
Using OAuth for a simple command line script to access Google's data
22 January 2019

I needed to write a simple script to pull some data from a Google website. Since I was grabbing some private data, I needed authorize myself to do that. I found it much more work than I expected, not because it's hard, but because there wasn't much documentation there to guide me - I had to puzzle out what path to go based on lots of not particularly relevant documentation. So once I'd figured it out I decided to write a short account of what I'd done, partly in case I need to do this again, and partly to help anyone else who wants to do this.
I first did this back in 2015. A year or so later, it broke, and I didn't have the bandwidth to fix it. I finally did fix it in 2019. While the libraries I'd used had changed (for the better), the documentation was still rather lacking, so I updated this article.
First a disclaimer. This is what I figured out, it works for me, at the moment. I haven't done extensive research of whether this is the best way to do what I want (although it sure felt like extensive research while I was doing it). So bear that in mind. (And if you have better ways do let me know.)
I did all of this in Ruby, since that's my familiar scripting language. I also used Google's api library for Ruby. But much of the overall flow would be the same for other languages, so if you're operating outside of Ruby I think much of what I did would still be relevant. I'll try to describe what I'm doing in a language independent view as much as possible, in addition to the ruby examples.
I need access some private data on youtube. 1 Since it's private data, I need to authenticate to Google and set up the necessary authorization for the script so it can get at that private data. I want to run this script without any manual intervention, so I want whatever auth mechanism I use to be something that the script can access itself, at least once I've logged into my laptop.
1: This isn't exactly what I was trying to do, but since I'm focusing on the Oauth part of the problem, I've simplified the actual task as much as I can.
Before I describe the successful path I followed, I should mention a path I took to a dead end. One of the things that made this simple exercise so tricky is that most of the documentation I read assumed I wanted to write a web-app that was guiding a browser. But I wanted a simple command line app (I guess because I'm old-fashioned that way) that didn't involve a browser. The first time I tried this I read through the Google guide to authentication and authorization and decided to use OAuth 2.0, as that seemed to be where Google wanted to go. Google then gave several scenarios for OAuth authorization, of which the natural (if complex) one to go for seemed to be Service Accounts. These support server-to-server access with authentication done via public/private key pair. I spent a good bit of time fiddling to get this to work and eventually was able to access google with it successfully, at which point I ran into a wall. With a service account, you effectively create a new user on Google. You then need some mechanism to allow that user to access your personal data. If you are running a domain on Google, there is a way to authorize service accounts to access your domain's data. However I could find no such mechanism for accessing data from a direct google account such as mine. Documentation implied you could do for some properties (such as analytics) but there was no general mechanism, such as one that would work for youtube data.
When I tried again in 2019, I tried Service Accounts again. This time it seemed much easier to use them in the way I wanted to. I was able to make a call that I felt confident would work, but it kept failing. Eventually I found the line in the documentation that said that Service Accounts don't work with YouTube. It's always frustrating to spend many hours working out a solution and running into a hard wall like that, if this article does nothing more than save a few people from that effort, then it's worth writing.
Outline flow for authorization
The path that did work for me is based on what Google calls the OAuth 2.0 for Mobile and Desktop Apps, but one that I needed to adapt to ensure I could (mostly) do it without having to manually intervene or use a browser.
To best explain how this works, I'll begin with a simple request to get that youtube listing. Whenever a script makes a request to get google data, you need to include an access token in your request. Google's docs show such an HTTP request like this.
GET /plus/v1/people/me HTTP/1.1 Authorization: Bearer 1/fFBGRNJru1FQd44AzqT3Zg Host: googleapis.com
The access token is just a random looking bunch of characters. It lasts for a short amount of time: roughly an hour. The access token is what the script needs to do its work, but that just leads to the question - how do you get an access token in the first place?
One way to get an access token is to have a different kind of token - a refresh token. Unlike access tokens, refresh tokens last for a long time. They only expire when they are revoked, they are superseded by later refresh tokens, or when Google has a hissy fit. I've been using the same one to access Google Analytics for several years. For our script's purpose a refresh token is just the job. Once I have a refresh token, I can store it in a safe place that the script can get to without manual intervention. I can then access the refresh token when I run the script, and as a first step use the refresh token to get a brand new access token. I then use the access token for the rest of the script run (providing my script doesn't run longer than the lifetime of an access token - and even Ruby isn't that slow).
