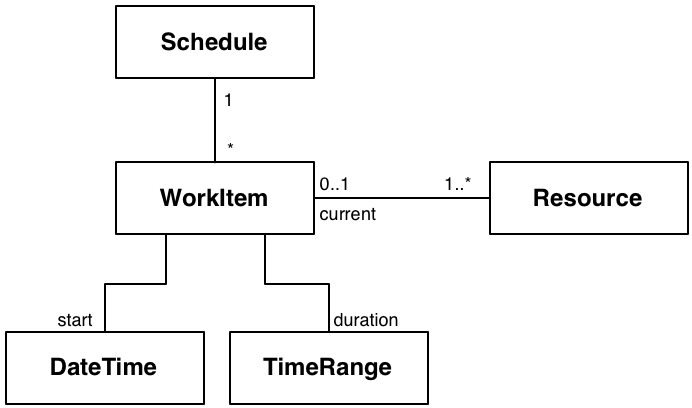
Image a system that has a number work items, each of which use some resource. Each item is either
scheduled to happen, happening, or finished happening. When two work items attempt to use the same
resource, there will be conflict and you need to make sure the system handles conflict correctly.
How are you going to verify that your system manages conflicts well?
Figure 14: Work items need to get worked
Domain Breakdown
There are a few key concepts in this description: work items, conflict, and time:
Work items are relatively simple, they have a name, description, start date/time, duration
and one or more resources.
Handling conflicts sounds like an interesting problem and there may be a number of ways to
handle conflicts. Initially we might have first-in, first out, later we might have something
like most valuable first, etc. In any case, we'll need to take the idea of conflict
resolution and promote it to something first-class in the system.
So far, so good. What about time?
Time is an interesting idea. Most of the time we take time for granted, if we think about it at all.
If we do nothing, a system will probably have a time, the time will pass about like it does on your
clock on the wall. It's always there, its rate of change doesn't seem to change much. However, what
if we want to make it move at a different pace than reality. What if we make the date appear to be
different from the actual date. How about skipping whole sections of time? A key thing about time is
it's changing without user intervention, but what if we want to own time? What could that even mean?
Move at a different pace
You have a time sensitive system with things that happen at time-frames of
seconds, minutes, days. You'd like to watch the system over time but you don't want to have
to wait an hour between occurrences of something that happens at the top of each hour.
Date different from current date
You are running the system across a test-bed with real production data that is
date-specific. Right now, the dates are in the future but you want to see what would happen
if it were tomorrow, a week before yesterday, or even next year. You can either change your
copy of the production data, or you can make your system think it's a different date from
the real date.
Skipping whole sections of time
In your system, things happen at discrete times. You want to make sure the right
thing happens at the right time. You could either make sure those things are set up based on
the time at which you choose to run the system, or you could just set the time and see what
happens.
How to train your Time Lord
Is time like other business concepts? Should we treat it as a first class citizen that deserves a
little respect? What might that look like? What might that offer? Have a look at the Scheduling
Example.
Scheduling Example
Feature:
Handling Scheduling Conflicts
As an operator I want to make sure feature conflicts are managed by an appropriate policy.
Background:
Given
an empty schedule
And
a work item named Megatron_Torso scheduled to start at 10:00, last for 15 minutes, and use
3d_printer_1
And
a work item named Megatron_Head scheduled to start at 10:10, last for 5 minutes, and use
3d_printer_1
And
a first one wins conflict resolution approach
And
the business time is 9:59
Scenario:
Nothing going on
Then
there should be no active items at 9:59
Scenario:
One item active
Then
Megatron_Torso should be active at 10:01
Scenario:
Conflict Handled
Then
Megatron_Torso should be active at 10:10
And
Megatron_Head should be blocked
Scenario:
Delayed Start
Then
Megatron_Torso should be completed at 10:16
And
Megatron_Head should be active
Scenario:
Delayed work item finishes late
Then
Megatron_Head should be completed at 10:21
The Scheduling Example is a description of a hypothetical system rewritten for this article, that's
based on a number of real systems I've worked on. These examples are written in a language called
Gherkin, which is used by a
tool called
Cucumber.
Using this particular
Domain Specific Language
(what the DDD and the BDD communities call a
Ubiquitous Language
, I have expressed some expectations / facts / examples of how the scheduling system is supposed to
behave.
This series of examples attempts to describe what should happen in the system given a well-defined
starting point and a number of follow-up activities. For example, according to the “Nothing Going
On” example, at 9:59, nothing should be active. Later on, at 10:01, one of the WorkItems should be
active. The first conflict is at 10:10, where WorkItem Megatron_Torso is still running and
Megatron_Head has to wait on the availability of the shared resource 3d_printer_1.
This kind of system validation is common, though this approach is not as common. In this domain,
time is important. Most times are not significant to this system, just certain times based on the
work schedule.
Which times are important? The example describes that explicitly by saying there is one work item
that starts at 10:00, is 15 minutes long, another that starts at 10:10 and lasts 5 minutes. To
verify my tests using something like
Boundary Testing
to choose times around the times that are important.
What I've seen as more typical is choosing times that are closer together and waiting for things to
happen. For example, instead of 15 minutes, I'll use 15 seconds. This kind of test setup, while
common, points out that the system has not taken ownership of a key domain concept: time.