Before I explain how to get the refresh token, there's one other thing about them. Each refresh token (and the access token they obtain) has a limited authorization scope - meaning you say what data they are allowed to access. I can create a refresh token that's only valid for reading my youtube data. If a bad guy were to get this token he could not read my calendar data, nor modify my youtube data. Having different tokens with different scopes helps me limit what I do with each token, which makes me a touch more secure (and less worried with how safely I store the tokens).
To get the refresh token, I do have to get a browser to log into google and authenticate itself as me. Like most people I have browser instances permanently logged into Google on my laptop, so that's no big deal. What I do is go to a google URL that's constructed in such a way to specify the authorization scope that I want. If I do that, while logged into my Google account, google will give me a one-time authorization code. I then take that code and visit another URL and google hands me the refresh token that I want. This is a manual step, but I only have to this rarely, so I'm fine with that.
Before all of this, there's a further thing I need to do - setup google to use APIs and allow access to the apps I want API access to reach. This also is a manual task, but I only need to do it once (unless Google has a really big hissy fit).
So here's the steps I need to go through:
- Set up Google for API access - a one-time manual action with logged in browser
- Get a one-time authorization code - needs logged in browser, done rarely
- Exchange the authorization code for a refresh token - API, done rarely
- Use the refresh token to get a new access token - api only, done once each time I run the script
- Use the access token when calling google - api only, done every time I call a google api
Setting up Google
To use APIs with a google account I need to go into Google and set things up. The place I need to be is the Google Developers Console. I already had a project defined in the console, but you'll need to do that if you don't have one already.
The first thing I need to do is to enable the youtube data api, I hit the link at the top marked “Enable APIs and Services
Following that link, I can search for APIs to add and enable them.
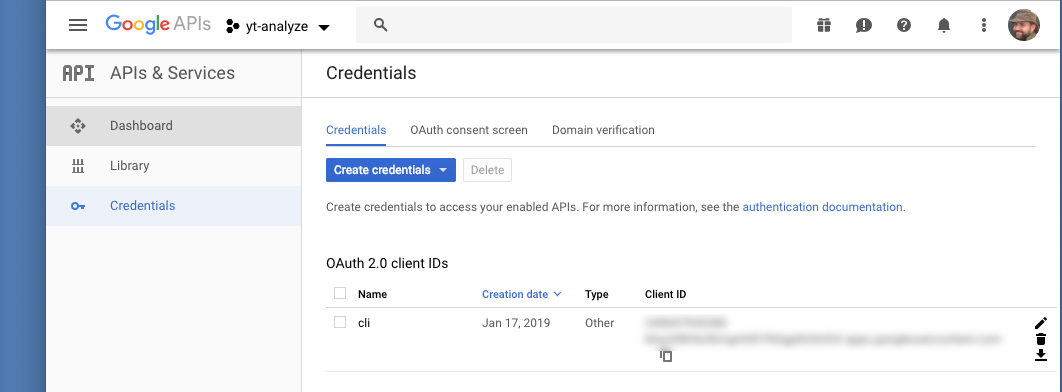
Next, I have to sort out credentials, For this I click on the the “credentials” tab (on the left. If I don't have credentials already, I use the “create credentials” button to create some. It gives me a choice of client types: I pick “other”. It then shows me a screen with a client ID and client secret. I can get at this information later by hitting the pencil icon for that credential. I'll need to use those in my code shortly.
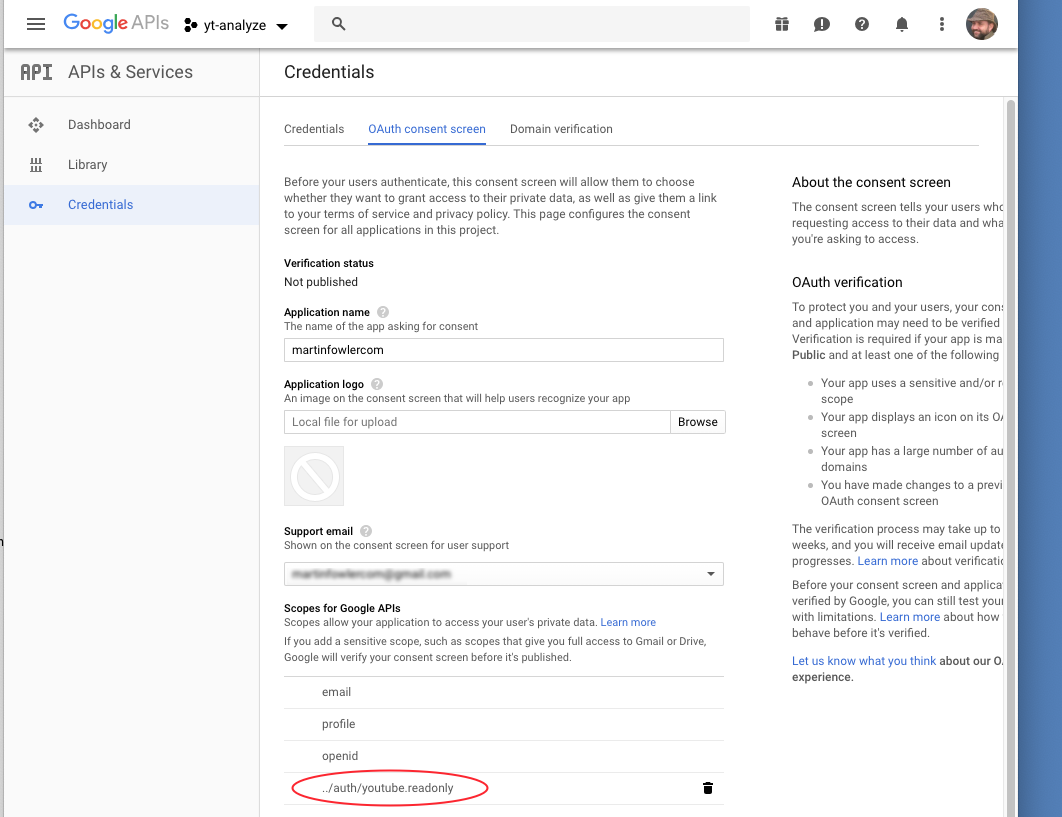
Finally I add the appropriate api scope to the project. For this I
hit the link at the top labelled “OAuth consent screen”. I scroll down to
the section “Scopes for Google APIs” and hit the “Add scope” button to add
the ../auth/youtube.readonly scope.
Getting the one-time authorization code
To get the one-time authorization code I need to hit a specially crafted google URL while logged into Google. Google will then return the authorization code. Google's documentation, and various samples I ran into, explain doing this via a web app. In the course of a normal web application flow, the web app realizes it needs auth, and sends the user over to google.
Google can return the authorization code directly to a web
app. All you need to do is run a server on your local machine
and tell google its URL - eg localhost:1234. Google
will then issue a GET to that URL and include the authorization
code as an parameter in the URL. Your code can then easily pick
off the parameter. You don't need much of a webserver on this
port to pick this up, all it ever needs to do is respond to this
one request. This level of simple server doesn't even need
Sinatra (Ruby's light weight web server framework), I remember
many years ago being in an introductory Ruby class with Prag
Dave where we wrote a simple web server in a few minutes. But I
was too lazy to do even that.
What I did instead was let my program craft the necessary google URL and print this URL out on the console. I then copy and paste it into my browser. Google (after a little dance to check I know what I'm doing) responds with the authorization code on a web page. I then copy and paste this code back into my script. It's not as smooth as an automated mechanism, but I don't care since I only have to do it once every blue moon.
Let's look at my code for this. I divide any non-trivial command line script into multiple classes, separating the class that handles the command line interaction from an “engine” class that does all the work behind the scenes - essentially a use of Separated Presentation. I do this because I find it easier to separate the command line from the core code when I'm working on them. It's barely worth it in this case, but I find it a useful habit.