An Example That Does It
If you choose to use Joda time, doing this kind of thing is trivial. Here is a simple Java class that
changes the time produced by Joda Time:
@Component
public class BusinessDateTimeAdjuster {
public void resetToSystemTime() {
DateTimeUtils.setCurrentMillisSystem();
}
public void setTimeTo(int hour, int minute) {
DateTimeUtils.setCurrentMillisFixed(todayAt(hour, minute).getMillis());
}
DateTime todayAt(int hour, int minute) {
MutableDateTime dateTime = new MutableDateTime();
dateTime.setTime(hour, minute, 0, 0);
DateTime result = dateTime.toDateTime();
return result;
}
}
Now, an expression like:
And the business time is 9:59
which, I execute for this example using
Cucumber-jvm, executes the following method:
public class ScheduleSteps {
@Given("^the business time is " + TIME + "$")
public void the_business_time_is(int hour, int minute) {
setTimeTo(hour, minute);
}
private void setTimeTo(int hour, int minute) {
BusinessDateTimeFactory.setTimeTo(hour, minute);
scheduleSystemExample.recalculate();
}
}
public class BusinessDateTimeFactory {
public static DateTime now() {
return new DateTime();
}
public static void restoreSystemTime() {
DateTimeUtils.setCurrentMillisSystem();
}
public static DateTime todayAt(int hour, int minute) {
MutableDateTime dateTime = now().toMutableDateTime();
dateTime.setTime(hour, minute, 0, 0);
return dateTime.toDateTime();
}
public static void setTimeTo(int hour, int minute) {
DateTimeUtils.setCurrentMillisFixed(todayAt(hour, minute).getMillis());
}
}
This code sets the time to a fixed point. The Cucumber-jvm library allows for hooks to execute
before and after tests. In this case, the after-test hook resets the time back to the system time.
In practice, the idea of introducing a domain concept like Business Time might sound like a lot of
work, but it really isn't. I've done this kind of thing late in a project, and even on a mature
project, getting this kind of idea introduced does not take as much time as I've seen it save in
terms of being able to test the system. For one data point, introducing a simple date factory might
take a few hours (I'd test it as dates tend to be persnickety). Finding all of the places where code
like
new Date()
or its equivalent occurs involves using regular expressions and recursive searching. Last time I did
this, 410 places in the code took maybe 2 hours to fix. So on a mature system, half a day. If you
are using Joda time, you don't even need to fix places in the code that callnew
DateTime(). While Joda time makes it easy, I've done this with Calendar in Java as well.
The idea sounds big, but it is more far reaching than the actual work to get it in place and
implemented.
Conclusion
We take many things as fixed. What's worse, we don't even notice key concepts because we are so used
to not thinking about them. I do not recall where I came across this idea. I think it was an
observation from a project many years ago. We were using copies of production data in a local
database. The production data had rules with dates. Every so often the dates would no longer be in
the future, and we also often got new cuts of the production data, with different dates (a different
problem). We kept “fixing” the dates after time had passed and it finally occurred to me that this
manual, repetitive, and error prone activity was a complete waste of time. We were changing the
dates, so clearly we needed to control the date. The first time I tried this, it took a bit longer
than half a day. Since then I've done it at least 5 times on 5 different in-production projects and
now it's something I do early on, so it takes very little time. I and several QA people have found
this kind of functionality handy and a great time-saver.
What this example demonstrates, however, is our code does not need to depend on something so
seemingly real as time. The more general idea is this: if something is causing problems, control it.
In this case, the control happened to be easily supported by the library, but if you have a look at
the final code example, I still introduce a BusinessDateTimeFactory to have a single place that
captured the idea of dates and time and then depended on it.
And That's a Wrap
We've seen a few of examples of the DIP in the wild:
Taking an unwieldy API with too many methods and taming it.
Removing a mismatch between the abstraction level of a library and the domain
Rejecting an external constraint that dictates a particular style of communication
Taking control of time itself
Some are more clearly an application of the DIP, while others might seem more like they fit into other
design principles. In the end, which principle applies more to a
situation is irrelevant. Daniel Terhorst-North
captures this idea well when he claims that
all software is a liability.
As a developer, it appears my goal is to write code. However, that is like asking an orthodontist if you
need braces. The answer is yes, thank you, I need to make another down-payment on my boat.
I enjoy writing code, learning new programming languages, and all of that. However, if I'm working on
solving a problem, it's important for me to remember that software is typically a means to an end, not
the end itself. This is true of design principles as well as agile practices. What makes sense is
remembering the point of the work and then let the context dictate what makes sense. If you are looking
for a way to frame a solution to a particular problem, the DIP is handy to know.
More generally, principles and practices that help me solve a particular business problem sooner are good
for that context. They may not work for another. I tend to work on long-lived systems that often involve
depending on work done by multiple reporting structures. This means identifying problematic dependencies
and getting them under control with a design principle like the DIP tends to be a recurring theme for
me. Any of these ideas could end up being terrible for your particular problem.
If you happen to be working on something with a short
software half-life, then the best
thing for your context might be to be directly dependent on those dependencies. Also, if you practice
TDD
as Robert Martin defines it (simply writing automated tests has almost nothing to do with TDD), then you
are probably in a position to make sweeping changes as needed. In this case, the DIP informs a
refactoring rather than an up-front design.
The practice of identifying dependencies and then determining if it is worth explicitly handling them and
if so, where, is a worthy skill to practice. You can take these specific examples as things to try,
guidelines on the kinds of things to look for when you're doing work, or even specific things you can
do to get your dependencies under control. Whether these examples, or the DIP for that matter, help
or hurt will be driven by the problem you are trying to solve.
Significant Revisions
21 May 2013: Added sections for “Don't take what is
given”, and “I've been in a coma, when is it?”





{kind=link}