To manipulate the credentials, I create a Google credentials class
class GoogleCredentials…
def initialize(application_name: nil, refresh_key: , scopes: nil,
client_secret: nil, client_id: nil)
@application_name = application_name
@refresh_key = refresh_key
@scopes = scopes
@client_secret = client_secret
@client_id = client_id
end
I can create a credentials object with a factory method, putting in all the data I need
class GoogleCredentials…
def self.for_youtube
return self.new(
application_name: 'Youtube Analytics',
refresh_key: 'yt-analyze',
scopes: ['https://www.googleapis.com/auth/youtube.readonly'],
client_id: '12434.apps.googleusercontent.com',
client_secret: '1234secretstring'
)
end
Despite its name, the client_secret isn't much of a
secret in this context, more of a user-id
Most of this data is needed for interaction with Google. The exception
is the refresh_key which is the key I use to store the
refresh token once I have it.
To get the authorization code, I need to craft a google URL to access
this. I do this with the authorization_url method
class GoogleCredentials…
def authorization_url
params = {
scope: @scopes.join(" "),
redirect_uri: 'urn:ietf:wg:oauth:2.0:oob',
response_type: 'code',
client_id: @client_id
}
url = {
host: 'accounts.google.com',
path: '/o/oauth2/v2/auth',
query: URI.encode_www_form(params)
}
return URI::HTTPS.build(url)
end
I use the Thor library2 to handle the command line
2: There are quite a few command-line toolkits in Ruby. I haven't done a proper survey of them, but Thor seems to fit the bill reasonably well for my needs. It does a fair amount of stuff I don't care about, but it keeps that complexity out of the way for the simple things I need.
class CLI…
class CLI < Thor
include Thor::Actions
def initialize *args
super(*args)
@engine = GoogleCredentials.for_youtube
end
desc "url", "display the google auth url to hit in the browser"
def url
puts @engine.authorization_url
end
With this set up, I can go ruby cli.rb url in the command
line, and my code prints out a URL looking something like this
https://accounts.google.com/o/oauth2/auth? scope=https://www.googleapis.com/auth/youtube.readonly& redirect_uri=urn:ietf:wg:oauth:2.0:oob& response_type=code& client_id=12434.apps.googleusercontent.com
To make it easier to read, I've added newlines and whitespace and decoded the URL escapes. I've also made up the client_id.
The parameters to the URL are:
- scope: how much api we want to access, in this case we want readonly access to the youtube data api
- redirect_uri: in the usual flow of using this with a web app, google redirects the browser to another URL (typically a localhost post) and deposits its response there. Using this value tells google I want it displayed in the browser for me to copy and paste
- response_type: I want a one-time authorization code back
- client_id I get this from the earlier interaction with the Google Developers Console
Pasting that URL into my browser will (eventually) lead me to a web page from Google that shows the glistening authorization code.
Exchanging the authorization code for a refresh token
Now I have the authorization code I can initiate the second operation, obtaining the refresh token. I do this by contacting the Google authorization resource again, this time supplying the authorization code I just got from them and blending it with my client-secret, a code that identifies me to the google API. I don't need to be logged into Google for this step, nor do I need to use a browser.
At this point I have to face up to another question: where do I store the refresh token once I have it? Since this is a script that I'm the only one using, I could just store it in the source code with something like
def refresh_token '1234567890WOxNS_gTztCGW3OBTKcSoKfLXDPc5TA7xz4MEudVrK5jSpoR30zcRFq6' end
I don't like this as I like to keep my code in repositories which are widely copied and often shared with others. Indeed general security advice is to never keep secrets anywhere inside your repository code tree. It's too easy to accidentally commit a file with a secret, and when done, it's nearly impossible to remove. Since I'm naturally rather careless, I try to arrange things so my inevitable mistakes won't cause lasting damage
Another option is to just dump the token in a file outside the source tree. My hard drive is encrypted, so that's reasonably safe - particularly since all I'm protecting is the dark secrets of my Youtube viewing habits. If I were being a bit more paranoid I could encrypt that file, but then that only raises the question of where to store the encryption key for the file, as I don't want to type in a password every time I use the script.
Since I'm running this on a mac, I decided to use the Mac's
built in keychain. This automatically opens when I log in and I
can access it with the security command-line
application. I'll have to think of something else should I want
to run this on my Ubuntu box, but I'll deal with that if I need
to do that one day.
To get the refresh token, I need to use the one-time authorization code I got earlier to request new tokens, dig out the refresh token, and put it into my keychain. (I say “tokens”, because Google responds with both an access token and a refresh token.)
To request these tokens, I talk again to Google, but this time I find it best to use the ruby client library for the Google api. Here's the code to get the tokens:
class CLI…
desc "refresh", "put in auth code, save refresh code"
def refresh
auth_code = ask "paste in the authorization code"
@engine.renew_refresh_token auth_code
end
class GoogleCredentials…
def renew_refresh_token auth_code
token = get_new_refresh_token(auth_code)
puts "new token: #{token}"
save_refresh_token token
end
def get_new_refresh_token auth_code
client = Signet::OAuth2::Client.new(
token_credential_uri: 'https://www.googleapis.com/oauth2/v3/token',
code: auth_code,
client_id: @client_id,
client_secret: client_secret,
redirect_uri: 'urn:ietf:wg:oauth:2.0:oob',
grant_type: 'authorization_code'
)
client.fetch_access_token!
return client.refresh_token
end
This code first instantiates a Signet OAuth2 client object with all the needed data and then tells it to fetch access_tokens. Once it's done that, I can ask it for the refresh token and save it away.
I save the token into my Mac's keychain.
class GoogleCredentials…
def save_refresh_token arg
cmd = "security add-generic-password -a '#{@refresh_key}' -s '#{@refresh_key}' -w '#{arg}'"
system cmd
end
The security command needs both a service (-s)
and an account (-a) when storing a value. I use
the same value for each of them, as I really just want a
key-value store.
Using the refresh token to get an access token
The above authorization logic is rare, I expected only to invoke it once every blue moon, and indeed I've only run it twice in the last few years. Hopefully, by the next time I need to, the libraries won't have changed so I need to mess with it again. I will just declare a new factory method if I need to access a new scope.
Now I have the credentials object, all I need is to use it to do something useful (or in this case print my playlists).
To use the refresh token I need to create a UserRefreshCredentials
with the refresh token, and use fetch_access_token! to get
it to talk to Google and load itself
with the access token I need to call the google apis. Here's
the code for that.
class GoogleCredentials…
def load_user_refresh_credentials
@credentials = Google::Auth::UserRefreshCredentials.new(
client_id: @client_id,
scope: @scopes,
client_secret: @client_secret,
refresh_token: refresh_token,
additional_parameters: { "access_type" => "offline" })
@credentials.fetch_access_token!
return @credentials
end
def refresh_token
@refresh_token ||= `security find-generic-password -wa #{@refresh_key}`.chomp
@refresh_token
end
Getting a list of videos from the Google API
When I first wrote this article, the ruby libraries to access google were particularly opaque. They used runtime code generation, so I needed to use pry just to figure out what methods I could call. But now they do the code generation as step in the build, and store the generated classes as a first class artifact. This allows me to see what methods they have, which makes it so much easier to work with them. This also allows them to have API documentation online at rubydoc.
To talk to youtube, I need to use youtube service. To sort out the authorization and authetication, I just provide it with the user refresh credentials.
auth_client = GoogleCredentials.for_youtube.load_user_refresh_credentials youtube = Google::Apis::YoutubeV3::YouTubeService.new youtube.authorization = auth_client
I can now call methods on this youtube object, such as one to list the items on a playlist.
youtube.list_playlists('snippet', max_results: 50, mine: true)
The call returns a ListPlaylistReponse object. This is simple data object, one of those anemic data objects that OO mavens like me usually despise, but is perfectly good in this context as it acts as a Data Transfer Object.
Footnotes
1: This isn't exactly what I was trying to do, but since I'm focusing on the Oauth part of the problem, I've simplified the actual task as much as I can.
2: There are quite a few command-line toolkits in Ruby. I haven't done a proper survey of them, but Thor seems to fit the bill reasonably well for my needs. It does a fair amount of stuff I don't care about, but it keeps that complexity out of the way for the simple things I need.
Significant Revisions
22 January 2019: Updated article to fit with current libraries
27 February 2016: Article deprecated due to change in libraries
26 January 2015: First published